Microsoft Access数据库(mdb格式)操作实战案例
数据库(Database)是一系列有组织的数据集合,它能够让我们有效地存储、检索和管理信息。在技术层面,数据库是通过数据库管理系统(DBMS)来创建、维护和使用的数据集合。一个数据库系统通常包括存储数据的硬件、管理数据的软件,以及相关的应用程序和计算机系统人员。表(Table):存储数据的基本结构,类似于Excel中的表格,但其数据结构更为复杂和严谨。查询(Query):用于从一个或多个表中检索数

简介:数据库是组织和管理信息的关键技术,本案例专注Microsoft Access数据库文件(mdb),一种流行的桌面数据库管理系统。文章将详细讲解如何使用SQL语言进行基本的数据查询和排序操作,以及Access中的高级功能,如创建查询、窗体、报表和宏。通过分析压缩包文件“PopManu”,读者将了解到数据库结构、管理数据、执行管理和分析任务的具体方法。学习这些技能对于数据管理至关重要,有助于提高工作效率和数据驱动决策能力。 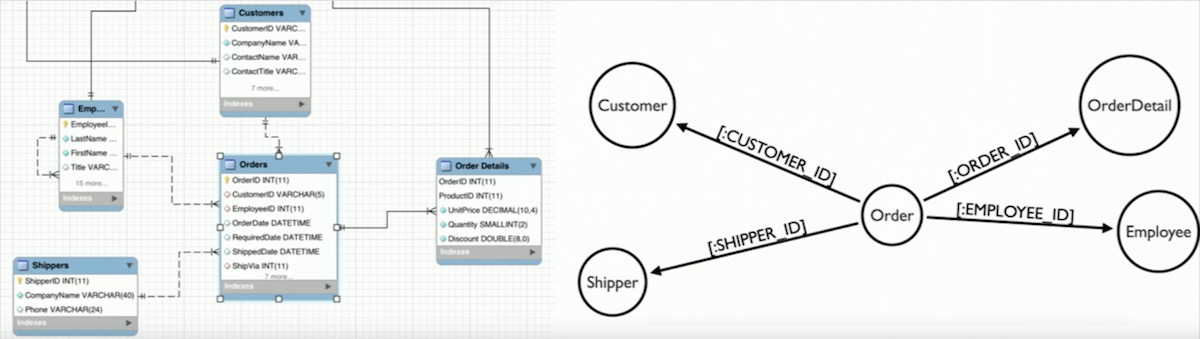
1. Access数据库基础与结构
1.1 Access数据库概述
1.1.1 数据库的基本概念
数据库(Database)是一系列有组织的数据集合,它能够让我们有效地存储、检索和管理信息。在技术层面,数据库是通过数据库管理系统(DBMS)来创建、维护和使用的数据集合。一个数据库系统通常包括存储数据的硬件、管理数据的软件,以及相关的应用程序和计算机系统人员。
1.1.2 Access数据库的特点和应用
Microsoft Access 是一个流行的数据库管理系统,其特点是易于使用、界面直观、并且拥有足够的功能来支持小型到中型的数据库需求。Access数据库通常用于个人项目、小企业以及部门级应用。它支持表、查询、表单、报表和宏等对象类型,适用于数据管理、报告、数据分析、表单和定制的办公自动化解决方案。
1.2 数据库对象的类型与功能
1.2.1 表、查询、表单、报表和宏的对象介绍
- 表(Table) :存储数据的基本结构,类似于Excel中的表格,但其数据结构更为复杂和严谨。
- 查询(Query) :用于从一个或多个表中检索数据。在Access中,查询可用于搜索、排序和汇总数据。
- 表单(Form) :用于数据输入和显示的界面,它提供了一个用户友好的方式来查看、添加或编辑表中的数据。
- 报表(Report) :用于打印和显示整理好的数据,可以按需格式化数据并支持多种布局。
- 宏(Macro) :一系列操作的集合,可以自动化常规任务,如数据输入和报告生成。
1.2.2 各对象在数据库中的作用与相互关系
在Access数据库中,这些对象相互协作构成一个完整的数据管理解决方案。例如,表用于存储数据,查询用于提取和处理这些数据,表单和报表分别提供数据的用户界面和最终展示形式,而宏则用于自动化数据库管理任务。理解这些对象如何相互作用,对于设计有效率的数据库系统至关重要。
1.3 数据库的结构设计
1.3.1 数据库规范化理论
数据库规范化是一种设计数据库表结构的过程,目的是减少数据冗余和提高数据完整性。它通常通过一系列规则(范式)来实现,确保每个数据项只在数据库中出现一次。规范化的过程包括几个级别,如第一范式(1NF)、第二范式(2NF)、第三范式(3NF),每个级别解决数据结构设计中的一类问题。
1.3.2 实体-关系模型(ER模型)
实体-关系模型(ER模型)是用来描述现实世界中实体间关系的方法。在数据库设计中,ER模型通常用来创建概念模型,以可视化实体类型、实体属性和实体间关系。ER模型有助于设计良好的数据库结构,确保系统能够准确反映真实世界的业务逻辑。
1.3.3 设计实例:数据库结构图的创建与应用
在Access中创建数据库结构图是为了可视化数据库对象之间的关系,帮助开发者理解并优化数据结构。通过拖放表对象并绘制它们之间的关系线,可以直观地展示哪些表是通过共同字段相互连接的。结构图不仅有助于规划数据库架构,而且是与非技术利益相关者沟通设计意图的有效工具。
这些章节内容为读者提供了一个全面理解Access数据库基础和结构设计的视角,为后续深入探讨具体操作和优化技巧打下了坚实的基础。
2. SQL查询操作基础
2.1 SQL基础语法
2.1.1 SQL语言概述
SQL(Structured Query Language)是一种专门用于数据库管理系统的编程语言,它允许用户创建、查询和修改数据库中的数据。SQL语言不仅包含数据查询语句(SELECT),还包含数据操作语句(如INSERT、UPDATE和DELETE),以及事务控制语句等。SQL是关系数据库的标准语言,因此被广泛应用于多种数据库管理系统中,如MySQL、PostgreSQL、SQLite和Microsoft SQL Server。
SQL语言的核心是关系型数据库理论,基于集合论和关系代数。其特点包括声明性、高度灵活性和强大的数据处理能力。声明性意味着用户只需指出所需的结果类型,数据库管理系统负责找出获取结果的方式。
2.1.2 SELECT语句的使用
SELECT语句是SQL中最为常用的语句之一,用于从数据库中检索数据。其基本语法结构如下:
SELECT column1, column2, ...
FROM table_name;
在这个语句中, SELECT 关键字后跟随要检索的列名,列名之间使用逗号分隔。 FROM 子句后跟随要查询的表名。例如,如果要从 employees 表中检索所有员工的姓名和工资,可以使用以下SQL语句:
SELECT first_name, last_name, salary
FROM employees;
执行结果将返回 employees 表中所有行的 first_name 、 last_name 和 salary 列。
扩展性说明
在SQL中,可以使用 * 符号来选择所有列,如 SELECT * FROM table_name; 。此外, SELECT 语句可以包含多种子句来过滤结果集,例如 WHERE 子句用于条件过滤, ORDER BY 子句用于排序结果集, GROUP BY 子句用于对结果进行分组。
一个完整的 SELECT 语句可以非常复杂,并包含多个子句,例如:
SELECT
department_id,
AVG(salary) AS average_salary
FROM
employees
WHERE
salary > 5000
GROUP BY
department_id
HAVING
AVG(salary) > 7000
ORDER BY
average_salary DESC;
此语句将返回部门ID和平均工资大于7000的部门的平均工资,并按平均工资降序排列。
2.2 SQL中的数据操作
2.2.1 数据的插入、更新和删除
SQL提供了多种数据操作语句,用于向数据库中插入新数据、更新现有数据以及删除不再需要的数据。
插入数据
INSERT INTO 语句用于向表中插入新数据。基本语法如下:
INSERT INTO table_name (column1, column2, ...)
VALUES (value1, value2, ...);
这里, table_name 是要插入数据的表名, column1, column2, ... 是表中的列名, value1, value2, ... 是对应列的值。
例如,要向 employees 表中添加一个新的员工记录,可以使用:
INSERT INTO employees (first_name, last_name, email, department_id)
VALUES ('John', 'Doe', 'johndoe@example.com', 10);
更新数据
UPDATE 语句用于修改表中的现有记录。基本语法如下:
UPDATE table_name
SET column1 = value1, column2 = value2, ...
WHERE condition;
这里, SET 子句用于指定要更新的列及其新值, WHERE 子句用于指定哪些记录需要更新。
例如,要将员工John Doe的工资更新为6000,可以使用:
UPDATE employees
SET salary = 6000
WHERE first_name = 'John' AND last_name = 'Doe';
删除数据
DELETE 语句用于从表中删除记录。基本语法如下:
DELETE FROM table_name WHERE condition;
这里, WHERE 子句用于指定要删除的记录。
例如,要删除工资小于5000的员工记录,可以使用:
DELETE FROM employees
WHERE salary < 5000;
扩展性说明
在使用数据操作语句时,必须谨慎处理 WHERE 子句,因为错误的条件可能导致大量数据的误删除或更新。此外,SQL还支持一些其他子句,如 LIMIT (限制结果数量)和 RETURNING (返回修改后的数据),可以用于更精细的数据操作。
2.3 SQL函数的应用
2.3.1 聚合函数和分组查询
聚合函数对一组值执行计算并返回单一值。在SQL中,常用的聚合函数包括 COUNT , SUM , AVG , MAX , 和 MIN 。
分组查询
使用 GROUP BY 子句可以将结果集分为多个组,并对每个组应用聚合函数。基本语法如下:
SELECT column1, AGGREGATE_FUNCTION(column2)
FROM table_name
GROUP BY column1;
例如,要获取每个部门的平均工资,可以使用:
SELECT department_id, AVG(salary) AS average_salary
FROM employees
GROUP BY department_id;
扩展性说明
在使用聚合函数时,通常会与 HAVING 子句一起使用, HAVING 子句允许设置针对聚合结果的过滤条件。
2.3.2 字符串、日期和数学函数
除了聚合函数,SQL还提供了丰富的字符串、日期和数学函数来处理数据。
字符串函数
字符串函数用于执行各种操作,如连接、截取、转换大小写等。例如, CONCAT() 函数用于连接字符串:
SELECT CONCAT(first_name, ' ', last_name) AS full_name
FROM employees;
日期函数
日期函数处理日期和时间值。例如, NOW() 函数返回当前日期和时间:
SELECT NOW();
数学函数
数学函数执行数学运算,如幂运算、三角函数等。例如, ABS() 函数返回一个数的绝对值:
SELECT ABS(-32);
扩展性说明
字符串、日期和数学函数为数据处理提供了极大的灵活性。在使用这些函数时,可以结合 CASE 语句进行更复杂的条件逻辑处理。
本章节介绍了SQL查询操作的基础语法和数据操作的基本方法,以及如何应用SQL函数进行数据的聚合计算和格式化。接下来的章节将深入探讨数据排序、Access的高级功能,以及数据库维护和优化策略。
3. 数据排序方法与步骤
3.1 数据排序的概念与语法
在数据库管理系统中,排序是经常遇到的操作,它允许用户根据一个或多个列的值来组织查询结果。 ORDER BY 子句是SQL中用来指定排序方式的关键字,基本语法如下:
SELECT column1, column2, ...
FROM table_name
ORDER BY column1 [ASC | DESC], column2 [ASC | DESC], ...;
3.1.1 ORDER BY子句的基本使用
ORDER BY 子句允许对结果集进行排序。默认情况下,排序为升序(ASC),也可以明确指定为 ASC 或 DESC 来进行降序排序。例如,要按照员工的年龄从低到高排序,可以使用:
SELECT * FROM Employees ORDER BY Age ASC;
如果需要按多个列进行排序,只需要在 ORDER BY 子句中添加更多的列名。例如,首先按照部门排序,再按照薪资排序:
SELECT * FROM Employees ORDER BY Department, Salary DESC;
3.1.2 多列排序和排序方向的控制
在多列排序时,结果集首先根据 ORDER BY 子句中的第一列进行排序。如果第一列的值有重复,数据库会根据第二列继续排序,以此类推。通过指定 ASC 或 DESC ,可以控制每个排序列的方向。每个列名前的排序方向声明都是独立的。
SELECT * FROM Employees ORDER BY Department ASC, Salary DESC;
上面的例子中,员工首先按照部门升序排序,如果部门相同,则按照薪资降序排序。
3.2 高级排序技巧
3.2.1 排序规则的定制与使用
不同数据库系统允许用户对排序规则进行定制。例如,对于字符串类型的数据,可以指定不同的排序规则(collation)来决定如何比较字符串。这在多语言环境下尤其有用。
SELECT * FROM Customers ORDER BY LastName COLLATE SQL_Latin1_General_CP1_CI_AI ASC;
上面的SQL语句展示了如何对客户名进行排序,其中 COLLATE SQL_Latin1_General_CP1_CI_AI 是一个排序规则,表示使用不区分大小写的规则进行排序。
3.2.2 在子查询和联合查询中进行排序
排序也可以在子查询或联合查询中使用。这允许在更复杂的查询中保持结果的顺序。例如,可以创建一个子查询,先对数据进行预处理和排序,然后在外部查询中继续使用这些排序后的结果。
SELECT * FROM (
SELECT *, ROW_NUMBER() OVER (ORDER BY Age DESC) AS RowNum
FROM Employees
) AS RankedEmployees
WHERE RowNum <= 10;
这个例子中使用了 ROW_NUMBER() 窗口函数来为每个员工分配一个行号,基于年龄降序排列。然后,外部查询返回行号小于或等于10的员工信息。
3.3 实际应用中的排序优化
3.3.1 性能优化:索引的使用与维护
排序操作在数据库中可能会非常消耗资源,尤其是在大型数据集上。为了解决这个问题,可以使用索引来优化排序。索引能够帮助数据库更快地找到排序依据的列值,从而加快排序速度。但是,索引也有维护成本,因此在设计数据库时需要权衡。
CREATE INDEX idx_age ON Employees(Age);
上述语句创建了一个名为 idx_age 的索引,目的是优化基于 Age 列的排序操作。
3.3.2 复杂场景下的排序问题分析
在复杂的查询中,排序可能会遇到各种问题。例如,在使用联合查询或子查询时,可能需要考虑如何优先排序,以及如何合并排序结果。在这些场景下,必须仔细分析查询逻辑,选择最佳的排序策略,以避免性能下降和结果不准确。
SELECT * FROM (
SELECT * FROM Employees WHERE Department = 'IT'
UNION ALL
SELECT * FROM Employees WHERE Department = 'Sales'
) AS CombinedEmployees
ORDER BY Department, Salary DESC;
这个查询的目的是合并IT部门和销售部门的员工列表,并根据部门名称和薪资进行排序。通过使用 UNION ALL 来合并两个部门的员工,并在外部查询中进行排序,以确保最终结果的顺序性。
通过本章节的介绍,我们深入探讨了数据排序的方法与步骤,了解了排序的基本概念与语法、高级排序技巧,以及如何在实际应用中进行排序优化。通过掌握这些知识,可以有效地控制数据排序,优化查询性能,并在复杂场景下正确地处理数据排序问题。
4. Access高级功能(查询、窗体、报表和宏)
4.1 Access查询的深入使用
4.1.1 多表关联查询和子查询
在Access中,当需要从两个或多个表中提取数据时,可以通过多表关联查询来实现。多表关联查询依赖于各个表之间的共同字段进行数据的整合。SQL中的JOIN语句被用来连接表,它允许从两个或多个表中选取相关联的数据。
关联查询的类型
- 内连接(INNER JOIN) :返回两个表中匹配的数据。
- 左连接(LEFT JOIN) :返回左表中的所有记录,即使右表中没有匹配的记录。
- 右连接(RIGHT JOIN) :返回右表中的所有记录,即使左表中没有匹配的记录。
- 全外连接(FULL JOIN) :返回左表和右表中匹配或不匹配的所有记录。
下面是一个多表关联查询的例子:
SELECT Customers.CustomerName, Orders.OrderID
FROM Customers
INNER JOIN Orders ON Customers.CustomerID = Orders.CustomerID;
在这个例子中, Customers 和 Orders 两个表通过 CustomerID 字段进行关联。执行此查询将返回所有既有客户名称又有订单ID的记录。
使用子查询
子查询是在另一个查询的WHERE子句或HAVING子句中嵌套的查询。子查询可以返回单个值,也可以返回一个结果集。
一个子查询的简单示例:
SELECT ProductName
FROM Products
WHERE ProductID IN (
SELECT ProductID
FROM OrderDetails
WHERE Quantity >= 10
);
在这个例子中,子查询首先从 OrderDetails 表中选择所有 Quantity 大于或等于10的 ProductID 。然后,外层查询利用这些ID从 Products 表中获取 ProductName 。
子查询与JOIN的比较
虽然子查询和JOIN都可以实现复杂的数据查询,但它们各有优劣。子查询可能在某些情况下更易于编写和理解,尤其是在不需要关心数据来源时。然而,在性能方面,特别是在涉及大量数据时,多表连接通常比子查询更高效。
4.1.2 SQL特定查询技巧:联合查询、子查询
在使用Access或任何支持SQL的数据库管理系统时,掌握特定的SQL查询技巧可以更有效地检索和管理数据。除了上述的多表关联查询和子查询之外,这里介绍两种常用查询技巧:联合查询和子查询的高级应用。
联合查询
联合查询(UNION或UNION ALL)用于合并两个或多个SELECT语句的结果集,并去除重复的行(UNION),或者保留所有行(UNION ALL)。适用于从多个具有相同列数和数据类型的表中合并数据。
一个UNION查询的例子:
SELECT CompanyName, ContactName, City
FROM Customers
UNION
SELECT SupplierName, ContactName, City
FROM Suppliers;
这个查询将合并 Customers 表和 Suppliers 表中的公司名称、联系人姓名和城市信息,仅保留不重复的行。
子查询的高级应用
在复杂的查询中,子查询可以嵌套使用,形成多层查询结构。这种结构可以帮助我们在查询中实现更细致的数据筛选。
一个嵌套子查询的例子:
SELECT EmployeeName, OrderDate
FROM Orders
WHERE CustomerID IN (
SELECT CustomerID
FROM Customers
WHERE City = 'London'
);
在这个例子中,内部子查询首先选择所有在伦敦的客户ID,然后外层查询返回这些客户的所有订单信息。
使用高级查询技巧可以极大地提升数据检索的灵活性和效率。然而,应注意查询的复杂性对性能的影响,并在必要时优化查询结构。对于大型数据库来说,查询优化是提升查询速度和系统性能的关键。
通过灵活使用这些SQL特定查询技巧,可以在Access中实现更强大的数据操作和分析功能。这些技巧的灵活运用将有助于IT专业人员在日常工作中更高效地处理数据。
5. 实际案例分析:PopManu压缩包文件
5.1 案例背景介绍
5.1.1 PopManu项目背景和数据库需求分析
PopManu 是一家专门从事数字内容分发的公司,主要提供音乐、视频和电子书等多种形式的数字媒体服务。随着业务量的增长,对内部数据管理的需求也逐渐增多,尤其是在文件管理方面。为了提高用户体验,PopManu 决定开发一个自动压缩上传的文件到相应格式的压缩包中的新功能,并要求数据库能够跟踪文件的上传时间、用户信息和压缩包状态等关键信息。
通过对数据库需求的分析,我们可以得出如下几点:
- 必须存储用户上传文件的相关信息,包括文件名、上传时间和文件大小等。
- 需要记录压缩操作的每个步骤和结果,如压缩成功、失败或是正在进行中的状态。
- 对压缩包文件进行跟踪,包括文件名、大小、压缩比例和创建时间等。
- 实现对历史记录的查询功能,以便于问题追踪和性能监控。
5.1.2 数据库设计的目标和约束条件
数据库设计的目标旨在满足PopManu的特定需求,具体包括:
- 高效的数据存储和查询性能,以支持快速响应用户操作。
- 优化的数据结构设计,以减少数据冗余并提高数据一致性。
- 良好的扩展性,便于未来的数据结构升级和功能扩展。
- 符合安全标准的数据存储方式,以保障用户数据安全。
考虑到这些设计目标,结合PopManu的业务特点,我们设定以下约束条件:
- 数据库表设计应该遵循数据库规范化原则,减少数据冗余。
- 为了保证数据的一致性,需要通过事务来确保操作的原子性。
- 在数据库中引入触发器和存储过程,以实现复杂逻辑的自动化处理。
- 设定合理的索引策略,以优化查询性能并减少不必要的全表扫描。
5.2 数据库结构的实现
5.2.1 表结构的设计与建立
在分析了需求和约束之后,我们可以设计以下数据库表:
Users:存储用户信息。Files:存储文件信息和上传记录。CompressionJobs:记录压缩任务的状态。CompressionPacks:存储压缩包的详细信息。
以下是具体的表结构设计示例:
CREATE TABLE Users (
UserID INT PRIMARY KEY AUTO_INCREMENT,
Username VARCHAR(50) NOT NULL,
Email VARCHAR(100) NOT NULL,
Password VARCHAR(50) NOT NULL,
-- 其他必要的用户信息字段
);
CREATE TABLE Files (
FileID INT PRIMARY KEY AUTO_INCREMENT,
UserID INT,
FileName VARCHAR(255) NOT NULL,
UploadTime DATETIME NOT NULL,
FileSize INT NOT NULL,
FOREIGN KEY (UserID) REFERENCES Users(UserID)
-- 其他必要的文件信息字段
);
CREATE TABLE CompressionJobs (
JobID INT PRIMARY KEY AUTO_INCREMENT,
FileID INT,
Status VARCHAR(20),
StartTime DATETIME,
EndTime DATETIME,
FOREIGN KEY (FileID) REFERENCES Files(FileID)
-- 其他必要的压缩任务字段
);
CREATE TABLE CompressionPacks (
PackID INT PRIMARY KEY AUTO_INCREMENT,
JobID INT,
PackName VARCHAR(255),
PackSize INT,
CompressionRatio DECIMAL(5,2),
CreateTime DATETIME NOT NULL,
FOREIGN KEY (JobID) REFERENCES CompressionJobs(JobID)
-- 其他必要的压缩包信息字段
);
5.2.2 各类查询的实现与优化
在这个案例中,我们设计了以下关键的查询操作:
- 查询压缩任务的状态。
- 获取用户上传的所有文件列表。
- 查找特定压缩包的所有相关信息。
为了实现这些查询,我们可以使用如下的SQL语句:
-- 查询压缩任务的状态
SELECT JobID, Status, StartTime, EndTime
FROM CompressionJobs
WHERE Status = 'complete';
-- 获取用户上传的所有文件列表
SELECT f.FileName, f.UploadTime, f.FileSize
FROM Files f
JOIN Users u ON f.UserID = u.UserID
WHERE u.Username = '指定的用户名';
-- 查找特定压缩包的所有相关信息
SELECT cp.PackName, cp.PackSize, cp.CompressionRatio, cp.CreateTime
FROM CompressionPacks cp
JOIN CompressionJobs cj ON cp.JobID = cj.JobID
WHERE cj.FileID = (SELECT FileID FROM Files WHERE FileName = '指定的文件名');
为了优化查询性能,我们可以考虑以下措施:
- 根据查询中经常涉及的字段创建索引。
- 在 JOIN 操作中,确保关联的外键字段已经被索引。
- 使用适当的 WHERE 子句来限制返回的数据量。
- 分析查询计划并根据实际情况调整表连接顺序或查询逻辑。
5.3 窗体和报表的实际应用
5.3.1 窗体界面设计与功能实现
在Access中,窗体(Forms)是用户交互的重要界面。在PopManu项目中,我们设计了以下几个窗体:
- 用户登录窗体:用于用户登录系统。
- 文件上传窗体:用于展示上传进度和结果。
- 压缩包管理窗体:用于查看和管理压缩包信息。
窗体设计的实现涉及到具体控件的布局和事件的编写,例如在文件上传窗体中,可以使用进度条控件来展示文件上传的进度,并在上传成功或失败后给予用户相应的提示。
5.3.2 报表生成及打印流程优化
报表(Reports)用于呈现格式化的数据输出,方便用户打印和存档。在PopManu项目中,我们创建了以下报表:
- 用户上传文件报表:展示用户上传文件的相关信息。
- 压缩任务状态报表:展示所有压缩任务的状态。
- 压缩包详细信息报表:展示压缩包的详细内容。
为了优化报表的生成和打印流程,我们可以执行以下步骤:
1. 设计报表模板,包含所有必要的信息字段和统计图表。
2. 根据报表类型和目标用户,提供导出为多种格式(如PDF、Excel等)的选项。
3. 为报表添加条件格式化,突出显示关键数据和异常状态。
4. 集成打印预览功能,并允许用户自定义打印设置。
5. 实现报表导出和打印的自动化工作流,提高办公效率。
5.4 宏与自动化操作
5.4.1 宏在数据处理中的应用
宏(Macros)是Access中用于自动化重复性任务的一组操作指令。在PopManu项目中,宏可以用于以下场景:
- 自动检查新上传的文件,并启动压缩任务。
- 当压缩任务完成时,自动更新数据库中的压缩包状态。
- 定期备份数据库,以防止数据丢失。
宏的实现可以通过以下步骤:
1. 在Access中创建宏,并为其命名。
2. 在宏中定义要执行的操作,如打开表、执行查询等。
3. 设置宏的触发条件,如表单打开、按钮点击等。
4. 测试宏,确保它按照预期工作。
5.4.2 自动化任务的设置与执行
自动化任务的设置是提高效率和减少人为错误的关键。在PopManu项目中,我们可以使用宏来自动化一些如数据备份的任务。
自动化任务的设置步骤包括:
1. 确定任务的执行时间和频率。
2. 编写宏来执行备份操作,包括连接到备份位置并复制数据库文件。
3. 设置任务调度器(如Windows任务计划程序)来触发宏的执行。
4. 定期检查自动化任务的运行状态和备份文件的完整性。
通过上述步骤,可以将数据备份任务自动化,确保系统数据的安全性和可靠性。
6. 数据库维护与优化
6.1 数据库性能监控
6.1.1 性能监控的必要性与方法
监控数据库性能是确保应用程序响应性和可用性的关键环节。性能监控可以及早发现资源瓶颈,提高数据处理效率,并能预防潜在的系统故障。常用的方法包括:使用内置的数据库管理工具进行实时监控,设置性能阈值触发警报,以及定期生成性能报告进行分析。
在Access数据库中,可以利用内置的数据库分析器(Database Analyzer)工具来检查数据库对象的性能和维护问题。通过分析数据库,可以识别出未使用的索引,冗余的数据,以及可能存在的性能瓶颈。
6.1.2 分析工具的使用与解析
分析工具对于数据库管理员来说是一个强大的资源。在Access中,可以通过“数据库工具”菜单下的“分析数据库”选项来调用数据库分析器。这个工具可以对数据库中的各种对象进行详细分析,并给出优化建议。例如,对于查询的优化建议可能包括创建索引,以减少查询执行时间。
在分析报告中,每一个建议都附有详细解释,说明如何及为何需要执行这些优化操作。例如,如果分析报告指出某个表上有太多的索引,可能会影响到更新和插入操作的性能,因此建议删除一些不常用到的索引。
-- 示例:删除不必要的索引
ALTER TABLE TableName DROP INDEX IndexName;
上述SQL语句展示了如何删除表中不必要的索引。在实际应用中,根据分析报告提供的建议,手动或通过脚本自动化执行这些操作。
6.2 数据库维护技巧
6.2.1 清理和优化数据库结构
随着数据库使用时间的增长,表中的数据量也在不断累积,不合理的数据库设计会导致查询效率下降。数据库维护过程中,清理无用数据和优化数据库结构是必不可少的环节。
清理无用数据可以通过编写SQL语句删除不再需要的记录,例如删除过期订单或垃圾数据。优化数据库结构则涉及规范化过程,确保数据不重复且依赖关系合理。例如,可以使用以下SQL语句来删除冗余字段:
-- 示例:删除冗余字段
ALTER TABLE TableName DROP COLUMN RedundantColumn;
6.2.2 备份与恢复的最佳实践
备份是数据库维护中最为基础且重要的环节,它能够在数据丢失或损坏时提供恢复能力。为了保证备份的有效性,需要定期进行,并且在不同的物理位置存储多个备份副本。
在Access中,备份可以通过“文件”菜单下的“另存为其他格式”选项,选择保存类型为“Access 数据库(.mdb 或 .accdb)”。这将导出当前数据库的所有对象和数据。
flowchart LR
A[开始备份] --> B[选择导出位置]
B --> C[选择文件类型: .mdb 或 .accdb]
C --> D[保存并完成备份]
恢复操作则是在遇到数据损坏时从备份中恢复数据的过程。在实际操作中,需要确保备份文件的完整性和最近性,以减少数据丢失的风险。
6.3 性能优化高级策略
6.3.1 索引优化和查询性能调整
索引优化是提升数据库查询性能的关键手段之一。通过建立合适的索引,可以加快数据查询的速度,尤其是对于大型表。在Access中,可以为表的某一列创建索引以加速查询。
使用索引时,需要注意以下几点:
- 不要为经常更新的列创建索引,因为索引本身也需要维护,这会降低更新操作的性能。
- 为经常用于查询条件的列创建索引,可以显著提升查询效率。
- 对于查询中的排序和连接操作频繁的列,索引同样能发挥重要作用。
6.3.2 分析与重构数据库架构
重构数据库架构是性能优化的高级阶段。这个过程通常包括调整表结构,优化查询语句,甚至重新设计应用程序的数据库访问逻辑。
进行架构分析和重构时,需要评估现有架构的优缺点,包括表的连接方式,查询设计以及数据的存储方式。例如,可以使用ER模型来重新评估实体间的关系,并根据新的设计来调整数据库架构。
数据库维护与优化是一个持续的过程,随着应用的不断发展,对数据库的监控、维护和优化策略也需要不断地更新和调整,以确保数据库性能达到最佳状态。
简介:数据库是组织和管理信息的关键技术,本案例专注Microsoft Access数据库文件(mdb),一种流行的桌面数据库管理系统。文章将详细讲解如何使用SQL语言进行基本的数据查询和排序操作,以及Access中的高级功能,如创建查询、窗体、报表和宏。通过分析压缩包文件“PopManu”,读者将了解到数据库结构、管理数据、执行管理和分析任务的具体方法。学习这些技能对于数据管理至关重要,有助于提高工作效率和数据驱动决策能力。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 12
12 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)