数据集转换_机器学习项目之照片分拣02:创建照片分类数据集
【导读:本文为照片分拣机器学习项目系列文章的第2篇,介绍如何读取不同文件夹下、不同大小的jpg格式图片,压缩至相同大小,创建csv分类数据集,用于后续分类模型的训练】
项目系列文章请查看:
机器学习项目之照片分拣01:项目概述
机器学习项目之照片分拣02:创建照片分类数据集(本文)
机器学习项目之照片分拣03:训练照片分类模型
机器学习项目之照片分拣04:预测新照片类别并分别存放
项目演示视频
要实现照片的预测和分拣,首先要构建一个打好标签的图片数据集,用来训练分类模型。本文介绍如何使用Python将收集的人物和花卉图片创建为csv格式的分类数据集。
一、基本思路
首先收集照片,将照片分类别保存在计算机硬盘上;分类别逐张读取图片,将它们压缩到相同形状;创建空的特征集和目标集列表;将压缩的每张图片展平为1行,添加到特征集的尾部,同时将图片的类标签添加到目标集的尾部;更新特征集的形状,使列数相同,行数等于所有图片数量;将特征集和目标集保存为csv数据文件。
二、收集图片
收集两种类别的图片(本项目方法可以扩充到更多类别):人物和花卉,图片为jpg格式,大小可以不同,如下图所示。

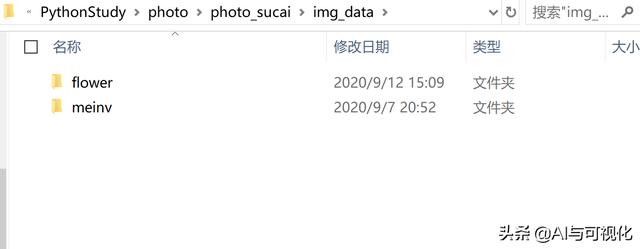
将它们分类别保存到同一路径下的不同子文件夹。子文件夹的名称以图片的类别命名。如本项目将保存人物和花卉图片的文件夹分别以meinv, flower命名,如下图所示。
三、获取每个图片文件夹的名称
使用os模块的listdir()方法,可以获取指定路径下的文件夹和文件名称。代码如下:
import numpy as npimport pandas as pdimport ospath_frames='.../img_data/' #各类别图片文件夹的上一级路径source_category_list = os.listdir(path_frames) #获取图片文件夹名称列表print('compressed目录下的子目录为:',source_category_list)运行结果返回一个列表,列表的元素是每个子文件夹的名称,如下图所示:

四、读取每个文件夹下每张图片,压缩、展平、添加到特征集和目标集
要读取每张图片,首先要拼出每张图片的全路径名称。可以这样实现:对source_category_list的每个元素(即子文件夹名称),拼出到达子文件夹的路径。
然后对每个全路径子文件夹名称,使用listdir()方法获取其保存的所有图像文件名称的列表。对该列表的每个元素,可以拼出图像文件的全路径名称。
然后使用OpenCV的cv2.imread()方法即可读取图片,进而进行压缩、展平、添加到特征集和目标集等操作。这需要创建两重循环,实现代码如下:
import cv2#生成图像数据集,一行数据(即一个样本)为一副图像print('图像批量读取中,请耐心等待......')X=[] #用于保存图像特征集y=[] #用于保存图像标签集y_dict={'meinv':0,'flower':1}#字典,将类别名称转换为数字标签for mydir in source_category_list: #拼出存放原始文件的目录(即类别)路径 source_category_path = path_frames+ mydir + "/" #获取某一目录(类别)中的所有文件 source_file_list = os.listdir(source_category_path) for file_name in source_file_list: full_name=path_frames+mydir+'/'+file_name img0=cv2.imread(full_name,cv2.IMREAD_UNCHANGED) img0=cv2.resize(img0,(50,50)) #压缩为50*50大小 X=np.append(X,img0.ravel()) #展平,添加到X尾部 y=np.append(y,y_dict[mydir]) #查询字典,转换为类标签,添加到y的尾部 X=X.reshape(-1,50*50*3) #将X的形状改变为50*50*3列,自动推断行数 print('此时数据集的形状为:',X.shape)print('数据集的形状为:',X.shape)print('图像批量读取完毕!')执行完上述代码,所有的图像数据和它们的类标签都保存在了X, y列表中。上面的代码使用了字典,它用于将类别型类标签转换为数字型类标签。读取的每张图片,不管原来的大小如何,统统暴力压缩为50*50的分辨率。X中,每一行代表一幅压缩后的图像,它包含了B, G, R三个通道的像素值。
如果你还不知道如何安装OpenCV, 可以在prompt窗口执行如下命令:
pip install opencv-python如果下载速度较慢,可以选择国内的清华大学镜像快速安装,方法是在prompt窗口执行如下命令:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple opencv_python五、将特征集X、目标集y保存为csv文件
使用pandas模块的.to_csv()方法,可以很方便地把数组、列表保存为csv文件。其前提是首先要使用DataFrame()方法将数组或列表转换为DataFrame对象。
#将X, y转换为DataFrame对象,保存为csv文件path_data='D:/PythonStudy/human_flower_cla/data/' #图像数据集要保存的目标文件夹#如果path_data不存在,则创建它if not os.path.exists(path_data): os.makedirs(path_data)df_images_data=pd.DataFrame(X) #将X转换为DataFrame对象#保存为csv文本文件df_images_data.to_csv(path_data+'human_flower_data.csv',sep = ',',index = False) df_images_target=pd.DataFrame(y) #将y转换为DataFrame对象#保存为csv文本文件df_images_target.to_csv(path_data+'human_flower_target.csv',sep = ',',index = False) print('图像数据集转换为DataFrame并保存完毕!')执行上述代码,将把特征集X和目标集y保存为csv文件,在计算机硬盘上可以找到它们,如下图所示:

需要说明的是,csv文件元素间尽量使用逗号','分割,这样你可以很方便的使用Excel, WPS表格打开它。也可以使用记事本打开它。
到此,把meinv和flower两个文件夹下的所有图像保存为csv数据集,同时创建了标签集。这样,在后续训练分类模型时,可以很从容地使用该数据集。
当然,你可以尝试把更多类别的图片(增加保存图片的子文件夹即可)保存为csv数据集,创建多元分类数据集。
要训练分类模型,请关注后续文章。感兴趣的朋友,现在可以动手收集照片,创建你自己的数据集了。
更多精彩内容,请关注本号。欢迎转发、评论、拍砖、交流。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 0
0 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)