机器学习---主成分分析(PCA)
PCA(Principal components analysis)是数据降维中用的最多的方法,其目标是在n维数据中寻找k(k<n)维新数据,并能反映这n维数据的主要特征。----即n维投影到k维会形成一些空间向量u1,u2...uk,我们转变成寻找u1,u2...uk空间向量形成的空间。创建PCA对象,数据维度设置为2,并使用预处理的数据计算出var_ratio。使用预处理后的数据再次使用knn
数据降维:在某些指定的条件下,降低随机变量个数,得到一组“不相关”主变量的过程。
优点:
- 通过降维,减少了模型分析的数据量,降低了计算的难度并提高了计算的处理效率;
- 实现了数据的可视化。
数据降维的实现方法:主成分分析(PCA)
PCA(Principal components analysis)是数据降维中用的最多的方法,其目标是在n维数据中寻找k(k<n)维新数据,并能反映这n维数据的主要特征。其核心是在信息损失尽可能小的情况下降低数据的维度。
二维数据x1,x2如何降维到一维数据??
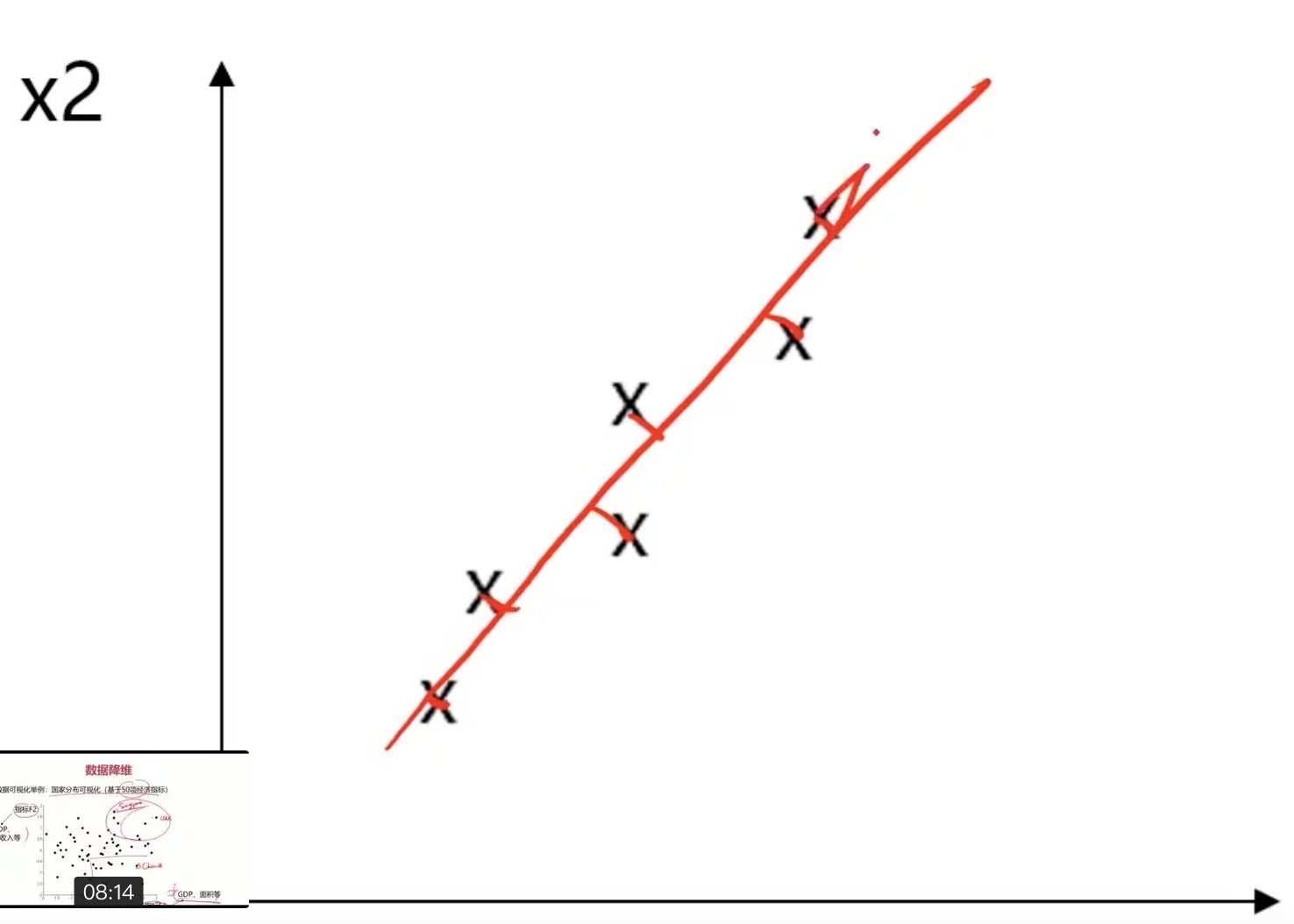
1.二维坐标点的数据都投影到红色的直线上;
2.计算各个坐标点到该条直线的距离(即损失信息);
3.各个坐标点相加最小的直线是信息损失最小的一维数据。
三维数据x1,x2,x3如何降维到二维数据?
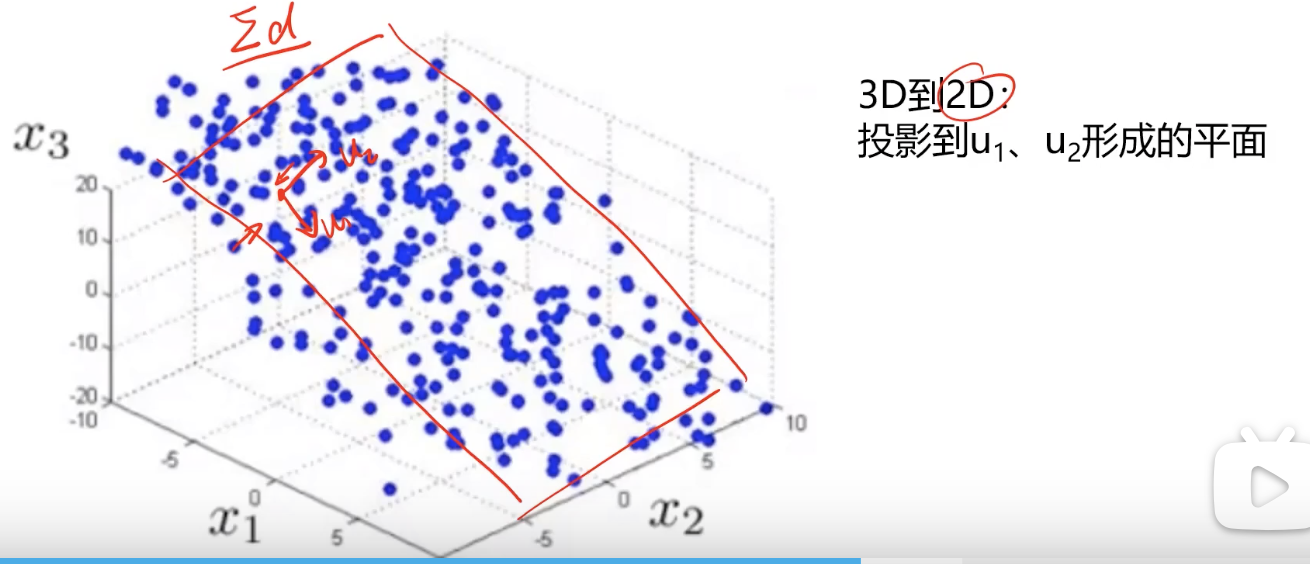
1.三维各个坐标点都投影到u1,u2形成的平面;
2.计算空间中的各个点到u1,u2平面到空间向量(即损失信息)
3.计算各个空间向量相加最小的平面。
n维数据降维到k维??----即n维投影到k维会形成一些空间向量u1,u2...uk,我们转变成寻找u1,u2...uk空间向量形成的空间。
如何保留数据降维后的主要信息?
我们需要保证投影后不同特征的数据尽量分的开和不相关。
PCA实战
导入iris数据集并使用knn算法训练和预测数据
import pandas
import numpy
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
from sklearn.preprocessing import StandardScaler
from matplotlib import pyplot
from sklearn.decomposition import PCA
data = pandas.read_csv("/Users/zc/Desktop/iris1.csv")
print(data.head())
data_train = data.drop(['leibie'],axis=1)
y=data.loc[:,'leibie']
print(data_train)
print(y)
KNN = KNeighborsClassifier(n_neighbors=3)
KNN.fit(data,y)
y_predict = KNN.predict(data)
accuracy = accuracy_score(y_predict,y)
print(accuracy)
对训练数据进行预处理
processed_data = StandardScaler().fit_transform(data)
计算未处理数据和预处理数据的均值和方差
x1_mean = data.loc[:,'lengthfore'].mean()
x1_sega = data.loc[:,'lengthfore'].std()
x1_process_mean = processed_data[:,0].mean()
x1_process_sega = processed_data[:,0].std()
print(x1_mean,x1_sega,x1_process_mean,x1_process_sega)
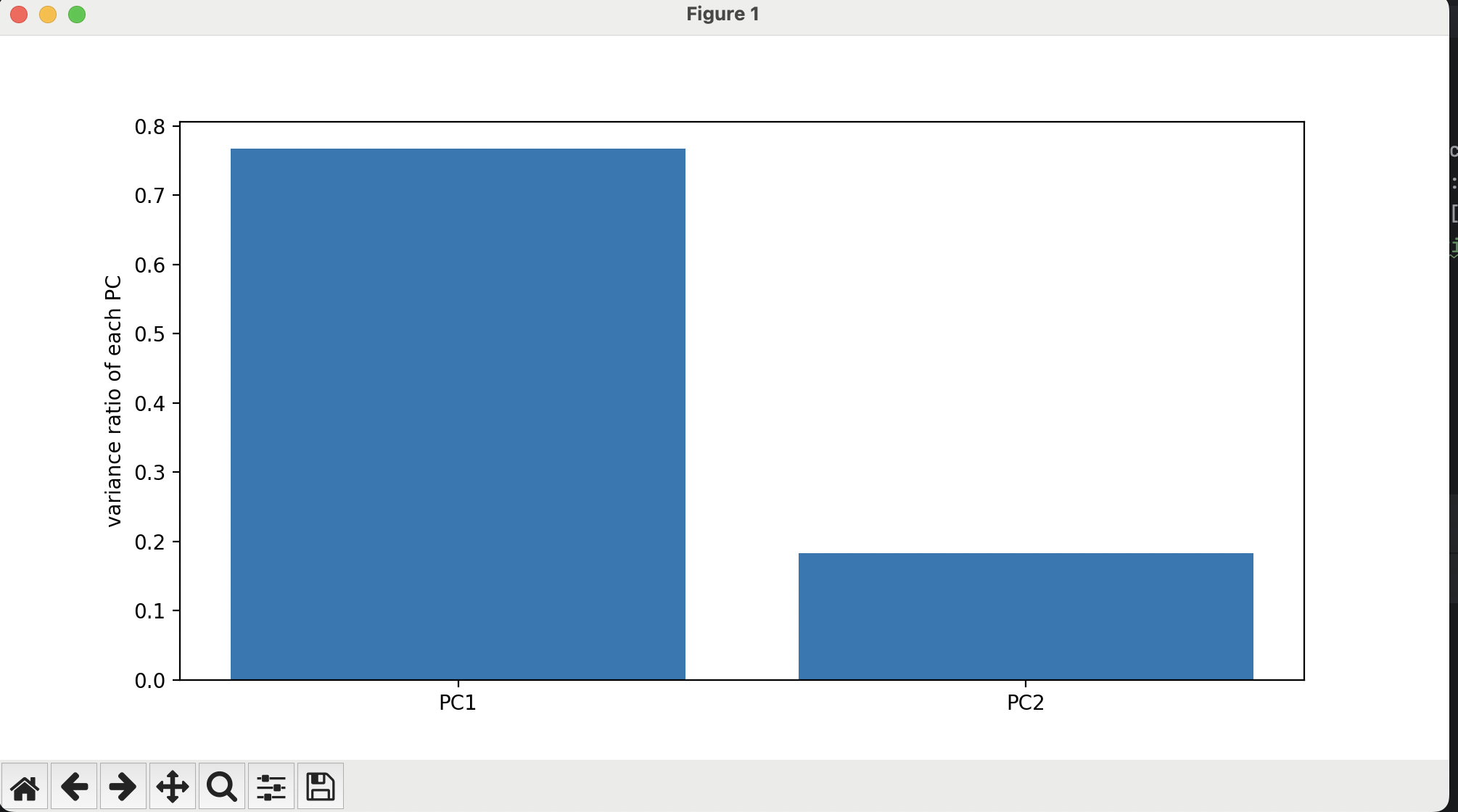
创建PCA对象,数据维度设置为2,并使用预处理的数据计算出var_ratio。同时将var_ratio和处理后的数据可视化显示。
pca = PCA(n_components=2)
process_pca =pca.fit_transform(processed_data)
print(process_pca.shape)
var_ratio = pca.explained_variance_ratio_
fig_2 = pyplot.figure(figsize=(10,5))
pyplot.bar([1,2],var_ratio)
pyplot.xticks([1,2],['PC1','PC2'])
pyplot.ylabel("variance ratio of each PC")
pyplot.show()
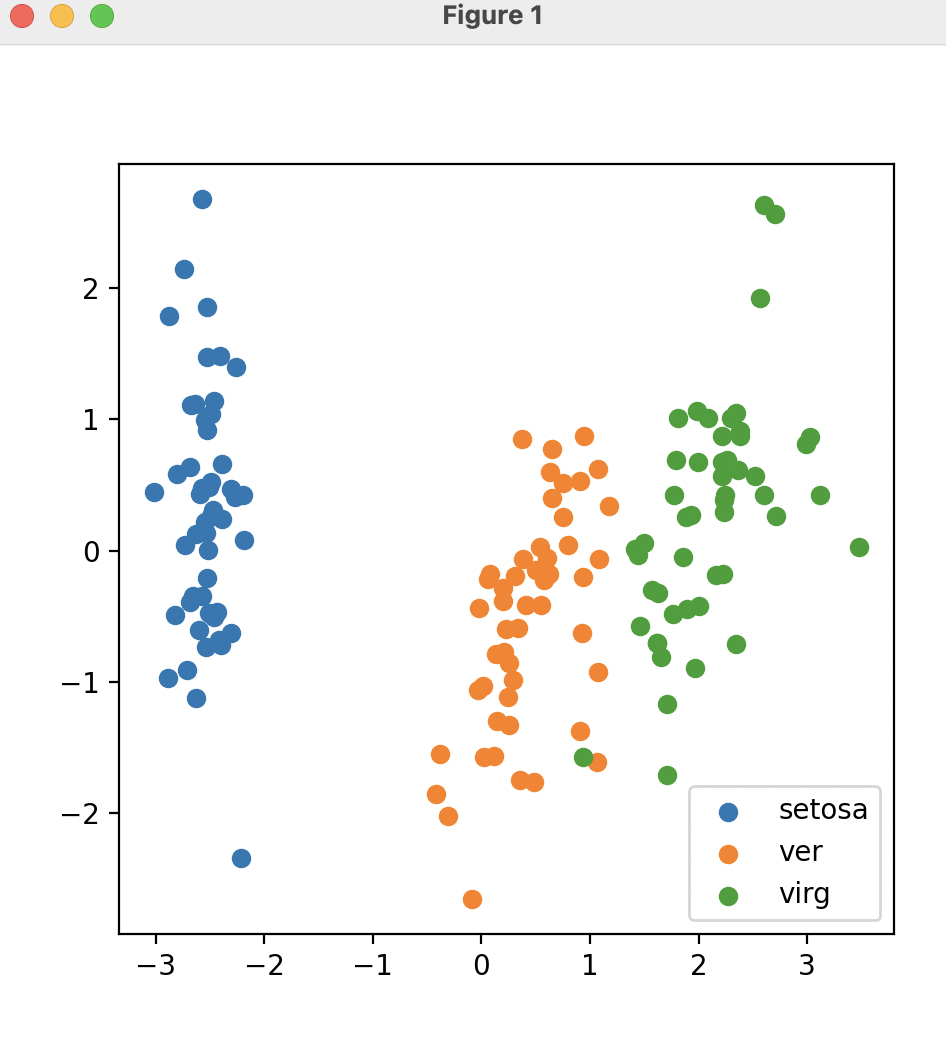
fig_3 = pyplot.figure(figsize=(5,5))
setosa = pyplot.scatter(process_pca[:,0][y==0],process_pca[:,1][y==0])
ver = pyplot.scatter(process_pca[:,0][y==1],process_pca[:,1][y==1])
virg = pyplot.scatter(process_pca[:,0][y==2],process_pca[:,1][y==2])
pyplot.legend((setosa,ver,virg),('setosa','ver','virg'))
pyplot.show()
使用预处理后的数据再次使用knn算法训练和预测,并和之前没有降维的数据训练和预测的准确度做对比
knn_1 = KNeighborsClassifier(n_neighbors=3)
knn_1.fit(process_pca,y)
process_predict_y = knn_1.predict(process_pca)
process_accuracy = accuracy_score(y,process_predict_y)
print(process_accuracy)
DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 20
20 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)