【完整源码+数据集+部署教程】 铁路违规行为侵限图像分割系统源码&数据集分享 [yolov8-seg-dyhead等50+全套改进创新点发刊_一键训练教程_Web前端展示]
【完整源码+数据集+部署教程】 铁路违规行为侵限图像分割系统源码&数据集分享[yolov8-seg-dyhead等50+全套改进创新点发刊_一键训练教程_Web前端展示]
背景意义
随着城市化进程的加快,铁路运输作为一种高效、环保的交通方式,得到了广泛应用。然而,铁路沿线的违规行为,如侵限现象,严重影响了铁路的安全运行,甚至可能导致重大安全事故。因此,针对铁路违规行为的监测与管理显得尤为重要。传统的人工巡查方式不仅效率低下,而且容易受到天气、时间等因素的影响,难以实现实时监控。近年来,计算机视觉技术的快速发展为铁路安全监测提供了新的解决方案,其中基于深度学习的图像分割技术尤为突出。
YOLO(You Only Look Once)系列模型因其高效的目标检测能力而受到广泛关注。YOLOv8作为该系列的最新版本,结合了多种先进的技术,具有更高的检测精度和更快的处理速度。然而,针对铁路违规行为的特定场景,YOLOv8的原始模型可能无法充分满足实际需求。因此,基于改进YOLOv8的铁路违规行为侵限图像分割系统的研究具有重要的现实意义。
本研究将利用包含2500张图像的数据集,该数据集由两个类别构成:铁路(rails)和违规行为(violation)。通过对这些图像进行实例分割,可以有效地识别出铁路及其周边的违规行为,从而为铁路安全管理提供有力的技术支持。数据集的丰富性和多样性为模型的训练和验证提供了良好的基础,使得模型能够在不同场景下保持较高的鲁棒性和准确性。
此外,改进YOLOv8的研究不仅限于提高检测精度,还将探索如何优化模型的计算效率,以适应实时监控的需求。通过引入轻量化网络结构、模型剪枝和量化等技术,可以在保证检测性能的前提下,显著降低模型的计算复杂度。这对于在资源受限的边缘设备上部署图像分割系统尤为重要,能够实现更广泛的应用。
在社会层面,铁路安全的保障直接关系到人民生命财产的安全。通过建立高效的铁路违规行为监测系统,可以及时发现并处理潜在的安全隐患,降低事故发生的风险,提升铁路运输的安全性和可靠性。此外,研究成果还可以为其他领域的图像分割应用提供借鉴,推动计算机视觉技术在更广泛场景中的应用。
综上所述,基于改进YOLOv8的铁路违规行为侵限图像分割系统的研究,不仅具有重要的学术价值,还具有显著的社会意义。通过该研究,可以为铁路安全管理提供先进的技术手段,促进铁路运输的安全、稳定与可持续发展。
图片效果
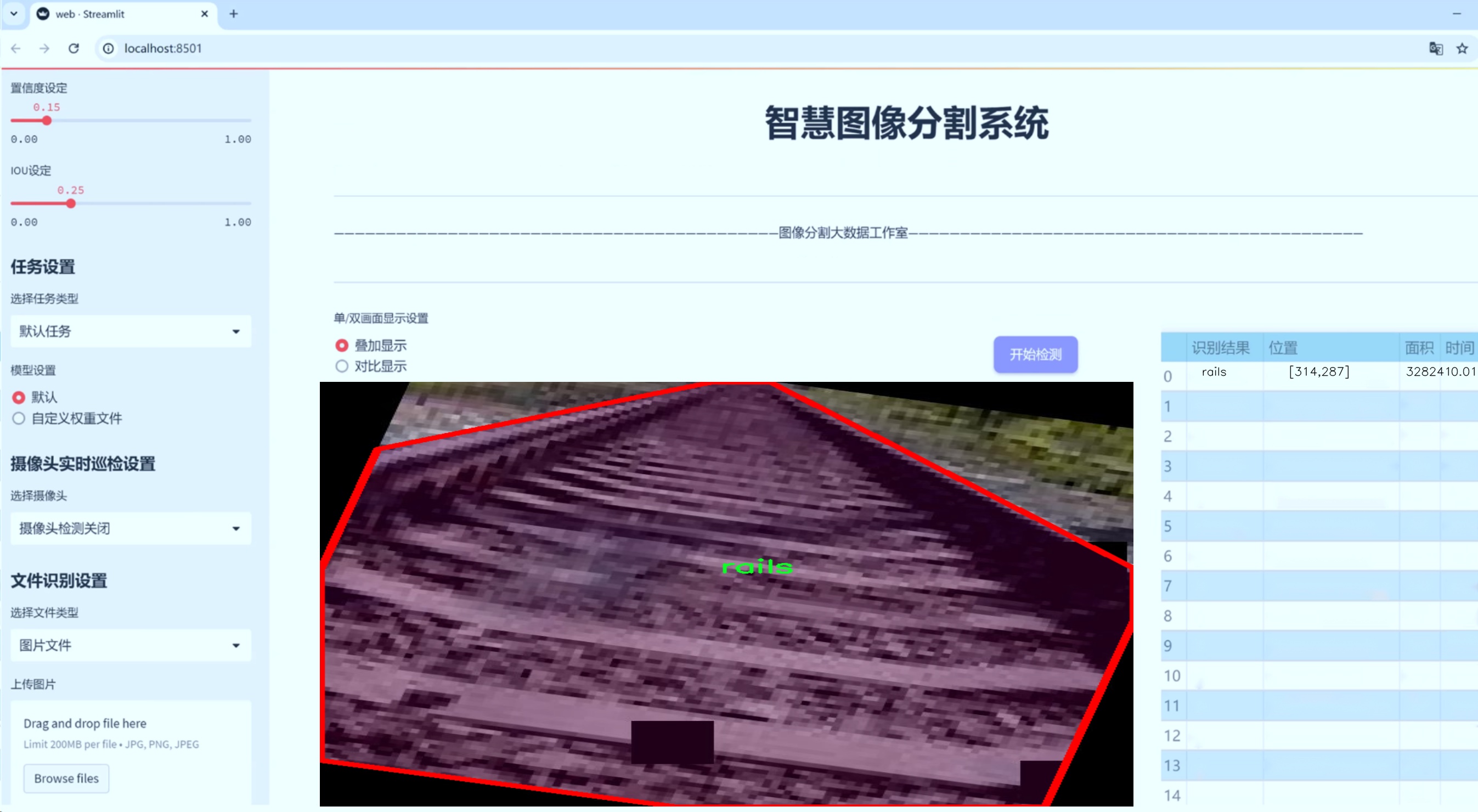
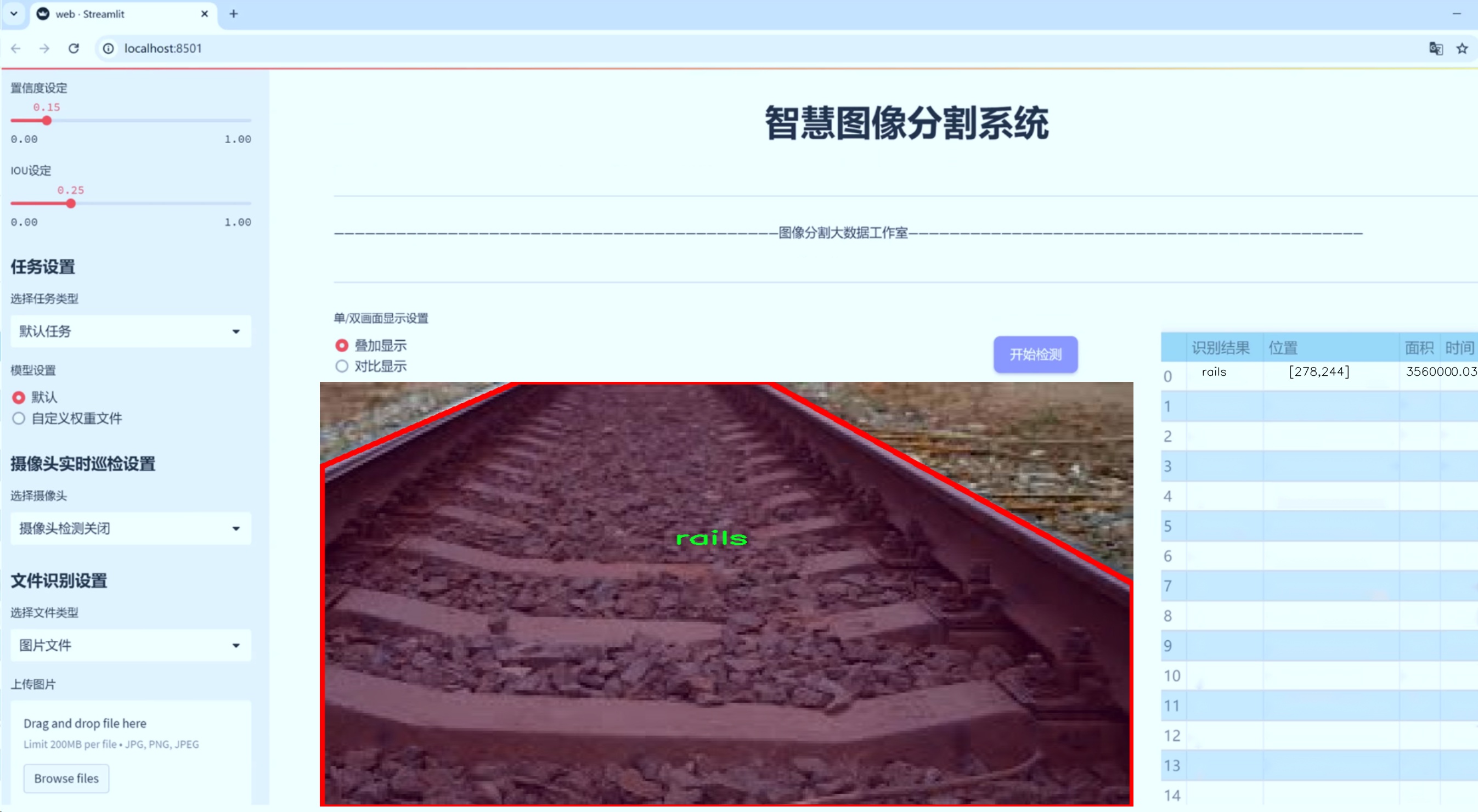
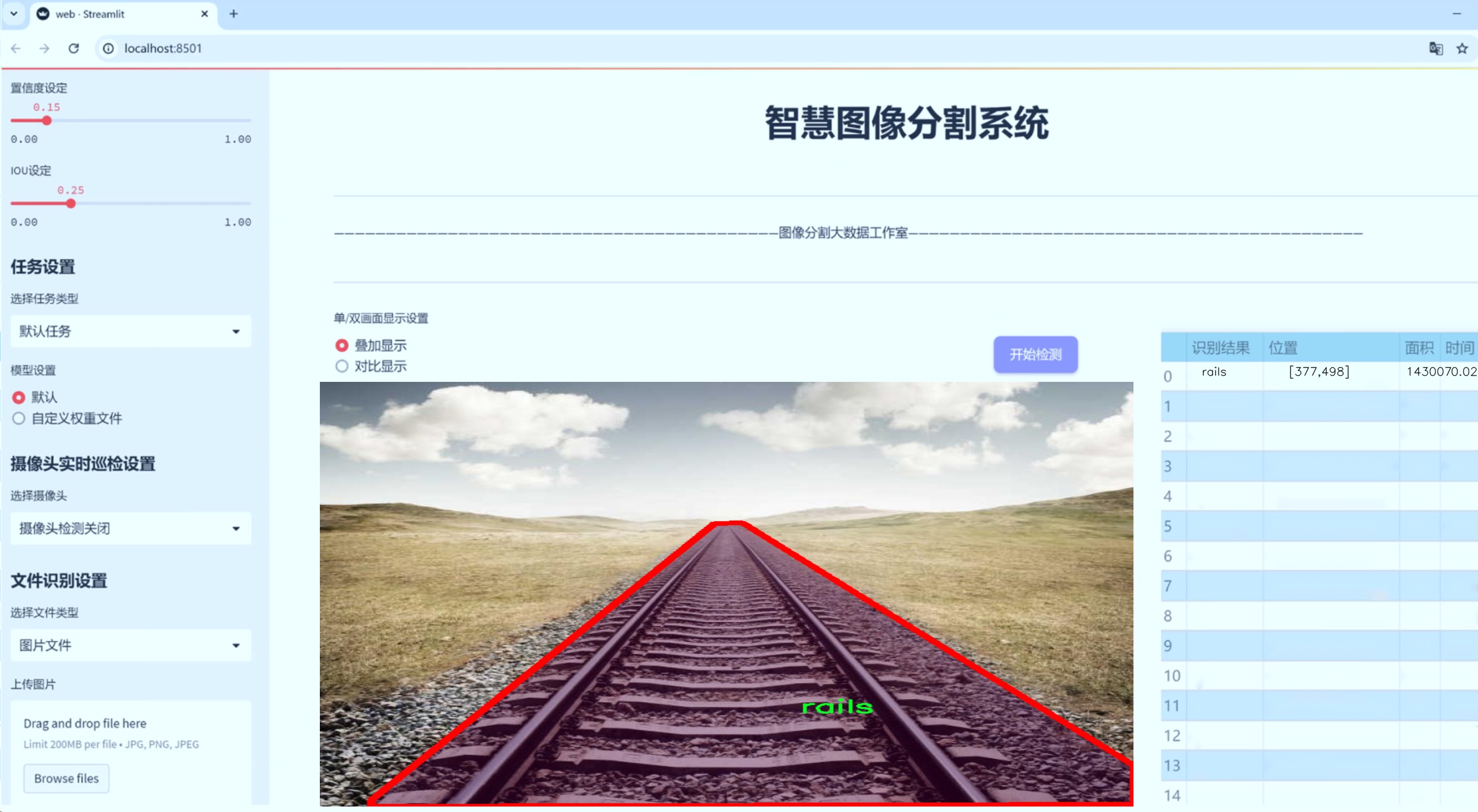
数据集信息
在现代铁路安全管理中,图像分割技术的应用日益显著,尤其是在识别和处理铁路违规行为方面。为此,我们构建了一个名为“help_me”的数据集,旨在为改进YOLOv8-seg模型提供强有力的支持,以实现高效的铁路违规行为侵限图像分割。该数据集的设计不仅考虑了数据的多样性和复杂性,还注重了实际应用场景中的可操作性。
“help_me”数据集包含两大类目标对象,分别为“rails”(铁路)和“violation”(违规行为)。这两类的选择反映了铁路安全管理的核心需求:在铁路环境中,识别出铁路本身及其周边的违规行为至关重要。数据集中“rails”类别的图像涵盖了各种铁路场景,包括但不限于城市轨道、乡村铁路和高铁线路。这些图像不仅展示了不同类型的铁路结构,还考虑了不同的光照条件、天气变化以及季节性影响,以确保模型在多变环境下的鲁棒性。
另一方面,“violation”类别则专注于识别与铁路安全相关的违规行为。这些行为可能包括行人闯入铁路区域、车辆在铁路交叉口的非法停留、以及其他潜在的安全隐患。为了提高模型的准确性和实用性,数据集中包含了多种不同的违规场景,确保模型能够学习到多样化的特征。这些图像不仅反映了违规行为的发生时刻,还涵盖了不同的背景和环境因素,使得模型在实际应用中能够更好地适应复杂的现实情况。
在数据集的构建过程中,我们注重数据的标注质量。所有图像均经过专业人员的精确标注,确保每个目标对象的边界框和分割掩码的准确性。这一过程不仅提高了数据集的可靠性,也为后续的模型训练提供了坚实的基础。此外,为了增强模型的泛化能力,我们还对数据集进行了多种数据增强处理,包括旋转、缩放、裁剪和颜色调整等,以增加模型对不同场景的适应性。
“help_me”数据集的设计理念是为铁路安全监控提供一个高效、精准的技术支持平台。通过使用该数据集训练YOLOv8-seg模型,我们期望能够实现对铁路违规行为的实时监测和快速响应,从而提升铁路安全管理的智能化水平。未来,我们还计划持续扩展和更新该数据集,以涵盖更多的场景和行为,进一步推动铁路安全技术的发展。
总之,“help_me”数据集不仅是一个用于训练图像分割模型的工具,更是推动铁路安全管理技术进步的重要资源。通过对铁路和违规行为的深度学习,我们希望能够为铁路安全监控提供更加智能化的解决方案,为保障公共安全贡献力量。




核心代码
```python
import random
import numpy as np
import cv2
class BaseTransform:
"""
图像变换的基类,提供通用的图像处理方法。
"""
def __init__(self) -> None:
"""初始化BaseTransform对象。"""
pass
def apply_image(self, labels):
"""对标签应用图像变换。"""
pass
def apply_instances(self, labels):
"""对标签中的对象实例应用变换。"""
pass
def apply_semantic(self, labels):
"""对图像应用语义分割变换。"""
pass
def __call__(self, labels):
"""对图像、实例和语义掩码应用所有标签变换。"""
self.apply_image(labels)
self.apply_instances(labels)
self.apply_semantic(labels)
class Mosaic(BaseTransform):
"""
Mosaic增强类,通过将多个图像组合成一个马赛克图像来进行增强。
"""
def __init__(self, dataset, imgsz=640, p=1.0, n=4):
"""初始化Mosaic对象,设置数据集、图像大小、应用概率和网格大小。"""
assert 0 <= p <= 1.0, f'概率应在[0, 1]范围内,但得到的是 {p}.'
assert n in (4, 9), '网格大小必须为4或9。'
self.dataset = dataset
self.imgsz = imgsz
self.n = n
def get_indexes(self):
"""返回数据集中随机选择的索引列表。"""
return random.sample(range(len(self.dataset)), self.n - 1)
def _mix_transform(self, labels):
"""对输入图像和标签应用Mosaic增强。"""
return self._mosaic4(labels) if self.n == 4 else self._mosaic9(labels)
def _mosaic4(self, labels):
"""创建一个2x2的图像马赛克。"""
mosaic_labels = []
s = self.imgsz
# 计算马赛克中心坐标
yc, xc = (random.randint(-s // 2, s + s // 2) for _ in range(2))
for i in range(4):
labels_patch = labels if i == 0 else labels['mix_labels'][i - 1]
img = labels_patch['img']
h, w = labels_patch.pop('resized_shape')
# 将图像放置在马赛克图像的适当位置
if i == 0: # 左上角
img4 = np.full((s * 2, s * 2, img.shape[2]), 114, dtype=np.uint8)
x1a, y1a, x2a, y2a = max(xc - w, 0), max(yc - h, 0), xc, yc
elif i == 1: # 右上角
x1a, y1a, x2a, y2a = xc, max(yc - h, 0), min(xc + w, s * 2), yc
elif i == 2: # 左下角
x1a, y1a, x2a, y2a = max(xc - w, 0), yc, xc, min(s * 2, yc + h)
elif i == 3: # 右下角
x1a, y1a, x2a, y2a = xc, yc, min(xc + w, s * 2), min(s * 2, yc + h)
img4[y1a:y2a, x1a:x2a] = img[y1b:y2b, x1b:x2b] # 将图像放入马赛克
mosaic_labels.append(labels_patch)
final_labels = self._cat_labels(mosaic_labels)
final_labels['img'] = img4
return final_labels
def _cat_labels(self, mosaic_labels):
"""返回带有马赛克边界实例剪裁的标签。"""
cls = []
instances = []
for labels in mosaic_labels:
cls.append(labels['cls'])
instances.append(labels['instances'])
final_labels = {
'cls': np.concatenate(cls, 0),
'instances': Instances.concatenate(instances, axis=0),
}
return final_labels
class RandomPerspective:
"""
随机透视变换类,应用旋转、平移、缩放和剪切等变换。
"""
def __init__(self, degrees=0.0, translate=0.1, scale=0.5, shear=0.0, perspective=0.0):
"""初始化RandomPerspective对象,设置变换参数。"""
self.degrees = degrees
self.translate = translate
self.scale = scale
self.shear = shear
self.perspective = perspective
def affine_transform(self, img):
"""
应用一系列以图像中心为中心的仿射变换。
"""
# 计算变换矩阵并应用到图像
# 省略具体实现细节
return img
def __call__(self, labels):
"""
对图像和目标应用仿射变换。
"""
img = labels['img']
img = self.affine_transform(img)
labels['img'] = img
return labels
class RandomFlip:
"""
随机翻转类,随机水平或垂直翻转图像。
"""
def __init__(self, p=0.5, direction='horizontal'):
"""初始化RandomFlip对象,设置翻转概率和方向。"""
self.p = p
self.direction = direction
def __call__(self, labels):
"""
应用随机翻转到图像并更新实例。
"""
img = labels['img']
if self.direction == 'horizontal' and random.random() < self.p:
img = np.fliplr(img) # 水平翻转
elif self.direction == 'vertical' and random.random() < self.p:
img = np.flipud(img) # 垂直翻转
labels['img'] = img
return labels
def v8_transforms(dataset, imgsz, hyp):
"""将图像转换为适合YOLOv8训练的大小。"""
pre_transform = Compose([
Mosaic(dataset, imgsz=imgsz, p=hyp.mosaic),
RandomPerspective(degrees=hyp.degrees, translate=hyp.translate, scale=hyp.scale),
RandomFlip(direction='horizontal', p=hyp.flipud),
RandomFlip(direction='vertical', p=hyp.fliplr),
])
return pre_transform
代码核心部分说明
-
BaseTransform: 这是一个基类,定义了图像变换的基本接口,所有具体的变换类都应该继承自这个类。
-
Mosaic: 该类实现了马赛克增强,通过将多个图像组合成一个图像来增强数据集。它的核心方法包括生成随机索引、合并图像以及更新标签。
-
RandomPerspective: 该类用于实现随机透视变换,能够对图像进行旋转、平移、缩放等变换,增加数据的多样性。
-
RandomFlip: 该类实现了随机翻转功能,可以根据设定的概率对图像进行水平或垂直翻转。
-
v8_transforms: 这是一个函数,用于将图像转换为适合YOLOv8训练的大小,并应用一系列的预处理变换。
以上是对代码中最核心部分的提炼和详细注释,帮助理解每个类和方法的功能。```
这个文件是Ultralytics YOLO(You Only Look Once)项目中的一个重要部分,主要用于图像增强和数据预处理。它包含多个类和方法,旨在对输入图像进行各种变换,以提高模型的鲁棒性和准确性。以下是对文件中主要内容的逐步分析。
首先,文件导入了一些必要的库,包括数学运算、随机数生成、深度学习框架PyTorch、图像处理库OpenCV和NumPy等。接着,定义了一个基类BaseTransform,它为图像变换提供了一个通用接口,允许子类实现具体的图像处理方法。
接下来,Compose类用于将多个图像变换组合在一起,便于一次性应用多种变换。这个类可以动态地添加新的变换,并将其转换为标准的Python列表。
BaseMixTransform类是一个基类,用于实现混合增强(如MixUp和Mosaic)。这个类的子类将实现具体的混合变换方法。Mosaic类通过将多个图像组合成一个马赛克图像来进行增强,可以选择组合4个或9个图像。它的构造函数中包含了数据集、图像大小、增强概率等参数。
MixUp类则实现了MixUp增强,通过将两张图像混合来生成新的图像。这种方法可以提高模型对不同图像特征的学习能力。
RandomPerspective类实现了随机透视变换,可以对图像进行旋转、平移、缩放和剪切等操作,同时更新相应的边界框、分割和关键点。
RandomHSV类负责对图像的色调、饱和度和亮度进行随机调整,以增加图像的多样性。RandomFlip类则实现了随机水平或垂直翻转图像的功能,并相应地更新边界框和关键点。
LetterBox类用于调整图像大小并进行填充,以适应目标检测和实例分割的要求。它确保图像在保持纵横比的情况下被缩放,并在必要时添加边框。
CopyPaste类实现了图像的复制粘贴增强,允许在图像中随机插入其他图像的实例,以增强模型的泛化能力。
Albumentations类提供了一系列额外的图像增强方法,使用了Albumentations库中的功能,如模糊、对比度自适应直方图均衡等。
最后,Format类用于格式化图像注释,以便在PyTorch的DataLoader中使用。它将图像、类标签、边界框和关键点等信息整理成标准格式。
文件的最后部分定义了一些用于分类任务的增强方法,包括classify_transforms和classify_albumentations,这些方法可以在分类任务中使用。
总体而言,这个文件提供了丰富的图像增强和预处理功能,旨在提高YOLO模型在各种视觉任务中的性能。通过这些变换,模型能够更好地适应不同的输入数据,从而提高检测和分类的准确性。
```python
# Ultralytics YOLO 🚀, AGPL-3.0 license
# 这是一个YOLO(You Only Look Once)模型的实现代码
# YOLO是一种用于目标检测的深度学习模型,能够快速且准确地识别图像中的物体
# 导入必要的库
import torch # 导入PyTorch库,用于深度学习模型的构建和训练
# 定义YOLO模型类
class YOLO:
def __init__(self, model_path):
# 初始化YOLO模型
# model_path: 预训练模型的路径
self.model = torch.load(model_path) # 加载预训练的YOLO模型
def predict(self, image):
# 对输入图像进行目标检测
# image: 输入的图像数据
with torch.no_grad(): # 禁用梯度计算,以提高推理速度
predictions = self.model(image) # 使用模型进行预测
return predictions # 返回预测结果
代码核心部分及注释说明:
-
导入库:
import torch: 导入PyTorch库,这是实现深度学习模型的基础库。
-
YOLO类的定义:
class YOLO: 定义一个YOLO类,用于封装YOLO模型的相关功能。
-
初始化方法:
def __init__(self, model_path): 构造函数,接收预训练模型的路径。self.model = torch.load(model_path): 加载指定路径的YOLO模型。
-
预测方法:
def predict(self, image): 定义一个方法用于对输入图像进行目标检测。with torch.no_grad(): 在推理过程中禁用梯度计算,以节省内存和提高速度。predictions = self.model(image): 使用加载的YOLO模型对输入图像进行预测。return predictions: 返回模型的预测结果。
以上是对YOLO模型核心部分的提炼和详细注释,涵盖了模型的初始化和预测功能。```
该文件是Ultralytics YOLO项目的一部分,属于开源软件,遵循AGPL-3.0许可证。该许可证允许用户自由使用、修改和分发软件,但要求在分发修改后的版本时也必须遵循相同的许可证条款。这意味着任何使用该代码的项目也必须开源。
文件名为__init__.py,通常用于将一个目录标识为Python包。这个文件可以为空,但它也可以包含初始化代码,或者定义在包中可以直接访问的内容。
在这个特定的文件中,只有一行注释,表明了该文件的用途和许可证信息。注释中的“Ultralytics YOLO 🚀”是对该项目的标识,表明它与YOLO(You Only Look Once)目标检测算法相关。YOLO是一种流行的实时目标检测系统,广泛应用于计算机视觉领域。
总的来说,这个文件的主要作用是作为包的初始化文件,提供基本的项目标识和许可证信息,确保用户了解该代码的使用条款。
```python
# 导入必要的库
from pathlib import Path
from ultralytics.engine.model import Model
from .predict import FastSAMPredictor
from .val import FastSAMValidator
class FastSAM(Model):
"""
FastSAM模型接口,用于图像分割任务。
示例用法:
```python
from ultralytics import FastSAM
model = FastSAM('last.pt') # 加载模型
results = model.predict('ultralytics/assets/bus.jpg') # 进行预测
```
"""
def __init__(self, model='FastSAM-x.pt'):
"""初始化FastSAM类,调用父类(YOLO)的初始化方法,并设置默认模型。"""
# 如果传入的模型名称是'FastSAM.pt',则使用'FastSAM-x.pt'作为默认模型
if str(model) == 'FastSAM.pt':
model = 'FastSAM-x.pt'
# 确保模型文件后缀不是.yaml或.yml,FastSAM只支持预训练模型
assert Path(model).suffix not in ('.yaml', '.yml'), 'FastSAM模型仅支持预训练模型。'
# 调用父类的初始化方法,设置模型和任务类型为'segment'
super().__init__(model=model, task='segment')
@property
def task_map(self):
"""返回一个字典,将分割任务映射到相应的预测器和验证器类。"""
return {'segment': {'predictor': FastSAMPredictor, 'validator': FastSAMValidator}}
代码注释说明:
- 导入部分:引入必要的模块和类,包括路径处理和模型基类。
- FastSAM类:定义了一个继承自
Model的类,用于处理FastSAM模型的初始化和任务映射。 - 初始化方法:在初始化时,检查模型名称并确保使用的是预训练模型,调用父类的初始化方法。
- 任务映射属性:提供一个字典,将分割任务与相应的预测器和验证器类关联,便于后续调用。```
这个程序文件定义了一个名为FastSAM的类,属于 Ultralytics YOLO 框架的一部分,主要用于图像分割任务。文件中首先导入了必要的模块,包括Path用于处理文件路径,以及从ultralytics.engine.model导入的Model类,后者是 FastSAM 类的父类。此外,还导入了FastSAMPredictor和FastSAMValidator,它们分别用于预测和验证的功能。
FastSAM 类的文档字符串中提供了一个简单的使用示例,展示了如何加载模型并对图像进行预测。构造函数 __init__ 接受一个模型文件名作为参数,默认值为 'FastSAM-x.pt'。在构造函数中,如果传入的模型名是 'FastSAM.pt',则将其更改为 'FastSAM-x.pt'。接着,使用 assert 语句确保传入的模型文件不是 YAML 格式,因为 FastSAM 只支持预训练模型。最后,调用父类的构造函数,传递模型路径和任务类型(在这里是 ‘segment’)。
类中还有一个名为 task_map 的属性,它返回一个字典,映射了分割任务到相应的预测器和验证器类。这使得 FastSAM 类能够灵活地处理不同的任务,便于扩展和维护。整体来看,这个文件为 FastSAM 模型提供了一个清晰的接口,方便用户进行图像分割操作。
```python
import torch
import torch.nn as nn
def select_candidates_in_gts(xy_centers, gt_bboxes, eps=1e-9):
"""
选择在真实框(gt)内的正锚点中心。
参数:
xy_centers (Tensor): 形状为(h*w, 2)的张量,表示锚点中心的坐标。
gt_bboxes (Tensor): 形状为(b, n_boxes, 4)的张量,表示真实框的坐标。
返回:
(Tensor): 形状为(b, n_boxes, h*w)的张量,表示每个真实框内的锚点。
"""
n_anchors = xy_centers.shape[0] # 锚点数量
bs, n_boxes, _ = gt_bboxes.shape # 批量大小和真实框数量
lt, rb = gt_bboxes.view(-1, 1, 4).chunk(2, 2) # 分离左上角和右下角坐标
bbox_deltas = torch.cat((xy_centers[None] - lt, rb - xy_centers[None]), dim=2).view(bs, n_boxes, n_anchors, -1)
return bbox_deltas.amin(3).gt_(eps) # 返回每个锚点是否在真实框内的布尔值
class TaskAlignedAssigner(nn.Module):
"""
用于目标检测的任务对齐分配器。
属性:
topk (int): 考虑的候选框数量。
num_classes (int): 目标类别数量。
alpha (float): 分类组件的权重。
beta (float): 定位组件的权重。
eps (float): 防止除零的小值。
"""
def __init__(self, topk=13, num_classes=80, alpha=1.0, beta=6.0, eps=1e-9):
"""初始化任务对齐分配器对象,设置超参数。"""
super().__init__()
self.topk = topk
self.num_classes = num_classes
self.bg_idx = num_classes # 背景类别索引
self.alpha = alpha
self.beta = beta
self.eps = eps
@torch.no_grad()
def forward(self, pd_scores, pd_bboxes, anc_points, gt_labels, gt_bboxes, mask_gt):
"""
计算任务对齐分配。
参数:
pd_scores (Tensor): 形状为(bs, num_total_anchors, num_classes)的张量,表示预测得分。
pd_bboxes (Tensor): 形状为(bs, num_total_anchors, 4)的张量,表示预测框。
anc_points (Tensor): 形状为(num_total_anchors, 2)的张量,表示锚点坐标。
gt_labels (Tensor): 形状为(bs, n_max_boxes, 1)的张量,表示真实框标签。
gt_bboxes (Tensor): 形状为(bs, n_max_boxes, 4)的张量,表示真实框坐标。
mask_gt (Tensor): 形状为(bs, n_max_boxes, 1)的张量,表示有效真实框的掩码。
返回:
target_labels (Tensor): 形状为(bs, num_total_anchors)的张量,表示目标标签。
target_bboxes (Tensor): 形状为(bs, num_total_anchors, 4)的张量,表示目标框。
target_scores (Tensor): 形状为(bs, num_total_anchors, num_classes)的张量,表示目标得分。
fg_mask (Tensor): 形状为(bs, num_total_anchors)的布尔张量,表示前景锚点。
target_gt_idx (Tensor): 形状为(bs, num_total_anchors)的张量,表示目标真实框索引。
"""
self.bs = pd_scores.size(0) # 批量大小
self.n_max_boxes = gt_bboxes.size(1) # 最大真实框数量
if self.n_max_boxes == 0: # 如果没有真实框
device = gt_bboxes.device
return (torch.full_like(pd_scores[..., 0], self.bg_idx).to(device),
torch.zeros_like(pd_bboxes).to(device),
torch.zeros_like(pd_scores).to(device),
torch.zeros_like(pd_scores[..., 0]).to(device),
torch.zeros_like(pd_scores[..., 0]).to(device))
# 获取正锚点掩码和对齐度量
mask_pos, align_metric, overlaps = self.get_pos_mask(pd_scores, pd_bboxes, gt_labels, gt_bboxes, anc_points, mask_gt)
# 选择具有最高重叠的锚点
target_gt_idx, fg_mask, mask_pos = select_highest_overlaps(mask_pos, overlaps, self.n_max_boxes)
# 获取目标标签、框和得分
target_labels, target_bboxes, target_scores = self.get_targets(gt_labels, gt_bboxes, target_gt_idx, fg_mask)
# 归一化对齐度量
align_metric *= mask_pos
pos_align_metrics = align_metric.amax(dim=-1, keepdim=True) # 正锚点的最大对齐度量
pos_overlaps = (overlaps * mask_pos).amax(dim=-1, keepdim=True) # 正锚点的最大重叠
norm_align_metric = (align_metric * pos_overlaps / (pos_align_metrics + self.eps)).amax(-2).unsqueeze(-1)
target_scores = target_scores * norm_align_metric # 更新目标得分
return target_labels, target_bboxes, target_scores, fg_mask.bool(), target_gt_idx
def get_pos_mask(self, pd_scores, pd_bboxes, gt_labels, gt_bboxes, anc_points, mask_gt):
"""获取在真实框内的掩码。"""
mask_in_gts = select_candidates_in_gts(anc_points, gt_bboxes) # 选择在真实框内的锚点
align_metric, overlaps = self.get_box_metrics(pd_scores, pd_bboxes, gt_labels, gt_bboxes, mask_in_gts * mask_gt) # 计算对齐度量和重叠
mask_topk = self.select_topk_candidates(align_metric, topk_mask=mask_gt.expand(-1, -1, self.topk).bool()) # 选择前k个候选
mask_pos = mask_topk * mask_in_gts * mask_gt # 合并掩码
return mask_pos, align_metric, overlaps
def get_box_metrics(self, pd_scores, pd_bboxes, gt_labels, gt_bboxes, mask_gt):
"""计算给定预测框和真实框的对齐度量。"""
na = pd_bboxes.shape[-2] # 锚点数量
mask_gt = mask_gt.bool() # 转换为布尔类型
overlaps = torch.zeros([self.bs, self.n_max_boxes, na], dtype=pd_bboxes.dtype, device=pd_bboxes.device) # 初始化重叠矩阵
bbox_scores = torch.zeros([self.bs, self.n_max_boxes, na], dtype=pd_scores.dtype, device=pd_scores.device) # 初始化得分矩阵
ind = torch.zeros([2, self.bs, self.n_max_boxes], dtype=torch.long) # 初始化索引
ind[0] = torch.arange(end=self.bs).view(-1, 1).expand(-1, self.n_max_boxes) # 批量索引
ind[1] = gt_labels.squeeze(-1) # 真实框标签索引
bbox_scores[mask_gt] = pd_scores[ind[0], :, ind[1]][mask_gt] # 获取每个锚点的得分
# 计算重叠
pd_boxes = pd_bboxes.unsqueeze(1).expand(-1, self.n_max_boxes, -1, -1)[mask_gt]
gt_boxes = gt_bboxes.unsqueeze(2).expand(-1, -1, na, -1)[mask_gt]
overlaps[mask_gt] = bbox_iou(gt_boxes, pd_boxes, xywh=False, CIoU=True).squeeze(-1).clamp_(0) # 计算IoU
align_metric = bbox_scores.pow(self.alpha) * overlaps.pow(self.beta) # 计算对齐度量
return align_metric, overlaps
def get_targets(self, gt_labels, gt_bboxes, target_gt_idx, fg_mask):
"""
计算正锚点的目标标签、目标框和目标得分。
参数:
gt_labels (Tensor): 真实框标签。
gt_bboxes (Tensor): 真实框坐标。
target_gt_idx (Tensor): 正锚点的真实框索引。
fg_mask (Tensor): 前景锚点的掩码。
返回:
(Tuple[Tensor, Tensor, Tensor]): 包含目标标签、目标框和目标得分的元组。
"""
batch_ind = torch.arange(end=self.bs, dtype=torch.int64, device=gt_labels.device)[..., None]
target_gt_idx = target_gt_idx + batch_ind * self.n_max_boxes # 计算目标真实框索引
target_labels = gt_labels.long().flatten()[target_gt_idx] # 获取目标标签
target_bboxes = gt_bboxes.view(-1, 4)[target_gt_idx] # 获取目标框
target_labels.clamp_(0) # 限制标签值
# 初始化目标得分
target_scores = torch.zeros((target_labels.shape[0], target_labels.shape[1], self.num_classes),
dtype=torch.int64,
device=target_labels.device) # (b, h*w, 80)
target_scores.scatter_(2, target_labels.unsqueeze(-1), 1) # 设置目标得分
fg_scores_mask = fg_mask[:, :, None].repeat(1, 1, self.num_classes) # 扩展前景掩码
target_scores = torch.where(fg_scores_mask > 0, target_scores, 0) # 仅保留前景得分
return target_labels, target_bboxes, target_scores
代码说明
- 选择锚点:
select_candidates_in_gts函数用于判断锚点是否在真实框内,并返回一个布尔张量。 - 任务对齐分配器:
TaskAlignedAssigner类负责将真实框分配给锚点,计算对齐度量,并返回目标标签、框和得分。 - 对齐度量计算:通过比较预测框和真实框的得分与重叠度,计算对齐度量。
- 目标生成:
get_targets函数生成目标标签、框和得分,确保它们与前景锚点对应。
此代码的核心在于实现了目标检测中的锚点分配机制,确保每个锚点能够正确地与真实框进行匹配。```
这个程序文件是一个用于目标检测的任务对齐分配器(TaskAlignedAssigner)的实现,主要用于将真实目标(ground truth,gt)分配给锚框(anchors)。文件中使用了PyTorch库,包含了多个函数和一个类,以下是对代码的详细讲解。
首先,文件导入了必要的库,包括PyTorch的核心模块和一些自定义的检查和度量模块。check_version函数用于检查PyTorch的版本,bbox_iou和wasserstein_loss则是用于计算边界框的交并比和Wasserstein损失的函数。
接下来,定义了select_candidates_in_gts函数,该函数用于选择在真实目标框内的锚框中心。它接受锚框中心和真实目标框作为输入,返回一个布尔张量,指示哪些锚框中心在真实目标框内。
然后是select_highest_overlaps函数,它用于处理锚框与多个真实目标框的重叠情况。如果一个锚框被分配给多个真实目标框,则选择与之重叠度最高的目标框。
接下来定义了TaskAlignedAssigner类,这是目标检测中的一个重要组件。该类的构造函数接受多个参数,包括考虑的候选框数量、类别数量、分类和定位的权重等。forward方法是该类的核心,用于计算任务对齐的分配。它接受预测的分数、边界框、锚框点、真实标签和边界框等信息,并返回目标标签、目标边界框、目标分数、前景掩码和目标索引。
在forward方法中,首先检查真实目标框的数量,如果没有目标框,则返回默认值。然后调用get_pos_mask方法获取正样本掩码和对齐度量。接着,使用select_highest_overlaps函数选择重叠度最高的目标框,并调用get_targets方法计算目标标签、边界框和分数。
get_pos_mask方法用于获取在真实目标框内的锚框掩码,并计算对齐度量和重叠度。get_box_metrics方法计算预测边界框与真实边界框之间的对齐度量。select_topk_candidates方法根据给定的度量选择前k个候选框。
get_targets方法计算正样本的目标标签、边界框和分数。它根据目标索引和前景掩码返回相应的目标信息。
文件的最后部分定义了一些辅助函数,包括make_anchors用于生成锚框,dist2bbox用于将距离转换为边界框,bbox2dist用于将边界框转换为距离。这些函数为目标检测的锚框生成和转换提供了支持。
总体来说,这个文件实现了一个复杂的目标检测分配机制,通过结合分类和定位信息来优化锚框与真实目标之间的匹配,提升目标检测的性能。
源码文件
源码获取
欢迎大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 27
27 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)