数学建模---SPSSPRO
一句话区分算法 = 做菜的方法(K-means、Logistic、ARIMA…)模型 = 按方法炒出来的那盘菜(K-means 聚类模型、Logistic 回归模型…)举例K-means 是算法;用 K-means 把 300 个客户聚成 3 类后得到的“3 个中心坐标 + 每个客户的归属”就是模型。所以:聚类、回归、时间序列里,我们通常说“用 K-means 算法 训练一个 聚类模型”“用 Lo
一句话区分
-
算法 = 做菜的方法(K-means、Logistic、ARIMA…)
-
模型 = 按方法炒出来的那盘菜(K-means 聚类模型、Logistic 回归模型…)
举例
-
K-means 是算法;
-
用 K-means 把 300 个客户聚成 3 类后得到的“3 个中心坐标 + 每个客户的归属”就是模型。
所以:
聚类、回归、时间序列里,我们通常说
“用 K-means 算法 训练一个 聚类模型”
“用 Logistic 回归算法 拟合一个 分类模型”。
SPSSPRO用于数据处理、数据分析、Pro画图
数据类别:
(1)定类:只有属性区分,不具有大小之分(例如,不能说“男性”比“女性”大或小,它们只是不同的类别。)
(2)定量:具有大小、顺序和距离的概念。(例如,20岁比10岁大,且20岁与10岁之间的年龄差为10岁。)
1 Pro画图
2 数据处理
最主要掌握:异常值处理、数据标准化、缺失值处理
2.1 异常值处理
一般选用3slgma标准(只把特别 异常的值识别出来),并置为空值
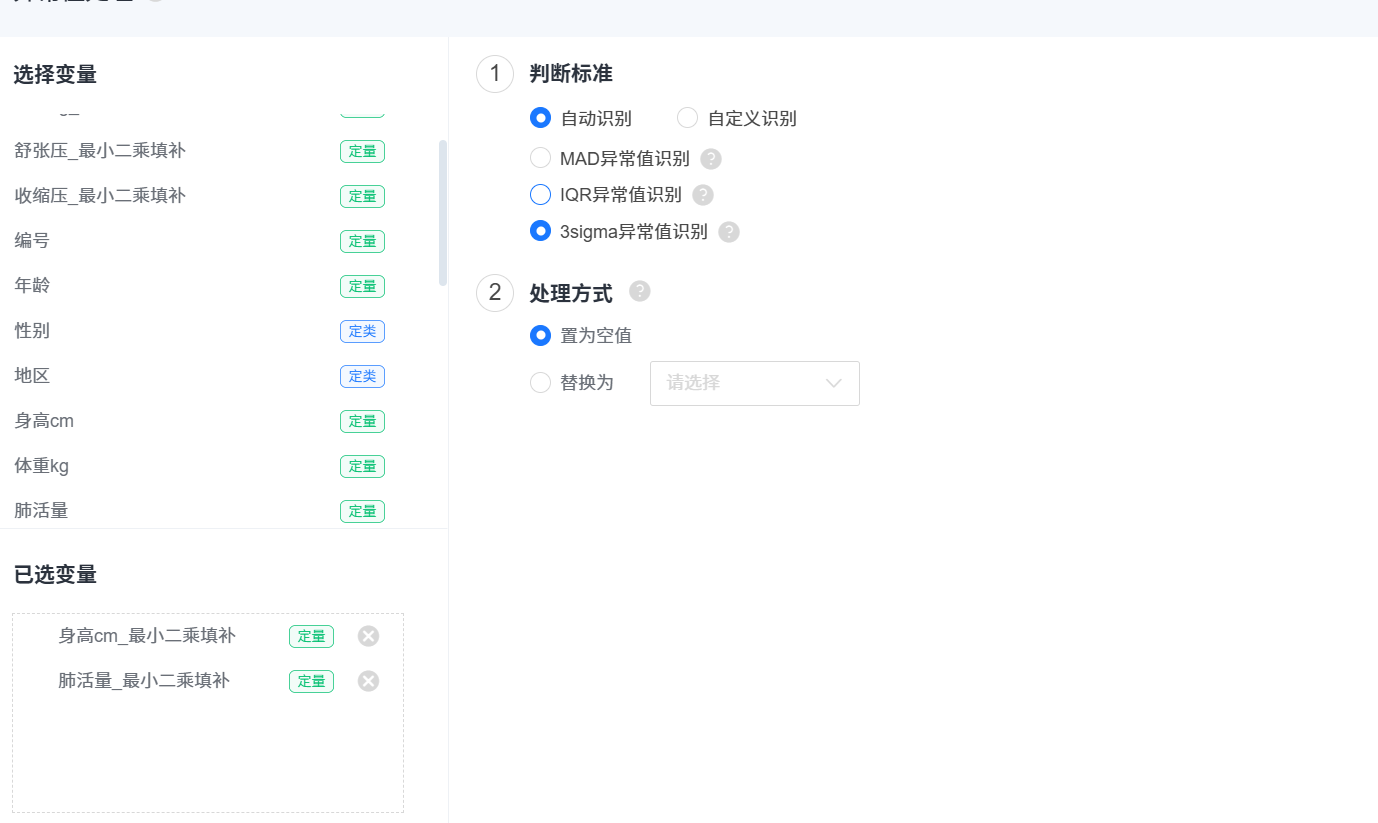
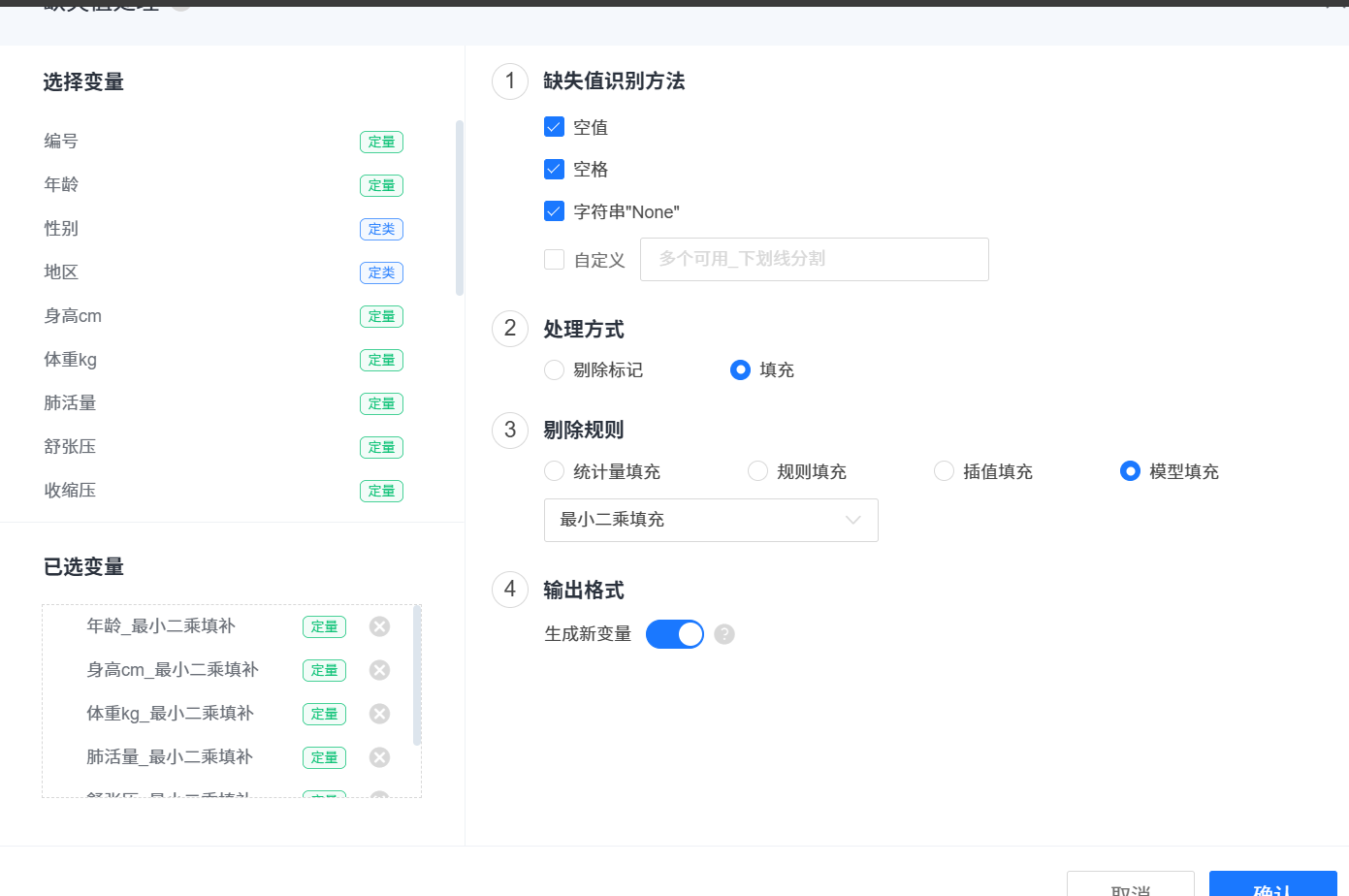
2.2 缺失值处理
如果样本量特别大,缺失值特别多,即选用剔除方法。
如果数据之间是有联系的就选择后两种填充方式(插值填充,模型填充)
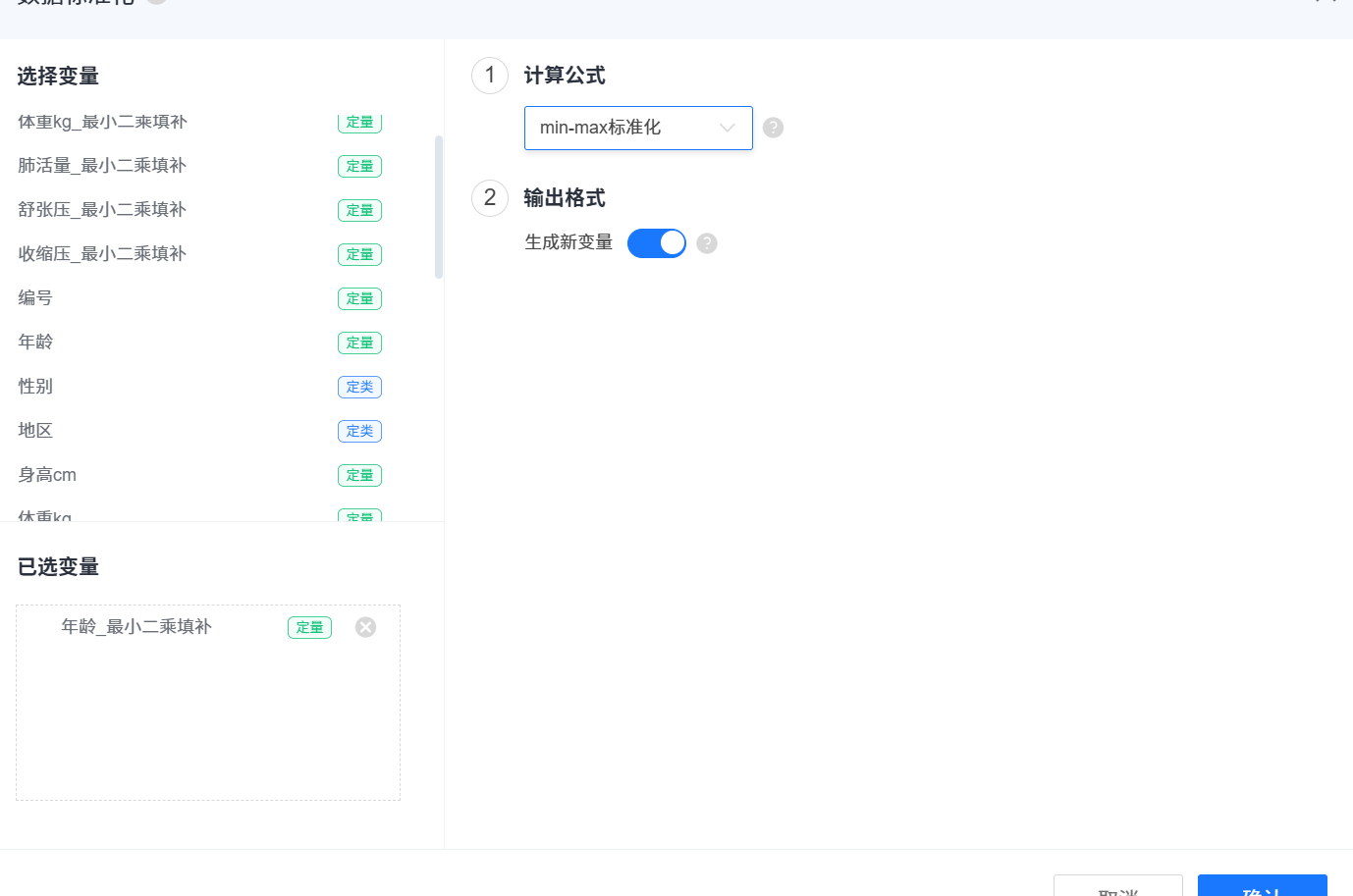
2.3 数据标准化 (评价类问题)
标准化可以使数据去量纲化(使所有数据都是值越大越好)
如果有负数,就用第一个(min-max);如果没有的话就用归一化或min-max
3 聚类算法求解
3.1 K-means聚类算法(对行聚类)
聚类分析是基于中心的聚类算法。通过迭代,把样本分成k个大类,使得每类的样本与该样本中心或均值的距离之和最小。
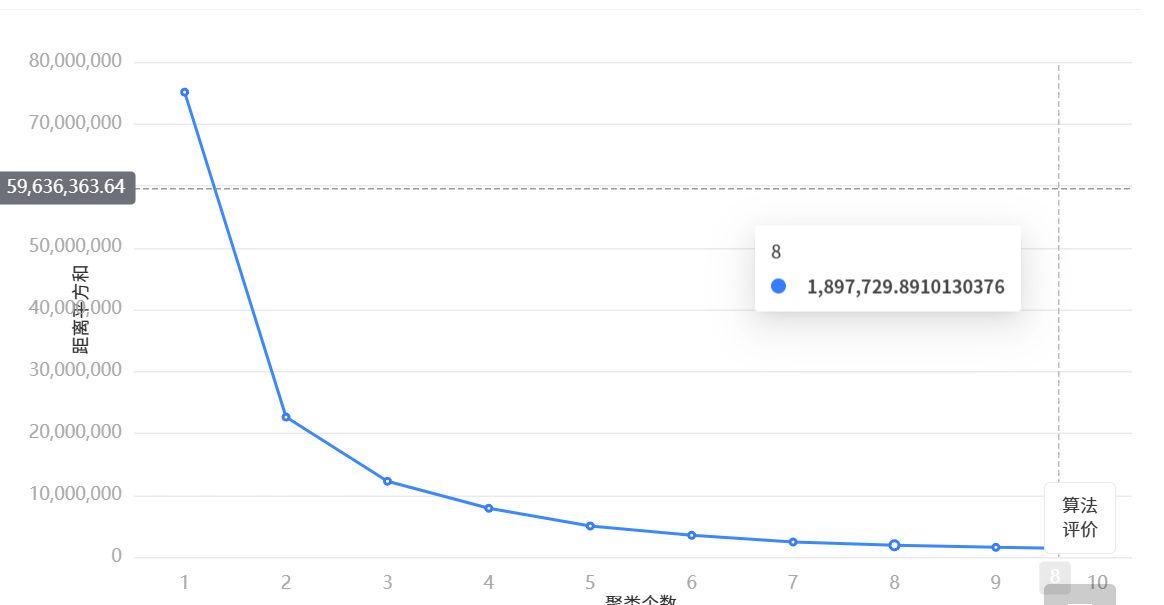
论文一定要把手肘图放进去!!!
• K-Means 负责“分出 4 类人”;
• F & p 值负责回答“哪些变量真的起了区分作用”。
(F是统计值,它越大分组就越明显;p是显著值,当p<0.05则表示该指标在 4 个簇之间差异显著,聚类有效)
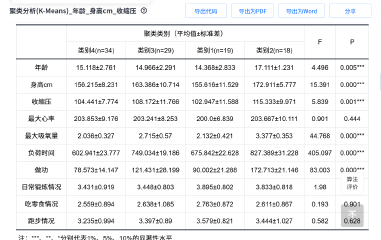
● 轮廓系数:对于一个样本集合,它的轮廓系数是所有样本轮廓系数的平均值。轮廓系数的取值范围是[-1,1],同类别样本距离越相近不同类别样本距离越远,分数越高,聚类效果越好。
● DBI(Davies-bouldin):该指标用来衡量任意两个簇的簇内距离之后与簇间距离之比。该指标越小表示聚类效果越好。
● CH(Calinski-Harbasz Score):通过计算类内各点与类中心的距离平方和来度量类内的紧密度(分母),通过计算类间中心点与数据集中心点距离平方和来度量数据集的分离度(分子),CH指标由分离度与紧密度的比值得到,CH越大表示聚类效果越好。

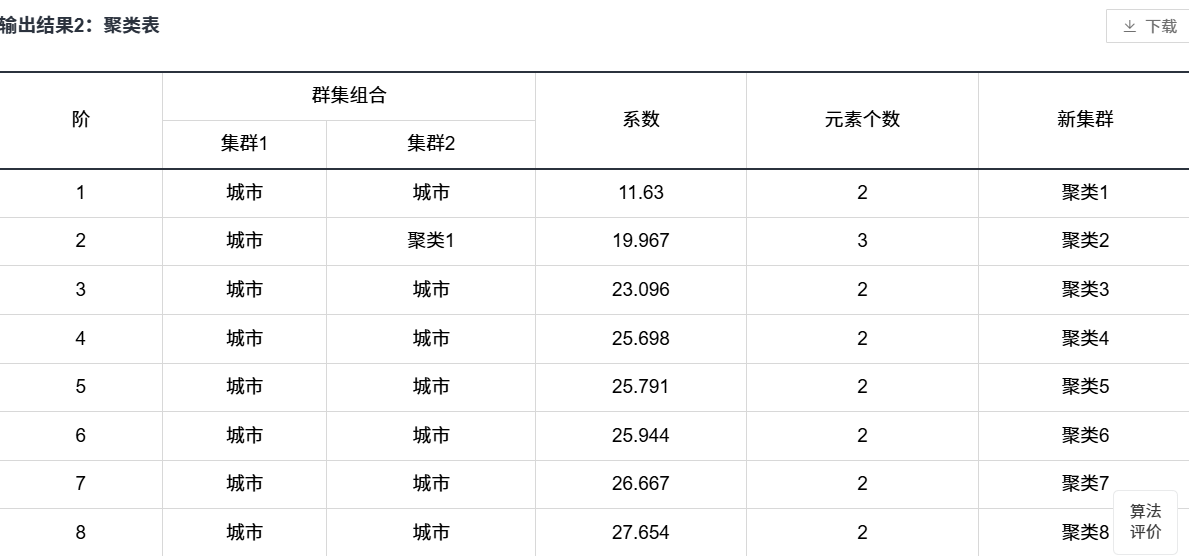
3.2分层聚类(对列聚类)
分层法一定要把树状图放进去!!! 先把待聚类的元素放在一类,再将距离最小的两类元素合并为一个新类,并计算出新类与其他类之间的距离。接着再将距离最近的两类合并,直至全部合并为一类为止。这个过程可以用树状图来表示。
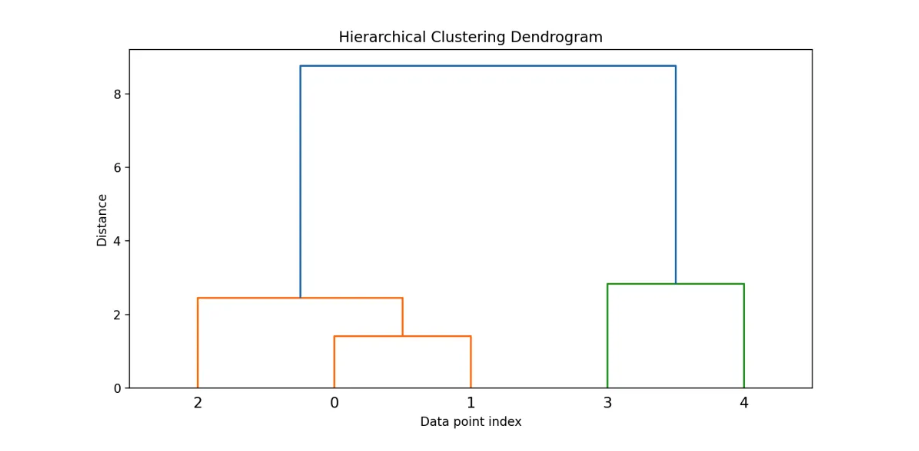
在层次聚类里,“系数”就是合并两个群组时计算出的距离(或相似度)数值:
-
距离越小 → 两个群组越相似,越早被合并。
-
距离越大 → 两个群组差异越大,越晚被合并。
-
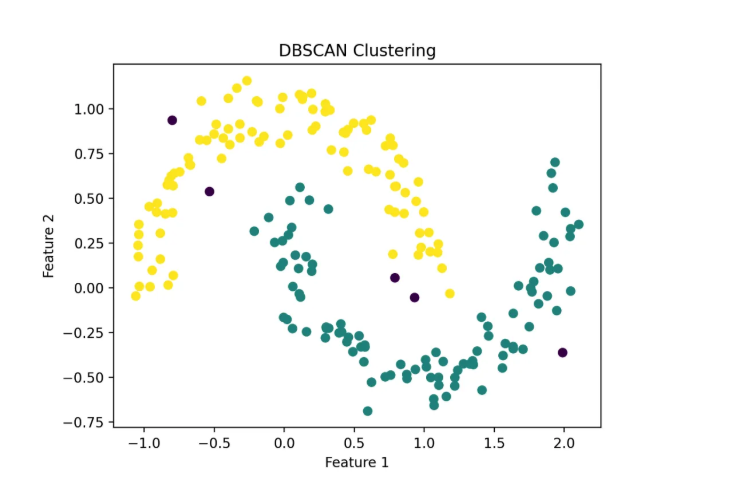
3.3密度聚类(DBSCAN)
一种基于密度的聚类算法,特别适用于具有噪声的数据集和能够发现任意形状簇的情况。它不需要事先指定簇的数量,能有效处理异常点。 (适用于样本之间相关性稍微强一点的数据)
3.4二阶聚类(可对定类进行分析)
既有定类又有定量的时候可用二阶聚类进行分析;全是定量数据可使用K-means或者分层聚类分析。
4 SPSSPRO评价类算法 记得做数据标准化!!!
评价类算法分为:计算指标权重和评价方法
一般使用层次分析法+熵权法+CRITIC结合或分开使用
参考文献:
[1]迟国泰,祝志川,张玉玲.基于熵权-G1法的科技评价模型及实证研究[J].科学学研究,2008,26(06):1210-1220.DOI:10.16192/j.cnki.1003-2053.2008.06.001.
(第一种方法的权重*0.5+第二种方法的权重*0.5)
[2]祝志川,贾通通,王美懿.我国中心城市经济高质量发展水平测度及差异分析——基于时空博弈组合权重的TOPSIS模型[J].辽宁大学学报(哲学社会科学版),2024,52(03):39-53.DOI:10.16197/j.cnki.lnupse.2024.03.008.
(博弈论有可能算出来是负数,正数再用,负数别用)
4.1 层次分析法
输出结果1:指标指数(矩阵)
(1)如果指标太多,就先用权重计算分为几个大类。(先求大类的权重,再用层次分析法算出小类的权重,最后用大类权重*小类权重即可以得到最终权重)
(2)由专家或自己决策对所有指标做“两两比较”。
例如问:“指标 1 相对于指标 2 有多重要?”
-
如果答“强烈重要”,记 7;
-
如果答“同等重要”,记 1;
-
如果指标 2 比指标 1 重要,就记 1/7。
(3)把两两比较的结果填入上三角(对角线固定为 1)。
(4)利用 AHP 的互反规则 a_{ji}=1/a_{ij} 把下三角补全,就得到你看到的矩阵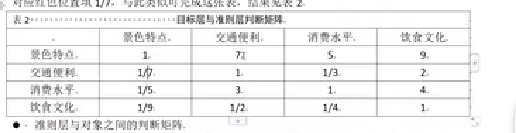
输出结果2:AHP层次分析结果
输出结果3:一致性检验结果(CR=CI/RI<0.1,则通过一次性检验。)
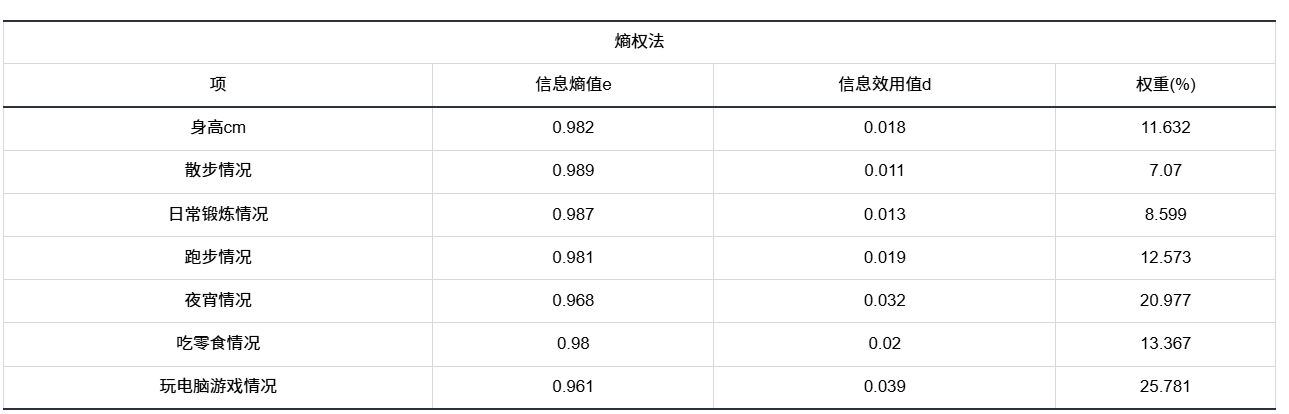
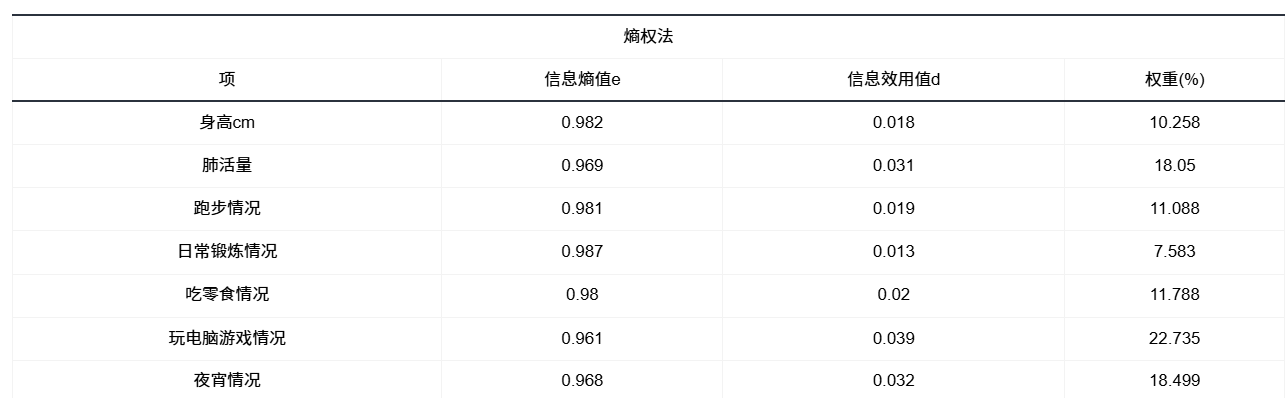
4.2 熵值法(熵权法)
信息熵值(e) 越大 → 这一列数据越“平均、没波动”,区分度越差。
信息效用值(d)d = 1 – e ,e 越小,d 越大,说明这列越能拉开差距。
权重(w)把各列的 d 按比例放大成 100%,谁 d 大谁w大。从而计算得分。
w越大表示在所有指标里,这一项的数据波动最大、差异最明显,因此对“区分不同样本”贡献最大。
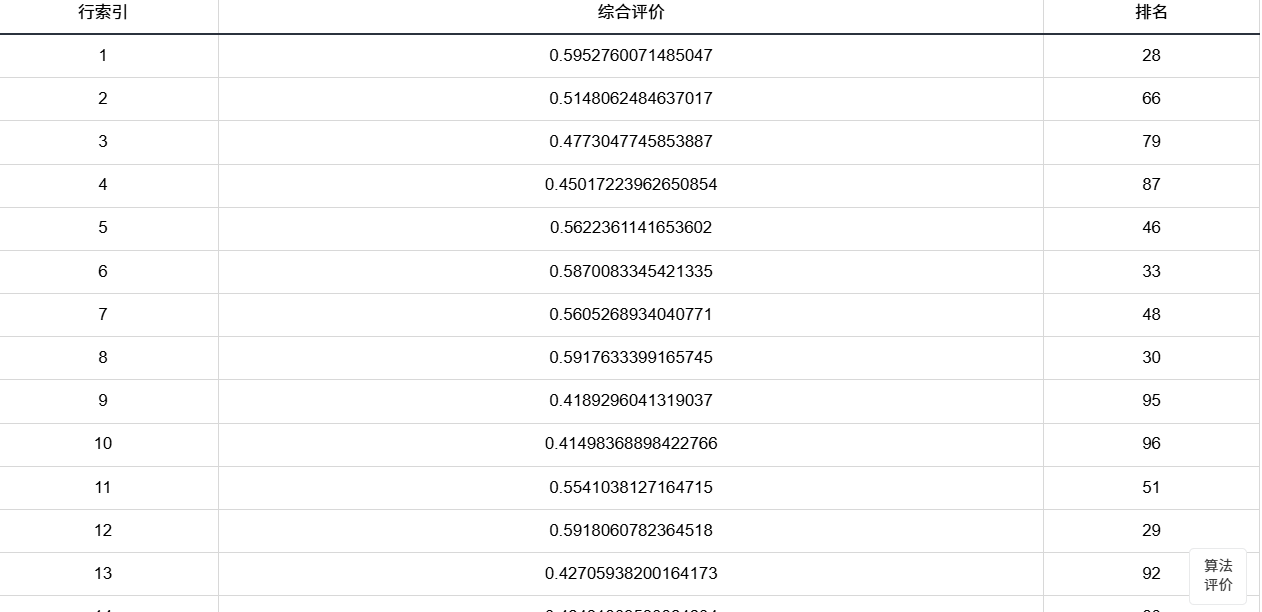
综合得分表只是拿这些权重去算每个人的总分,看谁的综合状况好、谁需要干预。
综合得分越高则越不需要干预;综合得分越低则越需要干预
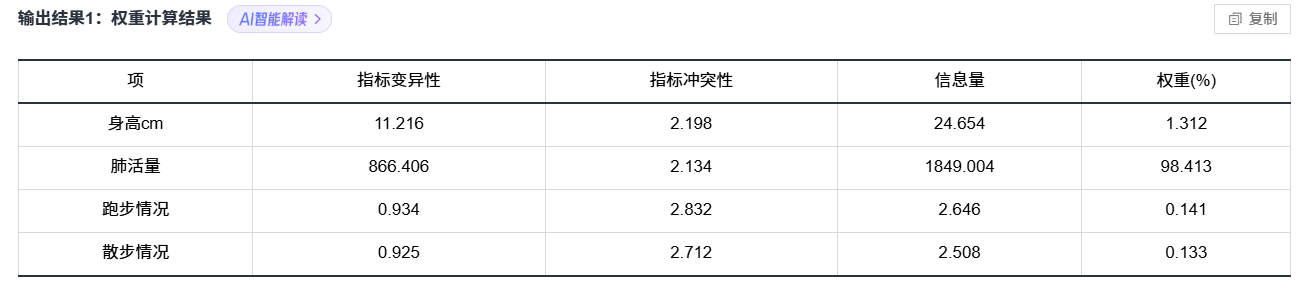
4.3 CRITIC权重法 必须数据标准化!!!
结合了指标之间的方差和相关性去给权重。
● 指标变异性为标准差,标准差越大则权重越大。
● 冲突性为相关系数,指标之间相关性越强则冲突性较低,权重越小。
● 信息量为指标变异性*冲突性指标。
● 权重是信息量的归一化。
目的:
-
如果你想快速判断或筛选谁更健康,量肺活量就够了。
-
再测身高、跑步、散步对“区分样本”几乎没帮助,属于可精简的冗余指标。
4.4 独立性权重系数
只结合了指标之间的相关性
● 复相关系数R值越大说明重复信息越多,权重则越小。
● 复相关系数1/R值越大,则说明权重应该越大。
● 权重由复相关系数倒数1/R值归一化得到。
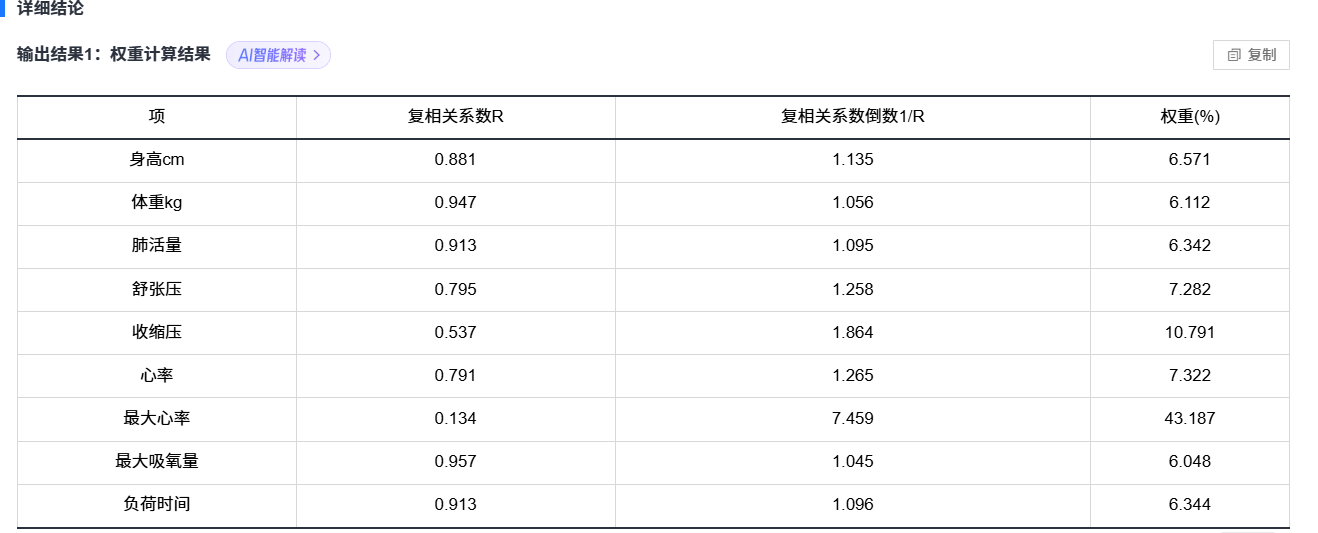
目的:用这些指标综合评估一个人的心肺耐力(或健康风险)”时,权重越高的指标最能拉开人与人之间的差距,算法认为它最“值钱”
4.5变异法
4.6 Topsis
输出结果1:指标权重计算
-
先用权重告诉你“看什么指标最关键”(打游戏、夜宵)。
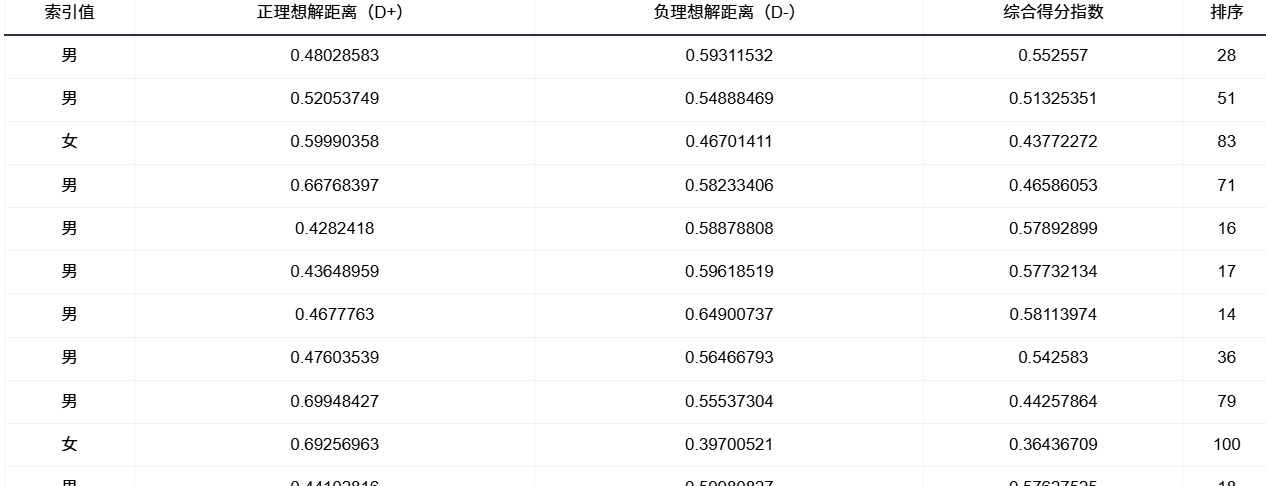
输出结果2:TOPSIS评价法计算结果
‑ 正理想解距离 D+:离“完美健康人”有多远(越小越好)。
‑ 负理想解距离 D-:离“最差健康人”有多远(越大越好)。
再用 TOPSIS 给你一张榜单,越靠后的越需要干预。
4.7因子分析法(门槛较高)
5 回归类算法
5.1 线性回归
-
B(非标准化系数)
原始单位下的“斜率”:X 增加 1 个自己单位,Y 平均变多少。 -
Beta(标准化系数)
把 X、Y 都转成标准分后的斜率,绝对值越大 → 该变量对 Y 的影响越大,可直接比大小。 -
标准误(SE)
系数估计的“误差棒”:SE 越小,估计越精确。 -
t 值
系数 ÷ 标准误,|t| 越大越显著;粗略判读:|t| > 2 就值得关注。 -
p 值
系数为 0 的概率;p < 0.05 通常认为“真显著”。 -
VIF(方差膨胀因子)
检验多重共线性;VIF > 5 或 10 说明该变量与其余变量高度重叠,结果不可信。 -
R²
模型能解释多少 Y 的波动;越接近 1 拟合越好。 -
F 值 & 对应 p
整个模型是否“至少有一个变量有用”;F 的 p < 0.05 表示模型整体显著。
输出结果1:线性回归分析结果表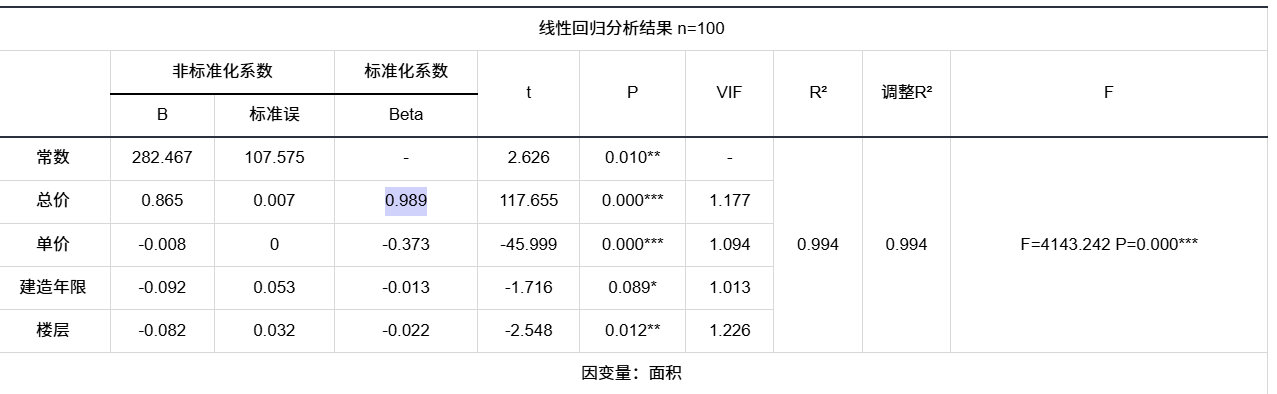
-
输出结果2:拟合效果图
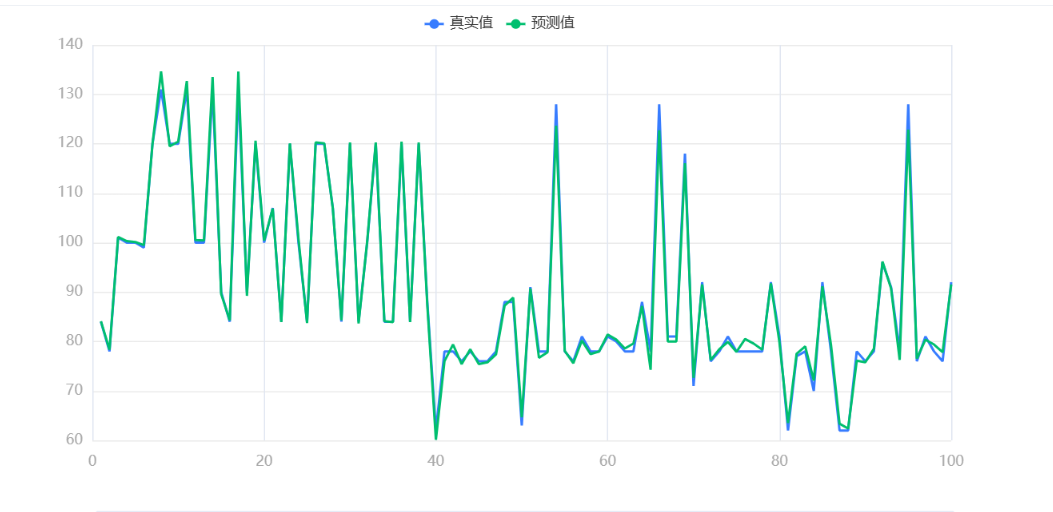 再画一条真实值与预测值的y= x图&散点图会使结果更为精确
再画一条真实值与预测值的y= x图&散点图会使结果更为精确
5.2逻辑回归 (有多个因变量)
逻辑回归的作用:给定特征 → 预测类别
给定一套房子的特征,预测它属于哪个小区
输出结果2:模型评价
-
似然比卡方值 = 15.731
衡量“加了这些自变量后,模型比空模型好多少”。数值越大,说明模型整体越有用。 -
P = 0.000*
上面卡方对应的显著性,p < 0.01(*),表示模型整体显著**,不是瞎猜。 -
AIC = 27.731
越小越好;用来在多个模型里挑最简洁又最拟合的那个。单看一次没意义,比多个模型时才用。 -
BIC = 43.362
和 AIC 类似,但惩罚更严厉;同样“越小越好”,也是模型比较工具。
一句话:
卡方和 P 告诉你“这模型行”;AIC、BIC 留着以后跟别的模型比“谁更精简”。

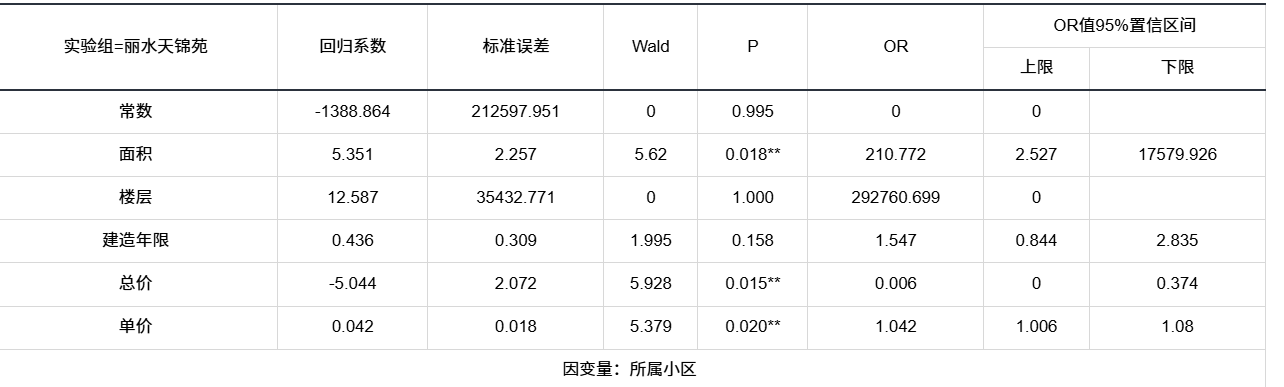
输出结果3:二分类逻辑回归结果
置信区间(95% CI)
-
如果区间 包含 1(或 0 在指数化前),说明 OR 可能无实际差异 → 不显著。
-
楼层区间含 0,再次印证其 OR 不可信。
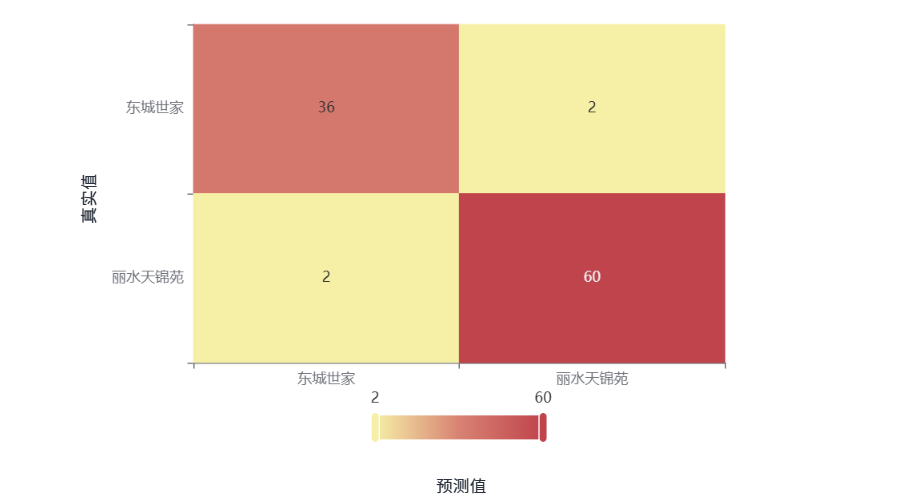
输出结果4:混淆矩阵热力图
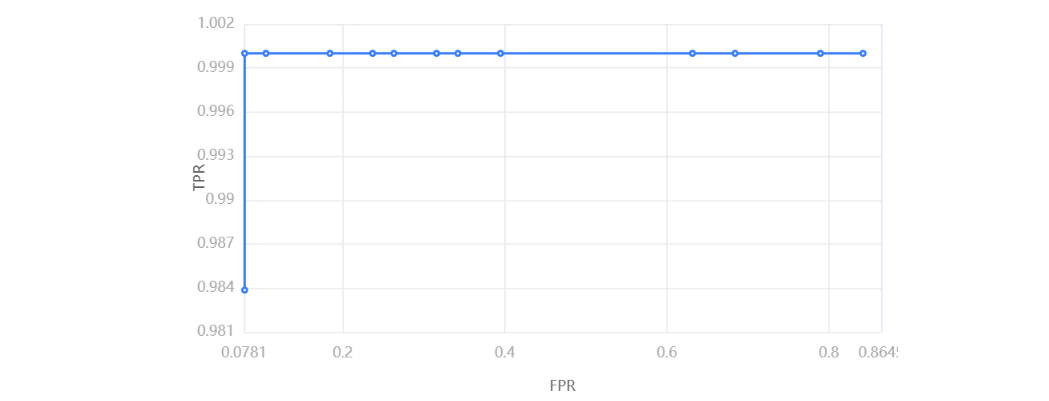
输出结果5:ROC曲线
ROC曲线要结合下表看,AUC的值越接近1,说明此模型分类能力越好
输出结果6:分类评价指标

5.3 灰色预测 (数据较少时用,只适合中短期预测)
数据较少时用,只适合中短期预测。如果数据超过20个建议用LSTM或者时间序列
级比检验就是“看相邻数据变化别太猛”。
序列通过检验,可以安全地用灰色 GM(1,1) 模型去预测未来面积(或价格)。
5.4 bp神经网络 (万金油)
以下三类机器学习的回归方法,模型好不好用都看R²越接近1,精度越好;真实值和预测值越接近,精度越好。多试几次
5.5支持向量机(SVR)
5.6 adaboost回归
6 优化算法
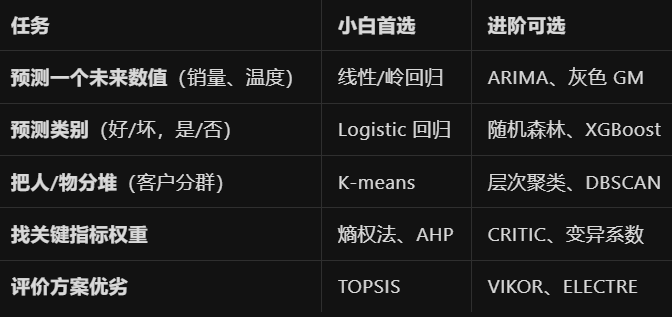
7总结

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 25
25 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)