红外小目标检测论文(DNA-Net)学习(OUC新芽第五周)
本周学习了DNA-Net论文中的特征提取模块密集嵌套交互模块(DNIM), 特征金字塔融合模块(FPFM),八连通邻域聚类算法。下周计划继续学习红外小目标检测的相关论文。DNA-Net处理流程如上图所示,图像被送入密集嵌套交互模块(DNIM)的核心结构中,该模块用于提取多尺度的特征,并通过一个通道与空间注意力模块(CSAM)来增强这些特征,以解决不同层级特征间的语义差异。
本周学习了DNA-Net论文中的特征提取模块密集嵌套交互模块(DNIM), 特征金字塔融合模块(FPFM),八连通邻域聚类算法。
下周计划继续学习红外小目标检测的相关论文。
目录
论文地址:
https://arxiv.org/pdf/2106.00487
代码地址:
https://github.com/YeRen123455/Infrared-Small-Target-Detection
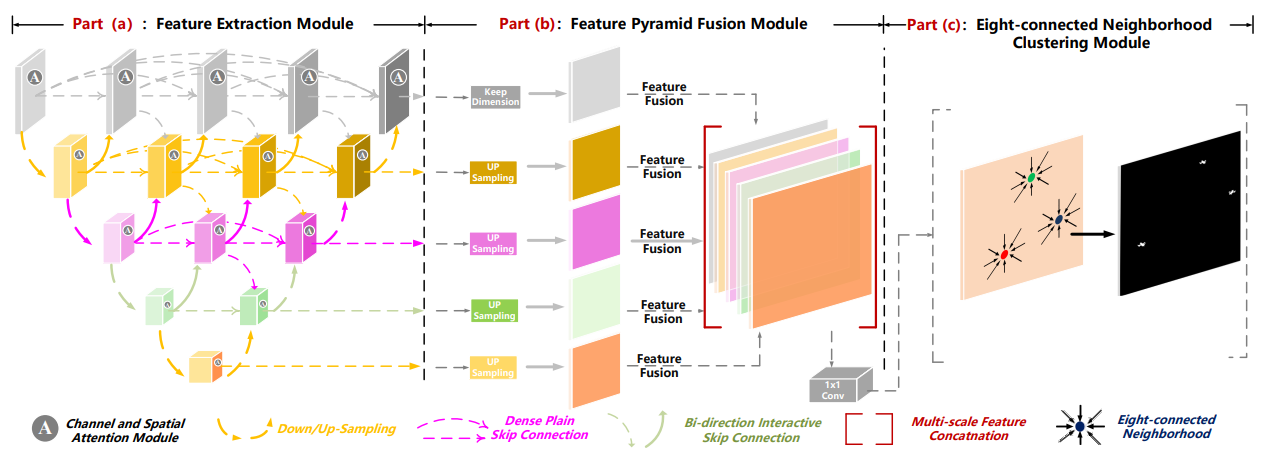
DNA-Net处理流程如上图所示,图像被送入密集嵌套交互模块(DNIM)的核心结构中,该模块用于提取多尺度的特征,并通过一个通道与空间注意力模块(CSAM)来增强这些特征,以解决不同层级特征间的语义差异。接着,这些被增强的特征图被送入特征金字塔融合模块(FPFM),在这里它们被统一尺寸并进行拼接,将浅层的空间细节与深层的高级信息相结合,生成一张的最终特征图。最后,利用八连通邻域聚类算法对这张图进行处理,通过聚类分析来确定出每个目标区域的中心点位置。接下来将分别介绍这三个部分。
特征提取模块密集嵌套交互模块(DNIM)
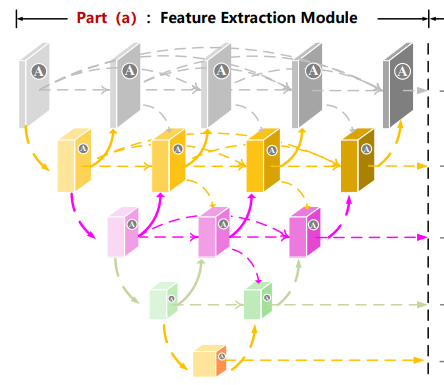

作者认为红外小目标的尺寸差异巨大,其范围从单个像素(即点目标)到数十个像素(即扩展目标)不等。随着网络层数的增加,虽然可以获取到扩展目标的高层信息,但是点目标却容易在多次池化操作后丢失。所以我们应当设计一个特殊的模块,用以在提取高层特征的同时,保持小目标在网络深层中的特征表示。由于不同尺寸目标所需的最佳感受野差异巨大,这些具有不同深度的U形子网络便天然地适用于检测不同尺寸的目标。此外作者认为他提出的模块中除了具有U形子网络的优点外,每个节点都可以从其自身以及相邻的层级接收特征,从而实现了重复性的多层特征融合。这样一来,小目标的特征表示在网络的深层中得以保持,因此能够取得更好的效果。
在密集嵌套交互模块(DNIM)中,节点的计算流程分为两种情况。对于处于编码器主干路径上的节点(即 j=0 的情况,就是最左边的一列节点),其计算遵循一个标准的下采样流程,公式如下:
![]()
例如,一个维度为 (4, 16, 256, 256) 的特征图流入i=1,j=0的节点时,会先经过卷积块 F 进行特征提取(维度变为 (4, 32, 256, 256)),然后通过一个步长为2的最大池化进行下采样,最终输出维度减半的特征图 (4, 32, 128, 128)。i=0,j=0的节点具体内容如下图所示:
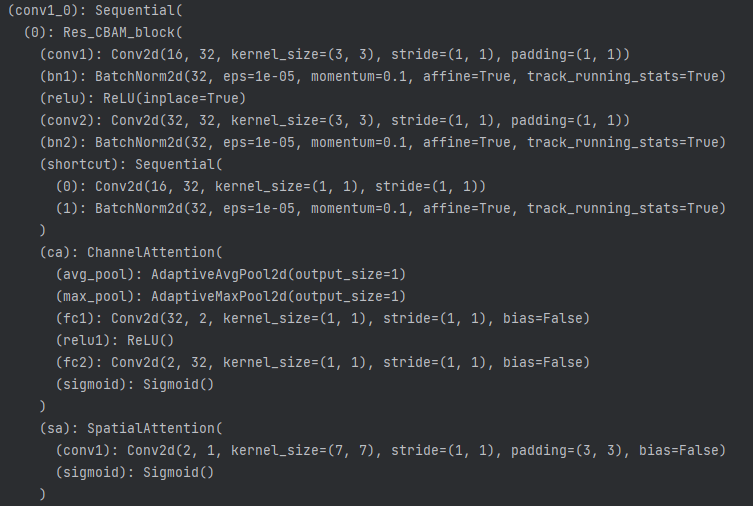
就是一个残差块串联上通道和空间注意力。计算公式体现成代码为:
x1_0 = self.conv1_0(self.pool(x0_0))而对于模块内部的融合节点(即 j>0 的情况),计算流程要复杂一点,公式如下:
![]()
它会从三个方向汇集信息:首先,它会拼接并处理来自同一层级i上所有先前节点(j-1, j-2,...)的输出;其次,它会接收来自更深层级 i+1,j-1 的特征,并通过一个上采样层 U 将其放大;最后,它还会接收来自更浅层级 i-1,j 的特征,并通过一个下采样层将其缩小。最终,这三个经过对齐的特征图会在通道维度上进行拼接,形成一个通道数剧增、融合了多尺度上下文信息的强大特征图作为该节点的输出。例如,i=1,j=2的节点会收到三个方向汇集信息,A.来自同一层级i上所有先前节点(1,0),(1,1)的输出,形状都为(4, 32, 128, 128) (同一层形状相同)B.来自更深层级节点(2,1)的输出,形状为 B.(4, 64, 64, 64),通过一个上采样层 U 将其放大为 (4, 64, 128, 128) C.来自更浅层级节点(0,2)的输出,形状为 B.(4, 16, 256, 256),并通过一个下采样层将其缩小为 (4, 16, 128, 128)(这里的上下采样仅改变图片尺寸,没有对应的减少增加通道数量)。i=1,j=2的节点具体内容如下图所示:
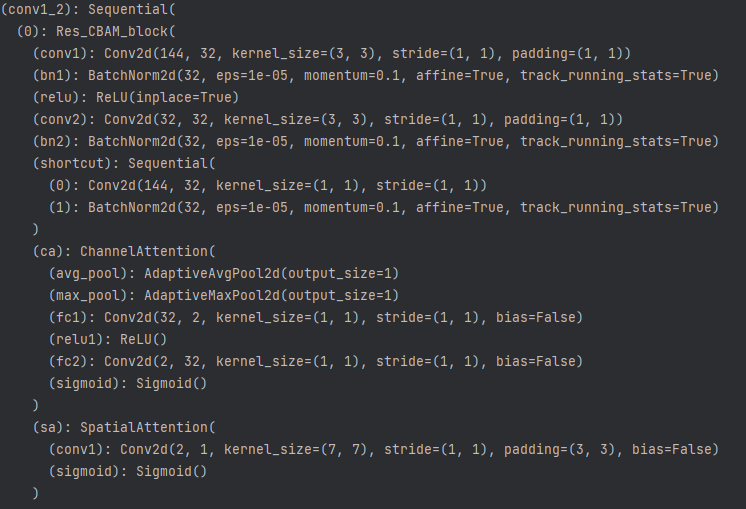
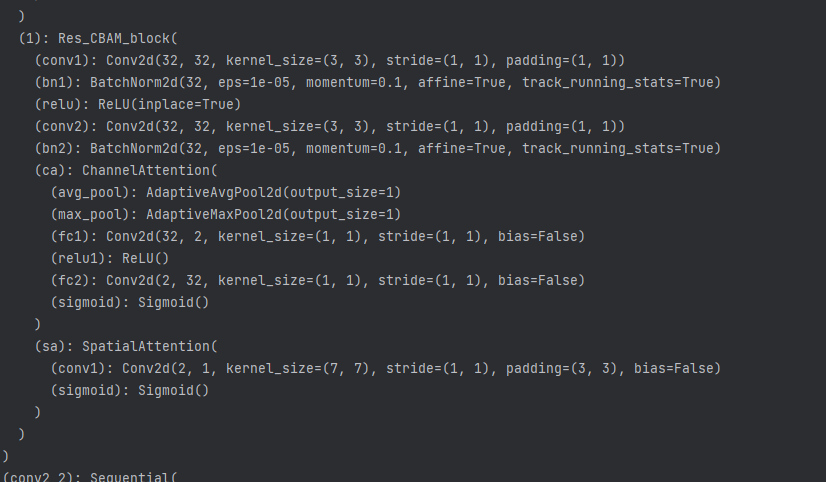
注意到i=1,j=2的节点是由两个残差块堆叠而成的。计算公式体现成代码为:
x1_2 = self.conv1_2(torch.cat([x1_0, x1_1, self.up(x2_1),self.down(x0_2)], 1))其中up与down分别为
self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
self.down = nn.Upsample(scale_factor=0.5, mode='bilinear', align_corners=True)仅改变图片尺寸,没有对应的减少增加通道数量,上下采样后三个来源尺寸相同,concatenate后通道数量为32+32+64+16=144,正巧与第一个残差块第一个卷积的输入通道144相对应。
特征金字塔融合模块(FPFM)
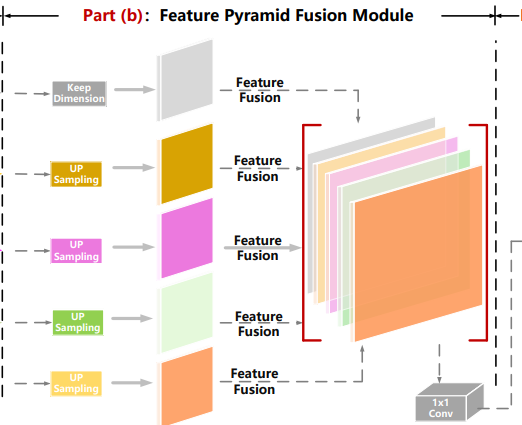

经过特征提取模块增强后的特征图会进入这一阶段进行融合,如上图所示,在FPFM模块中,来自不同尺度、经过CSAM增强的多层特征会被上采样到相同的尺寸。 然后包含丰富空间信息的浅层特征与含有高级别语义信息的深层特征进行拼接,生成一个信息更丰富的特征图。从上到下五个特征图输入的维度分别为(0,4)=(4,16,256,256),(1,3)=(4,32,128,128),(2,2)=(4,64,64,64),(3,1)=(4,128,32,32),(4,0)=(4,256,16,16)。FPFM模块代码体现为
Final_x0_4 = self.conv0_4_final(
torch.cat([self.up_16(self.conv0_4_1x1(x4_0)),self.up_8(self.conv0_3_1x1(x3_1)),
self.up_4 (self.conv0_2_1x1(x2_2)),self.up (self.conv0_1_1x1(x1_3)), x0_4], 1))其中up.x表示几倍的上采样,conv1x1把维度降到16(深度0节点的特征图通道维度),处理后五个特征图长宽尺寸都变为256了,通道维度都变为16了。然后用一个残差块进行融合,把通道维度由16*5降到16,self.conv0_4_final残差块结构如下:
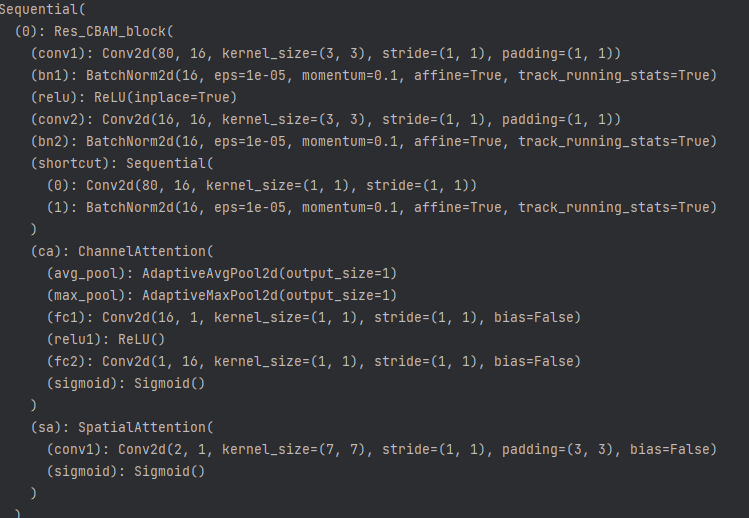
经过self.conv0_4_final,得到特征图维度为(4,16,256,256),这个结果将分别经过4个k1s1p0的卷积得到4个(4,1,256,256)的预测结果。
这个特征拼接的模块对于若干个通道维度不同,尺度不同的特征图是这么处理的:先通过k1s1p0卷积把所有特征图统一通道维度到通道最少,尺寸最大的特征图(这个尺寸也是最终预测图的尺寸,x04),然后上采样来统一尺寸到通道最少,尺寸最大的特征图(这个尺寸也是最终预测图的尺寸,x04),接着用一个大残差卷积块把拼接的特征图通道维度降到通道最少,尺寸最大的特征图(这个尺寸也是最终预测图的尺寸,x04),最后用k1s1p0的卷积把通道维度降为1。
大概分为几个步骤:A.统一通道尺寸-B.降通道维-C.降通道维
对于A,如果先上采样统一尺寸,后统一通道维度效果会怎么样;如果只统一尺寸,不统一通道维度会怎么样(类似前面DNIM就是不同通道维度concatenate)
对于B与C,B显然是不可或缺的,因为引入了两大注意力,如果不用C,在B中直接把通道降为1效果怎么样?这些问题可以通过实验来验证。·
八连通邻域聚类算法
所谓八连通区域或八邻域,是指对应位置的上、下、左、右、左上、右上、左下、右下,是紧邻的位置和斜向相邻的位置。共8个方向,所以称之为8连通区域或八邻域。

对应的还有四连通区域或四邻域,是指对应像素位置的上、下、左、右,是紧邻的位置。共4个方向,所以称之为四连通区域,又叫四邻域。


对于上图,4连通意义上可分成独立的三个区域,在8连通意义上只有一个区域。
八连通邻域聚类算法的实质就是,如果特征图g中任意两个像素g(m0,n0), g(m1,n1)在它们的八个邻域内有交集区域,且具有相同的值(0或1),则认为这两个像素处于连通区域。连接区域中的像素属于相同的目标。当图像中所有目标确定时,质心作为它们的坐标计算。八连通邻域聚类算法在本项目中封装在PD_FA类中,PD (探测概率)表示 有多少真实的目标被成功检测出来了?FA (虚警/误报)表示模型检测出了多少不存在的假目标?上一篇文章已经详细介绍过了。代码如下:
class PD_FA():
def __init__(self, nclass, bins):
super(PD_FA, self).__init__()
self.nclass = nclass
self.bins = bins
self.image_area_total = []
self.image_area_match = []
self.FA = np.zeros(self.bins+1)
self.PD = np.zeros(self.bins + 1)
self.target= np.zeros(self.bins + 1)
def update(self, preds, labels):
for iBin in range(self.bins+1):
score_thresh = iBin * (255/self.bins)
predits = np.array((preds > score_thresh).cpu()).astype('int64')
predits = np.reshape (predits, (256,256))
labelss = np.array((labels).cpu()).astype('int64') # P
labelss = np.reshape (labelss , (256,256))
image = measure.label(predits, connectivity=2)
coord_image = measure.regionprops(image)
label = measure.label(labelss , connectivity=2)
coord_label = measure.regionprops(label)
self.target[iBin] += len(coord_label)
self.image_area_total = []
self.image_area_match = []
self.distance_match = []
self.dismatch = []
for K in range(len(coord_image)):
area_image = np.array(coord_image[K].area)
self.image_area_total.append(area_image)
for i in range(len(coord_label)):
centroid_label = np.array(list(coord_label[i].centroid))
for m in range(len(coord_image)):
centroid_image = np.array(list(coord_image[m].centroid))
distance = np.linalg.norm(centroid_image - centroid_label)
area_image = np.array(coord_image[m].area)
if distance < 3:
self.distance_match.append(distance)
self.image_area_match.append(area_image)
del coord_image[m]
break
self.dismatch = [x for x in self.image_area_total if x not in self.image_area_match]
self.FA[iBin]+=np.sum(self.dismatch)
self.PD[iBin]+=len(self.distance_match)
其中
image = measure.label(predits, connectivity=2)实现了八连通聚类的效果,connectivity=1 代表四连通,即如果两个像素共享一条边,则它们是相连的。connectivity=2 代表八连通,即如果两个像素共享一条边或一个角点,则它们是相连的。该函数会遍历整个 predits 图,将所有通过八连通方式连接在一起的像素块(值为1的像素)视为同一个目标。它会返回一个新的数组 image,其中背景仍然是0,第一个被发现的目标区域所有像素都被标记为1,第二个目标区域所有像素都被标记为2,以此类推。这样就完成了“将属于同一目标的像素聚类在一起”的任务。
coord_image = measure.regionprops(image)
centroid_image = np.array(list(coord_image[m].centroid))这段代码计算每个目标的质心。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)