ICCV’2025|让每个物体在3D空间精准走位,FMC重新定义可控视频生成
作者|帅欣成,复旦大学研究生
引言
第一个可以控制多物体与相机6D位姿的视频生成模型!通过构建覆盖多种场景和运动模式的大规模合成数据集SynFMC,使得模型中的相机和物体运动控制模块解耦地学习到全局相机运镜与局部的物体运动。
论文题目:《Free-Form Motion Control: Controlling the 6D Poses of Camera and Objects in Video Generation》
Arxiv链接:https://arxiv.org/abs/2501.01425
代码链接:https://henghuiding.com/SynFMC/

研究背景与挑战
1.1 研究背景
基于视频生成模型的成功,研究者们开始追求运动可控的视频生成,包括对物体和相机的运动轨迹控制。
对于物体的运动控制,有两种主要的研究路线:第一种路线的方法通过用户输入的Pose序列(如图1)来控制人体的姿态变换。虽然这类方法能够提供精准的非刚性运动引导,但是无法完成一些刚性变换,如平移、旋转等。且这类方法专注于人物的运动控制,无法泛化到其他物体上。
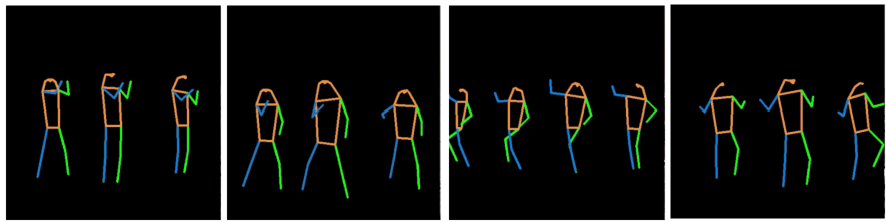

图 1 Pose序列引导姿态变换生成
如图2所示的第二种路线给予了用户控制物体运动轨迹的能力,但是这类方法往往只允许用户在图像空间中标记物体的运动轨迹,限制了其运动范围。其次,物体运动与相机运动在这类方法中无法完全解耦(如图3)。
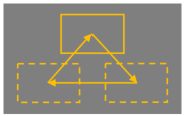

图 2物体运动受限示例

图 3物体运动与相机运动耦合示例
对于相机运镜控制,现有的方法使得用户可以通过简单的文本引导(如“Pan Left/Right/Up/Down” 或 “Zoom In/Out”等),或者提供相机运动轨迹来生成符合运镜规则的视频(如图4)。

图 4 相机运动控制示例
然而,大多数方法无法同时控制相机运镜与物体移动。其中,MotionCtrl独立地学习了相机运动模块以及物体运动模块,但是同时使用两个模块时会出现不符合物理规律的生成结果(如图5)。

图 5 模块耦合效果示例
1.2 当前挑战
综上,虽然现有的视频模型提供了基本的语义以及空间引导的生成能力,但仍然无法实现细粒度的、高自由度的运动控制生成。本质上,物体和相机的运动是在3D空间中进行的,如果将二者限制在图像空间中会影响运动的物理准确性,导致最后生成的视频出现不合理的视觉内容。
因此,我们需要构建一个3D感知的生成模型,以同时控制相机和多个物体的6D位姿(3D旋转+3D位置)。

方法
2.1 SynFMC (Synthetic Dataset for Free-Form Motion Control)数据集
为了同时控制相机和多个物体的6D位姿,视频生成模型需要在包含6D运动标注的大规模数据集上训练运动控制模块,而目前尚未有公开数据集符合标注需求。例如WebVid-10M虽然具有丰富的、高质量的视频数据与文本标注,但是缺乏相应的运动信息标注。
RealEstate-10K等一些数据集拥有丰富的相机运动轨迹标注,但是它们主要针对于静止场景,且拍摄的主体不具备多样性。为此,我们利用虚幻引擎(Unreal Engine)构建具有物体和相机6D位姿的合成视频,以让模型学习到如何以3D感知的方式对物体和相机的运动进行高自由度的控制。最后构建的数据集名为SynFMC(Synthetic Dataset for Free-Form Motion Control ),构建流程如图6所示。

图 6SynFMC数据集构建流程
数据集的构建流程包含:资产收集与过滤,物体与相机运动模式的构建,运动序列生成,以及渲染合成和运动信息标注。其中我们模拟了天空,地面,近地,水下以及水面等五种环境,并考虑了静态单物体,静态多物体,动态单物体,以及动态多物体等四种场景。静态代表物体是静止的,而相机是自由移动的。
下面展示了不同的环境以及场景下的部分示例:

图 7SynFMC数据集的不同环境下的视频示例

图 8 SynFMC数据集的不同场景下的视频示例
2.2 FMC (Free-Form Motion Control)运动控制模型
为了实现6D位姿控制,我们提出了FMC运动控制模型,其包含相机运动控制模块(Camera Motion Controller,CMC)和物体运动控制模块(Object Motion Controller,OMC)。
其中CMC使用普朗克编码的方式对相机的位姿参数进行编码,以注入运镜信息。对于第一帧,我们编码了相机的绝对姿态(即旋转矩阵)以及零初始化的位置,以实现对第一帧相机方位的控制,而OMC接受二维形式的物体位姿引导条件。
该引导条件本质上是一个H×W×12形状的张量,其中空间维度与生成图像在特征空间中的分辨率保持一致,而通道维度为位姿矩阵的维度(12=9(旋转矩阵)+3(位置))。为了表征物体在相机空间的位置和尺寸,我们将物体看作一个球体,并在相机坐标系下投影以获得一个代表物体的圆。
在该圆内,我们将引导条件图的通道维度设置为物体相对于相机的位姿矩阵,以注入姿态信息,就能完整地描述物体在相机视角下的6D位姿了。我们采用了高斯核来减弱远离中心的引导条件,并仅将输出的调制特征施加到物体区域,以降低对背景区域的影响,使用这种引导条件让我们可以使用同一种表示来表征多个物体的位姿。
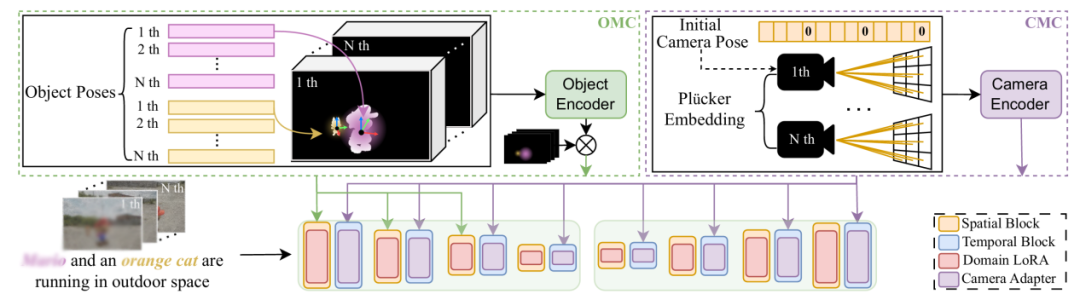
图 9 FMC架构图
为了避免学习到合成数据中的渲染风格内容,我们在第一阶段训练中加入了LoRA模块并优化与图像内容相关的网络参数,然后在第二和第三阶段中分别训练相机和物体控制模块。

实验结果
我们首先将相机运动与物体运动的独立控制与先前方法进行对比,随后展示FMC在同时控制二者运动中的卓越性能。最后,通过不同场景的额外示例验证SynFMC与FMC的有效性。
图10 (a)展示了相机运动独立控制,FMC实现了与之前的方法相当的性能。如图10 (b)所示,对比方法无法保持相机静止(背景出现动态移动),表明图像空间轨迹会耦合物体与相机运动。
此外,由于FMC中的物体运动控制模块接收物体6D位姿,FMC能高保真地还原物体朝向。

图 10 独立控制相机/物体的运动实验结果。(a)(b)分别展示了对相机和物体独立的控制
我们进一步探索相机与物体控制信号的组合输入下模型的性能。如图11所示,FMC生成的视频更精准匹配指定条件。而对比方法虽能捕捉相机运动,却难以生成逼真物体动态。这些结果验证了FMC实现相机与物体同步控制的有效性。

图 11 对相机和物体运动同时控制的比较结果
下面展示了四种场景的视频生成结果:静态单物体、动态单物体、静态多物体及动态多物体。得益于SynFMC中运动模式的多样性,FMC能有效学习各类复杂高级镜头语言。例如图12第2行中,相机先正面拍摄人物随后转为跟随视角。最后两行展示了多物体场景下的表现,物体间相对运动与相机运动均严格遵循输入条件。

图 12 不同场景下的运动控制
此外,如图13所示,我们的方法还可以和各种的预训练权重相结合,产生不同风格的生成视频。

图 13 与不同权重结合产生不同风格的视频

结论
综上,我们提出的SynFMC有效地解决了6D位姿控制中数据集的问题。基于此训练的FMC也可以有效地在各种场景下精准的控制物体的运动模式,实现高自由度的运动控制。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 0
0 0
0- 0



 已为社区贡献124条内容
已为社区贡献124条内容

所有评论(0)