GP3:通过多视角图像输入,为机器人构建拥有几何感知的操作能力
作者|钱权浩,阿里巴巴达摩院算法工程师
引言
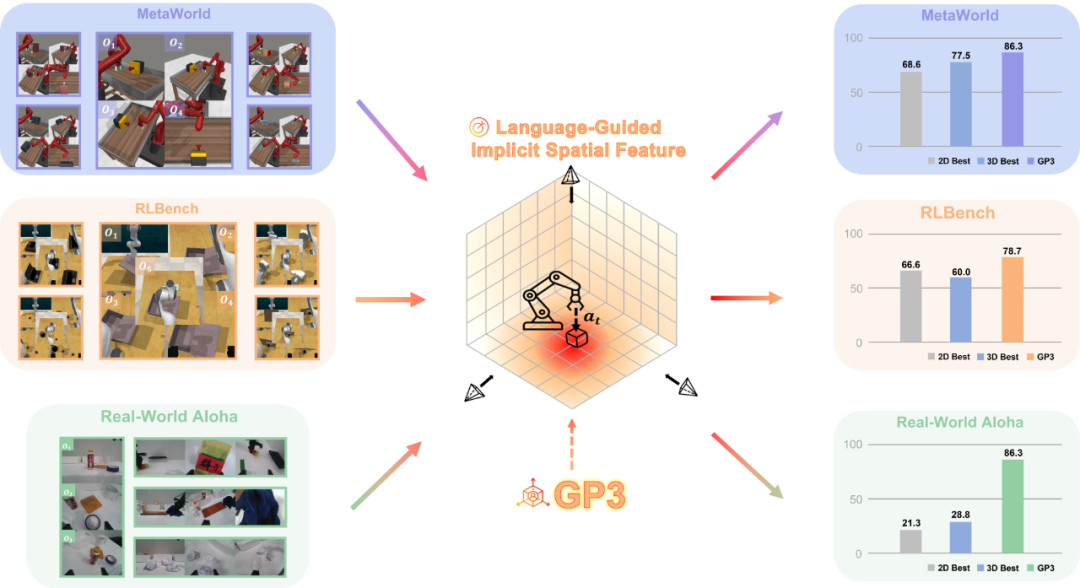
近年来,基于模仿学习的机器人操作技能策略学习发展迅猛,它依赖于图像输入,让机器人从示教数据中学习灵巧操作。而通过提供 3D 信息,能帮助机器人更加精准地在立体空间中完成任务。最容易获取准确 3D 信息的途径就是多视图的观测,基于此,我们提出 GP3( 3D Geometry-Aware Policy with Multi-View Images for Robotic Manipulation),一种多视图输入的面向机器人操控的三维几何感知策略。
GP3 基于多视角RGB输入,通过微调大型三维重建模型RoboVGGT 获得密集空间特征,并引入 G-FiLM(Global attention-based Feature-wise Linear Modulation)机制,利用语言指令动态调制全局注意力,抑制多视角冗余信息,突出任务相关的空间特征。
在MetaWorld、RLBench 和 真实机器人(Mobile ALOHA) 实验中,GP3 在无需深度传感器的条件下实现了领先性能,平均成功率显著高于现有方法,且具备良好的跨环境泛化与部署效率。
论文链接:https://arxiv.org/abs/2509.15733v1
对于机器人来说,精准操控离不开对三维场景几何的理解。现实中的场景充满深度、尺度和空间关系信息,缺乏 3D 感知的机器人,就像是“只用一只眼睛”去抓取、搬运、组装,难免出错。
过去,很多方法直接用深度传感器或点云进行策略学习,但这类硬件昂贵、易受光照/反射干扰,且不总是可用。另一类方法尝试纯 RGB 图像学习隐式 3D,但往往泛化性不足,一到新的环境就必须重新训练隐式特征 3D 的提取 。
基于这个痛点,研究团队提出了 GP3(Geometry-aware Policy with Multi-View Images)——一个面向机器人操控的三维几何感知策略,仅靠多视角 RGB 输入,就能实现可靠的空间推理与高精度控制。
它有三个核心创新点:
-
我们提出了 RoboVGGT,这是一种具备几何感知能力的三维重建模型,我们基于 VGGT, 在精心构建的结合模拟数据与真实数据的机器人场景数据集上进行了微调,能够在多样化的机器人任务中实现稳健且具有良好泛化能力的三维重建。
-
我们提出了G-FiLM(Global attention-based Feature-wise Linear Modulation),这是一种基于全局注意力的调制机制,可在多视角感知中促进与任务相关的注意力分配,抑制冗余信息。
-
基于上述两项关键技术贡献,我们提出了GP3,一种具备三维几何感知能力的机器人操作策略,可实现稳健且高效的多视角空间推理。GP3 在多个模拟与真实环境的基准测试中达到了当前最优性能,为无需依赖特定传感器的稳健视觉运动控制设立了新标准。
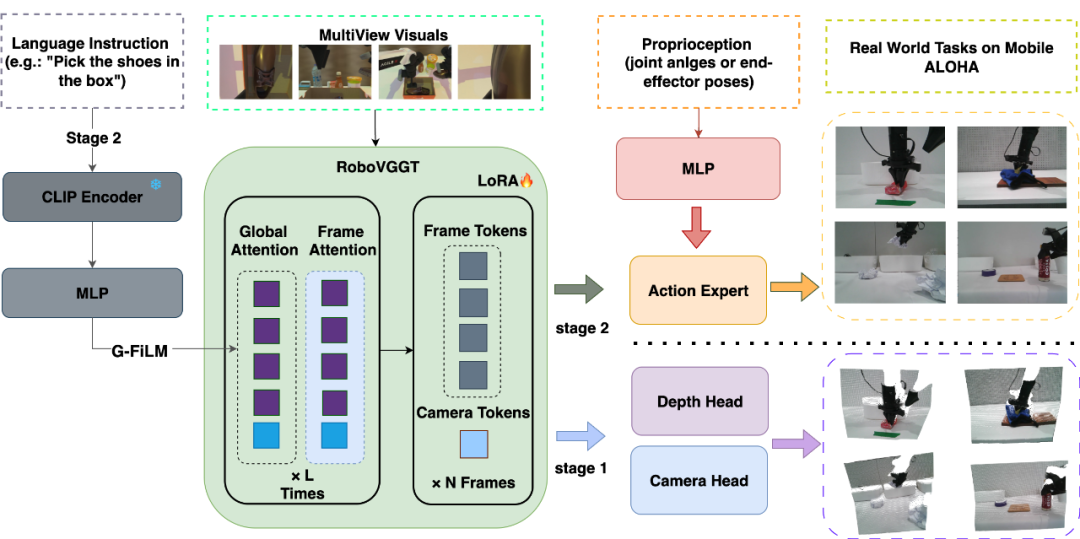
GP3流程图
在训练时,我们分为两阶段训练,分别学习场景几何建模和机器人动作预测,让机器人先会“看”,再会“动”。
第一阶段:几何模型微调
为了获得了一个强大通用的场景能力,我们选择VGGT 作为我们的基础模型,它能够从多视角输入中恢复场景重建结果。但是 VGGT 在训练时缺少对机器人场景下的监督,在机器人任务中表现不佳。我们为了适应机器人工作空间,提升机械臂、操作台等结构的精细重建质量,重新训练了 RoboVGGT,一个针对机器人场景的 3D 基础模型,为机器人提供空间特征。
我们在 3 个主流仿真平台 MetaWorld、RLbench 和 RoboTwin2.0 总共采集了 150K 的数据,同时采集了 20K 的真实场景数据,通过深度信息和相机姿态的监督,训练得到了 RoboVGGT。

如图,当我们输入模型不曾见过机器人操作场景时, RoboVGGT 相比 VGGT,对于机器人场景的重建质量有明显提高。
第二阶段:动作策略训练。
我们在实验中发现,当为机器人提供多视图输入时,成功率并非一直提升,甚至还会下降。经过分析,这是由于网络在面对多视图的输入时,由于增加了大量的冗余信息,无法保持对任务相关场景的注意力,从而导致了成功率下降。
为了解决这个问题,我们提出了 G-FiLM 来融合语言与空间特征。相比 FiLM,G-FiLM 只在引导多视图在全局下的注意力,更好的增强多视图任务相关性,不破坏原有的特征提取,G-FiLM 对任务相关区域的可视化结果如图:
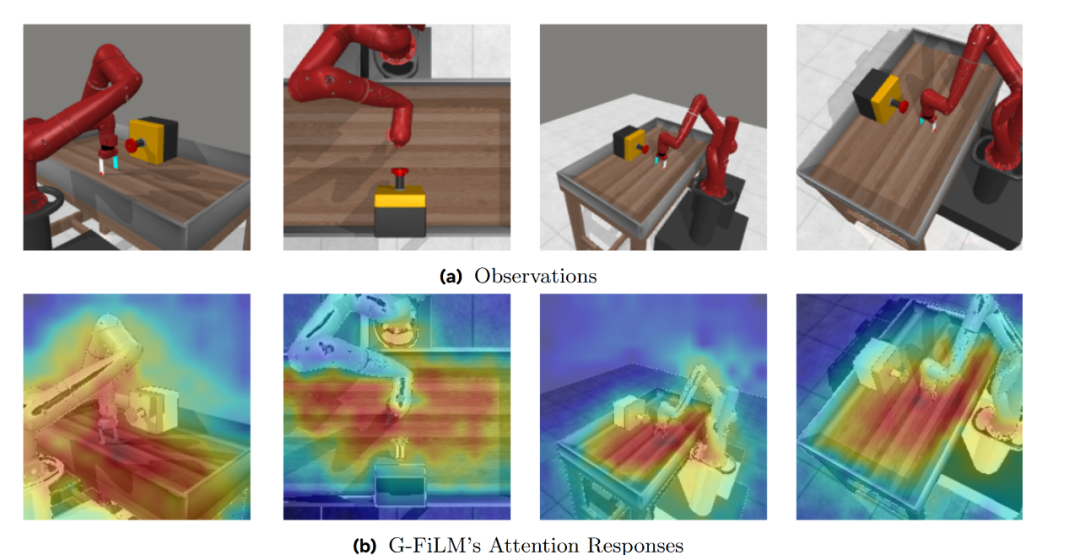
G-FiLM 可视化
最后,我们通过轻量化action expert输出连续控制指令。
核心结果:
我们在两个主流仿真平台 MetaWorld 与 RLBench 上,以及真实双臂机器人 Mobile ALOHA 上测试了 GP3 的操控能力,并进行了消融实验。
-
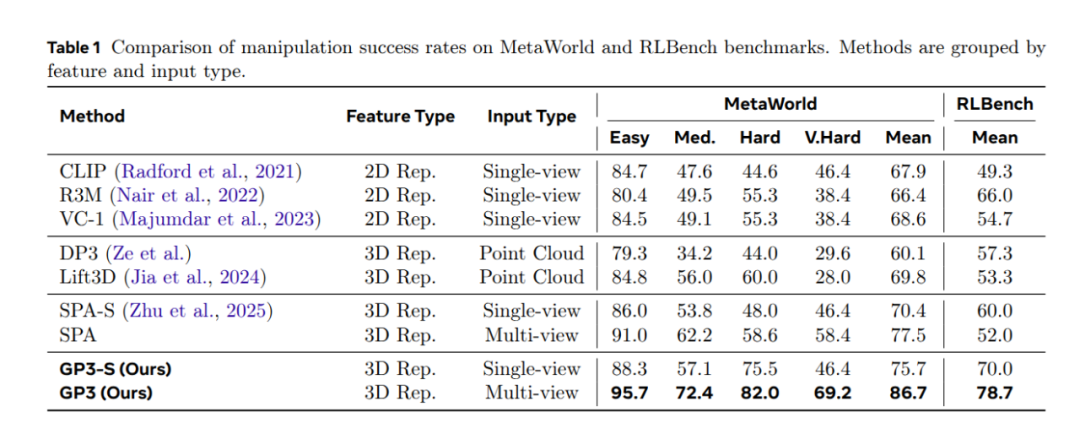
仿真平台结果:纯 RGB 输入下,GP3 多视角配置 ,在 MetaWorld 的 50 个任务中取得平均成功率 86.7%、在 RLBench 的 6 个任务中取得平均成功率 78.7%,相比 SOTA 分别提高了 8.8% 和 12.1%, 全面超越深度依赖方法(如 LIFT3D)和隐式 3D 方法(如 SPA)。
-
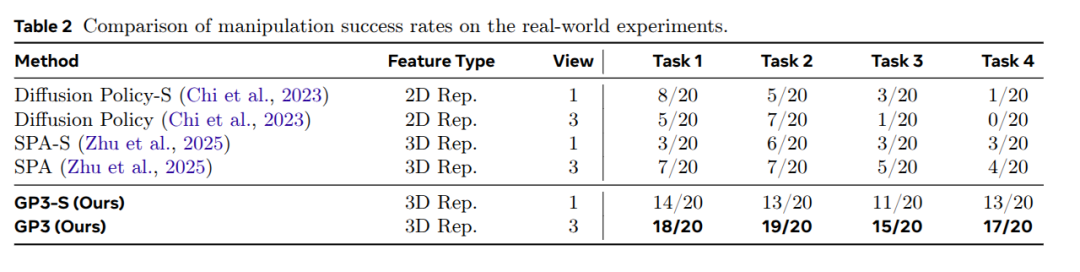
真机实验结果:在 4 个家庭类任务中(扔纸团、放置饮料、收拾桌面、擦拭桌板),我们对比了GP3和Diffusion policy、SPA在不同视角数目下的成功率,3视角输入下的GP3 平均成功率接近 90%,显著领先其他对比方法 57.5%,并且相比其他方法,GP3的成功率随着视角数目增加明显受益。
-
为了验证我们方法的有效性,我们在 MetaWorld 选出了15个任务,包括7个简单任务,5个中等难度任务,3个困难任务,分别对视角数、几何模型微调、G-FiLM 进行了消融实验。实验模型配置如下:
-
使用原始 VGGT 提取特征
-
使用微调后的 RoboVGGT 提取特征
-
RoboVGGT 融合 FiLM提取特征
-
RoboVGGT 融合 G-FiLM提取特征
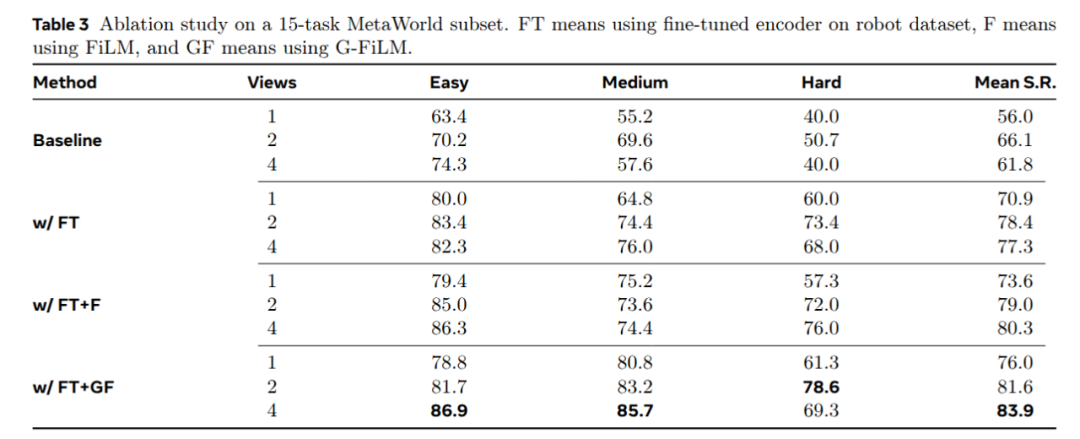
从实验结果可以看出,相比VGGT, RoboVGGT 对机器人任务成功率有显著提升;也证明了 G-FiLM 的全局注意力调制机制,保证了任务成功率始终能随着视角数增加而提升,是解决多视角噪声干扰的关键原因。
除此之外,我们还做了一个有趣的实验,来判断机器人是否真的具备了空间理解能力。
我们打印了真机中需要操作的物体,让机器人进行任务操作,如果机器人具备 3D 能力,就可以区分 2D 打印图片和 3D 物体。

我们测试了 4 种实验配置,进行比较:
-
基线方法 diffusion policy,多视图输入
-
3D 隐式 SOTA 方法 SPA,多视图输入
-
GP3,只使用前视相机视图输入
-
GP3,多视图输入
几种方法中,只有多视角输入的GP3能够精准判断2D图片,仅和真实的3D物体产生交互,这意味着 GP3在进行模仿学习的同时,真正地在理解空间信息,以完成和现实世界的交互。
从虚拟仿真到真实双臂机器人,GP3 都取得了不错的表现,它甚至能分辨真物体和二维假图,不会“上当”,为无需依赖特定传感器的空间视觉运动控制设立了新标准。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 0
0 0
0- 0



 已为社区贡献120条内容
已为社区贡献120条内容

所有评论(0)