阿里连发三大具身大模型,VLN、VLA、世界模型一起跑?
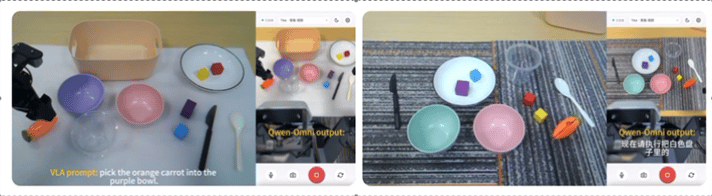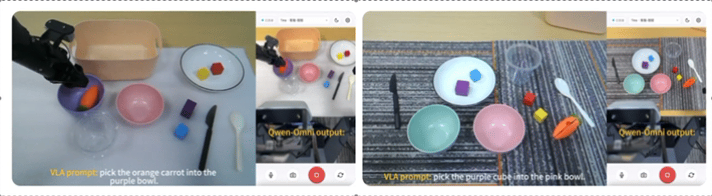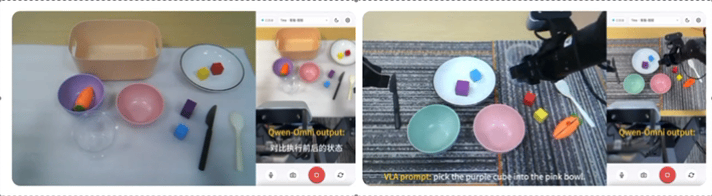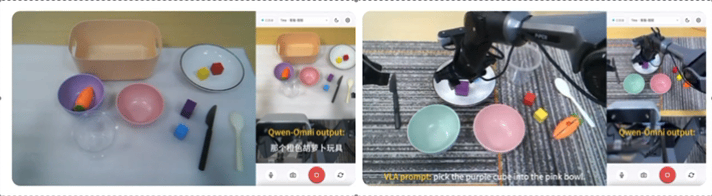
阿里发布首个完整的具身智能大模型系列Qwen-Robot
——在异构的物理世界里,“对齐” 才是规模化的前提
目录
Qwen-RobotManip:用 “相机坐标系” 统一异构机器人
Qwen-RobotWorld:用 “自然语言” 统一动作空间
近日,阿里巴巴正式推出Qwen-Robot 千问具身智能大模型全套套件,一口气发布三大核心模型,为机器人打造完整通用底座。
VLN移动模型:Qwen-RobotNav
VLA操作模型:Qwen-RobotManip
世界模型:Qwen-RobotWorld
用一套全新技术逻辑给出答案:在复杂异构的物理世界中,对齐能力才是模型规模化落地的核心前提。

▲Qwen-Robot Suite
01 对齐先于规模
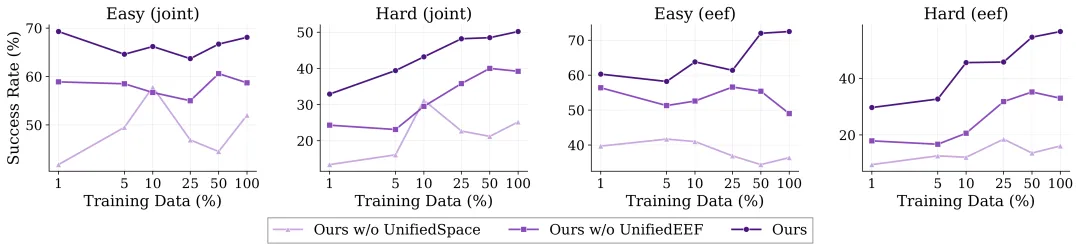
Qwen-RobotManip 的实验给出结论:当模型没有统一的跨本体表示时,数据规模曲线是抖动的、甚至持平的。
也就是说规模化无法弥补未对齐表征框架的固有缺陷。
这与行业主流路径形成了鲜明对比。Google RT-2、DeepMind RoboCat、OpenAI π0.5 等模型,本质上走的是 “暴力堆数据” 路线:用更大的数据集、更强的算力、更统一的 tokenization 来强行抹平异构性。
而阿里的判断是:在物理世界,异构性不是可以被算力抹平的噪声,而是需要被 “对齐” 的结构性问题。
这一发现贯穿了整个 Qwen-Robot Suite。三个模型:Nav、Manip、World,分别用三种不同的对齐策略,解决三种不同类型的物理动作与语言之间的鸿沟。
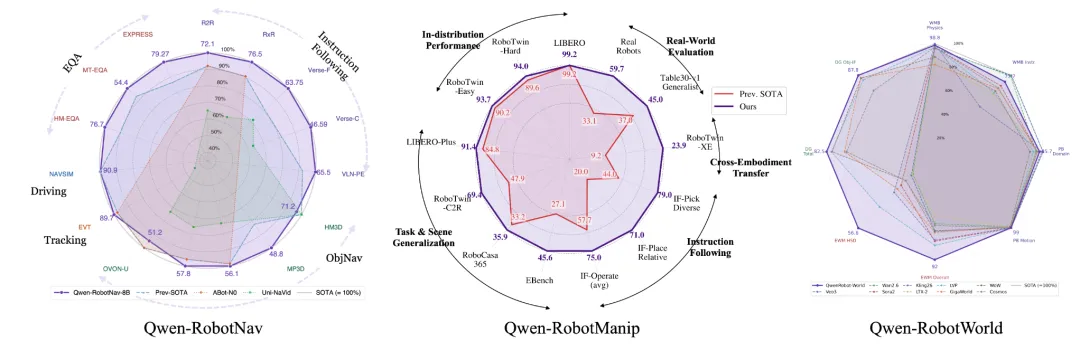
▲Qwen-Robot Suite 三个基础模型
02 三个模型,三种对齐策略
Qwen-RobotNav:把 “视觉历史” 变成可调节参数
导航的核心矛盾是:不同任务对历史信息的需求差异巨大。指令跟随需要保留长程上下文,目标追踪则几乎只关注最近几帧。
任何固定的视觉分配策略都无法同时满足。
Qwen-RobotNav 的解法是将视觉分配策略本身参数化。
四个控制轴:视觉 token 预算、时间衰减、逐相机权重、帧采样模式,作为推理时参数暴露出来。
模型在 1560 万条样本上训练,同时联合视觉语言数据以保留感知能力,一套权重统一了五类导航任务。
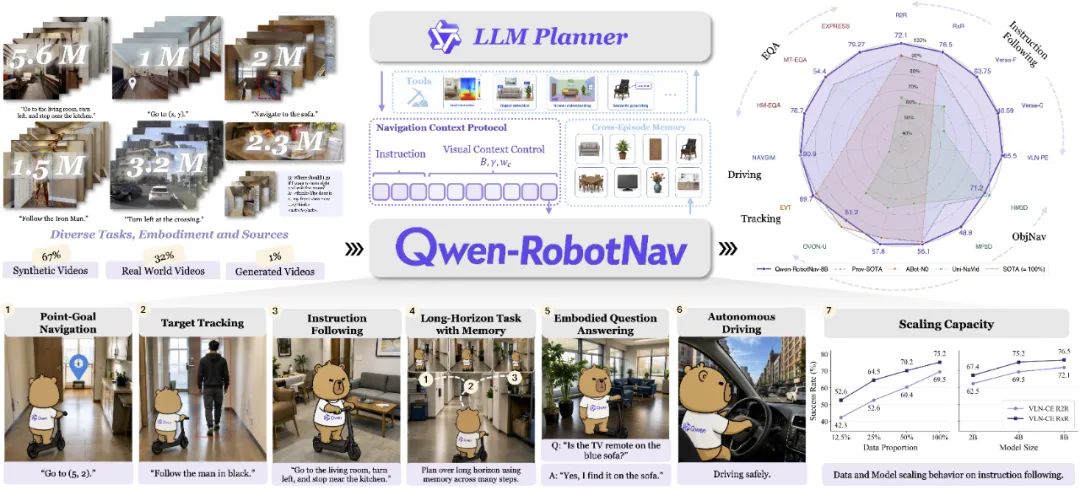
▲Qwen-RobotNav框架
它让 Nav 天然适合作为智能体系统中的 “导航工具”。
上层规划器可以在执行过程中动态切换任务模式和上下文策略,通过反复调用同一模型来组合复杂行为。
在 EXPRESS-Bench 上,这种 “导航即工具调用” 的架构提升了 15.4% 的成功率,导航步数减少 77%。
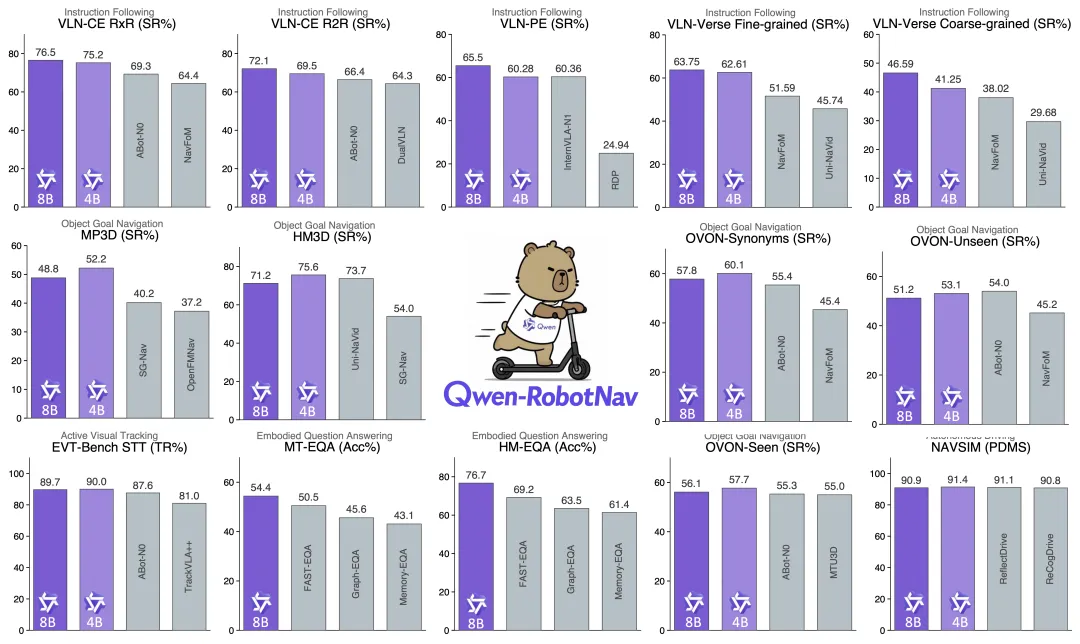
▲Qwen-RobotNav 基准测试结果
在 Unitree Go2 四足机器人上,仅使用单个低分辨率摄像头,推理延迟 196ms,就能在从未见过的公寓中执行自由自然语言指令。这证明了对齐策略带来的泛化能力,而非过拟合。
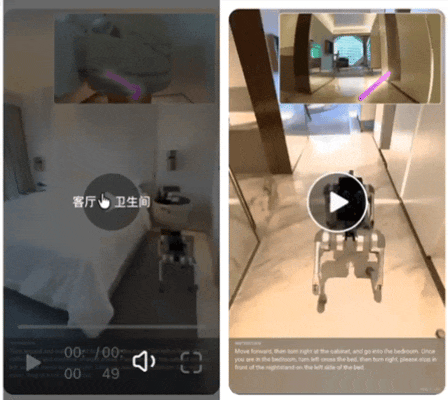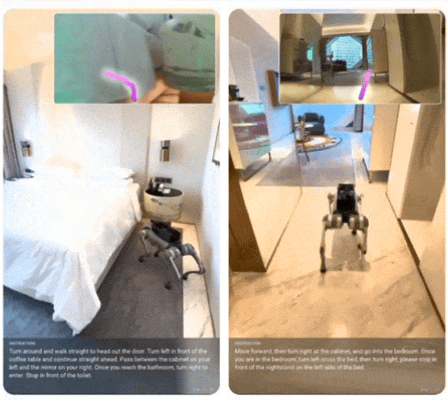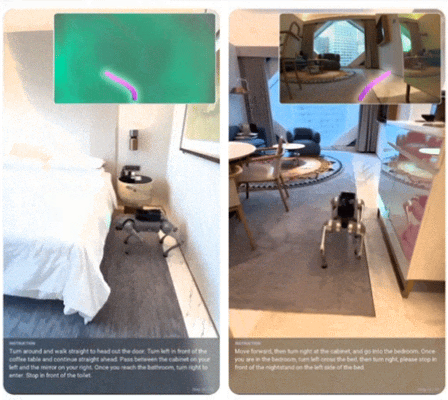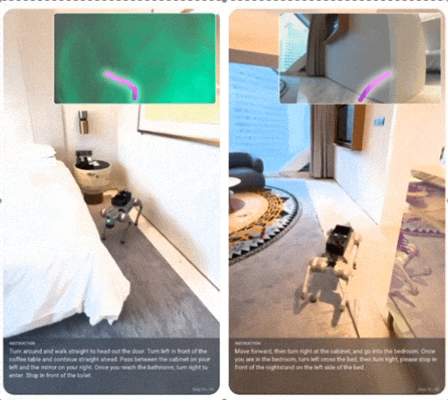
Qwen-RobotManip:用 “相机坐标系” 统一异构机器人
操作的核心矛盾是:产线上的工业臂与厨房中的服务臂,抓取动作视觉上可能非常相似,但关节配置和动作空间截然不同。
Qwen-RobotManip 的解法是三维对齐框架:
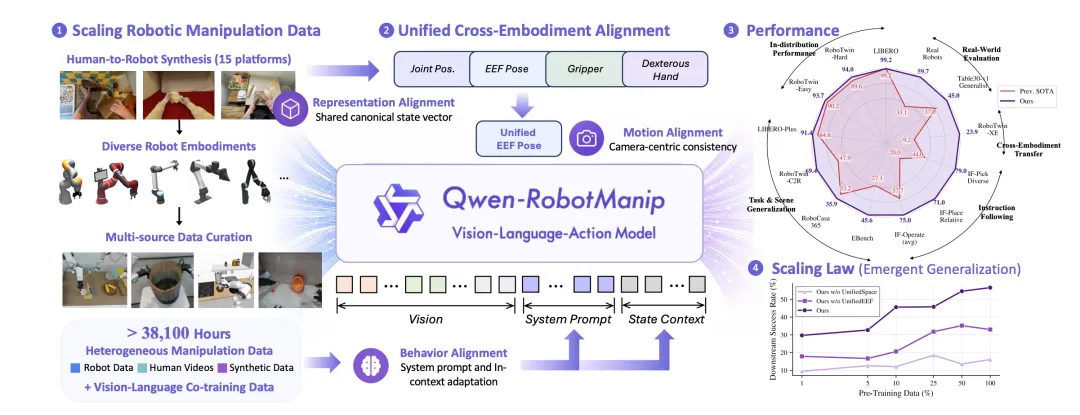
▲Qwen-RobotManip
- 表示对齐:统一的 80 维状态 - 动作表示,通过维度二进制掩码兼容单臂、双臂、灵巧手等不同本体
- 运动对齐:相机坐标系下的末端执行器增量位姿,使视觉上相似的运动在不同机器人之间数值上也相近
- 行为对齐:上下文策略自适应,将执行历史视为隐式的本体标识,实现推理时在线校准

▲核心亮点,来源官网
其中,相机坐标系增量位姿是最关键的创新。
传统方法用基座坐标系或末端执行器局部坐标系表示动作,但这导致同一物理运动在不同机器人上数值差异巨大。而相机坐标系的增量位姿,让 “视觉上看到的运动” 与 “数值上表示的运动” 直接对齐。
这正是 VLA 模型需要的,因为它的输入是视觉观测。
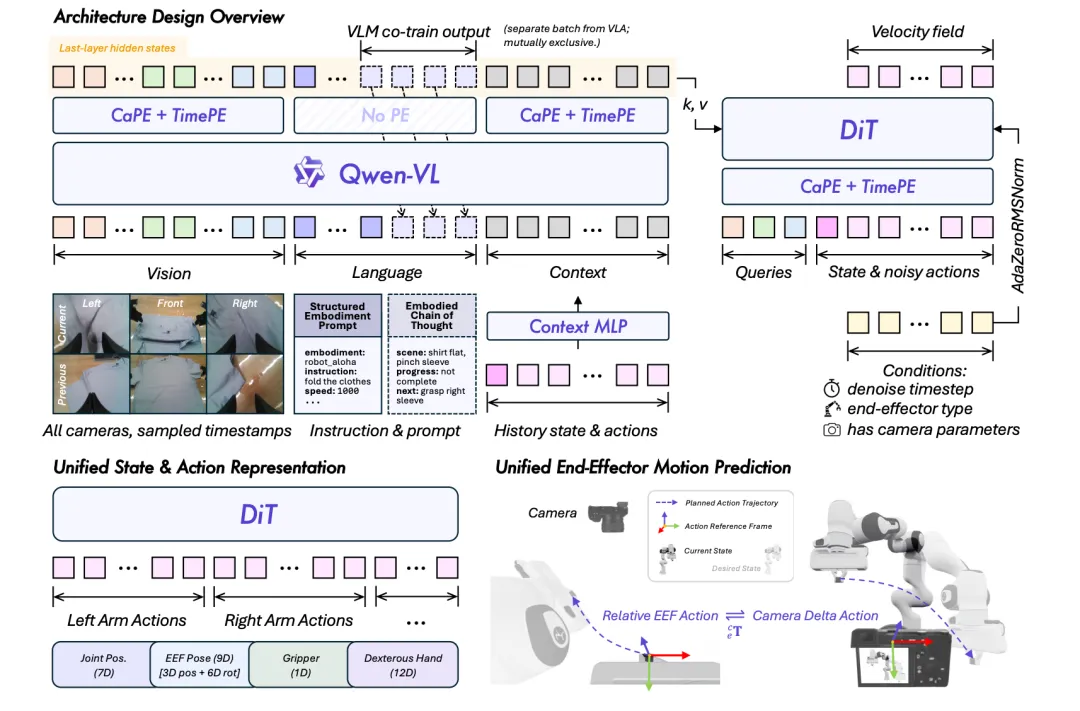
▲QWEN-ROBOTMANIP总览
基于这一对齐框架,Qwen-RobotManip 仅依靠开源数据就构建了超过 38,100 小时的操作语料库:包括 11,320 小时开源机器人数据、1,933 小时第一人称人类视频,以及通过人 - 机迁移合成管线生成的 24,808 小时跨 15 个本体的机器人数据。

▲数据合成pipeline
在 RoboChallenge Table30 v1 通用赛道以 45% SR 排名第一,包揽冠亚,领先季军 20%;在 LIBERO-Plus 达到 91.4%,超越 π0.5 7 个百分点。
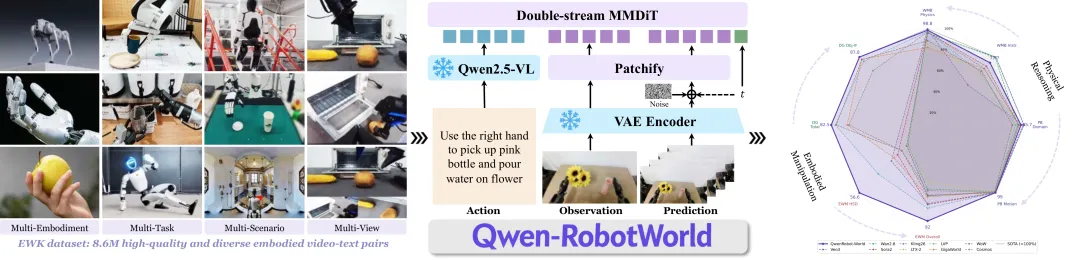
Qwen-RobotWorld:用 “自然语言” 统一动作空间
如果说 Nav 和 Manip 解决的是 “现在该做什么”,World 解决的则是 “接下来会发生什么”。
Qwen-RobotWorld 的核心设计选择是将所有动作以自然语言表达。
这将末端执行器位姿、转向指令、导航路标点统一为单一接口,使 20 余种本体类型和 500 余个动作类别得以在具身世界知识语料库(860 万视频 - 文本对,逾 2 亿帧)下协同训练。
这是因为自然语言是物理世界的 “通用坐标系”。
在大模型时代,自然语言统一了文本、图像、音频的接口;在具身智能时代,自然语言正在统一机器人的动作空间。
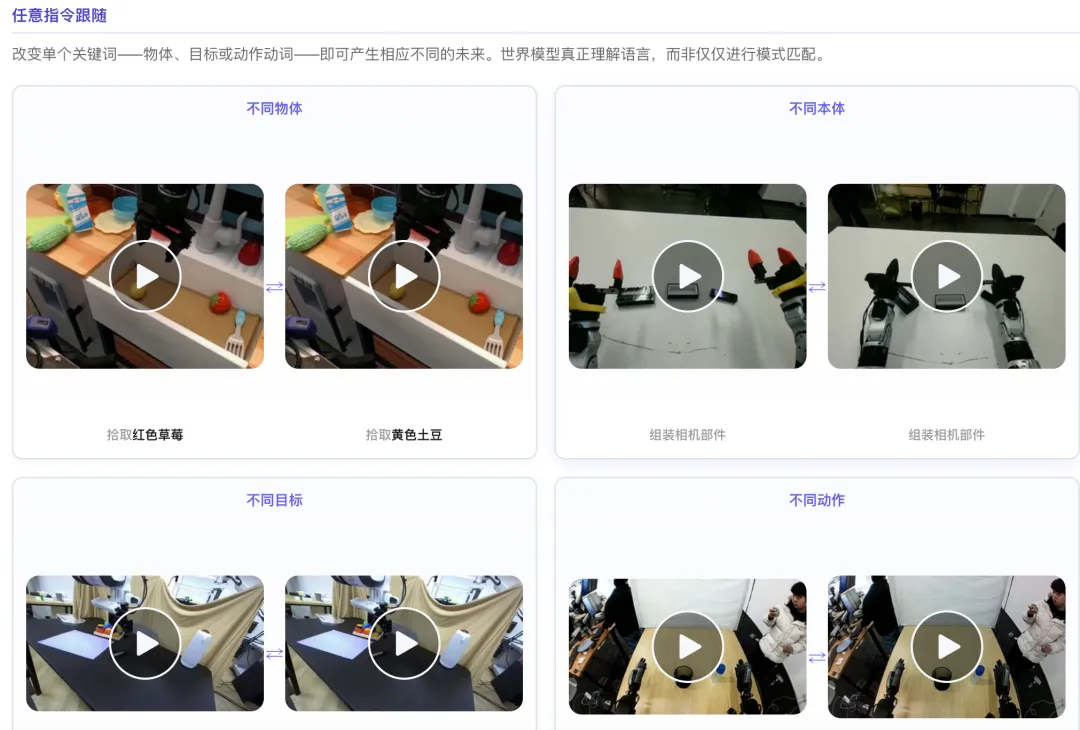
一个指令如 “拿起红色杯子”,隐式编码了完整的动作序列、目标状态和物理约束,无需了解底层的运动学链。
▲部分视角实例
另一个关键设计是用完整的多模态大语言模型(Qwen2.5-VL)作为动作编码器,而非轻量级文本编码器。
这带来了内化的世界知识:手臂是刚体、液体会扩散、物体会下落……从而隐式地将生成约束为物理上可信的未来。
在 WorldModelBench 上,模型在牛顿定律、质量守恒、流体动力学等物理规律遵循上达到完美分数。
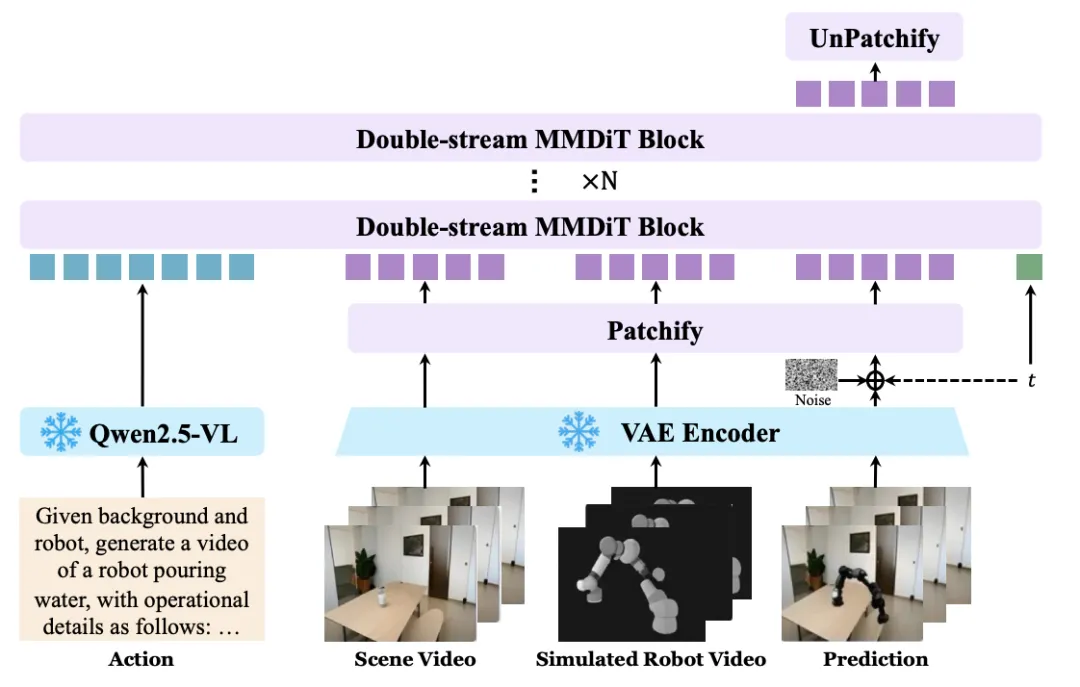
▲Scene2Robot:面向跨本体视频合成的多段条件控制
不同领域的数据相互强化:操作教会接触物理,驾驶教会大尺度三维几何,导航教会房间级别的空间推理。
这种 “互补强化” 效应是单领域模型无法企及的。
03 从模型到智能体:Qwen-RobotClaw 的闭环
三个模型各自独立可用,但由于它们都提供语言优先的接口,通用 Qwen 模型可以将它们作为物理世界工具进行组合。
这就是内部项目Qwen-RobotClaw,使 Qwen VLM 智能体能够将 Qwen-Robot Suite 模型作为物理世界工具调用。
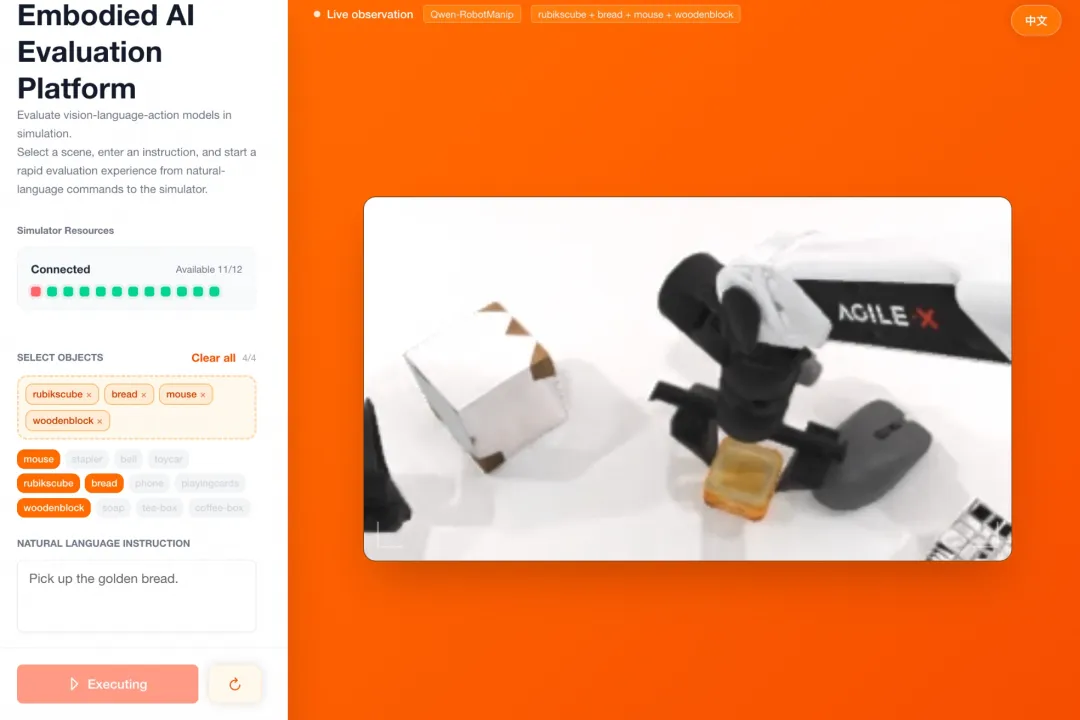
▲Chat2Robot
这种 “上层规划 + 底层执行” 的分工,大幅提升了模型在分布外场景和指令下的鲁棒性。
04 与主流路径的差异
将 Qwen-Robot Suite 放在行业坐标系中观察,可以清晰地看到阿里的差异化路径:

最值得关注的差异是数据策略。
Qwen-RobotManip 完全不依赖专有遥操作数据,而是通过人 - 机迁移合成管线将人类视频转化为机器人数据。
05 一个能够去往任何地方、做任何事情的物理智能体
Qwen-Robot Suite 是一个完整的 “第一步”,但物理世界智能仍处于起步阶段。
涉及复杂接触的长程任务、终身学习、通用规划器与物理执行器的深度融合,都仍是开放问题。
但前行的路径正愈发清晰:从强大的多模态理解出发,将视觉语言表示空间桥接至每一类物理行动,扩大训练规模,并以泛化能力作为衡量成功的北极星。
一个能够去往任何地方、做任何事情,并预见行动后果的物理智能体
——这是阿里的目标。
Ref
1、 Qwen-Robot Suite:迈向物理世界智能的基础模型套件
2、 Qwen-RobotWorld Technical Report: Unifying Embodied WorldModeling through Language-Conditioned Video Generation
3、 Qwen-RobotManip Technical Report: Alignment Unlocks Scale forRobotic Manipulation Foundation Models

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 6
6 0
0- 0



 已为社区贡献95条内容
已为社区贡献95条内容

所有评论(0)