机器学习基础:线性回归与房价预测案例
本文介绍了机器学习中的线性回归方法,以波士顿房价预测为例展开分析。首先解释了机器学习的基本概念,区分了回归与分类问题。重点阐述了线性回归的两种类型(一元和多元),并以多元线性回归为例进行实战演示。通过sklearn库加载波士顿房价数据集,详细讲解了数据预处理、特征工程(标准化/归一化)、模型训练与预测的全流程。文章提供了完整的Python代码实现,包括数据分割、特征处理、模型训练和结果输出等关键步
一、相关概念
1.1 什么是机器学习?
机器学习(ML)是让机器自动学习,而不是基于规则的编程
其英文是Machine Learning
1.2 什么是线性回归?
我们知道,在机器学习中,我们需要使用训练集特征x_train和训练集标签y_train来训练模型。
在机器学习中,有多种不同的问题,他们的任务各不相同,举例如下:
回归问题:预测连续的数值输出
分类问题:预测离散的类别标签
......
回归问题的目标是预测一个连续的数值输出,而线性回归则通过建立输入特征特征x_train与输出目标y_train之间的线性关系来实现这一目标
二、线性回归问题分类
线性回归问题主要分两大类:①一元线性回归;②多元线性回归
一元很简单,只有一个变量x,这里不过多阐述,我们只讨论实用性更强的多元线性回归
三、Boston房价预测案例分析
由于本网站不支持插入文件,因此无法上传Boston.csv数据集;
由于数据庞大,只能粘贴部分表格,现贴上前五行数据:
|
CRIM |
ZN |
INDUS |
CHAS |
NOX |
RM |
AGE |
DIS |
RAD |
TAX |
PTRATIO |
B |
LSTAT |
MEDV |
|
0.00632 |
18 |
2.31 |
0 |
0.538 |
6.575 |
65.2 |
4.09 |
1 |
296 |
15.3 |
396.9 |
4.98 |
24 |
|
0.02731 |
0 |
7.07 |
0 |
0.469 |
6.421 |
78.9 |
4.9671 |
2 |
242 |
17.8 |
396.9 |
9.14 |
21.6 |
|
0.02729 |
0 |
7.07 |
0 |
0.469 |
7.185 |
61.1 |
4.9671 |
2 |
242 |
17.8 |
392.83 |
4.03 |
34.7 |
|
0.03237 |
0 |
2.18 |
0 |
0.458 |
6.998 |
45.8 |
6.0622 |
3 |
222 |
18.7 |
394.63 |
2.94 |
33.4 |
|
0.06905 |
0 |
2.18 |
0 |
0.458 |
7.147 |
54.2 |
6.0622 |
3 |
222 |
18.7 |
396.9 |
5.33 |
36.2 |
该数据集的特征列名:
['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT']可以看到,特征(x)有多个,因此这是一个多元线性回归问题
该数据的标签列名:
['MEDV']我们的目标是:使用数据集训练回归模型,并预测房价
3.1 导包
import pandas as pd #用于读取csv文件
from sklearn.model_selection import train_test_split # 用于将数据集分割为训练集和测试集
from sklearn.preprocessing import StandardScaler # 用于数据标准化处理
from sklearn.linear_model import LinearRegression # 用于线性回归模型训练3.2 获取数据
从 sklearn 0.24 版本开始,load_boston 函数被标记为过时,推荐使用 fetch_openml 函数加载数据集。
load_boston 无法使用的原因是有一个参数B涉嫌种族歧视,认为B对房价有影响
from sklearn.datasets import fetch_openml
boston = fetch_openml(name="boston", version=1, as_frame=True)
X = boston.data
y = boston.target由于是读取在线数据,可能因为网络问题导致代码无法运行下去。即使是这样,通过本文应该也可以理解线性回归
3.3 数据预处理
数据预处理的目的是,将数据集按一定比例分为训练集和测试集,通常来说比例是8:2或7:2
比例的大小关乎模型的正确率,可不断尝试最优比例
# 数据预处理
x_train,y_train,x_test,y_test = train_test_split(x,y,test_size = 0.2,random_state = 88)解析:
train_test_split —— 已经在先前导入过,其作用是将数据集分割为训练集和测试集
test_size —— 是分割的比例,0.2表示测试集占20%
random_state —— 是随机数种子,当随机种子固定时,分割的结果也是固定的。
如果不设定种子,那么分割结果就是随机的,不可以这样做,因为会导致每次训练得到的模型不同,也就无法对模型进行调优
随机种子的不同关乎模型的正确率,可不断尝试最优种子
3.4 特征工程(Feature Engineering)
3.4.1 什么是特征工程?
由于特征的单位或者大小相差较大,或者某特征的方差相比其他的特征要大出几个数量级,容易影响(支配)目标结果,使得一些模型(算法)无法学习到其它的特征
因此,我们需要进行特征工程(又称“特征预处理”),将原始数据进行标准化和归一化,并转换为更好地代表潜在问题的特征,以便提高机器学习模型的性能
3.4.2 什么是标准化和归一化?
标准化:通过对原始数据进行标准化,转换为均值为0标准差为1的标准正态分布的数据
其公式为:
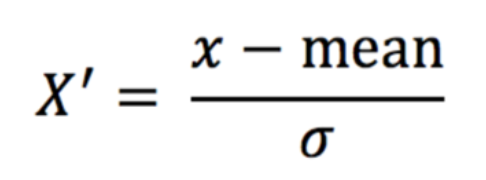
mean是均值,σ是正态分布的标准差,无需记忆,你用不上这公式
——难道老板会让你手动标准化吗?除非他是一头猪
归一化:通过对原始数据进行变换把数据映射到【mi,mx】(默认为[0,1])之间
其公式为:
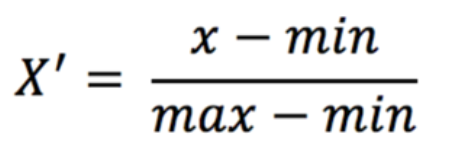
max为数据的最大值,min为最小值,无需记忆
3.4.3 什么是拟合和转换?
对训练集进行拟合(fit):
计算训练集中每个特征的统计信息(均值和标准差;
建立标准化的规则和参数。
对训练集进行转换(transform):
使用前面计算得到的统计参数(均值和标准差)对数据进行实际的标准化处理;
将原始数据转换为均值为0、标准差为1的标准正态分布形式。
3.4.4 代码实现
# 先用fit_transform对训练集进行拟合和转换,计算训练集的均值和标准差
x_train = transfer.fit_transform(x_train)
# 再用transform对测试集进行转换,确保测试集使用相同的标准化参数,避免数据泄露
x_test = transfer.transform(x_test)3.5 模型训练
3.5.1 创建线性回归正规方程对象
# 创建线性回归正规方程对象
# es为模型对象;fit_intercept为是否需要计算偏置值,默认为True
es = LinearRegression(fit_intercept=True)3.5.2 模型训练
# 模型通过学习x_train(特征)和y_train(目标值)之间的关系来进行训练
# 损失函数计算:训练过程中,模型会比较预测值和y_train的真实值,计算误差并调整模型参数
# 模型优化目标:模型的目标是使预测值尽可能接近y_train中的真实值
# 简单来说,y_train就是训练数据中我们希望模型能够准确预测的"正确答案"
es = es.fit(x_train,y_train)3.6 模型预测
# 模型预测,通过测试数据x_test生成预测数据(在这个案例里是房价)
y_predict = es.predict(x_test)3.7 额外
print(f'预测结果:{y_predict}')
print(f'权重:{es.coef_}')
print(f"偏置:{es.intercept_}")
DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 30
30 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)