机器学习笔记(10)--回归分析
本文介绍了线性回归模型及其相关技术。首先讲解了数学基础,包括相关系数矩阵、皮尔逊相关系数、最小二乘法等概念。然后详细阐述了简单线性回归模型的实现过程,包括Python代码示例和数据可视化方法。接着介绍了RANSAC算法用于处理异常值,以及模型性能评估方法如残差图、均方误差等。最后讨论了回归分析的正则化方法(岭回归和LASSO)以及非线性回归技术(多项式回归和随机森林回归)。文章通过理论讲解和代码实
一.数学基础
1.相关系数矩阵:是表现每个变量两两之间关系的矩阵,矩阵元素通常用皮尔逊相关系数计算
2.皮尔逊相关系数:衡量两个连续变量线性相关强度与方向的指标
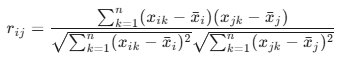 注:其实就是协方差除两个标准差
注:其实就是协方差除两个标准差
3.最小二乘法OLS:通过最小化误差的平方和寻找数据的最佳函数匹配
4.均方误差MSE:预测值与真实值之间的平均平方误差
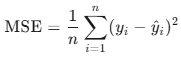
5.最小误差平方和SSE:
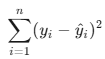
6.总平方和SST:
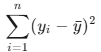
二.简单线性回归模型
1.基本概念
线性回归模型:通过模型来描述某一特征与连续输出之间的关系
当只有一个变量时,被称为简单线性回归,模型可定义为:y=w0+w1x
最佳拟合线被称为回归线,回归线与样本点的垂直连线叫偏移或残差
简单线性回归模型一般使用最小二乘法作为代价函数:
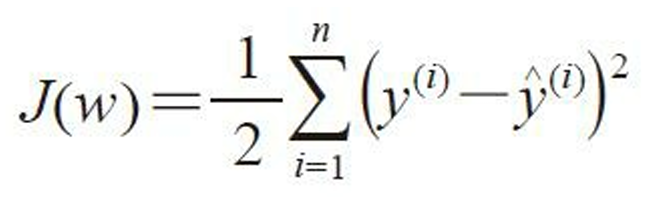
代价函数和权重更新和Adaline算法一样,只是没有了单位阶跃函数
2.python实现线性回归模型
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.preprocessing import StandardScaler
df = pd.read_csv(r'E:\learn\AI\database\housing.data', header=None, sep='\s+')
df.columns = ['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT', 'MEDV']
# 用sns绘制散点图,以方便看各项之间关系
sns.set(style='whitegrid', context='notebook')
# 选取部分特征
cols = ['LSTAT', 'INDUS', 'NOX', 'RM', 'MEDV']
sns.pairplot(df[cols], height=2.5)
plt.show()
# 用sns绘制相关系数矩阵的热图
cm = np.corrcoef(df[cols].values.T)
sns.set(font_scale=1.5)
hm = sns.heatmap(cm, cbar=True, annot=True, square=True, fmt='.2f', annot_kws={'size': 15}, yticklabels=cols, xticklabels=cols)
plt.show()
# 线性回归模型
class LinearRegressionGD():
"""
线性回归梯度下降算法
eta: 学习率
n_iter: 迭代次数
w_: 权重向量
errors_: 每次迭代错误分类的样本数
"""
def __init__(self, eta=0.001, n_iter=20):
"""初始化"""
self.eta = eta
self.n_iter = n_iter
def fit(self, X, y):
"""
训练模型
X: 训练样本
y: 训练样本的标签
"""
self.w_ = np.zeros(1 + X.shape[1])
self.cost_ = []
for i in range(self.n_iter):
output = self.net_input(X)
errors = (y - output)
self.w_[1:] += self.eta * X.T.dot(errors)
self.w_[0] += self.eta * errors.sum()
cost = (errors**2).sum() / 2.0
self.cost_.append(cost)
return self
def net_input(self, X):
"""计算净输入"""
return np.dot(X, self.w_[1:]) + self.w_[0]
def predict(self, X):
"""返回预测结果"""
return self.net_input(X)
X = df[['RM']].values
y = df['MEDV'].values
# 标准化
sc_x = StandardScaler()
sc_y = StandardScaler()
X_std = sc_x.fit_transform(X)
y_std = sc_y.fit_transform(y.reshape(-1, 1)).flatten()
# 训练模型
lr = LinearRegressionGD()
lr.fit(X_std, y_std)
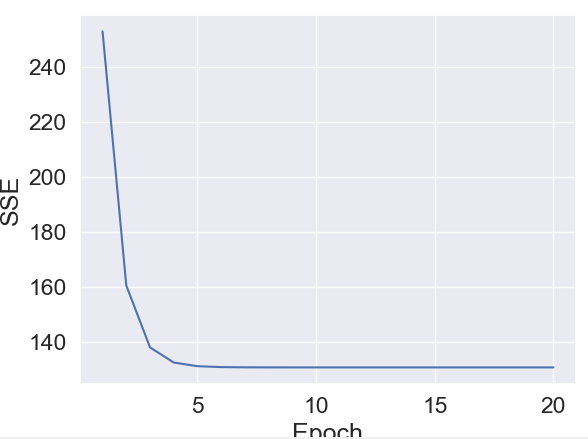
# 绘制代价函数图
plt.plot(range(1, lr.n_iter+1), lr.cost_)
plt.ylabel('SSE')
plt.xlabel('Epoch')
plt.show()
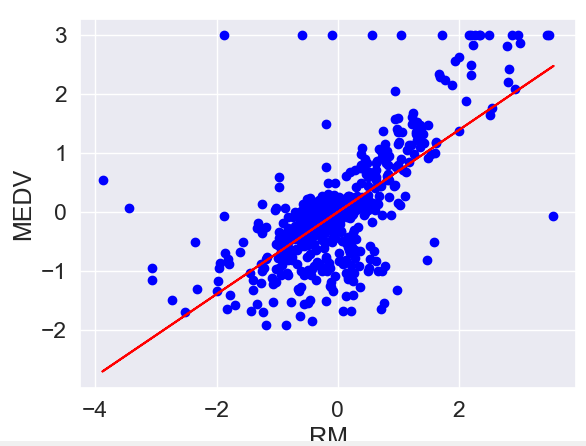
def lin_regplot(X, y, model):
"""绘制线性回归模型"""
plt.scatter(X, y, c='blue')
plt.plot(X, model.predict(X), color='red')
# 绘制线性回归模型
lin_regplot(X_std, y_std, lr)
plt.xlabel('RM')
plt.ylabel('MEDV')
plt.show()
三.随机抽样一致性算法RANSAC
1.RANSAC算法流程
a.从数据集中随机抽取样本构建内点集合来拟合模型。
b.使用剩余数据对上一步得到的模型进行测试,并将落在预定公差范围内的样本点增至内点集合中
c.使用全部的内点集合数据再次进行模型的拟合
d.使用内点集合来估计模型的误差
e.如果模型性能达到了用户设定的特定阈值或者迭代达到了预定次数,则算法终止,否则跳转到第a步
2.scikit-learn实现RANSAC算法
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression
from sklearn.linear_model import RANSACRegressor
df = pd.read_csv(r'E:\learn\AI\database\housing.data', header=None, sep='\s+')
df.columns = ['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT', 'MEDV']
X = df[['RM']].values
y = df['MEDV'].values
# 标准化
sc_x = StandardScaler()
sc_y = StandardScaler()
X_std = sc_x.fit_transform(X)
y_std = sc_y.fit_transform(y.reshape(-1, 1)).flatten()
# RANSAC线性回归模型
ransac = RANSACRegressor(LinearRegression(),
min_samples=50,
max_trials=100,
loss='absolute_error',
residual_threshold=5.0,
random_state=0)
ransac.fit(X, y)
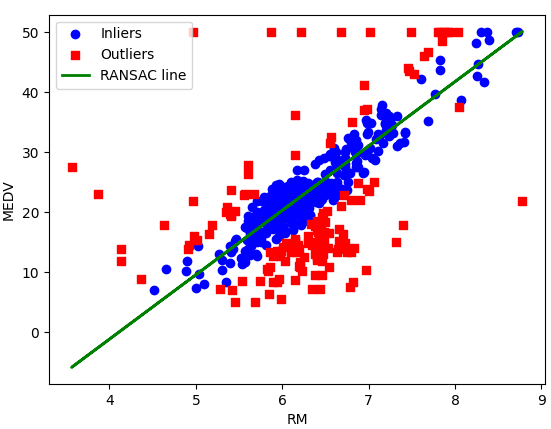
# 绘制内点、外点和拟合线
linier_mask = ransac.inlier_mask_ # 内点掩码
outlier_mask = np.logical_not(linier_mask) # 外点掩码
line_X = np.arange(3, 10, 1)
line_y_ransac = ransac.predict(line_X[:, np.newaxis])
plt.scatter(X[linier_mask], y[linier_mask], c='blue', marker='o', label='Inliers')
plt.scatter(X[outlier_mask], y[outlier_mask], c='red', marker='s', label='Outliers')
plt.plot(X, ransac.predict(X), color='green', linewidth=2, label='RANSAC line')
plt.xlabel('RM')
plt.ylabel('MEDV')
plt.legend(loc='upper left')
plt.show()
四.线性回归模型性能评估
1.残差图
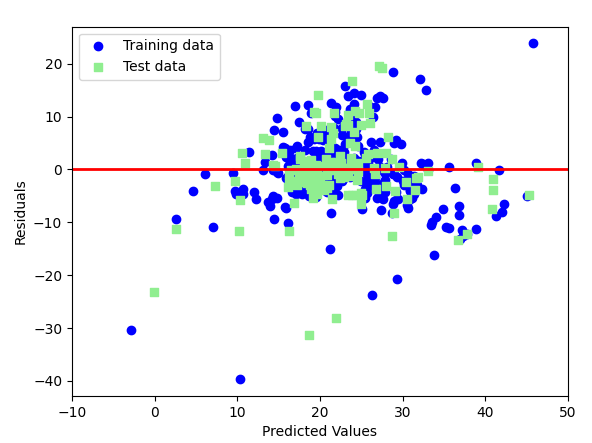
若模型较好,则残差应当在中心线附近随机分布。
如果分布存在规律,说明缺失了样本信息,样本没有很好拟合。
2.均方误差MSE
若训练集均方误差远小于测试集均方误差,则说明存在过拟合
3.决定系数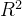
![]()
若=1,则说明模型完美拟合数据,越低,则拟合程度越差
五.回归分析的正则化
回归分析的正则化同样是在代价函数后加上正则化项
1.岭回归
岭回归是基于L2罚项的正则化方法
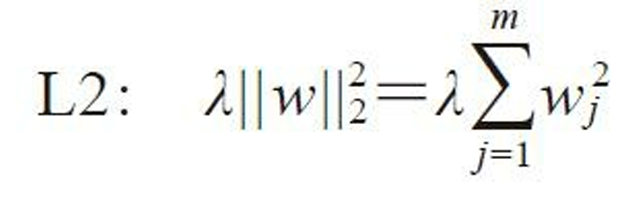
2.LASSO回归
LASSO回归是基于L1罚项的正则化方法
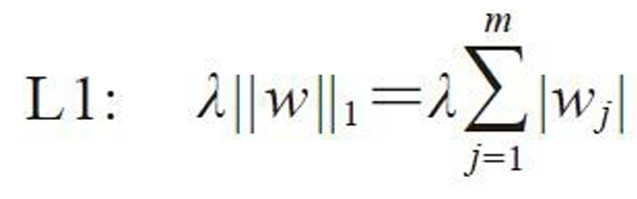
六.非线性回归
1.多项式回归
对于非线性问题,常用的方法便是多项式回归:
![]()
2.随机森林回归
随机森林回归和随机森林的区别是随机森林回归用的不纯度度量标准为MSE,即:
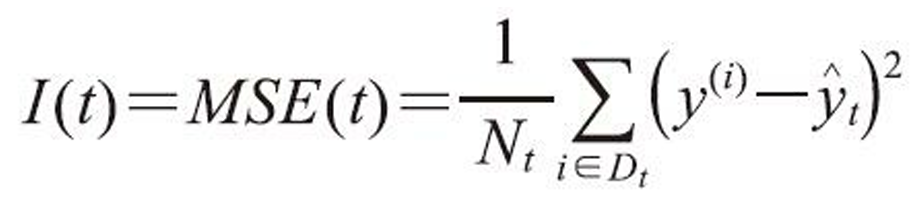
其他步骤和随机森林分类相同

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 19
19 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)