Oracle RAC 数据库存储替换,由裸磁盘绑定方式变成scsi uuid的绑定方式
这里写自定义目录标题添加磁盘前准备工作开始添加磁盘添加磁盘前准备工作查看现有磁盘、状态以及使用空间,如果是sqlplus / as sysasm方式,使用以下语句,可以格式化下,记录好结果,方便后续比对:col failgroup for a20;col path for a30;set linesize 200;col total_size for a20;col free_size for a
添加磁盘前准备工作
查看现有磁盘、状态以及使用空间,如果是sqlplus / as sysasm方式,使用以下语句,可以格式化下,记录好结果,方便后续比对:
col failgroup for a20;
col path for a30;
set linesize 200;
col total_size for a20;
col free_size for a20;
col name for a20;
set pagesize 800;
select failgroup,group_number,name,mode_status,state,header_status,path,disk_number,round(total_mb/1024,2) || ‘G’ as total_size , round(free_mb/1024,2) || ‘G’ as free_size from v$asm_disk order by 1,2;
FAILGROUP GROUP_NUMBER NAME MODE_ST STATE HEADER_STATU PATH DISK_NUMBER TOTAL_SIZE FREE_SIZE
ARCHDG_0000 1 ARCHDG_0000 ONLINE NORMAL MEMBER /dev/raw/raw7 1 100G 93.91G
CRSDG_0000 2 CRSDG_0000 ONLINE NORMAL MEMBER /dev/raw/raw1 3 40G 39.67G
CRSDG_0001 2 CRSDG_0001 ONLINE NORMAL MEMBER /dev/raw/raw2 4 40G 39.67G
CRSDG_0002 2 CRSDG_0002 ONLINE NORMAL MEMBER /dev/raw/raw3 5 40G 39.68G
DATADG_0000 3 DATADG_0000 ONLINE NORMAL MEMBER /dev/raw/raw6 1 100G 83.15G
REDODG_0000 4 REDODG_0000 ONLINE NORMAL MEMBER /dev/raw/raw4 0 10G 8.22G
REDODG_0001 4 REDODG_0001 ONLINE NORMAL MEMBER /dev/raw/raw5 1 10G 8.22G
查看磁盘组的状态以及使用空间,记录好group_number可以对应后面rebalance中的磁盘组
col total_size for a20;
col free_size for a20;
set linesize 200;
col name for a20;
set pagesize 800;
select GROUP_NUMBER,name,state,type,ALLOCATION_UNIT_SIZE,round(total_mb/1024,2) || ‘G’ as total_size , round(free_mb/1024,2) || ‘G’ as free_size,round((total_mb-FREE_MB)/total_mb*100,2) used_perc,USABLE_FILE_MB/1024 usableG from v$asm_diskgroup;
GROUP_NUMBER NAME STATE TYPE ALLOCATION_UNIT_SIZE TOTAL_SIZE FREE_SIZE USED_PERC USABLEG
1 ARCHDG MOUNTED EXTERN 4194304 100G 93.91G 6.09 93.9140625
2 CRSDG MOUNTED NORMAL 4194304 119.99G 119.04G .79 39.5214844
3 DATADG MOUNTED EXTERN 4194304 200G 183.13G 8.43 183.132813
4 REDODG MOUNTED NORMAL 4194304 19.99G 16.45G 17.74 8.22265625
在/etc/sysconfig/network-scripts下的 ifcfg-eth0 和 ifcfg-eth1分别添加如下参数(数据库所有节点都要更改),防止start_udev导致监听自动停止
HOTPLUG=no
查看系统中的uuid,不过linux6 和linux7的脚本还不太一致,如下区别,如果有更简便方式,欢迎讨论呀:
linux6 使用以下步骤查看磁盘的uuid
scsi_id -g -u -d /dev/sdg
或者linux7使用以下步骤查看磁盘uuid
lsscsi --scsi_id
使用/dev/sdx 盘前不需要在fdisk /dev/sdx的格式化,添加的时候主机组同事已经格式化过了,
使用上面的命令将查出来的结果放入到/etc/udev/rules.d/99-oracle-asm.rules 文件中
linux6=>99-oracle-asm.rules,根据实际情况添加数目,这里举个栗子,一个盘的写法:
KERNEL==“sd*”, BUS==“scsi”, PROGRAM=="/sbin/scsi_id --whitelisted --replace-whitespace --device=/dev/$name",RESULT==“36000c299ac0f660c2bef4887fcffabb1”, NAME="./raw/raw17",OWNER=“grid”, GROUP=“asmadmin”, MODE=“0660”
linux7=>99-oracle-asm.rules,根据实际情况添加数目,这里举个栗子,一个盘的写法:
KERNEL==“sd*[!0-9]”, ENV{DEVTYPE}“disk”, SUBSYSTEM"block", PROGRAM=="/usr/lib/udev/scsi_id -g -u -d $devnode", RESULT==“36000c2942e0e369b2a16e4d4c2f5dc8b”, RUN+="/bin/sh -c ‘mknod /dev/raw/raw18 b $major $minor; chown grid:asmadmin /dev/raw/raw18; chmod 0660 /dev/raw/raw18’"
使用以下命令扫描盘,对应到/dev/raw/raw 下面
linux6.5使用以下语句:
start_udev
或者Linux7使用以下语句:
udevadm control --reload-rules
udevadm trigger
另一个节点执行以下语句,发现已分区的磁盘
partprobe
查看是否新加的磁盘已经被grid软件发现到了,两种方法:
1)使用系统命令,查看磁盘组的权限是否变成grid.asmadmin,加粗为新加磁盘
ll /dev/raw/raw*
crw-rw---- 1 grid asmadmin 162, 1 Nov 29 15:11 /dev/raw/raw1
brw-rw---- 1 grid asmadmin 8, 144 Nov 29 15:11 /dev/raw/raw11
brw-rw---- 1 grid asmadmin 8, 160 Nov 29 15:11 /dev/raw/raw12
brw-rw---- 1 grid asmadmin 8, 176 Nov 29 15:11 /dev/raw/raw13
brw-rw---- 1 grid asmadmin 8, 192 Nov 29 15:11 /dev/raw/raw14
brw-rw---- 1 grid asmadmin 8, 208 Nov 29 15:11 /dev/raw/raw15
brw-rw---- 1 grid asmadmin 8, 224 Nov 29 15:11 /dev/raw/raw16
brw-rw---- 1 grid asmadmin 8, 240 Nov 29 15:11 /dev/raw/raw17
brw-rw---- 1 grid asmadmin 65, 0 Nov 29 15:11 /dev/raw/raw18
crw-rw---- 1 grid asmadmin 162, 2 Nov 29 15:11 /dev/raw/raw2
crw-rw---- 1 grid asmadmin 162, 3 Nov 29 15:11 /dev/raw/raw3
crw-rw---- 1 grid asmadmin 162, 4 Nov 29 15:11 /dev/raw/raw4
crw-rw---- 1 grid asmadmin 162, 5 Nov 29 15:11 /dev/raw/raw5
crw-rw---- 1 grid asmadmin 162, 6 Nov 29 15:11 /dev/raw/raw6
crw-rw---- 1 grid asmadmin 162, 7 Nov 29 15:11 /dev/raw/raw7
2)切换到grid用户下,查看新加磁盘的 状态是否为candicate,如果是,代表添加成功,可以将磁盘添加到磁盘组了,使用刚开始查看磁盘组的命令来查看,部分查询结果如下,加粗的为新加磁盘:
FAILGROUP GROUP_NUMBER NAME MODE_ST STATE HEADER_STATU PATH DISK_NUMBER TOTAL_SIZE FREE_SIZE
REDODG_0000 4 REDODG_0000 ONLINE NORMAL MEMBER /dev/raw/raw4 0 10G 8.22G
REDODG_0001 4 REDODG_0001 ONLINE NORMAL MEMBER /dev/raw/raw5 1 10G 8.22G
0 ONLINE NORMAL CANDIDATE /dev/raw/raw15 3 0G 0G
0 ONLINE NORMAL CANDIDATE /dev/raw/raw14 0 0G 0G
前面的准备工作都做完了,现在开始添加磁盘了,建议放在业务非高峰期去执行,毕竟rebalance的操作还是有点点影响性能的
开始添加磁盘
可以使用两种方式添加磁盘,图形界面方式或者命令行方式
1) 图形界面
在数据库服务器上指定要输出的图形页面的window IP
export DISPLAY=192.168.2.45:0.0
冒号后面的0.0 还是1.0 要看windowns页面打开xmanager显示的后缀,如下图:
数据库服务器上执行:
su - grid
export DISPLAY=192.168.2.45:0.0
asmca
然后在192.168.2.45 这台windows服务器上投递出来的界面如下,选择磁盘组,右键,出来添加、删除磁盘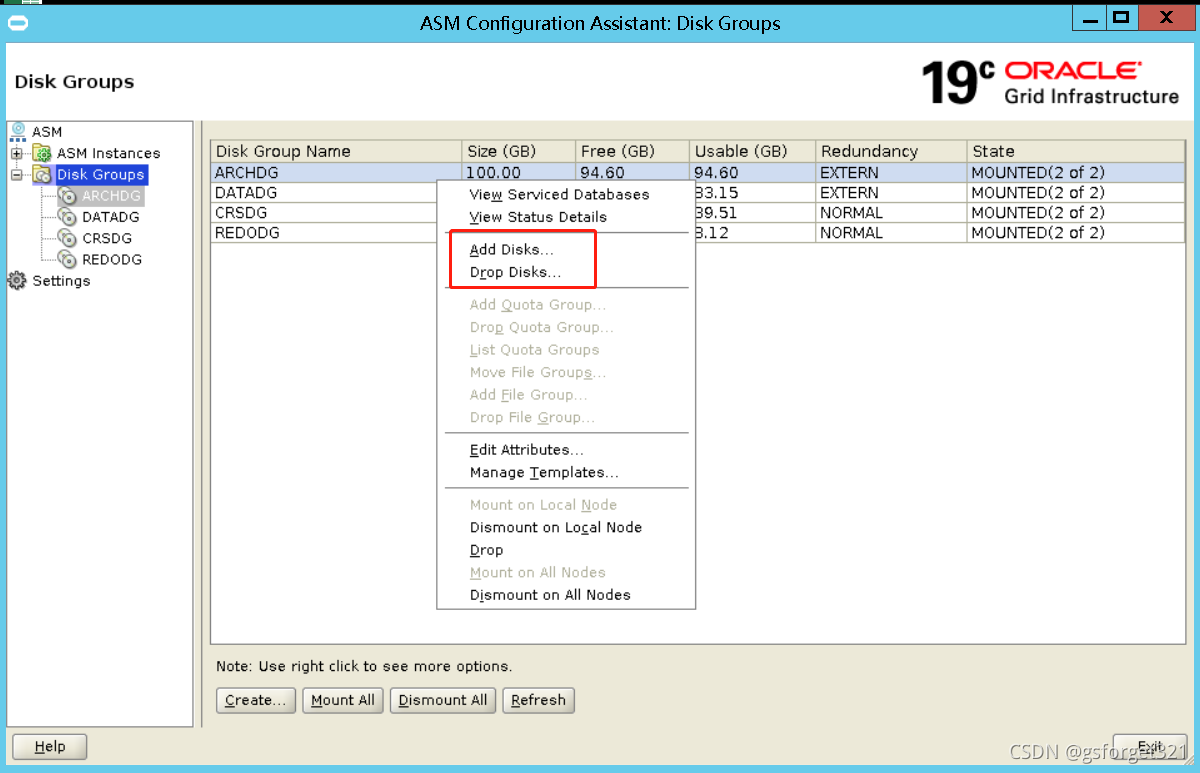
注意:19c以上对于normal冗余方式的磁盘组有以下两个限制:
第一:每个磁盘组至少有三个磁盘,基于安全考虑;
第二:是无法通过图形化页面的方式添加、删除磁盘的,只能通过命令行方式;
2)命令行方式添加磁盘
19c以上的需要更改以下参数才能添加磁盘,添加完后,再更改回来,已经在生产执行过,不影响生产环境:
alter system set “_asm_disable_failgroup_size_checking”=true;
alter system set “_asm_disable_dangerous_failgroup_checking”=true;
添加磁盘命令,加了三块磁盘
alter diskgroup REDODG
add disk ‘/dev/raw/raw14’
add disk ‘/dev/raw/raw15’
add disk ‘/dev/raw/raw18’ rebalance power 8;
查看rebalance的状态,根据group_number对应到磁盘组,如果多个磁盘组rebalance在进行的话:
select * from v$asm_operation;
GROUP_NUMBER OPERA PASS STAT POWER ACTUAL SOFAR EST_WORK EST_RATE EST_MINUTES ERROR_CODE CON_ID
1 REBAL COMPACT RUN 8 1 98 0 0 0 0
1 REBAL REBALANCE DONE 8 1 776 776 0 0 0
1 REBAL REBUILD DONE 8 1 0 0 0 0 0
最后完成rebalance的时候,这个视图就没有数据了
删除老的磁盘,在刚开始的时候查到路径可以对应到磁盘要删除的name;
SQL> alter diskgroup REDODG drop disk REDODG_0000,REDODG_0001 rebalance power 8;
Diskgroup altered.
在查看rebalance完没有
select * from v$asm_operation;
rebalance完成后,好,这个磁盘组的磁盘迁移完毕,从老存储迁移到新存储,这个是db层面的,还要从os层面删除老存储;
如果原来是使用裸磁盘的挂载方式,屏蔽60-raw.rules文件中的映射方式
cat /etc/udev/rules.d/60-raw.rules
#ACTION==“add”, KERNEL==“sdc1”, RUN+="/bin/raw /dev/raw/raw1 %N"
#KERNEL==“raw1”, OWNER=“grid”,GROUP=“asmadmin”, MODE=“0660”
#ACTION==“add”, KERNEL==“sdd1”, RUN+="/bin/raw /dev/raw/raw2 %N"
#KERNEL==“raw2”, OWNER=“grid”,GROUP=“asmadmin”, MODE=“0660”
#ACTION==“add”, KERNEL==“sde1”, RUN+="/bin/raw /dev/raw/raw3 %N"
#KERNEL==“raw3”, OWNER=“grid”,GROUP=“asmadmin”, MODE=“0660”
#ACTION==“add”, KERNEL==“sdf1”, RUN+="/bin/raw /dev/raw/raw4 %N"
#KERNEL==“raw4”, OWNER=“grid”,GROUP=“asmadmin”, MODE=“0660”
#ACTION==“add”, KERNEL==“sdg1”, RUN+="/bin/raw /dev/raw/raw5 %N"
#KERNEL==“raw5”, OWNER=“grid”,GROUP=“asmadmin”, MODE=“0660”
#ACTION==“add”, KERNEL==“sdh1”, RUN+="/bin/raw /dev/raw/raw6 %N"
#KERNEL==“raw6”, OWNER=“grid”,GROUP=“asmadmin”, MODE=“0660”
#ACTION==“add”, KERNEL==“sdi1”, RUN+="/bin/raw /dev/raw/raw7 %N"
#KERNEL==“raw7”, OWNER=“grid”,GROUP=“asmadmin”, MODE=“0660”
再使用刚开始发现盘的方式执行,不过Linux7的话,执行完,/dev/raw/raw* 下面还是有老盘,但通过sql查看,盘已经不再磁盘组了,主机组同事就可以在底层拆除这些磁盘了
使用以下命令扫描盘,对应到/dev/raw/raw 下面
linux6.5使用以下语句:
start_udev
或者Linux7使用以下语句:
udevadm control --reload-rules
udevadm trigger
另一个节点执行以下语句,发现已分区的磁盘
partprobe
以上都是个人经过生产验证的,有任何疑问、好的建议都 可以评论私信我!

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)