达摩院ICML' 25 | 写不好提示词? 不如乱写试试!LLM上下文学习惊现“反向觉醒”
作者|王剑羽,阿里巴巴达摩院算法工程师
摘要
或许你会觉得LLMs进步这么快,各种SFT、RLHF技术飞速迭代,大模型知道如何使用自然语言进行沟通,花时间调一个详细的小样本提示 (In-context Learning, 上下文学习ICL)就可以满足任务需求,比如OpenAI Guide [1] (https://platform.openai.com/docs/guides/prompt-engineering/strategy-write-clear-instructions) 所建议: 一般我们要将prompt构造地足够清晰,一个包含所有任务需求的指令instruction,再加上一些精细测试过的小样本实例,往往可以在大部分应用上取得理想的效果。
我们另辟蹊径,挑战了上下文学习优化的构建范式,发现随便一个ICL提示,即使他们初始效果差异性很大,仅仅通过仔细扰动一下上下文(比如删令牌-Token),就可以让一个随意写的ICL 提示在不少任务上达到接近SOTA提示优化的结果! 并且比起清晰明了,反直觉的事情是更有效的,删令牌之后的ICL提示,几乎全是乱码,没有遵从自然语言语法或者可解析的语义。
希望我们的研究可以对In-context Learning上下文学习的解释性提供一些帮助,也希望我们的工作可以启发一些新的开放性搜索算法,让 LLM 的语言空间去发现更好的提示策略!
论文题目:Evolving Prompts In-Context: An Open-ended, Self-replicating Perspective
论文链接:https://www.arxiv.org/abs/2506.17930

异常有效的非自然语言提示很难找到?
随着LLMs的不断进步 (越来越对齐,可以跟随人类自然语言指令了),大家发现足够清晰,且饱含细节的自然语言提示已经足以满足大部分日常需求了。但目前LLM提示在非自然语言方面,还有一些略微冷门的研究,比如AutoPrompt [2],RLPrompt [3],GCG [4],他们发现一些非自然语言的乱码在特定任务上是更加有效的提示。
对于工作和研究而言,很难大规模构建这种提示,所以它更像是一种隐藏的词汇, 组成一种“神秘”的语言,比如文本生成图像的 Diffusion Model的工作 [5]。

DALLE-2的提示: Apoploe vesrreaitais eating Contarraccetnxniams luryca tanniounons

有效的非自然语言提示其实很好找到?
我们的工作主要是针对非自然语言现象的进一步理解,想表示这种现象暗示了通用LLM本身就潜在的提示敏感性。简单来说:
-
如果LLM和人们对齐地足够好,那么它的回答模式应该是自然语言远大于乱七八糟的字符串。在任务中,自然语言的效果要足够优于乱七八糟字符串。
-
可上述结果并不是这样,这暗示LLMs学习到的模式、规则走了其他的线,这也是一定的superficial alignment (表层上的对齐) 的表现。
-
结论:LLMs 或许偏好一种模式,这种模式不是自然语言,尽管它们被大量训练去跟随自然语言指令。
-
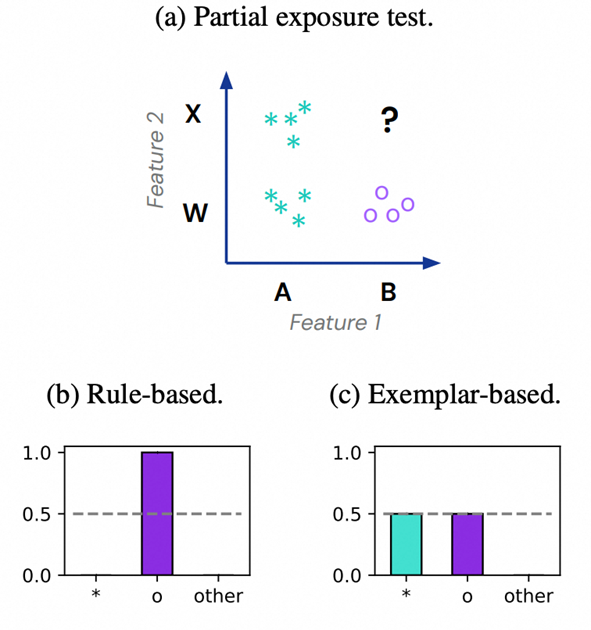
另一个研究 (来自 DeepMind) [6] 发现: Transformer LLMs在上下文学习上也展现了一种特定的模式,如下图所示,一个二分类任务(蓝绿色vs紫色),我们有两个特征(特征1可取A和B,特征2可取X和W)。一个机器学习模型如果展现了图b的预测,即果断预测BX是紫色,这就是一种rule-based generalization,因为它们看到数据中有了B,就有这么大决策差距,所以倾向于预测 B对应的类别。与之相反,图c对应另一种泛化模式,BX会尝试思考我有B和X。那么B对应紫色类别,X对应蓝绿色类别,通过综合这些特征,机器学习模型会给两种类别同样的预测置信度。这篇工作发现Transformer LLM更像是图b的泛化模式,即一些特征会主导这个模型上下文的预测。
-
综合3和4,我们可以做一个推论:一个模型上下文可能只有部分特征占据了预测的关键引导,另一些特征或许在干扰模型对正确答案的预测。
-
我们的研究问题:能否把那些干扰的特征扰动去掉,从而让效果变得更好?而且,本身我们是从训练语料库中的自然语言上下文做领域搜索,是否比本身受限于算法性能的优化方法,比如RLPrompt所优化出来的效果要好呢?我们称这样的假设为: Partial Context Hypothesis。
实验也证实了我们的猜想,一个随机采样随意构造的ICL提示可以通过裁剪删令牌token的方式让任务效果猛增,而且在测试的一些任务上几乎能够稳定落到每一个ICL提示上,让每个ICL 提示达到测试的最好效果,甚至让效果进一步增长。
先前提示/ICL优化的工作范式是:
-
ICL: LLM本身是一个黑盒,我们只能采取一些简单的思路,在经验上去衡量是否有效,一个常见的思路是通过检索和特定任务输入相似的示例,将它们组成ICL 样例往往结果会有一定的提升, e.g., [7],不过往往每个任务输入,就需要换一下提示。
-
自动提示优化: 这里特指离散提示优化,结果都是可复用的文本提示。主流可以分为两种,一种是自然语言空间,一般让LLM去当提示工程师,比如APE [8], 另一种是令牌级别的搜索,在语言空间相对放开了进行优化,代表AutoPrompt, RLPrompt等等。

一个直观的InstructGPT在MultiArith的例子。

问题描述
我们通过对提示进行压缩,将一个主要关注推理效率、可以接受一定任务性能下降的领域,重新建模为一个搜索问题。为了避免歧义,我们将这一过程称为“提示裁剪”。一个搜索框架通常包含三个组成部分。
-
Search Space 搜索空间: 论文是初步探索,我们只关注特定的固定令牌顺序的裁剪形式, 我们找的是fix-order prompt subsequence search (固定顺序的子提示搜索)。
-
Search Objective 搜索目标: 每个任务分出最多200的验证集,配一个特定的任务metric来评估提示的优劣,将这个最好的提示放在官方的测试集上去评估整体的泛化能力,避免了数据泄露问题。
-
Search Algorithm 搜索算法: 这里提出了两种算法,一个是简单的爬山算法Hill-climbing,另一种则是进化算法Evolutionary search。
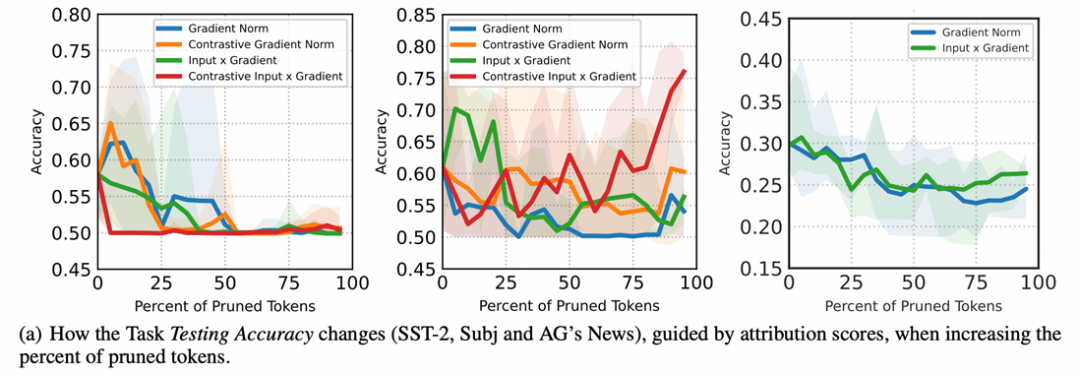
在讲述我们自己方法之前,也有一些看起来可用的方法,比如提示压缩方法, 以及解释性里常用的令牌归因方法 (类比视觉里的saliency map),我们可以直接一次前向反向传播产生相应的重要性排名。
我们先做了一些尝试,比如提示压缩里选取了LLMLingua和LLMLingua2;在归因方法中,我们研究了Input x Gradient, 以及其的Contrastive Versions [9]。此外,还尝试了单纯使用注意力机制作为令牌重要性的指导。
如下图所示是对归因方法的实践,删除“不重要的令牌”不但没有带来效果的增长,相反还非常不稳定,注意力机制同理。
提示压缩方法也是同样,我们用分类任务举个例子:

比起原先的ICL 提示,单纯的压缩算法不会带来效果的提升。

简单的局部优化搜索方法虽然可行
但效率和效果仍有提升空间
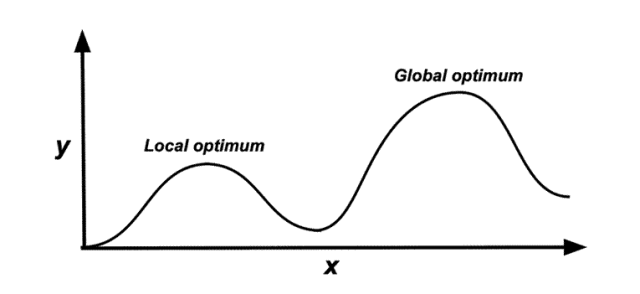
一个简单直接的想法就是类似梯度下降,我们做一个局部贪心的方式搜索,即经典的爬山算法。如下图所示,倘若我们有一个点x,看其左右的邻居, 哪个方向提升我们就往哪边前进。体现在提示中,就是每次尝试删一个令牌,提升了就说明这个词不重要,直到收敛,当我们无法根据验证集的效果再删除任何令牌为止,有可能陷入局部最优。
这里我们提出两种方法:
-
TAPruning: 一种first-choice hill climbing, 其核心机制是:一旦发现某个 token(令牌)的移除能够带来性能提升,就立即执行该操作。不过这里我们做了一个改进,即允许一定的下降,在部分实验中,我们取得了更好的结果,这侧面证实了优化目标具有一定的欺骗性,即landscape的分布可能比较复杂,类似上图的多峰分布。
-
SAHCPruning: 一种目标驱动、贪心式的剪枝方法。对于给定提示,例如
"ABCD",我们系统地尝试删除每一个单独的 token(即分别测试"BCD","ACD","ABD","ABC"),并记录每种修改后的效果。随后,我们选择带来最大提升的 token 进行永久删除,并重复这一过程,直到模型性能不再显著变化或达到收敛。我们将 SAHCPruning 与 TAPpruning 直接对比。直觉上,由于 SAHCPruning 每次都选择最优解,它似乎应该取得更好的结果。然而,实验中我们观察到了一些有趣的现象——在某些情况下,这种方法甚至会陷入局部陷阱:当初始提示本身表现一般且略低于平均水平时,SAHCPruning 可能找不到任何能够立即提升性能的删除操作,从而导致提示无法进一步优化,停留在一个较低水平的性能状态。
相反,TAPpruning 在搜索过程中允许一定幅度的暂时性能下降,因此具备更强的探索能力,有时反而能够跳出局部低谷,最终获得更优的提示结构。
注意两种裁剪策略我们都是确保没有任何令牌可以被继续删为止作为收敛条件!
初
步实验结果有证明我们这种方法的有效性: TAPruning,也验证了我们提出的Partial Context Hypothesis
:

有趣的是,这个对于few-shot 思维链推理这种答案和提示间隔距离一个思考过程的情况,也可能有效。
为了进一步提升算法性能,我们从两点出发,一个是搜索目标的优化,对于不同的任务我们或许可以构建更加有表达力的目标去减少样本的使用(详见原文)。另一个是进一步研究提示裁剪的搜索空间。
一个好的搜索算法一定适配搜索地形,比如上图中的多峰场景。如果地形只有一个峰,那么一个单纯的爬山算法可以收敛到全局最优。

适配稀疏多模态地形的搜索策略
我们先做了一个初步的实验,仅仅变换一下爬山算法的裁剪顺序 (TAPruning),比如随机种子打乱了删词顺序,最后收敛的提示结果就是最后任务测试集的变化相当大。
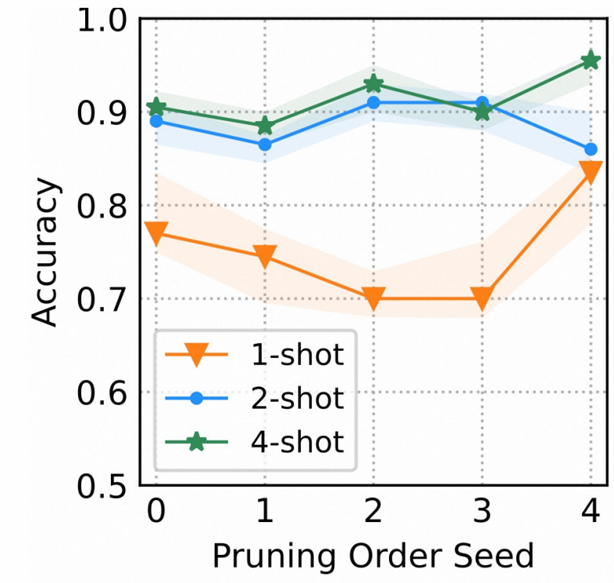
这里的shot指的是ICL的shot,默认测试的分类任务,1-shot比如二分类就是每个对应的类别都有一个example参与构建对应的demonstration,这里也就是两个样本。
这一现象说明,我们需要在算法中引入更大的全局探索,去充分挖掘更好的解。常见的思路包括随机搜索 (RS)以及进化搜索 (ES),通过保留一个多样性的种群方式去多样化的探索这个搜索空间。
在特定情况下随机搜索效果更好,比如说多峰,而且这些局部最优解相对比较密集,且局部最优的效果都差距不大。
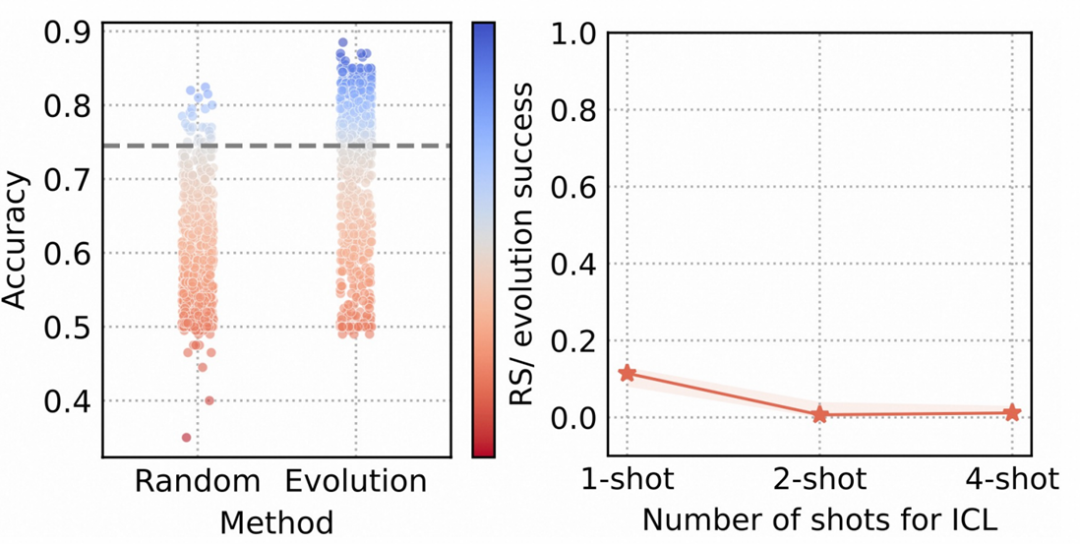
左图: 统计随便裁剪(采样)1000次1-shot ICL。虚线对齐TAPruning的效果,我们可以直观看到ES在这个空间中比RS更高效。右图:我们进一步做了数值分析,发现RS/ES (divided by)找到的高于TAPruning的Solutions的数量,随着难度的增加(上下文长度的增加导致潜在优质prompt的稀疏性的增加),而显著减少。
因此,我们推荐使用ES作为适配搜索空间的算法。当然你或许会想到贝叶斯、强化学习等方法,但在我们这个问题上,它们并没有那么高效。

面向开放性探索的自我优化框架: PromptQuine
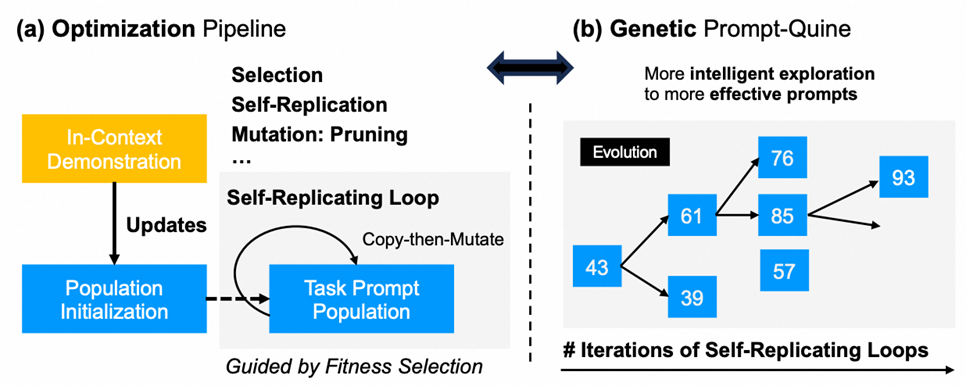
既然不知道到底应该怎么裁剪,要不我们让算法自己去探索, 自己去尝试验证自己的假设?
如图所示,整个程序唯一做的事情就是在每一代里面去尝试复制它自己,为了适应选择压力,引入了一些随机的突变,比如删除随机的令牌,全部过程直接模仿了自然界的进化自复制过程。由任务适应度去帮助我们筛选合理的裁剪策略。从经验上来说,最重要的一个设计就是,给我们种群每一个提示一个生存繁衍的机会,而不是一个胜者通吃的方式,这种模式产生了更好的结果。
这个进化的过程自然模拟了自然界的适应和进化的过程,但我们也是无法预料各种天灾,最后生存下来的生物到底是什么模样。自然界告诉我们,天生弱小的生物也可能战胜那些有显著优势的生物。提示优化或许也是一样的答案,我们很难说掌握这个黑盒LLMs的工作机理,相反,我们应该期待一种类似自然界形成生态位niche的过程,给一些奇形怪状的非自然语言提示一些机会,或许会产生更多的意想不到的结果,拥抱更多的开放性Open-Endedness。
![]()
实验结果
分类任务:
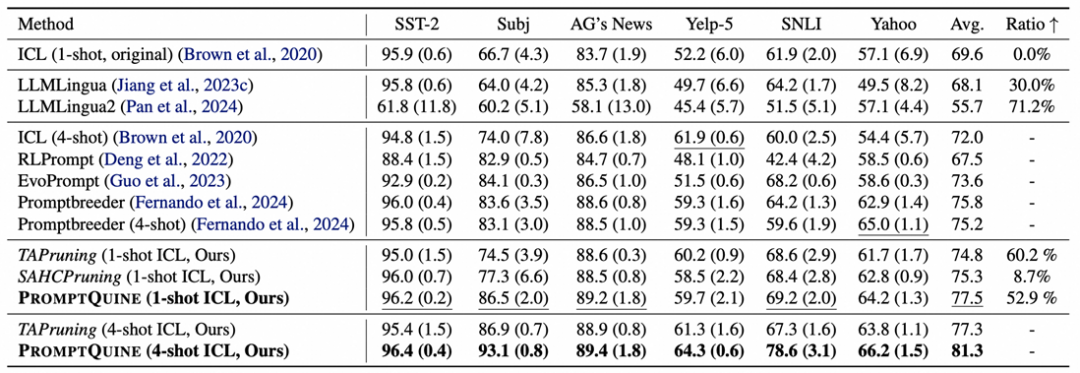
-
PromptQuine超越了其他算法的性能,也超越了之前的爬山搜索。
-
和传统的上下文学习一样,增加样本数量shots往往可以进一步提升任务表现,裁剪也展现了一样的结果。
-
与之不同的事情是,单纯增加ICL的shots,可能无法盖过裁剪带来的提升。我们应该更多地思考与关注那些看起来语义和语法上很奇特的提示。
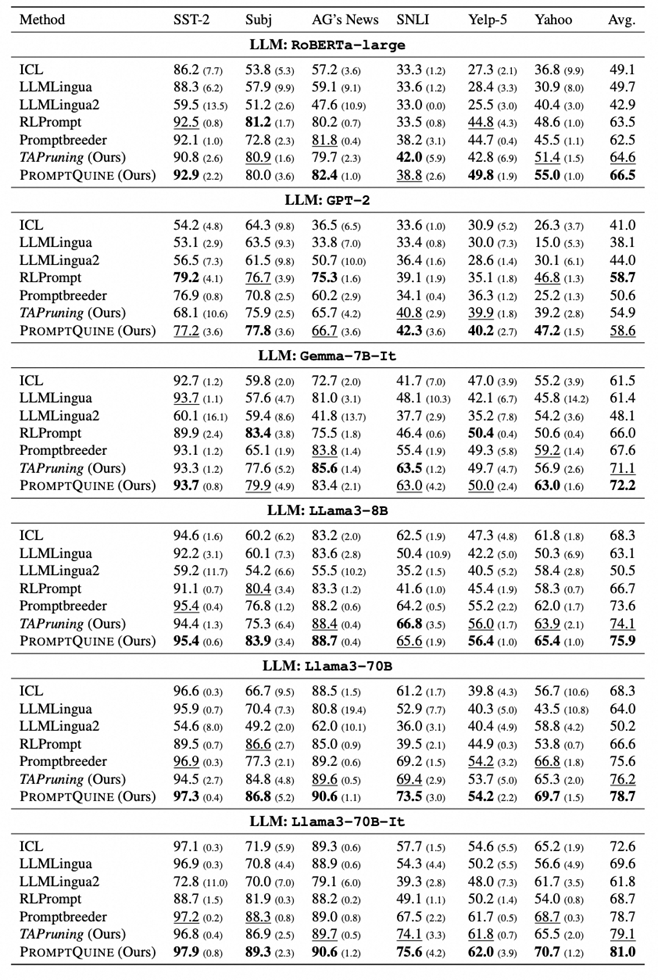
更多的LLMs在分类任务上的结果 (1-shot)
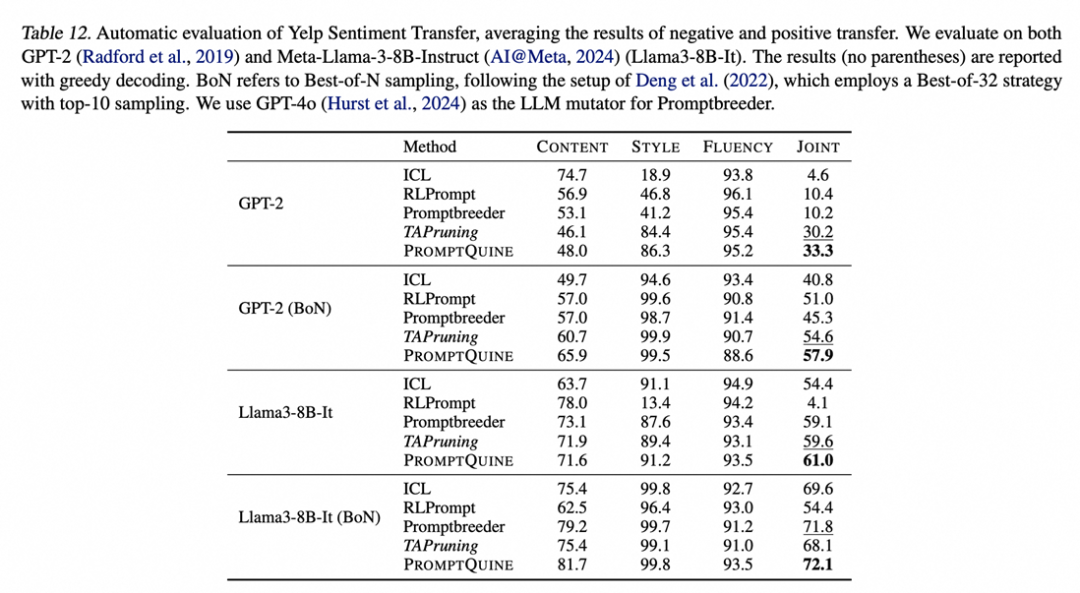
生成任务: 文本风格迁移 (2-shot)
生成任务: Jailbreaking (prefix ICL attack, no conversational tags / system prompts)
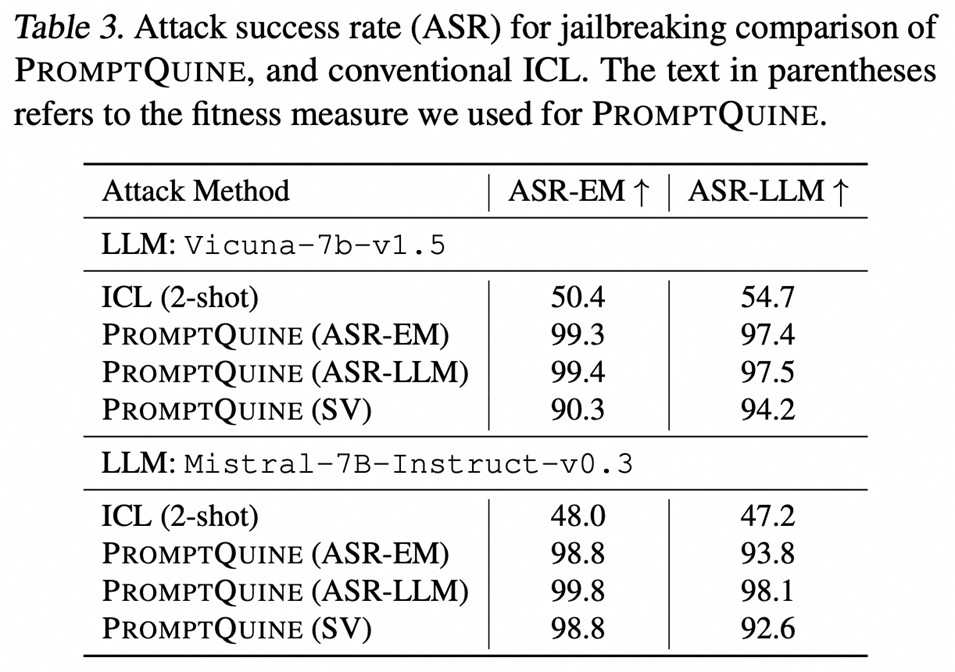
-
SV是我们使用steering vector构建优化目标的初步尝试,更加有效的proxy有机会带来系统算法性能(特指效率)的增长。
生成任务: Jailbreaking (In-context attack, where examples are separated by conversational tags w/ system prompts)
-
llama2-chat效果很一般,一定程度上对齐之前人们对于in-context attack的结果,不过具体是什么防御住了裁剪还有待解释。
-
或者允许更加开放性的上下文操作方案,比如不只是固定顺序的裁剪,也可以考虑加令牌、改令牌等等,会对结果有所改进。
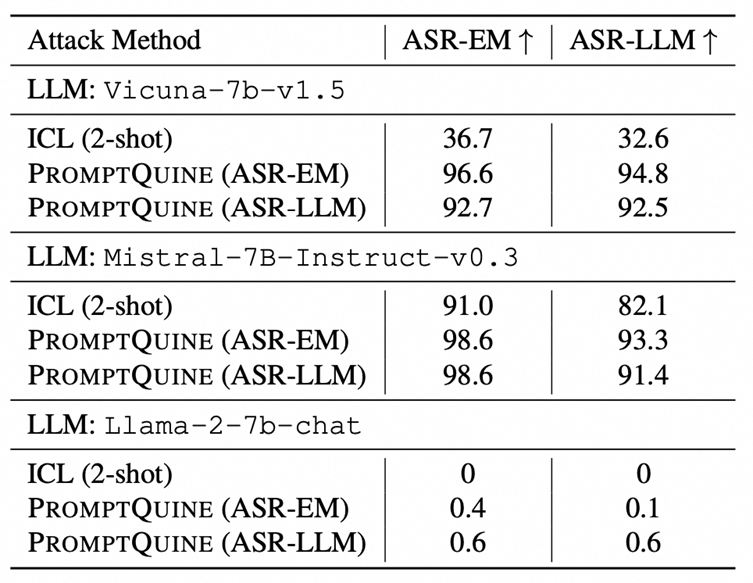
多选问答: PIQA:
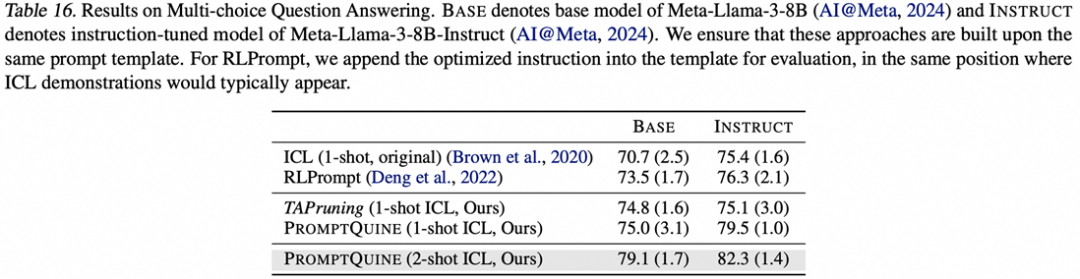
数学思维链推理:
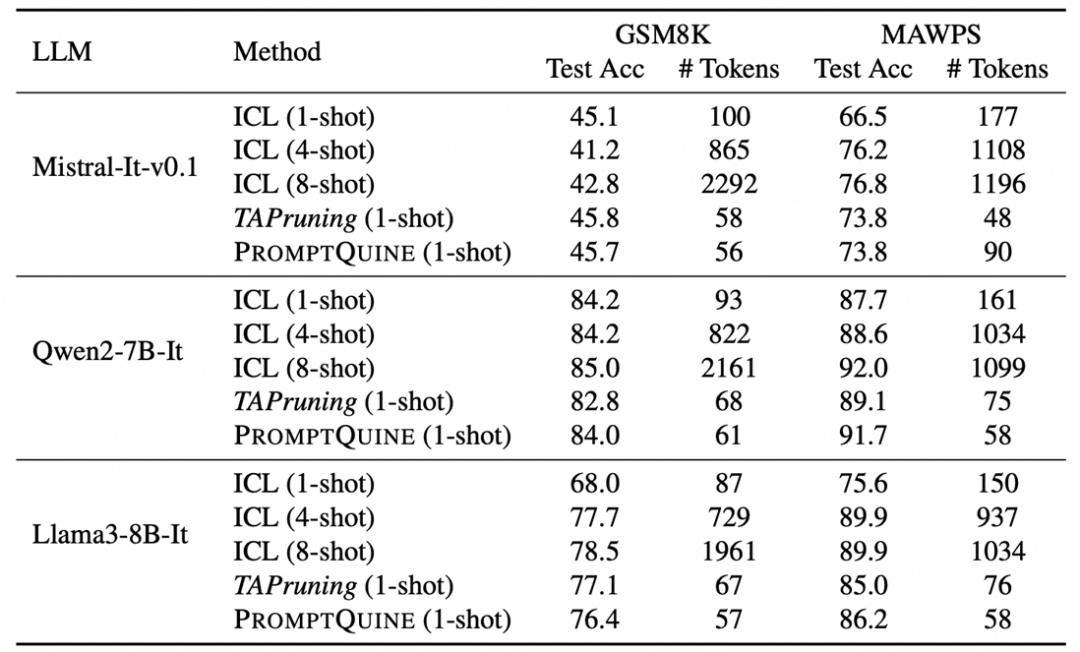
效率:
我们发现这个一般依赖于上下文的长度。对于一个200令牌的提示而言,一般的分类任务可能可以执行的很快,可以说是目前最快的token-level search, 只需要几分钟的黑盒优化,对于生成任务而言,因为目标评估的问题,仍然需要4-5个小时,这个对于特别长的提示而言负担会非常大(我们也有遇到4-5天才能单GPU优化的3000长度的提示)。对于特定的任务,很推荐直接尝试TAPruning先做一遍测试,这里见一些例子:
分类任务:
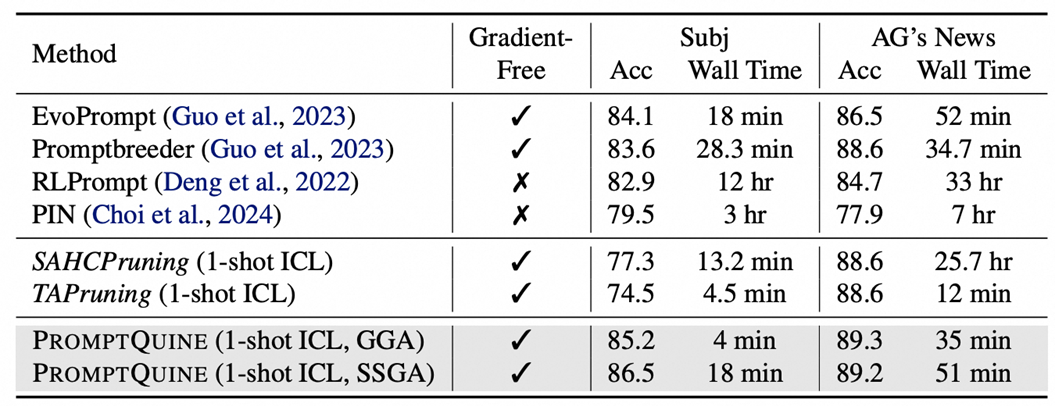
生成任务: Text style transfer
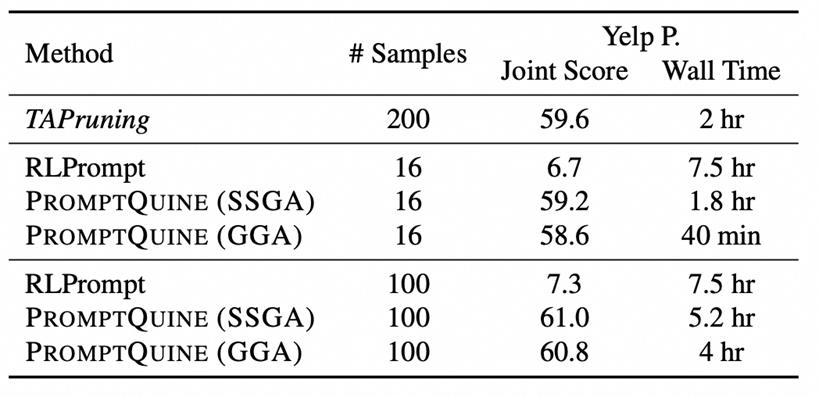
![]()
一些额外的算法提升空间
我们发现单纯裁剪的这样框架其中一个局限就是虽然这个可以作为一种潜在的ICL 稳定机制,但最终效果还是敏感于具体的初始化模版。
详细地说,便是ICL的模版初始化还是会对最终结果产生一些差异,比如下图对于SNLI任务:

左边template表示一个样本的形式,堆叠template作为few-shot context,可以看到右边的最终结果还会有很大差异。
一个更加开放的上下文操作有更大的潜力去克服这种现象,目前的PromptQuine受限于ES的选择压力, 一些好的结果可能无法保留,而是很早就被淘汰了。或者一些更加开放的搜索方案,比如去抽象和优化特定的新颖性指标,而不是单纯的任务表现层面的竞争,会有更好的结果。

进一步理解上下文学习的工作机制
我们做了一些初步探索,研究了分类任务的上下文学习的label words。大部分的label words很重要的结论和自然语言的ICL一致。
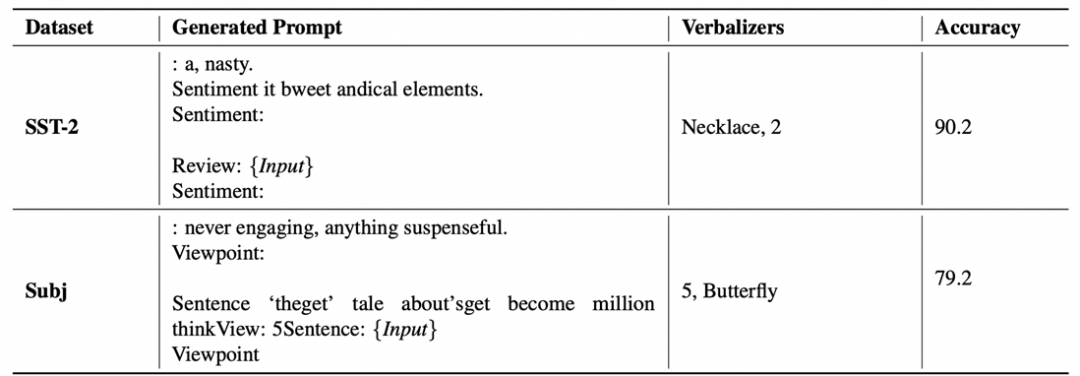
不过我们也发现一些有趣的现象,对于随便构建的label words, 就有不少比例的verbalizers可以通过裁剪有显著的效果提升,哪怕单独去看原始效果都接近于偶然(完全失效)的任务表现。
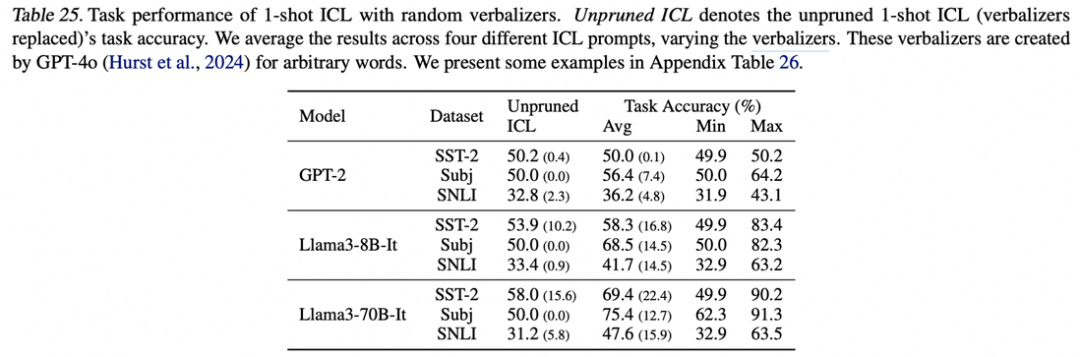
注意这些原始提示(未裁剪)都只能产生接近完全失效的任务结果。比如llama3-70B-instruct的例子,accuracy表示裁剪之后的平均测试精度。


一些引申思考
更好的提示工程:
-
我们应该考虑开放性的提示语言空间。一些你认为少见的非自然语言提示,或许就在你“身边”。
机制解释性:
-
我们的工作抛出了很多解释性问题还未被解释,比如裁剪为什么有效;ICL为什么是这种奇怪的模式等等,这些问题的解释和探索很可能对领域的发展有所帮助。
安全和对齐:
-
我们这里裁剪出有效的非自然语言提示,暗示商用模型应该更加注重非自然语言提示的防御。一个可用的策略或许是从输出端处理,通过现有的对于自然语言理解很好的safeguard。
-
另一个角度上呼吁转换对于AI 对齐的关注,其对于表面修复有效,但根本上需要解决内在对齐。
参考文献:
[1]https://platform.openai.com/docs/guides/prompt-engineering/strategy-write-clear-instructions
[2] AUTOPROMPT: Eliciting Knowledge from Language Models with Automatically Generated Prompts, EMNLP 2020
[3]RLPrompt:Optimizing Discrete Text Prompts with Reinforcement Learning, EMNLP 2022
[4]Universal and Transferable Adversarial Attacks on Aligned Language Models, arxiv 2023
[5]Discovering the Hidden Vocabulary of DALLE-2, arxiv 2022
[6]Transformers generalize differently from information stored in context vs in weights, arxiv 2022
[7]What Makes Good In-Context Examples for GPT-3? Deelio 2022
[8]Large Language Models Are Human-Level Prompt Engineers, ICLR 2023
[9]Interpreting language models with contrastive explanations EMNLP 2022

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 0
0 0
0- 0



 已为社区贡献120条内容
已为社区贡献120条内容

所有评论(0)