RoboAfford++:一个用于机器人操作和导航中多模态 Affordance 学习的生成式AI增强数据集
25年11月来自小米、中科院自动化所、清华、人大和合肥工大的论文“RoboAfford++: A Generative AI-Enhanced Dataset for Multimodal Affordance Learning in Robotic Manipulation and Navigation”。机器人操作和导航是具身智能的基本能力,使机器人能够与物理世界进行有效的交互。在操作中,预测
25年11月来自小米、中科院自动化所、清华、人大和合肥工大的论文“RoboAfford++: A Generative AI-Enhanced Dataset for Multimodal Affordance Learning in Robotic Manipulation and Navigation”。
机器人操作和导航是具身智能的基本能力,使机器人能够与物理世界进行有效的交互。在操作中,预测精确的交互位置对于抓取和放置物体至关重要。在导航中,找到目标并理解可通行空间对于安全移动至关重要。实现这些能力需要对环境有全面的理解,包括物体识别(用于定位目标物体)、物体affordance(用于识别潜交互区域)以及空间affordance(用于辨别物体放置和机器人移动的最佳区域)。虽然视觉-语言模型(VLM)在高级任务规划和场景理解方面表现出色,但它们通常难以推断用于物理交互的可操作位置,例如功能性抓取点和允许的放置区域。这种局限性源于其训练数据集中缺乏物体和空间affordance的细粒度标注。为了应对这一挑战,RoboAfford++,一个生成式人工智能增强数据集,用于多模态affordance学习,以支持机器人操作和导航。该数据集包含 869,987 张图像和 200 万条问答 (QA) 标注,涵盖三个关键任务:物体affordance识别(基于属性和空间关系识别目标物体)、物体affordance预测(精确定位可操作的功能部件)以及空间affordance定位(识别用于物体放置和机器人导航的可用空间)。作为该数据集的补充,RoboAfford-Eval,一个用于评估真实场景中affordance感知预测的综合基准测试,包含 338 个精心标注的样本,涵盖上述三个任务。大量的实验结果揭示现有VLM 在 affordance 学习方面的不足,而基于 RoboAfford++ 数据集的微调显著提升它们对物体和空间 affordance 的推理能力,验证了该数据集的有效性。
在机器人操作和导航中,视觉语言模型(VLM)需要根据语言指令定位目标物体或其部件,同时识别适合放置或移动的区域。这涉及三个核心能力:(1)物体affordance识别:基于类别、颜色、大小和空间关系等属性识别物体;(2)物体affordance预测:定位物体的功能部件以支持特定动作,例如抓取茶壶的把手;(3)空间affordance定位:检测场景中用于物体放置和机器人导航的空置区域,例如用于存放物品的货架空间。尽管近年来取得了一些进展[32]、[33]、[28],但能够全面整合物体和空间affordance,并充分支持操作和导航任务的研究仍然相对较少。虽然一些VLM[32][33]能够通过坐标粗略定位物体或评估空间兼容性,但它们通常无法在部件级别进行精细定位,例如识别物体的功能组件。此外,这些模型专门针对操作任务进行训练,导致其应用范围狭窄,限制了它们在现实世界中各种操作和导航场景下的泛化能力。
为了应对这些挑战,RoboAfford++,一个由生成式人工智能增强的大规模数据集,包含密集且感知affordance的标注,用于机器人操作和导航。它包含 869,987 张图像和 200 万个问答对,统一物体和空间affordance,以支持跨两个域以交互为中心的学习。如图所示,RoboAfford++ 旨在为VLM提供具身交互所必需的affordance推理能力。该数据集使模型能够确定目标物体的位置,预测用于交互的部件级affordance,并识别用于放置和导航的空间affordance。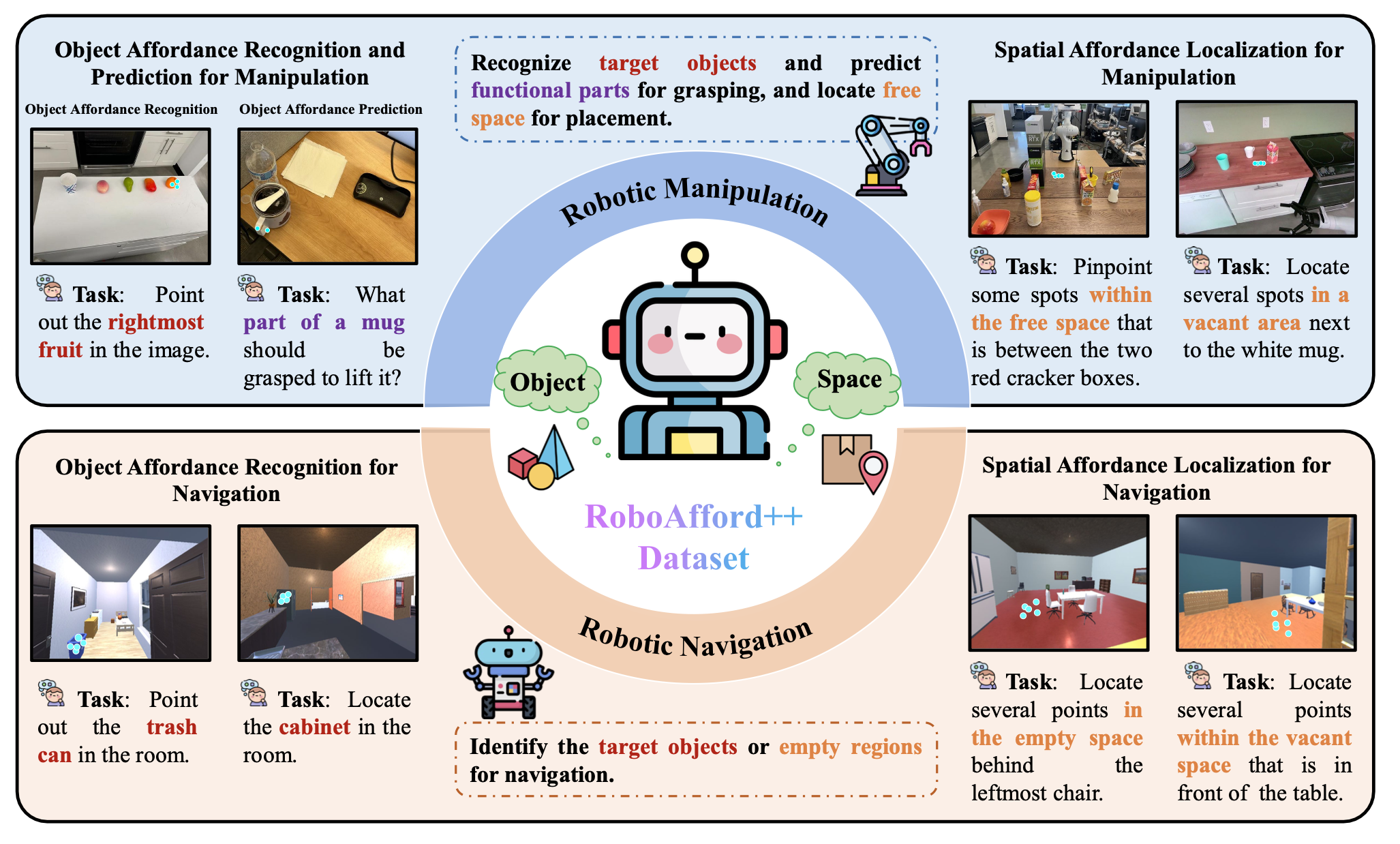
数据收集与筛选
如表所示,RoboAfford++ 数据集整合来自六个数据源的标注信息。通过将来自互联网的真实世界数据与仿真生成的合成数据相结合,创建一个多样化的数据集,用于建模物体和空间交互。该数据集包含三个主要部分:物体affordance识别、物体affordance 预测和空间affordance定位。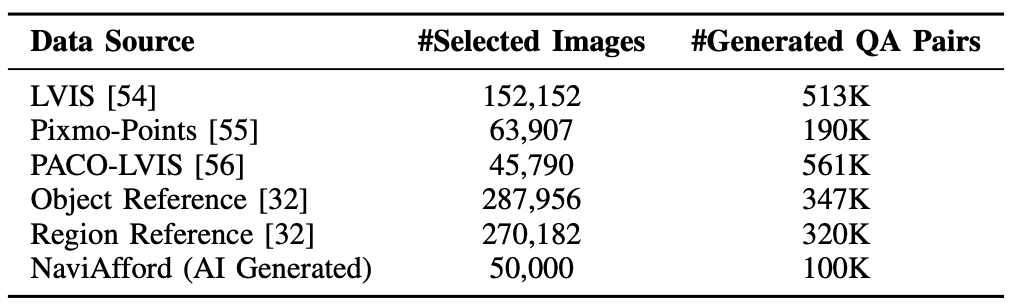
物体affordance识别。为了使视觉语言模型(VLM)具备通用的物体识别知识,利用 LVIS [54],将其转换为具有边框坐标 (x1, y1, x2, y2) 的物体检测格式,以建立视觉参考。此外,还利用 Pixmo-Points 数据集 [55],其中包含来自 22.3 万张图像的 230 万个点标注,以及来自 RoboPoint [32] 的 28.8 万张合成图像,用于物体参考学习。为了解决 Pixmo-Points [55] 中物体实例重复密集的问题,采用两步过滤流程:首先,为了简化训练,舍弃标注点数超过 10 个的标注;其次,用 GPT-4o [6] 仅保留相关的室内物体(例如家具、厨具),最终得到 63,907 张适用于物体指向的图像。
为了满足导航任务的需求,在 AI2Thor 模拟器 [57] 中构建 Navi-Afford 数据集,该数据集包含在 200 个室内环境中拍摄的 50,000 张以自我为中心的图像。数据采集过程首先随机选择可访问的位置,同时排除净空高度超过 1.5 米的区域。在每个位置,采集 RGB 图像以及实例分割掩码,并采样各种视角(0° 至 360° 随机旋转,以及 -15° 至 15° 水平旋转)。每张图像都附带元数据,例如可见物体的边框、它们的 3D 距离和 2D 坐标。然后,通过检测满足预定义邻近性标准(例如,水平距离大于 20 像素)的物体对来导出空间关系标注。对于每个有效的关系,在目标物体的边框内生成 4 到 8 个指向位置,形成“在 <目标物体> <关系> <参考物体> 上定位几个点”的指令。NaviAfford 数据集总共提供 50,000 个专为导航训练定制的affordance 样本。
物体affordance预测。对于物体affordance预测,利用 PACO-LVIS 数据集 [56] 提供用于推理的部件级标注。从 75 个物体类别和 200 个部件类别的 45,790 张图像中提取边框和部件分割掩码,并将它们转换为物体affordance的真实标签。这种结构化数据能够根据物体的affordance精确预测其交互方式。
空间affordance定位。为了进行空间affordance定位,从 RoboPoint [32] 获取区域参考数据,该数据集包含 27 万张图像,涵盖 8000 个实例和 262 个类别。每张图像包含一个或两个彩色边框来指示物体,其真实值被表示为一系列点 [(x1, y1), (x2, y2), …],用于自由空间参考。将归一化坐标转换为绝对位置,并对每个答案最多采样十个点,从而优化空间任务的模型性能。
问答对生成
如图所示,为 RoboAfford++ 中的每个任务创建专门的问答生成流程。通过将收集的数据转换为感知affordance的问答,增强VLM与数据集的交互,使其能够学习和推理物体及其affordance之间的空间关系。
• 对于物体affordance识别,用 GPT-4o [6] 分析场景并过滤掉无关的室外图像。创建用于生成问答的模板,例如“指出图像中所有出现
RoboAfford-Eval 基准测试
为了评估物体affordance识别和预测,用 Where2Place [32] 数据集中的图像,手动标注 114 个用于识别的问题和 124 个用于预测的问题。对于空间affordance,保留原始的 100 个问题,但将标注的affordance点从归一化坐标表示转换为绝对坐标表示。每个问题的真实值由一个或多个人工标注的多边形掩码组成,这些掩码对应于答案中的部件或实例。
对于每个预测点,检查它是否落在真实值掩码内。问题的准确率是正确定位的点与预测点总数的比值,总体准确率是所有问题的平均值。为了实施更严格的标准,对图像边界外的点进行惩罚,以鼓励模型更好地学习绝对交互位置。
框架。用 RoboAfford++ 数据集对名为 RoboAfford-Qwen++ 的模型进行微调。该模型采用多模态架构,包括视觉编码器、多层感知器 (MLP) 投影器、语言token化器和 Qwen2.5 大语言模型 (LLM),具体结构参见文献 [8],如图所示。视觉编码器从输入图像中提取视觉特征,并通过 MLP 投影器将其转换到与语言 token相同的嵌入空间。这些视觉嵌入与嵌入的文本指令连接起来,作为 LLM 的输入,用于跨模态的联合推理。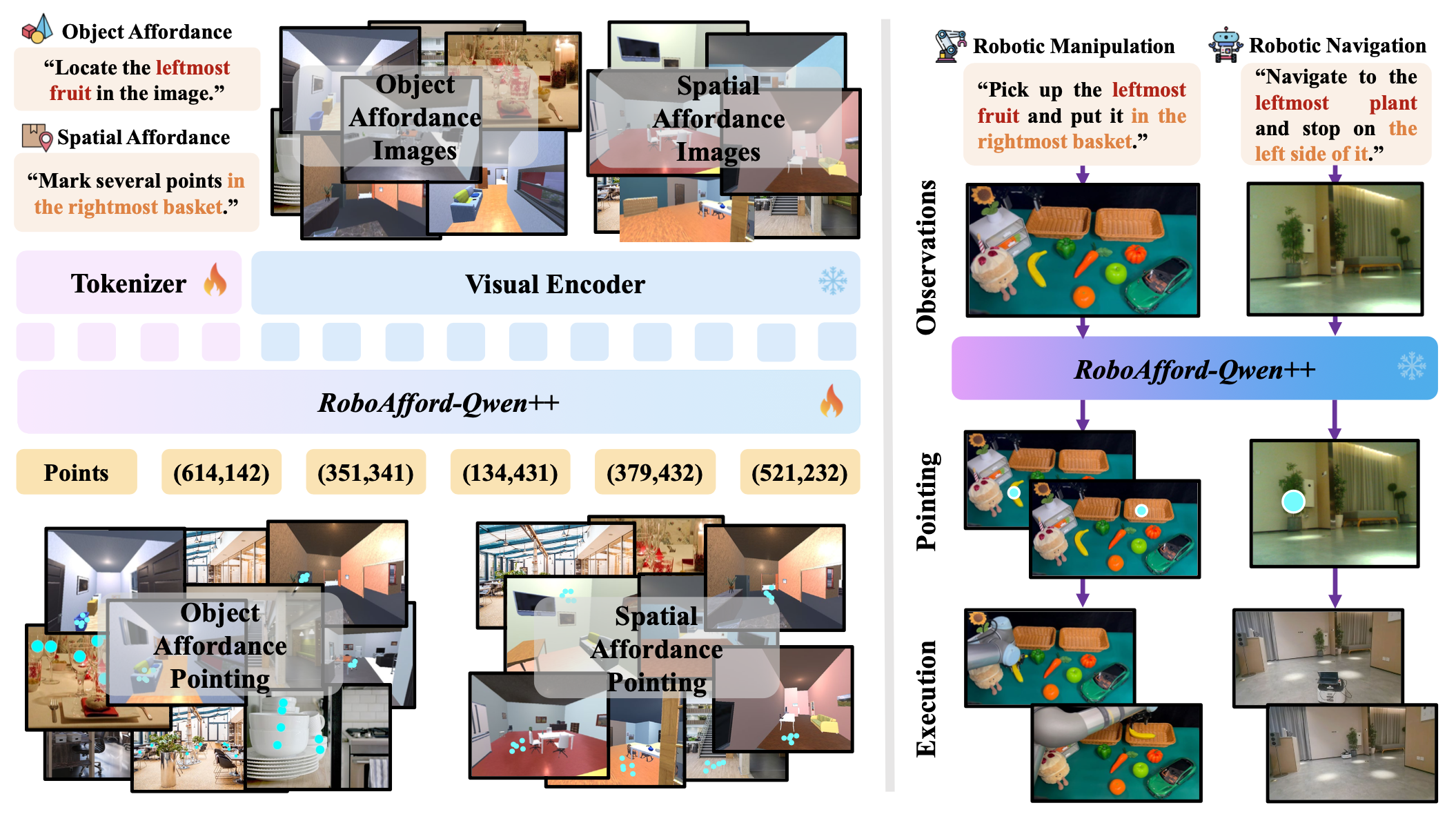
指令微调。采用基于 LLaVA-1.5 指令微调框架 [58] 的多阶段训练策略,该策略包含两个阶段:通用定位学习和对象空间affordance增强。第一阶段使用 LVIS [54] 和 Pixmo-Points [55] 数据集,共计 21.6 万张图像和 70.3 万个 QA 对,以增强基本的物体affordance识别能力。第二阶段整合 Object Reference [32]、NaviAfford、PACO-LVIS [56] 和 Region Reference [32] 数据集,共计 65.4 万张图像和 133 万个 QA 对,以优化物体affordance预测和空间affordance定位。这种多阶段方法使模型能够逐步发展分层affordance推理能力,从基本识别任务演进到高级预测任务。
实际机器人操作和导航。上图显示,经过微调的 RoboAfford-Qwen++ 可以有效地应用于下游机器人操作和导航。对于“拿起最左边的水果并将其放入最右边的篮子”这项任务,RoboAfford-Qwen++ 会预测目标物体对指定水果的affordance,以及篮子在可行放置位置的空间affordance。然后,预测的二维affordance点会被用作提示,通过 [59] 对目标物体进行分割,或者使用深度图将其转换为三维坐标,其中抓取姿态由 [60] 生成,用于机器人执行。
实现细节。RoboAfford-Qwen++ 模型使用预训练的 Qwen2.5-VL-7B-Instruct [65] 权重进行初始化,并按照 [66] 中描述的方法进行全参数监督微调。实验在八块 H100 GPU 上进行,使用 AdamW [67] 作为优化器,学习率为 10⁻⁵,训练周期为 1 个 epoch。每个设备处理的批大小为 4,梯度累积步数设置为 2。
基线模型。用提出的 RoboAfford-Eval 基准测试评估一系列最先进的 VLM 模型,包括闭源模型和开源模型。闭源模型包括 GPT-4o [6]、Claude-3.5-Sonnet [61]、Gemini-2.5-Flash [62] 和 Gemini-2.5-Pro [7]。开源模型涵盖了通用VLM,例如 LLaVA-Next [64]、Molmo [55]、Qwen2-VL [63] 和 Qwen2.5-VL [8]。还评估具有空间感知能力的开源 VLM,包括 SpaceMantis(SpatialVLM [48] 的社区实现)、RoboPoint [32] 和 RoboAfford-Qwen [28]。
评估指标。针对三个任务评估所提出的 RoboAfford-Eval 基准测试:物体affordance识别、物体affordance预测和空间affordance定位。使用的评估指标是准确率 (Acc),定义为正确定位到真实掩码内的预测点数与预测点总数的比值。对于实际操作和导航,采用成功率 (SR),定义为成功执行次数与总尝试次数的比值。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 15
15 0
0- 0



 已为社区贡献211条内容
已为社区贡献211条内容

所有评论(0)