揭示GPT-5与人类的差距!李飞飞&李曼玲提出具身智能评估新基准ENACT:以VQA形式评估世界模型
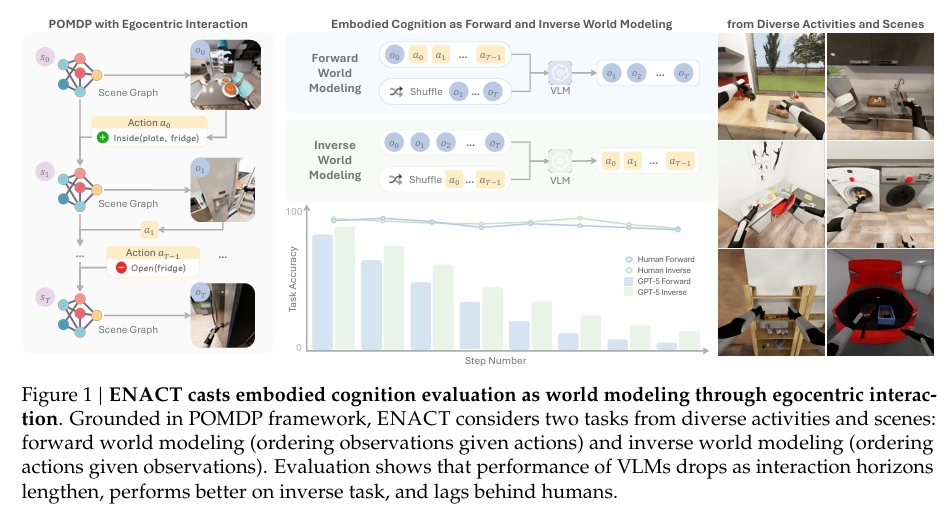
ENACT将VLMs的具身认知评估转化为第一视角交互下的世界建模问题核心空间定义状态空间sss:元素为从模拟器底层状态GGG提取的符号场景图,场景图以“节点(物体/主体,如On(fridge))-边(关系,如OnTop(pen, desk))”结构表征场景语义;观察空间O⊂RH×W×3O⊂RH×W×3:机器人第一视角的RGB图像,记录环境视觉信息;动作空间AAA:元素为场景图差异atδstst−1
李飞飞与李曼玲团队推出具身智能新作——基准测试ENACT,该测试旨在解决视觉-语言模型(VLM)具身认知涌现程度难以量化的问题,其核心是将具身认知评估转化为第一视角交互世界建模的视觉问答(VQA)任务,实验不仅揭示了GPT - 5、GLM - 4.5V等前沿模型与人类之间的显著能力差距,还发现该差距会随交互时长的增加而扩大;值得一提的是,李曼玲现任美国西北大学计算机科学系助理教授,她在斯坦福大学担任博士后研究员期间,导师为李飞飞以及斯坦福大学助理教授吴佳俊。

1. 【导读】

论文标题:ENACT: Evaluating Embodied Cognition with World Modeling of Egocentric Interaction
作者:Qineng Wang*、Wenlong Huang*、Yu Zhou、Hang Yin、Tianwei Bao、Jianwen Lyu、Weiyu Liu、Ruohan Zhang†、Jiajun Wu†、Li Fei -
Fei†、Manling Li
作者机构:1. 西北大学(Northwestern University);2. 斯坦福大学(Stanford University);3. 加州大学洛杉矶分校(UCLA)
论文来源:李飞飞&李曼玲团队
论文链接:https://arxiv.org/abs/2511.20937
项目链接:https://github.com/mll-lab-nu/ENACT
2. 【论文速读】
具身认知理论认为智能源于感知运动交互而非被动观察,李飞飞&李曼玲团队由此提出疑问:以非具身方式训练的现代视觉语言模型(VLMs) 是否展现具身认知迹象?为此,他们引入ENACT基准,将具身认知评估转化为基于第一视角交互的世界建模问题,采用视觉问答(VQA)形式,并基于部分可观察马尔可夫决策过程(POMDP,动作表现为场景图变化)设计两大核心任务——前向世界建模(根据动作重排打乱的观察结果)与反向世界建模(根据观察结果重排打乱的动作),这些任务需VLMs具备感知可用性识别、动作-效果推理等具身认知关键能力,同时规避可能干扰评估的低层次图像合成需求。该基准通过机器人仿真平台(BEHAVIOR)构建可扩展数据生成流程,生成涵盖家庭场景长时活动的8972个QA对;实验结果显示,前沿VLMs与人类存在显著人机性能差距,且该差距随交互时长增加而扩大,VLMs在反向世界建模任务上表现始终优于前向任务,并存在人类中心偏差(如偏好右手动作、相机内参或视角偏离人类视觉时性能下降)。
3.【具身智能评估困局破局:VLMs的认知能力丈量之旅】
3.1 研究背景
- 理论基础:具身认知理论指出,智能源于主体与环境的感知运动交互,而非被动观察,这一理论为评估AI模型的真实认知能力提供了核心依据。
- 现有模型矛盾点:当前主流视觉语言模型(VLMs)多采用非具身方式训练,虽已展现出一定的交互智能潜力,但学界尚未明确其具身认知能力的涌现程度,缺乏有效的量化手段。
- 过往研究缺陷:此前相关研究仅聚焦具身认知的单一维度,如静态场景空间感知、基础物体交互推理等;部分分类体系依赖主观标准,缺少能将第一视角感知与日常具身交互紧密结合的统一客观评估框架。
- 研究需求:亟需构建一个标准化基准,以精准衡量VLMs在长时程、日常场景中所需的核心具身能力,如可用性识别、动作-效果推理、长时记忆等。
3.2 相关工作
- 具身认知研究
- 核心围绕主体的空间感知、物理交互与语言抽象能力展开,以部分可观察马尔可夫决策过程(POMDP)为常用框架。
- 现有研究多枚举单一能力,缺乏通过第一视角交互进行世界建模的统一评估视角,且难以通过可控、可复现的方式对比模型与人类的表现。
- 世界建模研究
- 主流方向是学习动作驱动的动态变化,用于想象与规划,部分模型侧重视频生成保真度和长时预测,但存在局限。
- 现有基准或聚焦视觉丰富场景的控制与预测质量,或关注非交互视觉数据的物理场景理解,缺乏针对动作与观察序列排序的专项评估,且难以支撑复杂推理需求。
- VLMs在具身AI中的应用研究
- VLMs常作为具身智能体的高层规划器或端到端策略模型,广泛应用于机器人控制等场景,但当前应用多局限于无需复杂推理的简单任务。
- 现有基准侧重指令跟随和目标条件控制,对长时程交互中关键的多步因果推理能力关注不足,且缺乏明确的场景图动作空间定义。
4.【ENACT方法论:解锁第一视角交互的具身认知评估密码】
4.1 问题形式化定义:基于POMDP的具身世界建模框架
ENACT将VLMs的具身认知评估转化为第一视角交互下的世界建模问题,并基于部分可观察马尔可夫决策过程(POMDP)进行形式化定义,核心包含三大空间与两类核心任务:
- 核心空间定义
- 状态空间sss:元素为从模拟器底层状态GGG提取的符号场景图,场景图以“节点(物体/主体,如On(fridge))-边(关系,如OnTop(pen, desk))”结构表征场景语义;
- 观察空间O⊂RH×W×3O \subset \mathbb{R}^{H \times W \times 3}O⊂RH×W×3:机器人第一视角的RGB图像,记录环境视觉信息;
- 动作空间AAA:元素为场景图差异at=δ(st,st−1)a_t = \delta(s_t, s_{t-1})at=δ(st,st−1),即相邻状态间的语义变化(如“冰箱从关闭变为打开”)。
- 两类核心任务(序列重排VQA)
- 前向世界建模:给定初始观察o0o_0o0、有序动作序列(a0,...,aL−2)(a_0, ..., a_{L-2})(a0,...,aL−2)和打乱的未来观察O′=(o1′,...,oL−1′)O'=(o_1', ..., o_{L-1}')O′=(o1′,...,oL−1′),模型需输出排列σ∈Sym([L−1])\sigma \in Sym([L-1])σ∈Sym([L−1]),使(oσ(1)′,...,oσ(L−1)′)=(o1,...,oL−1)(o_{\sigma(1)}', ..., o_{\sigma(L-1)}')=(o_1, ..., o_{L-1})(oσ(1)′,...,oσ(L−1)′)=(o1,...,oL−1);
- 反向世界建模:给定初始观察o0o_0o0、有序观察序列(o1,...,oL−1)(o_1, ..., o_{L-1})(o1,...,oL−1)和打乱的动作A′=(a0′,...,aL−2′)A'=(a_0', ..., a_{L-2}')A′=(a0′,...,aL−2′),模型需输出排列τ∈Sym([L−1])\tau \in Sym([L-1])τ∈Sym([L−1]),使(aτ(1)′,...,aτ(L−1)′)=(a0,...,aL−2)(a_{\tau(1)}', ..., a_{\tau(L-1)}')=(a_0, ..., a_{L-2})(aτ(1)′,...,aτ(L−1)′)=(a0,...,aL−2)。

4.2 关键帧轨迹合成:高效构建长时程交互数据
为解决原始机器人轨迹中“无语义变化帧冗余”问题,ENACT设计分阶段关键帧轨迹合成流程,实现数据的规模化与高质量:
- 分段帧提取(筛选有语义变化的帧)
- 标记模拟器状态发生“最小抽象变化”的时间戳ttt(如“机器人从未抓取变为抓取钻头”),仅保留场景图差异δ(st,st−1)≠∅\delta(s_t, s_{t-1}) \neq \emptysetδ(st,st−1)=∅的帧;
- 引入余弦相似度过滤:将帧间状态变化转化为“变化签名”cjc_jcj,仅保留与前一接受帧签名相似度低于0.97的帧,避免近重复帧,最终得到时序分段帧集合K={t1<⋯<tM}K=\{t_1<\cdots<t_M\}K={t1<⋯<tM}。
- 关键帧轨迹采样(构建POMDP实例)
- 从MMM个分段帧中采样长度为LLL的轨迹π=(i0,...,iL−1)\pi=(i_0, ..., i_{L-1})π=(i0,...,iL−1)(1≤i0<⋯<iL−1≤M1 ≤i_0<\cdots<i_{L-1} ≤M1≤i0<⋯<iL−1≤M),需满足:相邻帧间可见状态变化ΔVis(sik+1,sik)≠∅\Delta_{Vis}(s_{i_{k+1}}, s_{i_k}) \neq \emptysetΔVis(sik+1,sik)=∅(仅保留视觉可验证的变化);
- 采用“DAG+动态规划”高效采样:将分段帧视为节点,有效状态变化视为有向边构建DAG,通过DP[ℓ,i]=∑j<iDP[ℓ−1,j]⋅EjiDP[\ell, i] = \sum_{j<i} DP[\ell-1, j] \cdot E_{ji}DP[ℓ,i]=∑j<iDP[ℓ−1,j]⋅Eji(EjiE_{ji}Eji为边存在标识)计数有效轨迹,再加权回溯采样确保无偏性。
4.3 世界建模QA生成:转化为序列重排VQA任务
将关键帧轨迹转化为视觉问答(VQA)形式,既规避低层次图像合成对评估的干扰,又聚焦VLMs的长时程交互推理能力:
- QA构建逻辑
- 前向世界建模QA:输入“初始观察+有序动作+打乱的未来观察”,提问“打乱观察的正确顺序是什么?”;
- 反向世界建模QA:输入“初始观察+有序观察+打乱的动作”,提问“打乱动作的正确顺序是什么?”。
- 设计优势
- 强制模型推理“动作-观察”的因果关系(如“打开冰箱”动作对应“冰箱门开启”的观察变化);
- 需维持第一视角下的长时空间记忆(如在家庭场景中跟踪物体位置变化)。
4.4 数据集与评估设计:标准化具身认知度量
- 数据集构建
- 来源:基于BEHAVIOR机器人模拟器的29项长时程家庭活动轨迹,提取对齐的“场景图-观察”对;
- 规模:覆盖L∈{3,...,10}L \in \{3,...,10\}L∈{3,...,10}(交互步数),每种QA类型(前向/反向)每步采样约560项,共8972个QA,包含“Open”“Grasping”等11类常用谓词。
- 评估指标与验证逻辑
- 任务准确率(TA):衡量全序列精确排序,若在线验证器接受预测排列则得1分,否则0分,公式为TA=1∣D∣∑x∈D1{accepted(x)}TA=\frac{1}{|D|} \sum_{x \in D} 1\{accepted(x)\}TA=∣D∣1∑x∈D1{accepted(x)};
- pairwise准确率(PA):衡量相邻步骤一致性,计数通过局部验证的相邻对占比,公式为PA=∑x#correct pairs in x∑xLxPA=\frac{\sum_{x} \#correct\ pairs\ in\ x}{\sum_{x} L_x}PA=∑xLx∑x#correct pairs in x;
- 在线验证器:支持“语义接受”(如前向任务需预测观察包含参考的可见变化,反向任务需预测动作是参考变化的子集),避免刚性数值匹配。

5.【ENACT实验揭秘:VLMs的具身认知能力究竟差在哪?】
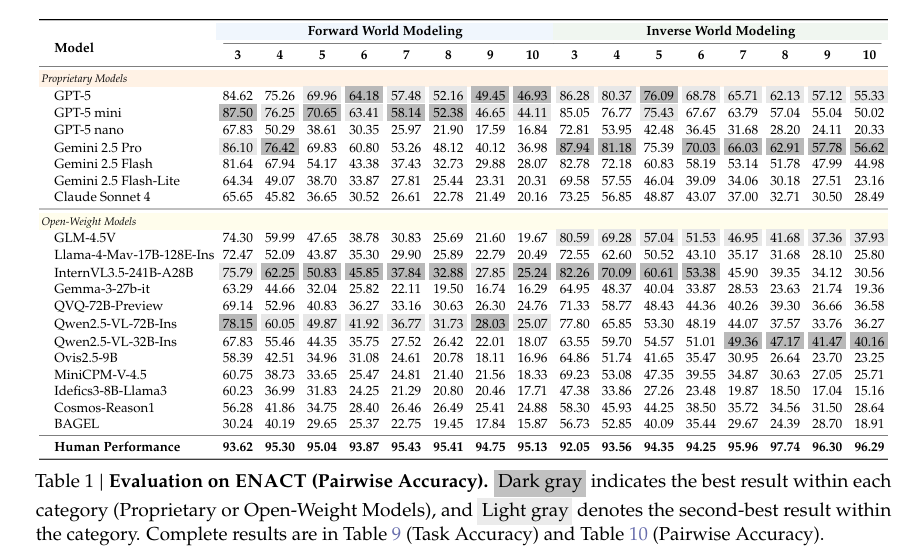
5.1 核心世界建模任务表现:反向优于前向,人机差距随步数拉大
- 任务不对称性:所有VLMs(含GPT-5、GLM-4.5V等)在反向世界建模任务上表现始终优于前向,且差距随交互步数LLL扩大(如GPT-5在L≥6L≥6L≥6时,反向 pairwise准确率比前向高5%-8%),反映模型更擅长“从观察推动作”的回溯推理,而非“从动作推观察”的前瞻视觉模拟。
- 步数敏感性:所有模型准确率随LLL单调下降——L≤4L≤4L≤4时部分VLMs(如GPT-5、Gemini 2.5 Pro)表现尚可(前向 pairwise准确率75%+),L≥8L≥8L≥8时即使最强模型(如GPT-5)前向准确率也降至50%以下,而人类在L=10L=10L=10时仍保持95%+的 pairwise准确率。
- 模型排名与特色: proprietary模型中GPT-5和Gemini 2.5 Pro表现最强;开源模型中InternVL3.5-241B-A28B、GLM-4.5V竞争力突出,甚至超过Claude Sonnet4;Cosmos-Reason1(经具身数据训练)在L>5L>5L>5时比同规模模型更稳定。
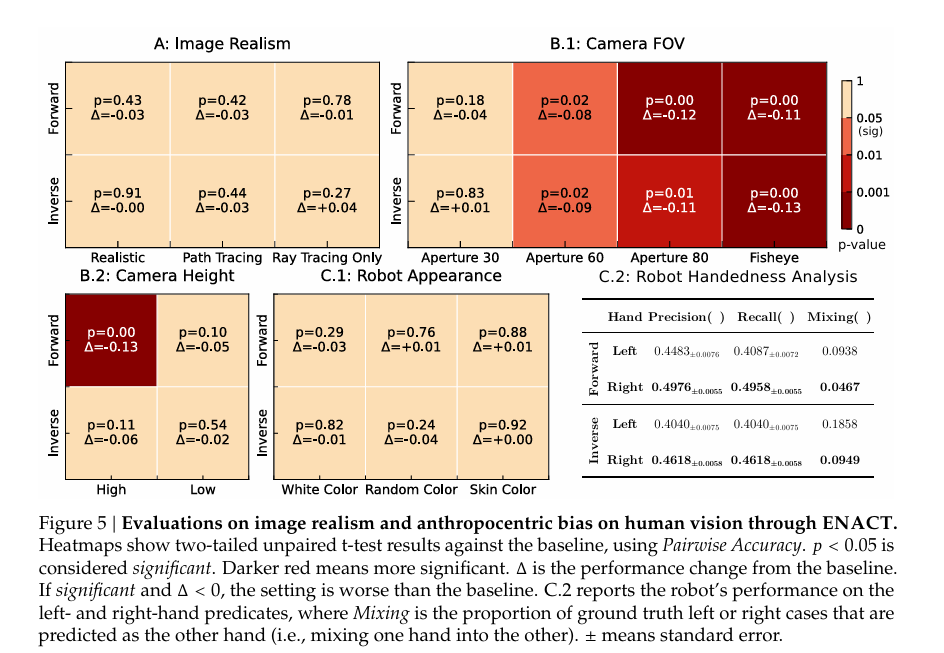
5.2 图像真实感敏感性:渲染方式不影响,虚实差距极小

- sim-to-real一致性:InternVL3.5-241B-A28B在真实世界(960个QA)与模拟器中的表现趋势完全一致——反向任务优于前向、准确率随LLL下降,且绝对准确率差异<5%,无显著sim-to-real gap。
- 渲染方式无影响:对比光线追踪(基线)、路径追踪(高保真)、光线追踪仅(无全局效果)等渲染方式,GPT-5 mini和InternVL3.5-241B-A28B的 pairwise准确率变化Δ<0.05\Delta<0.05Δ<0.05,且p≥0.2p≥0.2p≥0.2,说明VLMs在世界建模任务中不受低层次图像真实感干扰,瓶颈在多步交互推理。

5.3 人类视觉偏差:非人类视角让VLMs“看不清”
- 相机FOV影响显著:基线为光圈40,光圈30(小偏差)对性能无影响(p>0.1p>0.1p>0.1),但光圈60、80及鱼眼镜头(大偏差)会导致性能显著下降(p≤0.01p≤0.01p≤0.01),如GPT-5 mini在鱼眼镜头下前向 pairwise准确率降Δ=−0.12\Delta=-0.12Δ=−0.12,反映模型依赖人类视角内参。
- 相机高度影响分化:高相机高度(+0.5m,超人类 eye-level)使GPT-5 mini前向准确率降Δ=−0.13\Delta=-0.13Δ=−0.13(显著),反向任务仅降Δ=−0.06\Delta=-0.06Δ=−0.06(不显著);低高度(-0.25m,人类视角范围内)对两者均无显著影响,说明模型对“超出人类常规视角”的高度敏感。
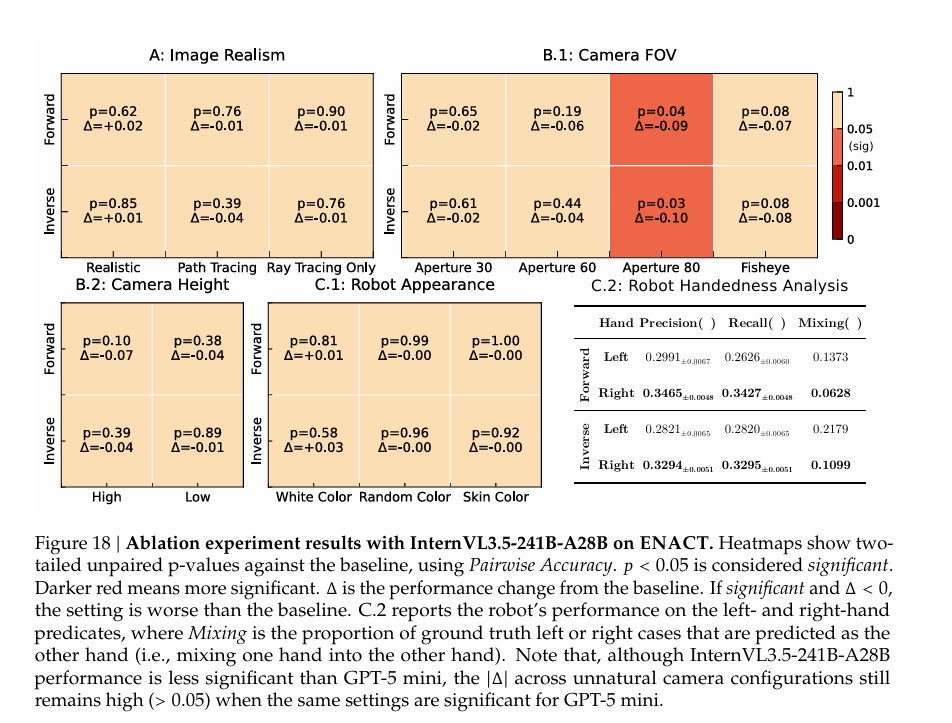
5.4 具身偏差:机器人外观不敏感,却有明显右手偏好
- 机器人外观无影响:改变机器人颜色(白色、随机色、肤色),GPT-5 mini和InternVL3.5-241B-A28B的性能变化Δ<0.05\Delta<0.05Δ<0.05且p>0.1p>0.1p>0.1,说明模型对自身具身外观的视觉表征不依赖特定颜色,仅关注交互逻辑。
- 右手偏好显著:所有VLMs对右手动作的精确率、召回率均高于左手(如GPT-5前向任务中,右手精确率49.76% vs左手44.83%),且左→右混淆率(9.38%)远高于右→左(4.67%),与人类89%右利手的分布一致,体现人类中心偏差。
5.5 错误分析:遗漏与幻觉是主要“失分点”
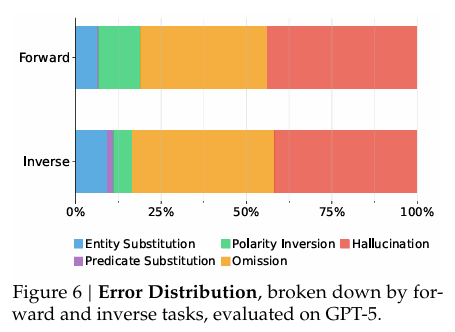
- 错误类型集中:以GPT-5为例,前向任务中“遗漏(37.1%)+幻觉(43.9%)”占总错误的81%,反向任务中两者各占41.8%,合计83.6%,说明模型核心问题是“无法准确识别哪些状态变化发生/未发生”,而非误解变化细节(如实体替换、极性反转仅占10%以下)。
- 任务差异:前向任务中幻觉更突出(43.9% vs反向41.8%),反向任务中实体替换略多(5.4% vs前向6.3%),反映前向任务中模型更易依赖文本先验“编造”变化,反向任务中更易混淆动作关联的物体。
6.【ENACT:VLMs具身认知的“体检报告”与未来修炼路】
李飞飞等人提出ENACT基准,将VLMs的具身认知评估转化为第一视角交互下的前向/反向世界建模序列重排VQA任务,基于BEHAVIOR模拟器生成8972个QA并完成实验;结果显示,VLMs在反向任务上表现优于前向,与人类的性能差距随交互步数扩大,且存在右手偏好、人类视角依赖等偏差,推理错误主要源于状态变化的遗漏与幻觉。研究存在局限:诊断任务未穷尽、评估受计算成本限制仅覆盖部分模型与数据、未探索VLM微调;未来ENACT可作为 extensible工具拓展至更多具身场景,其自动化数据集也有望助力提升VLMs的具身世界建模能力,推动更贴近人类的具身AI发展。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 17
17 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)