论文阅读-Hybrid Classical/RL Local Planner for Ground Robot Navigation
本文提出了一种混合经典/强化学习(RL)的局部路径规划器,结合DWA算法和SAC强化学习的优势。创新点包括:1)采用极坐标代价地图提升避障直观性,增强仿真到实机的迁移能力;2)基于启发式规则(如障碍物距离阈值)实现规划器动态切换,无需额外训练。系统通过虚拟走廊检测路径净空状态,并采用滤波机制避免传感器噪声导致的频繁切换。实验表明,混合方法在保持DWA高效性的同时,通过SAC解决了DWA在复杂障碍下
Hybrid Classical/RL Local Planner for Ground Robot Navigation
根据周围环境在规划器之间进行切换,利用这两种方法的优势【AI/传统】
创新:
1. 用了 **极坐标代价地图:**普通的地图是XY坐标的格子,极坐标是“距离-角度”图。对于机器人避障来说,极坐标更直观(比如:前方3米处有个障碍),这有助于Sim-to-Real(仿真到真机)的迁移
2. 启发式逻辑切换:就是写几条硬规则(比如:前方X米内有障碍物就切RL,没有就切DWA),既简单又好用,不需要再训练一个网络
一些实现探索速度空间并基于配置空间中的前向模拟对候选速度进行评分(严格来说,这使它们成为规划器)
而其他实现则解决将状态映射到动作的约束优化问题(严格来说,这使它们成为控制器)
DWA 规划器:生成一组允许的速度,这些是在给定当前速度和机器人动力学约束(即加速度限制)的情况下可以达到的速度。对于每个允许的速度,DWA 执行前向模拟以计算机器人使用该速度时产生的轨迹。最后,对每个模拟轨迹进行评分,并选择成本最低的轨迹。目标函数反映了向目标的进展、与障碍物的间隙、遵循全局计划(到路点的距离)和旋转
核心优化函数:
C o s t = α ⋅ Goal_Dist + β ⋅ Obstacle_Dist + γ ⋅ Path_Align Cost = \alpha \cdot \text{Goal\_Dist} + \beta \cdot \text{Obstacle\_Dist} + \gamma \cdot \text{Path\_Align} Cost=α⋅Goal_Dist+β⋅Obstacle_Dist+γ⋅Path_Align
DWA 的做法是:假设我在接下来的 0.1秒保持速度 ( v , ω ) (v, \omega) (v,ω) 不变,我会走到哪?它会模拟出一条圆弧。
模拟几十条这样的圆弧,然后给每一条打分。离障碍物远的加分,离目标近的加分。
缺点:
如果路径中有障碍物,成本函数中的障碍物距离分量将开始占主导地位,指向远离全局路径的圆弧将具有更低的成本,从而使机器人偏离全局计划或目标。随着机器人转向离开,成本函数中的计划距离和目标距离分量将达到平衡,机器人将受引力回到计划上。接下来可能发生三种情况:
机器人可能已经取得了足够的前向进展,使得下一个路点位于障碍物后面,在这种情况下,局部规划器将使机器人返回到由全局计划确定的路径;
机器人可能转回障碍物,向其移动,并再次转向离开障碍物,但这次由于靠近障碍物而处于更困难的境地;机器狗在人面前左右横跳,就是不过去
全局规划器可能被触发并生成一组新的路点,引导机器人绕过障碍物。
理想的局部规划器应该总是产生第一种情况… 第二种情况通常会导致活锁(live-lock),表现为机器人接近障碍物并犹豫不决地振荡而不取得进展。在某些情况下,由于传感器限制可能会发生碰撞。即,在我们的实验中,我们看到碰撞是因为我们使用的 LiDAR 传感器具有最小距离范围。一旦机器人太靠近障碍物,反射未被注册,机器人就会冲向障碍物。我们认为这些缺点是 DWA 使用的单圆弧运动规划的直接后果
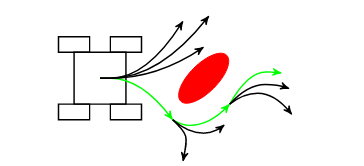
- 成功的避障需要三个连续的圆弧,如图 1 中的绿色所示。第一个圆弧将机器人推离障碍物,第二个圆弧在成功绕过障碍物后将其送回正轨,第三个圆弧重新调整方向以指向计划。DWA 规划器根本不探索超出这一个速度矢量的空间… 所有测试都指向缺乏对正在评分的圆弧之后的后续圆弧的可见性。
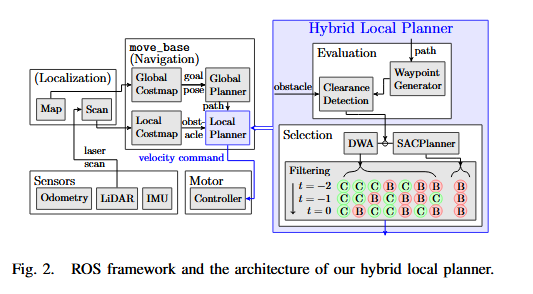
A. (路点生成)
为了生成路点,通向目标的全局路径(由 Dijkstra 算法生成)被降采样,并在局部代价地图上选择固定数量的路点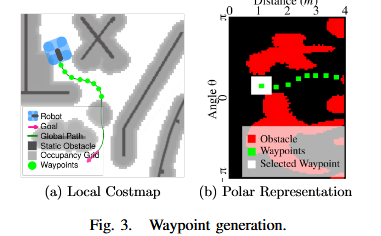
B. (净空检测/障碍物检测)
- 查找在没有任何动态障碍物的情况下的路径是否可以无碰撞地通过
-
一条有宽度的“虚拟走廊”(模拟机器狗的宽度),如果这个“虚拟走廊”里哪怕有一个像素是障碍物(红色部分),系统就判定:Block(受阻)
-
如果是 Clear -> 用 DWA(跑得快);如果是 Block -> 用 SACPlanner(避得开)。
C. Filtering (滤波)
传感器数据中的噪声可能导致净空检测器在两个规划器之间快速反复跳变(flip-flopping),如果仅使用最新的净空状态进行规划器选择的话。为了稳定,只有当我们确信路径上存在障碍物时,切换才应该发生。处理这种情况下的噪声的典型方法是检查基于直到当前时间 $t$ 的过去 $n$ 次观测 $O_{t-n:t}$,路径被阻塞 $b$ 的似然度 $\mathcal{L}(b|O_{t-n:t})$。[**公式解释** $\mathcal{L}(b|O_{t-n:t})$:这只是个数学写法。意思是:根据过去 $n$ 次的观察,判断现在是不是真的堵了。]
如果障碍物的似然度高于用户定义的阈值 $\tau$,我们认为路径被阻塞。我们将此策略实现为一个滤波器,跟踪检测器给出的最近 $n=3$ 次路径净空状态。如果所有状态都指示路径受阻,我们使用 SACPlanner,实际上使用了 $\tau=1$。否则,使用 DWA
这个方案在图 2 的“滤波(Filtering)”步骤(右下角的框)中进行了可视化。这种设计有助于在传感器强烈指示路径上存在障碍物时使用 SACPlanner,并带来高效的导航,因为相对更平滑和更快速的方法 DWA 在大多数时间被使用,只有在必要时才发生切换。
公式详细讲解:
这个公式由 5个部分 累加而成:
R ( s , a ) = ( d o l d − d n e w ) ⋅ C 1 ⏟ 1. 距离进步奖励 + ( ∣ θ o l d ∣ − ∣ θ n e w ∣ ) ⋅ C 2 ⏟ 2. 角度对齐奖励 − R m a x ⋅ I c o l l i s i o n ⏟ 3. 碰撞惩罚 + R m a x ⋅ I g o a l ⏟ 4. 到达目标奖励 − G ( s ′ ) ⏟ 5. 危险区域惩罚 \begin{aligned} R(s,a) = \ & \underbrace{(d_{old}-d_{new}) \cdot C_1}_{\text{1. 距离进步奖励}} \\ + \ & \underbrace{(|\theta_{old}|-|\theta_{new}|) \cdot C_2}_{\text{2. 角度对齐奖励}} \\ - \ & \underbrace{R_{max} \cdot \mathbb{I}_{collision}}_{\text{3. 碰撞惩罚}} \\ + \ & \underbrace{R_{max} \cdot \mathbb{I}_{goal}}_{\text{4. 到达目标奖励}} \\ - \ & \underbrace{G(s')}_{\text{5. 危险区域惩罚}} \end{aligned} R(s,a)= + − + − 1. 距离进步奖励 (dold−dnew)⋅C12. 角度对齐奖励 (∣θold∣−∣θnew∣)⋅C23. 碰撞惩罚 Rmax⋅Icollision4. 到达目标奖励 Rmax⋅Igoal5. 危险区域惩罚 G(s′)
-
距离奖励 (Distance Reward): ( d o l d − d n e w ) ⋅ ( 1 if d o l d − d n e w ≥ 0 , else 2 ) (d_{old}-d_{new}) \cdot (\text{1 if } d_{old}-d_{new}\ge0, \text{ else } 2) (dold−dnew)⋅(1 if dold−dnew≥0, else 2)
-
正值表示靠近目标,负值表示远离。
-
非对称加权(Asymmetric Weighting):
else 2是关键。这意味着后退的惩罚是前进奖励的两倍。这迫使 Agent 除非万不得已(即将碰撞),否则绝不走回头路。这解决了 RL 机器人容易原地打转刷分(Reward Hacking)的问题 19。
-
-
角度奖励 (Heading Reward): ( ∣ θ o l d ∣ − ∣ θ n e w ∣ ) ⋅ ( 1 if ∣ θ o l d ∣ − ∣ θ n e w ∣ ≥ 0 , else 2 ) (|\theta_{old}|-|\theta_{new}|) \cdot (\text{1 if } |\theta_{old}|-|\theta_{new}|\ge0, \text{ else } 2) (∣θold∣−∣θnew∣)⋅(1 if ∣θold∣−∣θnew∣≥0, else 2)
- 鼓励机器人车头对准目标。同样采用了非对称加权,惩罚偏离目标的旋转。
-
碰撞惩罚 (Collision Penalty): − R m a x ⋅ ( 1 if collision, else 0 ) - R_{max} \cdot (\text{1 if collision, else } 0) −Rmax⋅(1 if collision, else 0)
-
到达目标奖励 (Goal Reward): + R m a x ⋅ ( 1 if d n e w = 0 , else 0 ) + R_{max} \cdot (\text{1 if } d_{new}=0, \text{ else } 0) +Rmax⋅(1 if dnew=0, else 0)
-
高斯势场 (Gaussian Potential Field) G ( s ′ ) G(s^{\prime}) G(s′):
-
G ( s ′ ) ≈ ∑ o b s exp ( − d i s t ( r o b o t , o b s ) 2 2 σ 2 ) G(s') \approx \sum_{obs} \exp(-\frac{dist(robot, obs)^2}{2\sigma^2}) G(s′)≈∑obsexp(−2σ2dist(robot,obs)2)。
-
这实际上引入了一个人工势场(Artificial Potential Field)。即使没有发生碰撞,只要机器人靠近障碍物,这个项就会产生负值(惩罚)。这就是为什么 SACPlanner 在实验中表现得比 DWA 更“胆小”——它不仅怕撞,还怕靠得太近。DWA 只有在撞上的一瞬间(或极近距离)才会有巨大的代价,而 RL 通过这个项学会了保持安全距离 21。
-
它不是硬邦邦的一堵墙,而是一个斥力场,这对于处理动态障碍物非常有帮助,因为动态障碍物的位置是不确定的,留出安全余量能减少碰撞率
-
实验设置
无障碍复杂轨迹
路径上的意外静态障碍物
路径上的动态障碍物
动态障碍物穿过路径
反应时间
(C1) DWA:虽然能走,但你可以看到它贴墙很近,甚至撞了(碰撞图标)。
(C1) SAC:像喝醉了一样(红色轨迹扭来扭去),虽然没撞,但走得太丑了。
(C1) Hybrid:完美。主要用红色(DWA模式)跑直道,平滑且快。
不要只列“成功率”。要列出 平均速度(Efficiency)、路径长度(Path
optimality)、平滑度(角速度的变化率,Jerky)。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 13
13 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)