魔珐星云具身智能数字人平台深度体验:从平台配置到SDK实战的全流程指南
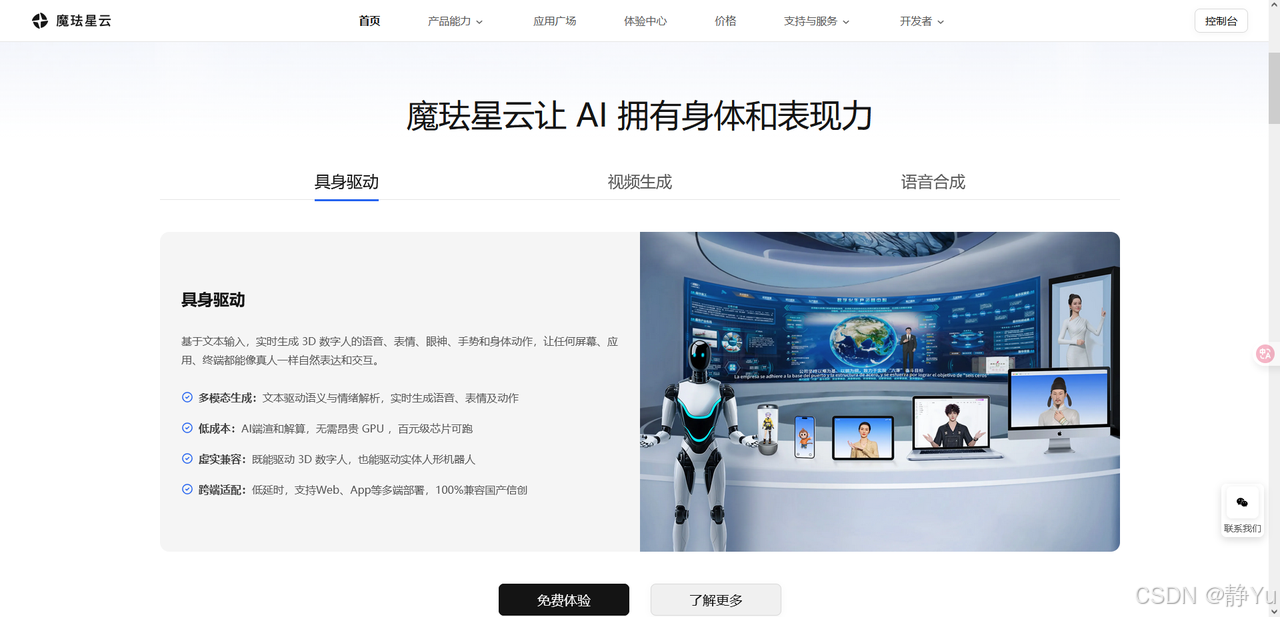
魔珐科技推出星云平台,作为具身智能基础设施,为开发者提供三维交互工具。平台包含具身驱动实验室、视频生成工坊和智能语音合成站三大核心模块,支持文本/语音指令驱动数字人动作、一键生成视频及60+音色库选择。用户可免费注册体验,通过简单配置创建个性化数字人应用,并支持本地SDK调用实现快速部署。该平台整合多模态技术,降低数字人开发门槛,适用于教育、娱乐等多场景创新应用。
在AI技术从“有大脑”向“有身体”演进的关键节点,魔珐科技推出的星云平台以“具身智能基础设施”的定位,成为开发者实现AI三维交互的突破性工具。本文将从平台配置流程、产品体验、技术解析三个维度,全面解析这款具身智能开放平台的实战价值。
一、魔珐星云平台产品初体验
所有用户都可免费注册,免费送100积分;如果持有邀请码还可免费获取1000积分。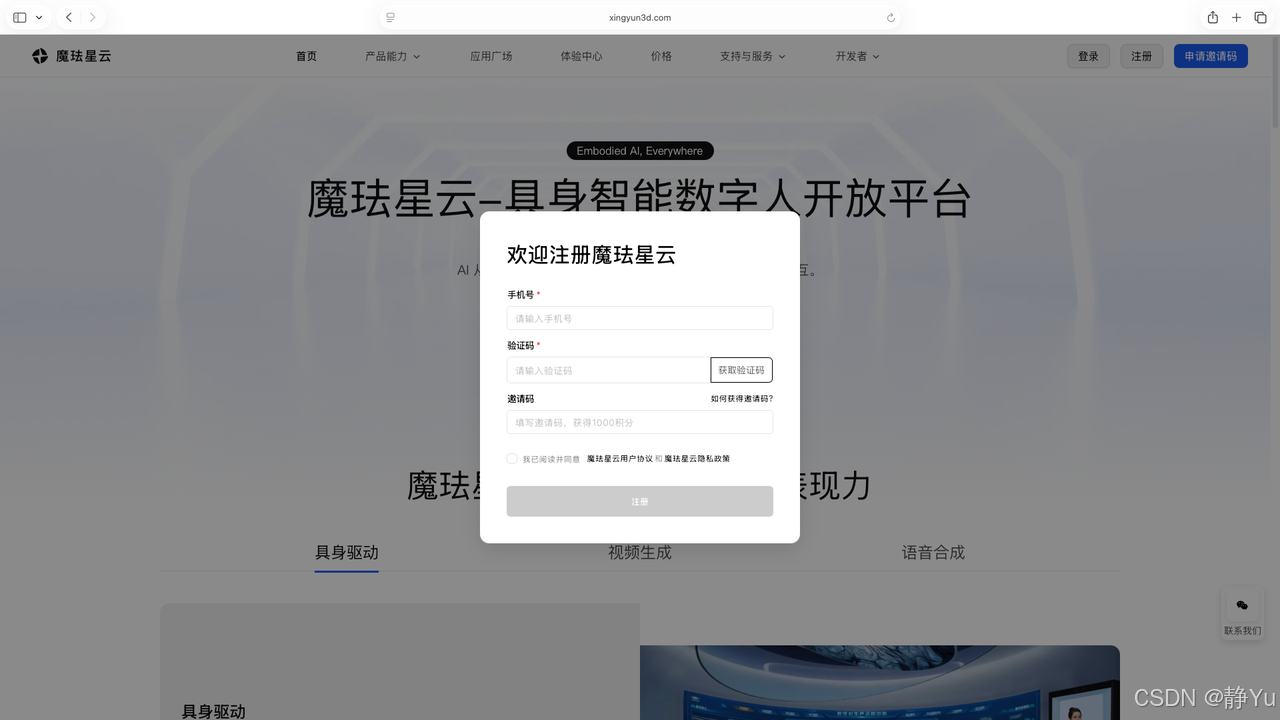
🎮 注册即玩:三大核心模块开启具身智能全体验
完成账号注册后,您将直接进入沉浸式体验中心,三大功能模块已就绪: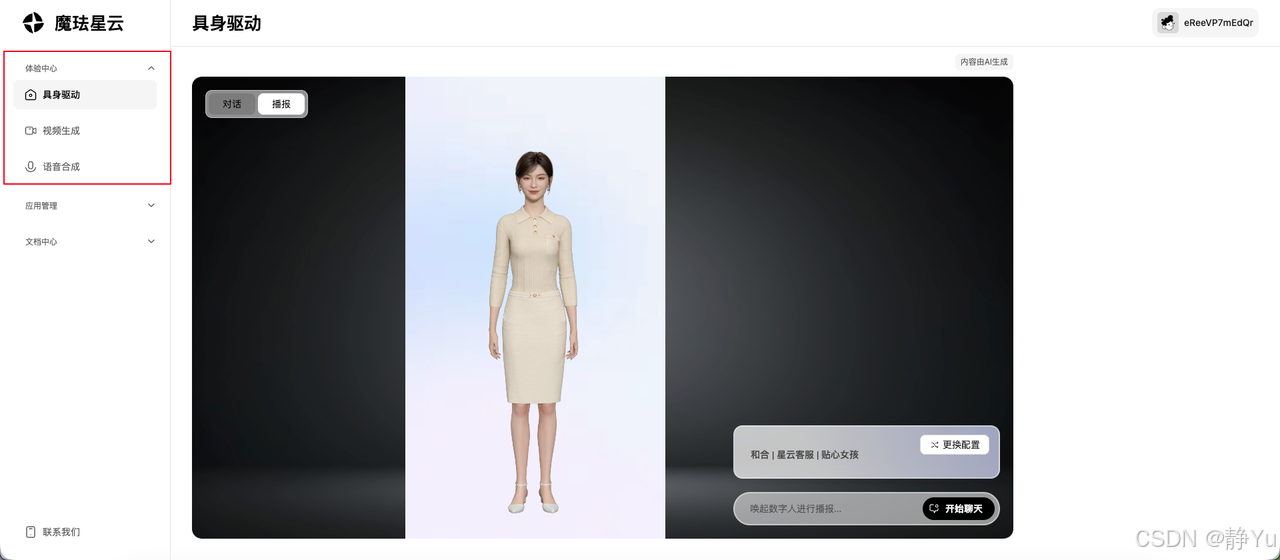
1️⃣ 具身驱动实验室
- 指令驱动动作:输入“跳舞”“挥手”等文本或语音指令,数字人可实时生成自然流畅的肢体动作。
- 高质量渲染:数字人模型具备影视级皮肤纹理、光影效果,动作过渡平滑无卡顿。
- 低延时保障:从指令输入到动作/语音响应平均仅需300ms左右(实测数据),交互如真人对话般顺畅,无感知延迟。
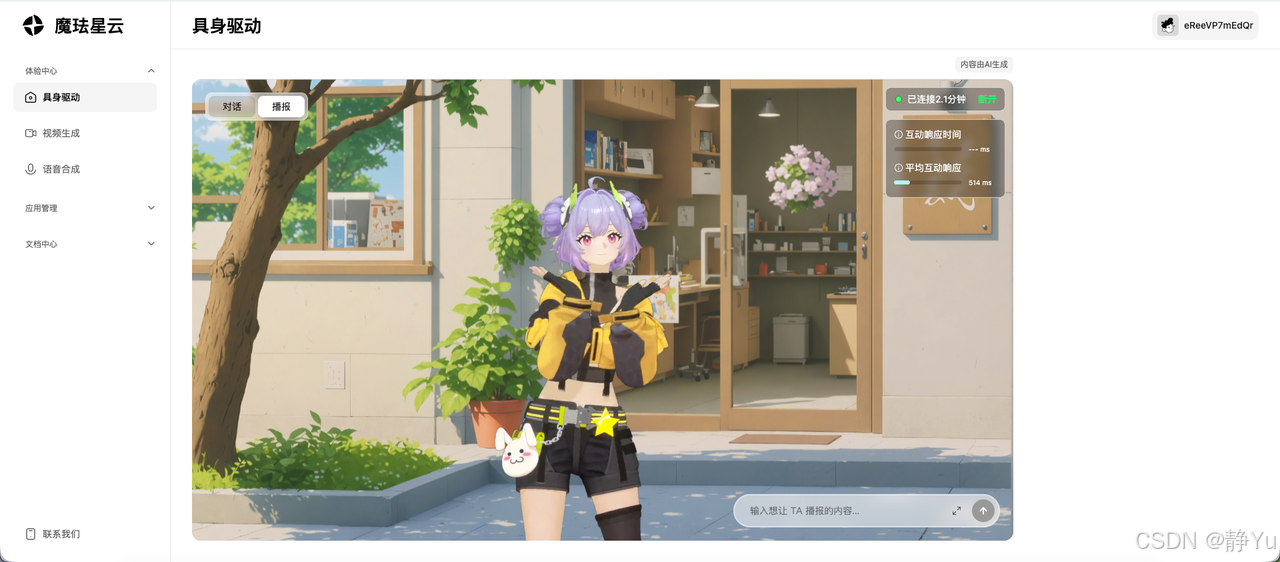
2️⃣ 一键视频生成工坊 - 输入脚本自动渲染:短时间将文字转化为带唇形同步的演讲视频,还可以上传PPT进行创作,可生成讲解文档的数字人视频
- 角色库任选:提供多种超写实数字人形象

3️⃣ 智能语音合成站
• 60+音色库:从专业女声到优雅主播,覆盖中英韩等多种语言
• 情感化表达:通过选择不同的风格,让AI语音传递喜悦/惊讶/愤怒等情绪
• 实时语音生成:输入声音内容之后即可生成音频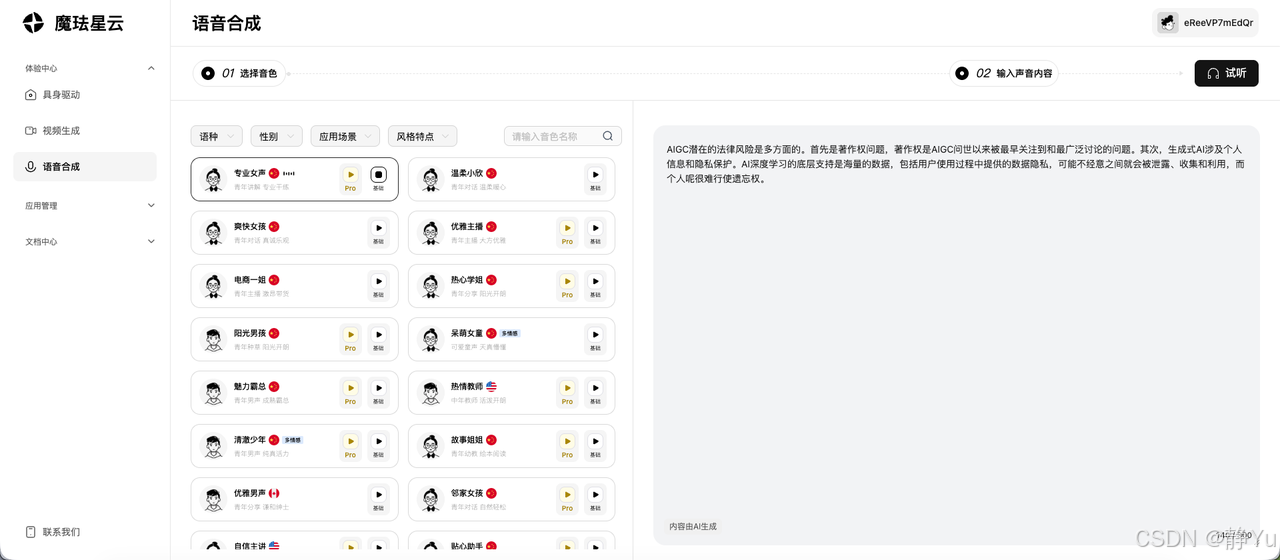
体验魔珐星云的三大核心模块后,其技术优势令人印象深刻:具身驱动带来毫秒级响应的流畅交互,动作自然且富有语境表现力;视频生成实现“文本到4K成片”的一键创作,画质与效率双优;语音合成则突破机械感,赋予AI声音情感与个性。平台以全栈能力整合多模态技术,既降低数字人应用门槛,又重新定义交互沉浸感,为教育、娱乐、客服等场景注入创新动能。
二、打造个人具身智能应用
平台应用管理搭建
到应用管理模块,可自定义搭建个人的具身智能应用。现在拿驱动应用示例。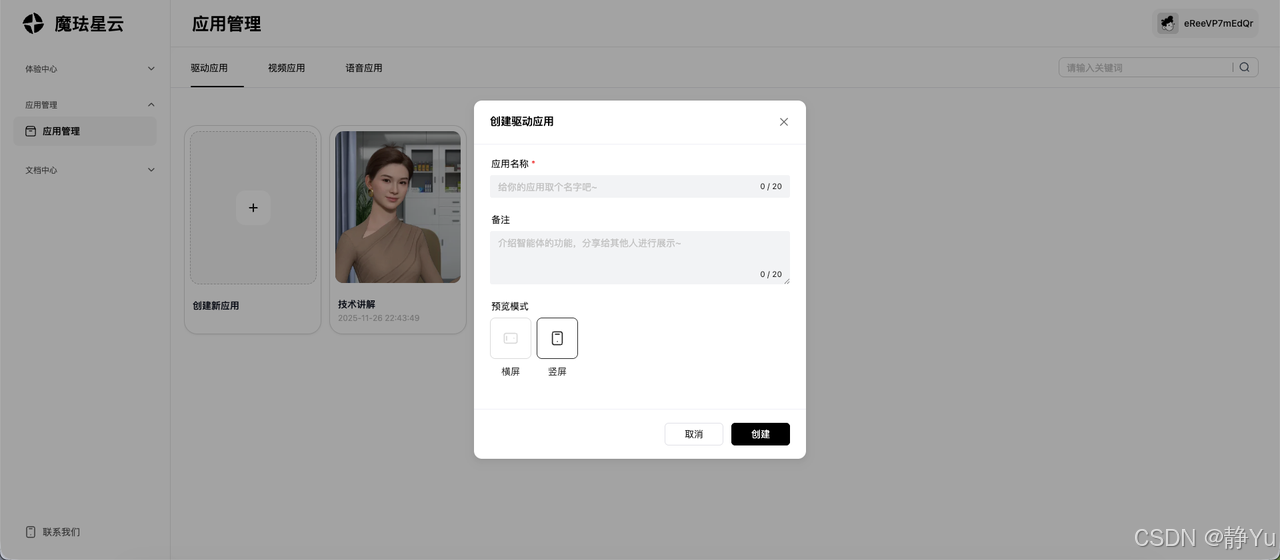
- 选定虚拟形象
在形象库中浏览或搜索角色,支持按风格(优雅风/复古风/学院风)、年龄、色系等标签筛选。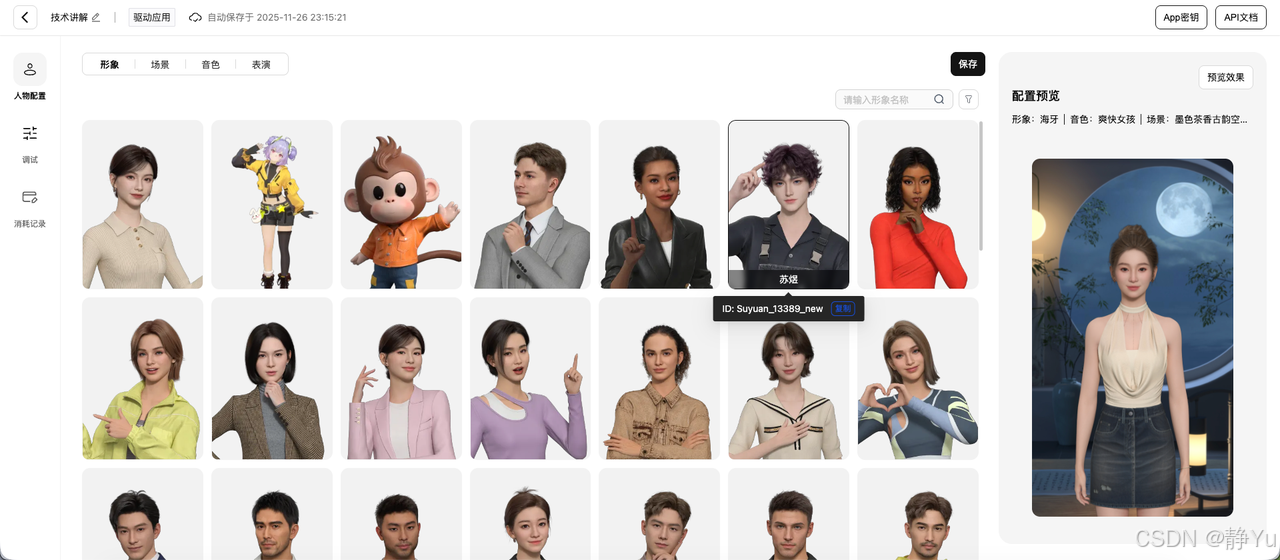
- 选定场景
可选择不同的站姿或者是坐姿,站姿或坐姿还区分了不同的场景和角度。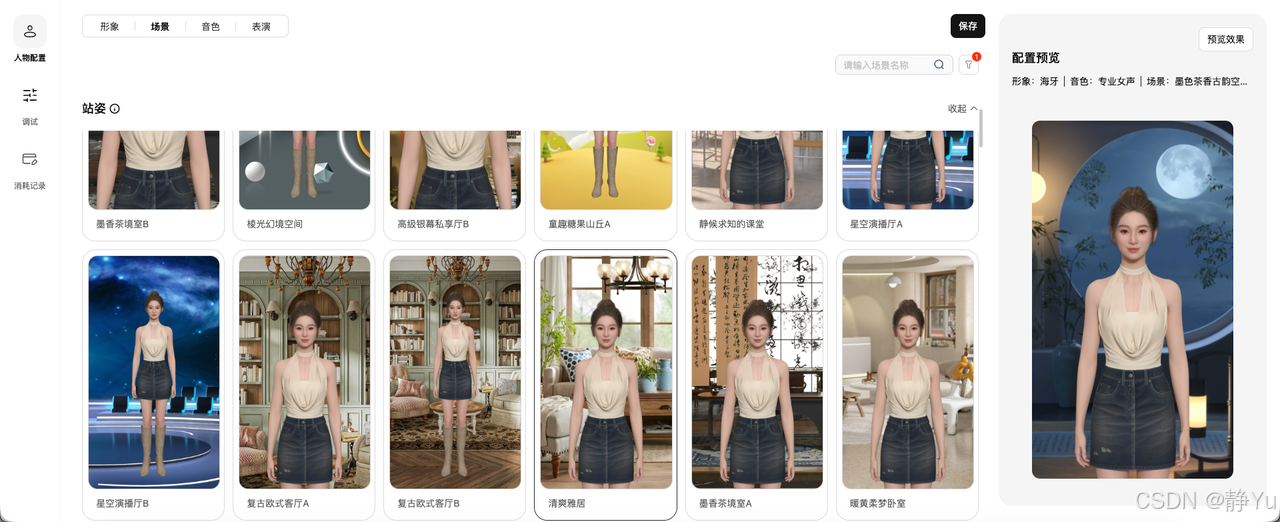
- 选定音色
平台提供了几十种不同的音色,包括男声、女声、不同风格、不同状态、不同语言。选择音色之后,还可个性化调节语速、语调、音量,打造适合自己应用场景的数字人形象。 - 选定表演(动作风格和面部表情)
可选择不同的动作风格,可根据你的应用场景来选择动作风格,例如我的应用场景是技术讲解,就选择活泼风格,能让学习者更加轻松。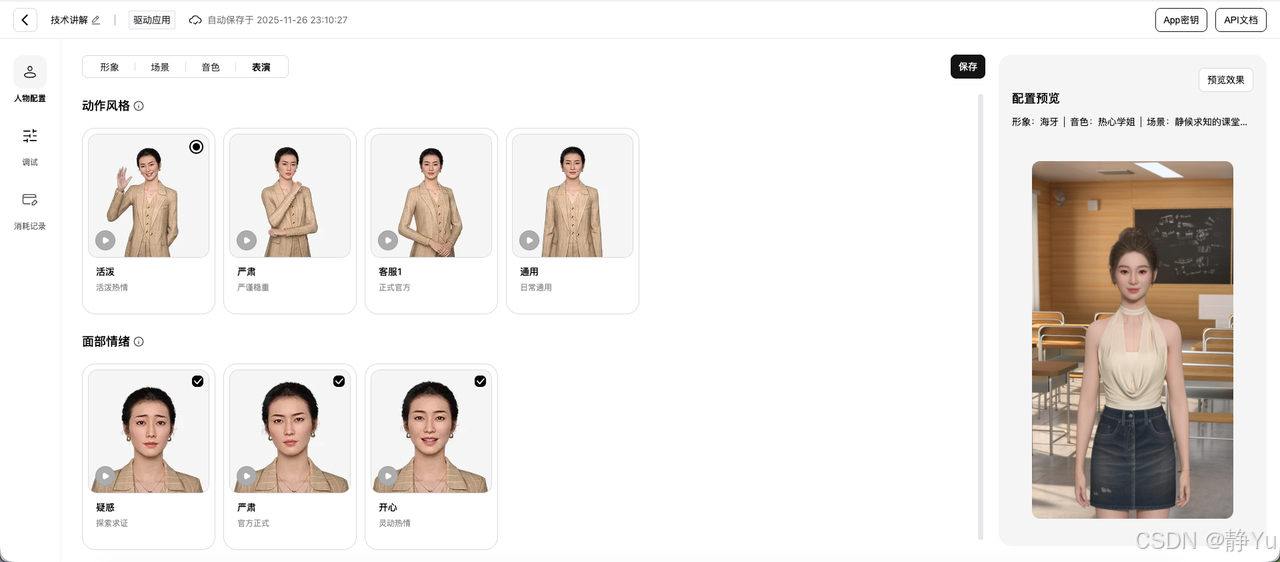
- 完成角色配置后,点击「预览效果」即可进入实时预览界面,全方位校验数字人形象、动作及语音的同步效果,不满意可即时调整。
除此之外,魔珐星云还提供了SDK,其以极简设计大幅降低数字人开发门槛:通过npm/CDN一键集成,初始化仅需传入APP ID和APP密钥,即可在本地部署自己的数字人。开发者无需处理复杂动画逻辑或语音渲染技术,只需几行代码就能让数字人实现自然交互,真正实现“开箱即用”,让技术聚焦业务创新。
本地部署,具身驱动SDK调用
- 现在我们就通过Vue+Ts创建一个前端项目,然后调用官方提供的SDK搭建一个个人专属具身智能应用,整体代码结构如下。
src/
├── App.vue # 应用主组件
├── main.ts # 应用入口
├── style.css # 全局样式
├── vite-env.d.ts # Vite环境类型声明
├── components/ # Vue组件
│ ├── index.vue # 虚拟人渲染组件
├── services/ # 服务层
│ ├── avatar.ts # 虚拟人SDK服务
│ └── llm.ts # 大语言模型服务
├── utils/ # 工具函数
│ ├── index.ts # 通用工具函数
│ ├── split.ts # 剪切字符串函数
└── assets/ # 静态资源
├── siri.png # 语音识别动画图标
└── vue.svg # Vue Logo
- 通过vue脚手架vue create demo创建一个vue项目,然后再通过npm i下载需要的依赖文件(typescript、vite、openai)。在index.html文件引入JS SDK:
<!doctype html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<link rel="icon" type="image/svg+xml" href="/vite.svg" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>Vite + Vue + TS</title>
</head>
<body>
<div id="app"></div>
<script type="module" src="/src/main.ts"></script>
<script src="https://media.xingyun3d.com/xingyun3d/general/litesdk/xmovAvatar.0.1.0-alpha.15.js"></script>
</body>
</html>
- 整个页面分为两个部分,左侧是数字人渲染区域,右侧是所需参数配置区域。
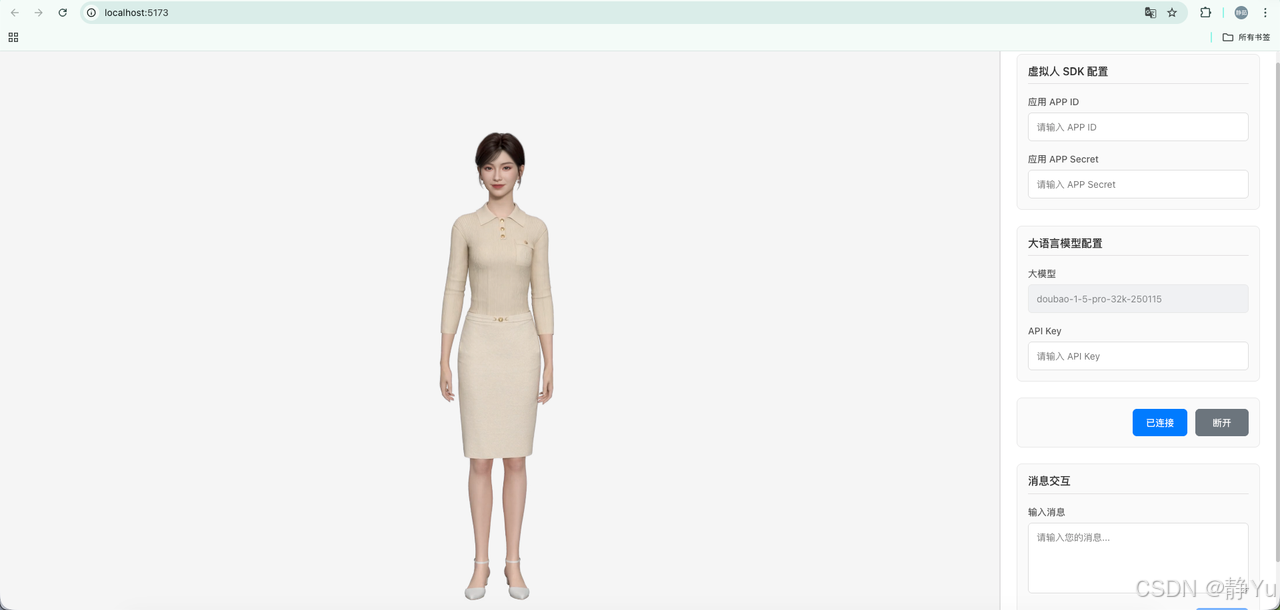
左侧数字人渲染区域,通过id为containerId的div块承接,包括展示数字人语音字幕和数字人记载状态。
<!-- SDK 渲染容器 -->
<div id="containerId" class="sdk-container" />
<!-- 字幕显示 -->
<div v-show="appState.ui.subTitleText" class="subtitle">
{{ appState.ui.subTitleText }}
</div>
<!-- 加载状态 -->
<div v-if="!appState.avatar.connected" class="loading-placeholder">
<div class="loading-text">-- 正在连接 --</div>
</div>
</div>
右侧配置区域,主要是一些input输入框,用来添加调用sdk一些必须的参数。
<div class="config-panel">
<!-- 虚拟人配置 -->
<section class="config-section">
<h3 class="section-title">虚拟人 SDK 配置</h3>
<div class="form-group">
<label>应用 APP ID</label>
<input
v-model="appState.avatar.appId"
type="text"
placeholder="请输入 APP ID"
/>
</div>
<div class="form-group">
<label>应用 APP Secret</label>
<input
v-model="appState.avatar.appSecret"
type="text"
placeholder="请输入 APP Secret"
/>
</div>
</section>
<!-- LLM配置 -->
<section class="config-section">
<h3 class="section-title">大语言模型配置</h3>
<div class="form-group">
<label>大模型</label>
<input v-model="appState.llm.model" disabled />
</div>
<div class="form-group">
<label>API Key</label>
<input
v-model="appState.llm.apiKey"
type="password"
placeholder="请输入 API Key"
/>
</div>
</section>
<!-- 控制按钮 -->
<section class="control-section">
<div class="button-group">
<button
@click="handleConnect"
class="btn btn-primary"
>
{{ isConnecting ? '连接中...' : appState.avatar.connected ? '已连接' : '连接' }}
</button>
<button
@click="handleDisconnect"
:disabled="!appState.avatar.connected"
class="btn btn-secondary"
>
断开
</button>
</div>
</section>
<!-- 消息交互 -->
<section class="message-section">
<h3 class="section-title">消息交互</h3>
<div class="form-group">
<label>输入消息</label>
<textarea
v-model="appState.ui.text"
rows="4"
placeholder="请输入您的消息..."
/>
</div>
<div class="button-group">
<button
@click="handleSendMessage"
:disabled="!appState.avatar.connected || !appState.ui.text.trim() || isSending"
class="btn btn-primary"
>
{{ isSending ? '发送中...' : '发送' }}
</button>
</div>
</section>
</div>
- 点击配置区域的连接按钮,触发handleConnect方法来加载数字人。数字人实时驱动SDK需要创建数字人创建实例,并且连接参数 App ID、App Secret,获取方式就是在平台应用管理中。
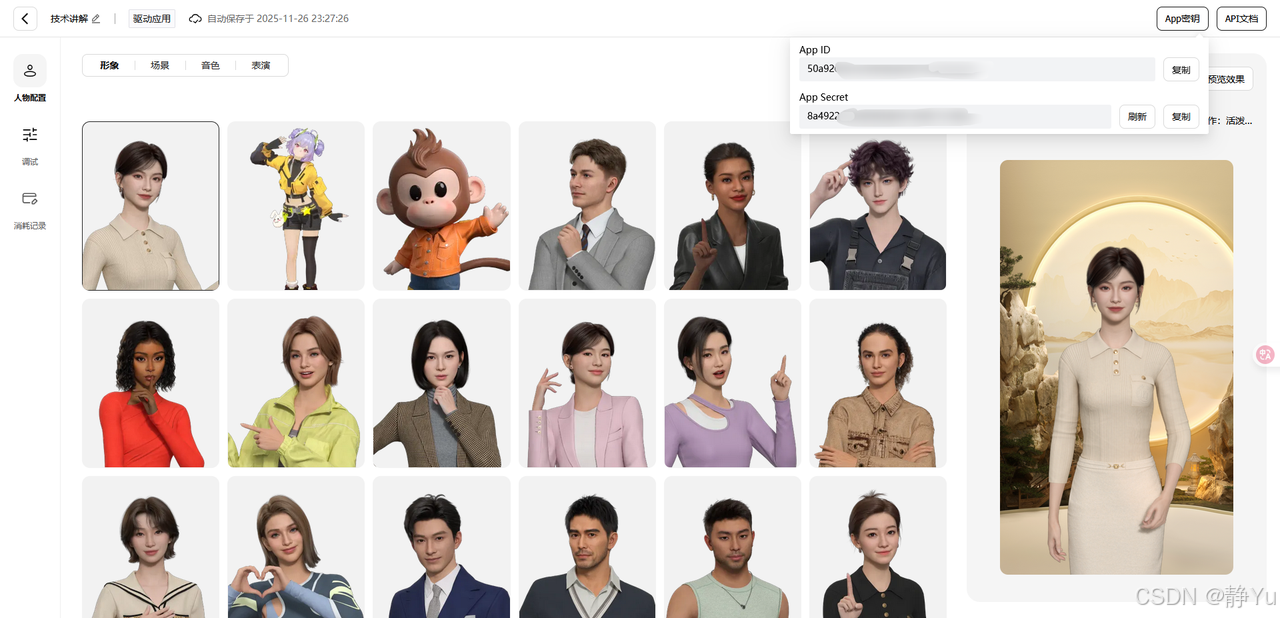
使用填写的 appId 和 appSecret 调用connect方法连接虚拟形象服务。配置字幕显示/隐藏和状态变化的回调函数,实时更新全局状态。
async function connectAvatar(){
const { appId, appSecret } = appState.avatar
try {
const avatar = await avatarService.connect({
appId,
appSecret
}, {
onSubtitleOn: (text: string) => {
appState.ui.subTitleText = text
},
onSubtitleOff: () => {
appState.ui.subTitleText = ''
},
onStateChange: (state: string) => {
avatarState.value = state
}
})
appState.avatar.instance = avatar
appState.avatar.connected = true
} catch (error) {
appState.avatar.connected = false
throw error
}
}
connect 方法用于初始化并连接虚拟形象(Avatar)SDK。首先,该方法从传入的配置中解构出 appId 和 appSecret,以及回调函数(包括字幕显示/隐藏和状态变化的处理器)。接着,构建网关 URL 并添加查询参数(如数据源和自定义 ID)。然后,创建一个 Promise(connectPromise)来管理连接状态,并通过 resolve 和 reject 控制其结果。SDK 的构造选项(constructorOptions)包括容器 ID、认证信息、调试配置、网关地址以及事件回调(如处理字幕事件 subtitle_on/subtitle_off 和状态变化 onStateChange)。在创建 SDK 实例(window.XmovAvatar)后,代码通过 setTimeout 等待初始化超时,再调用 avatar.init() 开始初始化,并通过下载进度回调(onDownloadProgress)在进度达到 100% 时解析 connectPromise。初始化完成后,使用 Promise.allSettled 等待连接完成或超时(1 秒),如果连接失败(connectPromise 被拒绝),则抛出错误;否则返回 SDK 实例。整个过程通过多层 Promise 和回调函数确保异步操作的正确顺序和错误处理,最终实现与虚拟形象服务的连接。
async connect(config:any, callbacks:any): Promise<any> {
const { appId, appSecret } = config
const { onSubtitleOn, onSubtitleOff, onStateChange } = callbacks
// 构建网关URL
const url = new URL(SDK_CONFIG.GATEWAY_URL)
url.searchParams.append('data_source', SDK_CONFIG.DATA_SOURCE)
url.searchParams.append('custom_id', SDK_CONFIG.CUSTOM_ID)
// 连接Promise管理
let resolve: (value: boolean) => void
let reject: (reason?: any) => void
const connectPromise = new Promise<boolean>((res, rej) => {
resolve = res
reject = rej
})
// SDK构造选项
const constructorOptions = {
containerId: `#containerId`,
appId,
appSecret,
enableDebugger: false,
gatewayServer: url.toString(),
onWidgetEvent: (event: any) => {
if (event.type === 'subtitle_on') {
onSubtitleOn(event.text)
} else if (event.type === 'subtitle_off') {
onSubtitleOff()
}
},
onStateChange,
onMessage: async (error: any) => {
const state = await getPromiseState(connectPromise)
const plainError = new Error(error.message)
if (state === 'pending') {
reject(plainError)
}
}
}
// 创建SDK实例
const avatar = new window.XmovAvatar(constructorOptions)
// 等待初始化
await new Promise(resolve => {
setTimeout(resolve, APP_CONFIG.AVATAR_INIT_TIMEOUT)
})
// 初始化SDK
await avatar.init({
onDownloadProgress: (progress: number) => {
if (progress >= 100) {
resolve(true)
}
},
onClose: () => {
onStateChange('')
}
})
// 等待连接完成
const [result] = await Promise.allSettled([
connectPromise,
new Promise(resolve => setTimeout(resolve, 1000))
])
if (result.status === 'rejected') {
throw result.reason
}
return avatar
}

断开数字人连接,直接调用disconnect方法,暂停然后销毁之前创建的数字人实例。
disconnect(avatar: any): void {
if (!avatar) return
try {
avatar.stop()
avatar.destroy()
} catch (error) {
console.error('断开连接时出错:', error)
}
}
- llm模块为大模型对接,采用的是openai的接入模式开发者可根据需要替换大模型。例如大模型连接参数:大模型版本、大模型 key。
通过 OpenAI SDK 初始化一个客户端实例,配置了 API 密钥(apiKey)、允许浏览器环境调用(dangerouslyAllowBrowser,通常用于测试或前端直连),并指定了 自定义服务端点(baseURL,我用的是火山引擎的 API 地址)
this.openai = new OpenAI({
apiKey: 'apiKey',
dangerouslyAllowBrowser: true,
baseURL: 'https://ark.cn-beijing.volces.com/api/v3'
})
通过 OpenAI SDK 调用大语言模型(LLM)的聊天补全接口(chat.completions.create),传入对话消息(messages)并指定模型名称(如火山引擎的 “doubao-1-5-pro-32k-250115”),最后从返回结果中提取模型生成的文本内容(choices[0].message.content)。
const completion = await this.openai.chat.completions.create({
messages, //输入的文本内容
model: 'doubao-1-5-pro-32k-250115'
})
//LLM响应内容
const response = completion.choices[0]?.message?.content
通过右侧的消息交互框实现调用大模型,获取大模型返回的文字信息,然后通过调用数字人speak功能,实现数字人讲话。
sendMessage()用于处理用户输入文本并通过虚拟形象(Avatar)流式播报回复。首先检查配置有效性(LLM 的 apiKey、用户输入文本 ui.text 和虚拟形象实例 avatar.instance),若无效则直接返回。通过 llmService.sendMessageWithStream 调用 LLM 服务(如 OpenAI)获取流式响应,若没有响应则退出。等待虚拟形象完成当前播报后,逐块处理返回的文本流:将累积的文本按句子分割,生成 SSML 格式的语音标记,并通过 avatar.instance.speak 分段播报(首句标记为开始,中间句持续播报,末尾空内容标记结束)。若剩余未处理的文本,单独生成 SSML 并播报。最后发送一个空的 SSML 标记播报结束,返回剩余文本缓冲区。
async function sendMessage(){
const { llm, ui, avatar } = appState
if (!validateConfig(llm, ['apiKey']) || !ui.text || !avatar.instance) {
return
}
try {
// 发送到LLM获取回复
const stream = await llmService.sendMessageWithStream({
provider: 'openai',
model: llm.model,
apiKey: llm.apiKey
}, ui.text)
if (!stream) return
// 等待虚拟人停止说话
await waitForAvatarReady()
// 流式播报响应内容
let buffer = ''
let isFirstChunk = true
for await (const chunk of stream) {
buffer += chunk
const arr = splitSentence(buffer)
if(arr.length > 1) {
const ssml = generateSSML(arr[0] || '')
if (isFirstChunk) {
// 第一句话:ssml true false
avatar.instance.speak(ssml, true, false)
isFirstChunk = false
} else {
// 中间的话:ssml false false
avatar.instance.speak(ssml, false, false)
}
buffer = arr[1] || ''
}
}
// 处理剩余的字符
if (buffer.length > 0) {
const ssml = generateSSML(buffer[0])
if (isFirstChunk) {
// 第一句话:ssml true false
avatar.instance.speak(ssml, true, false)
} else {
// 中间的话:ssml false false
avatar.instance.speak(ssml, false, false)
}
}
// 最后一句话:ssml false true
const finalSsml = generateSSML('')
avatar.instance.speak(finalSsml, false, true)
return buffer
} catch (error) {
console.error('发送消息失败:', error)
throw error
}
}
- 上述内容都操作完成之后,就可以开始和数字人对话了,输入文本进行对话。
SDK调用步骤总结:
1.通过script引入SDK依赖
2.在平台系统设置虚拟人角色、音色、表演风格,获取App ID、App Secret
3.通过 new XmovAvatar创建实例
4.调用init({ onDownloadProgress?: (progress: number) => void, })初始化SDK,加载必要资源
5.调用speak(),speak(ssml, is_start, is_end)控制数字人说话
6.不使用时可调用destroy()方法销毁SDK实例,断开连接
完整的项目代码:https://gitee.com/jingyu1205/digital-demo.git
大家快来体验学习体验一下吧!!!
真的被魔珐星云SDK的易用性戳中了!以前开发数字人总要和代码“死磕”到深夜,如今它像一根魔法棒,把动画绑定、语音唇形同步这些“硬骨头”技术悄悄藏进后台——初始化只需填个角色ID,调用接口就像发条微信般自然,甚至能边喝咖啡边用几行代码让数字人又唱又跳。这种把专业能力变成“傻瓜操作”的温柔,不仅治好了我的技术焦虑,更让开发从“苦差事”变成了“创作游戏”,终于能甩开包袱,把全部热情投入到和数字人共舞的奇妙体验里了!
三、产品体验分享:从实验室到真实场景的颠覆性突破
魔珐星云SDK把开发数字人的门槛降到了“地板级”——不用啃技术文档,不用调复杂参数,简单配置就能快速上手。正因如此,它正被越来越多行业用来解锁新场景:从课堂里的虚拟老师到商场里的智能导购,从直播间里的AI主播到企业里的数字客服,SDK用“零压力”的集成方式,让数字人轻松走进真实业务,接下来就一起看看这些生动的应用案例吧。
- 视觉与交互:影视级渲染与低延时并存
- 画质表现:数字人皮肤纹理细腻,光影渲染达到影视级标准,微表情(如眉毛起伏、微笑弧度)随语义动态调整。
- 实时性:500ms内完成云端参数生成与端侧渲染,支持随时打断对话,体验接近真人交流。
- 多终端适配:在浏览器调整窗口大小,数字人渲染无锯齿卡顿,证明其跨端稳定性。
- 场景化测试:覆盖全行业需求
- 政务服务:数字导办员主动问候、手势引导办理流程,减少群众等待时间。
- 教育领域:AI助教在平板端互动授课,支持知识点演示与提问,沉浸式学习效率提升。
- 企业招聘:模拟真实面试场景,数字人根据简历智能提问,面试后提供个性化反馈,降低筛选成本。
- 情感陪伴:AI虚拟男友通过摆臂、轻拍肩膀等动作传递情绪,撒娇语气与肢体语言高度同步。
- 开发者生态:低门槛构建具身智能应用
- API与SDK开放:平台提供全栈数字人能力,开发者可快速集成至App、小程序、Web端。
- 行业解决方案:
- 商显厂商:将广告屏升级为可对话导购,根据顾客表情实时调整推荐。
- 机器人厂商:输出动作参数驱动人形机器人,实现自然服务交互。
- 内容工具:PPT工具自动生成讲解视频,直播平台接入数字人形象支持虚拟直播。
四、技术测评:破解数字人“不可能三角”
传统数字人技术在规模化商用中面临质量、延迟、成本、扩展性四大核心矛盾:受限于预生成动画与云端渲染架构,企业需在“高精度建模与高昂算力成本”间艰难抉择;端到端交互延迟普遍高于2秒,导致用户提问后需长时间等待;同时,单一云端架构难以适配车载屏、低端手机等多元终端,且缺乏对国产信创芯片的兼容,市场覆盖率与政策合规性受限。这些痛点共同制约了数字人从“技术演示”向“生产力工具”的跨越。而魔珐星云具身智能数字人开放平台很好的解决了这些问题。
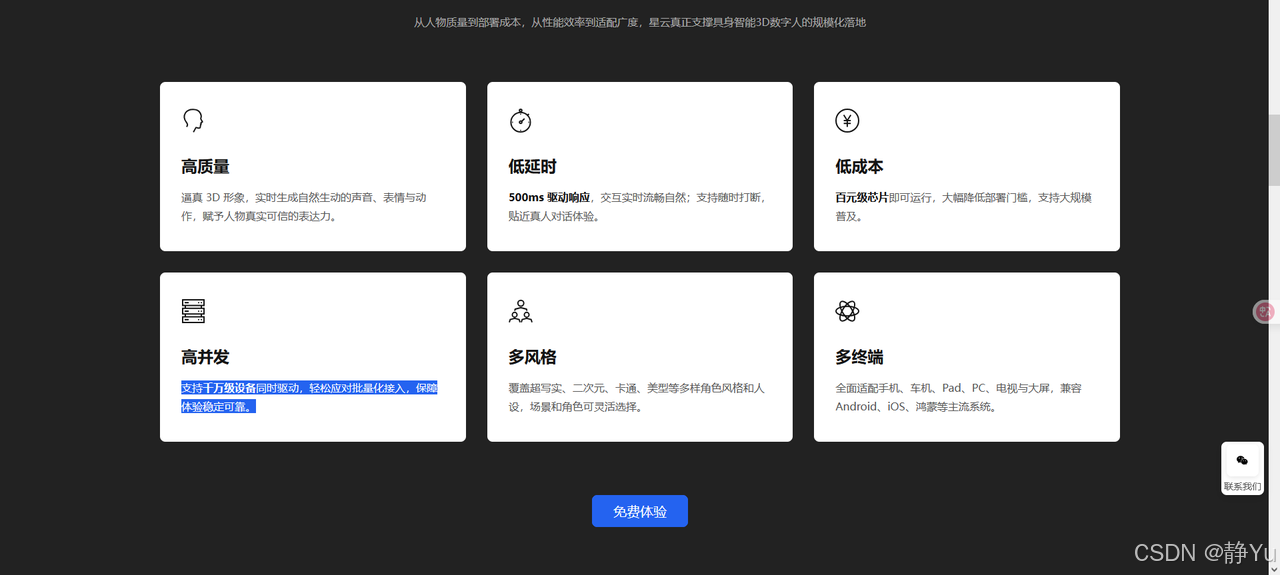
魔珐星云通过文生多模态3D大模型+云-端协同架构,首次实现质量、延迟、成本、并发、终端、信创六大维度的协同优化。
- 高质量:语义驱动生成自然表情与动作,表情丰富度达真人92%,动作流畅度,实现“有灵魂的交互”。
- 低延时:500ms内实时响应,支持随时打断,交互中断恢复率98%,对话流畅度媲美真人。
- 高并发:支持千万级设备同时驱动,轻松应对批量化接入,保障体验稳定可靠,规模化部署无压力。
- 低成本:百元级芯片流畅运行,单数字人年运营成本显著降低,中小企业也能轻松落地。
- 多终端:手机、车载屏、商显大屏全适配,动作精度像素级一致,跨设备交互无缝衔接。
- 信创支持:国产飞腾/鲲鹏/龙芯芯片全兼容,政务、金融等敏感领域自主可控,政策红利加速落地。
五、结论:具身智能时代的入口级平台
星云作为魔珐科技推出的具身智能平台,真正让AI突破了“无形”的边界——它不仅赋予大模型鲜活的数字形象,更让智能交互从“听声辨意”升级为“眼见为实、身临其境”的沉浸式体验。从此,AI不再是屏幕里的文字或耳机中的声音,而是能与你对视微笑、举手投足间传递温度的“数字生命”。星云正以技术之力,重新定义人与AI的连接方式,让未来世界的智能伙伴,既有智慧的大脑,也有触手可及的灵魂。
未来,随着平台对机器人、AR眼镜等更多载体的支持,AI将真正走出对话框,成为虚拟与现实世界中无处不在的交互主体。
心动不如行动,速速来体验一下吧!体验网址:直达入口

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 25
25 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)