李行统计学习,习题8.1
题目解题步骤:既然弱分类器是决策树,那就先用决策树分类吧。常见的决策树算法有ID3,C4.5和CART树,这里我选用CART树。1,确定权值 因为是第一次计算,所以每个权值初始化为0.1,即W1 = (w11, w12, ..., w110) = (0.1,0.1, ..., 0.1)2,确定弱分类器: 用A, B, C表示“
题目

解题步骤:
既然弱分类器是决策树,那就先用决策树分类吧。
常见的决策树算法有ID3,C4.5和CART树,这里我选用CART树。
1,确定权值
因为是第一次计算,所以每个权值初始化为0.1,即W1 = (w11, w12, ..., w110) = (0.1,0.1, ..., 0.1)
2,确定弱分类器:
用A, B, C表示“身体、业务、潜力”这三个特征
2.1,求Gini:
Gini(D,A = 1)

PS1:D1:身体为0的样本,D2:身体为1的样本,D:所有样本
PS2:W_D1_sum:D1的权值和,W_D2_sum:D2的权值和
PS3:原本的公式中没有W_D1_sum和W_D2_sum,但是根据Adaboost算法,我们需要在确定弱分离器的分类标准时将每个样本的权值作用到里面,所以我添加了这个。
PS4:PS3是个人想法,可能不是最恰当的做法,还望指正。
PS5:因为最初所有的权值都一样,因此这次我就不计算W_D1_sum和W_D2_sum了,因此这里得出的Gini都没有计算W_D1_sum和W_D2_sum。

同理求出B和C的Gini:
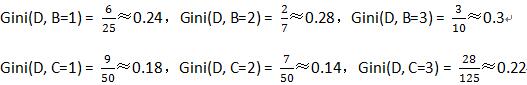
2.2,选出最小的Gini作为最优切分点
因为Gini(D, C=2)最小,所以“‘潜力’的特征‘2’”是最优切分点。
2.3,切分。
此时有决策树:
原始样本
/ \
左分支(属于潜力2) 右分支(属于非潜力2)
/ \
样本3,6,7 样本1,2,4,5,8,9,10
2.4,对左分支和右分支不停的重复以上步骤,得出第一个决策树,这里为了简单起见,我对决策树进行“前剪枝”,即:规定决策树的层数只有1层,因此我的决策树到此为止,而这就是第一个弱分类器G1(x)。
3,计算误差率。
对于上述决策树,经计算发现:左分支中有2个误分类到-1类,右分支中有1个误分类1类,所以一共有3个误分类点,其权值的和为0.3,即误差率是e1 = 0.3。
4,计算G1(x)的系数。
a1= (1/2) log [(1-e1)/e1]
5,更新训练数据的权值分布
W2= (w21, w22, ...,w210)
w2i= (w1i/Z1)exp(-a1yiG1(xi)),i = 1, 2,..., 10
6,确定强分类器F(x)
此时的强分类器是:F(x)= a1G1(x)
7,重复以上步骤,直到误分类点个数为0,或者满足自己的需求。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)