DAX 底层计算过程演示——ADDCOLUMNS + 复杂上下文环境
关于 DAX 理论的资料很多,DAX 理论帮助我们理解和预测 DAX 的计算结果,但 DAX 在底层实际是怎么计算的却少有人谈及。本篇以一段在复杂上下文环境中通过 ADDCOLUMNS 进行计算的 DAX 查询代码为观察对象,使用 DAX Stuido 查看查询计划,展示其在存储引擎中执行了哪些数据查询,揭示公式引擎如何组装这些数据最终得出计算结果。
关于 DAX 理论的资料很多,DAX 理论帮助我们理解和预测 DAX 的计算结果,但 DAX 在底层实际是怎么计算的却少有人谈及。本篇以一段在复杂上下文环境中通过 ADDCOLUMNS 进行计算的 DAX 查询代码为观察对象,使用 DAX Stuido 查看查询计划,展示其在存储引擎中执行了哪些数据查询,揭示公式引擎如何组装这些数据最终得出计算结果。
数据环境
数据文件 下载
1、DFact——数据表,由 Date 和 Amount 两列组成
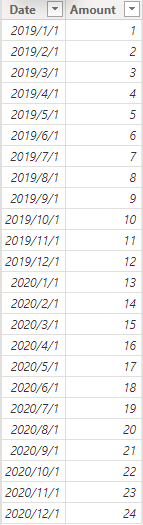
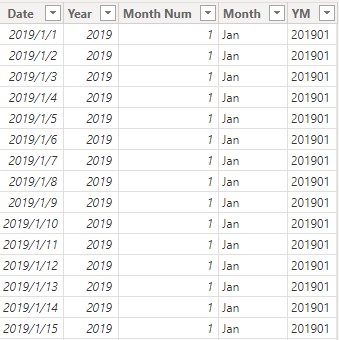
2、Dates——日期表,由 DAX 代码生成
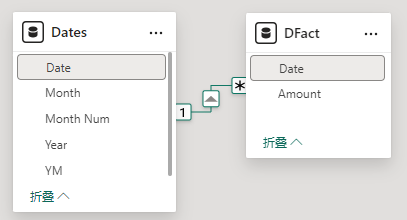
3、两张表通过 [Date] 列建立关系,Dates[Date](1) — (*) DFact[Date]
4、度量值
SumAmount = SUM('DFact'[Amount])
SumxBug = SUMX(VALUES(Dates[Year]),[SumAmount])
DAX 查询代码
EVALUATE
CALCULATETABLE (
ADDCOLUMNS ( VALUES ( Dates[Year] ), "SumxBug", [SumxBug] ),
TREATAS (
{ ( 2019, 1 ), ( 2019, 2 ), ( 2020, 11 ), ( 2020, 12 ) },
'Dates'[Year],
'Dates'[Month Num]
)
)
CALCULATETABLE 以 TREATAS 作为调节器,为ADDCOLUMNS 提供筛选上下文,ADDCOLUMNS 在该上下文中扫描 Dates[Year]并计算度量值[SumxBug]
运行结果如下:
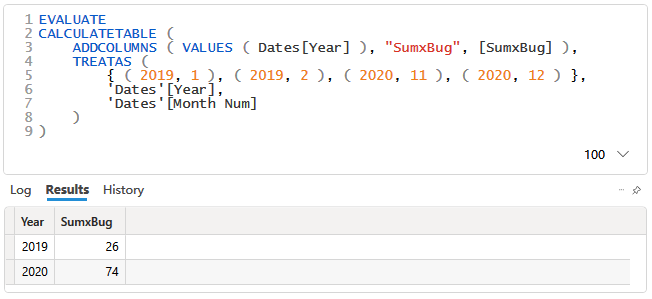
DAX 理论
先用 DAX 理论分析一下计算结果。
下面的图中使用红色数字标记了某些列,这是故意的,后面有用处。
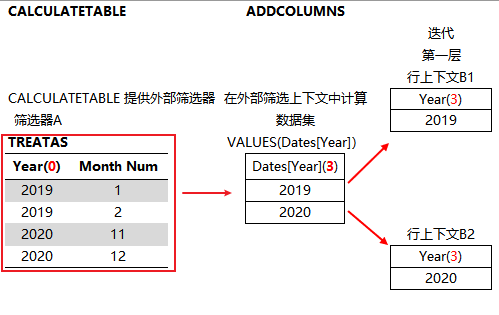
1、CALCULATETABLE 以 TREATAS 作为调节器,为 ADDCOLUMNS提供外部筛选器。
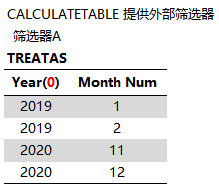
2、在外部筛选上下文中计算 ADDCOLUMNS 一参 VALUES(Dates[Year])

3、ADDCOLUMNS以 2# 数据集为迭代对象,逐行读取行上下文,在外部筛选上下文和行上下文中计算[SumxBug]
SumxBug = SUMX(VALUES(Dates[Year]),[SumAmount])
[SumxBug] 将行上下文转换为筛选上下文,并覆盖外部筛选上下文。
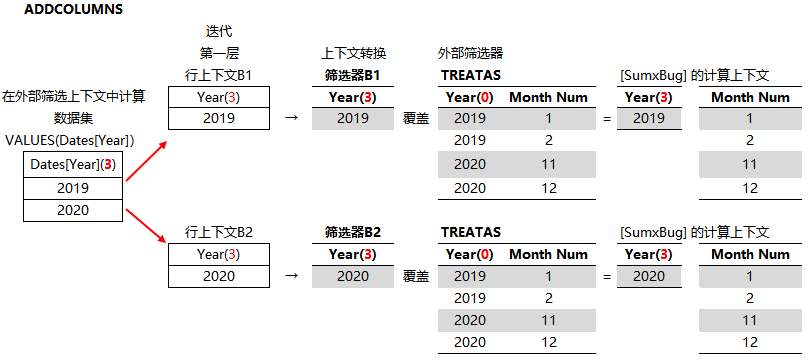
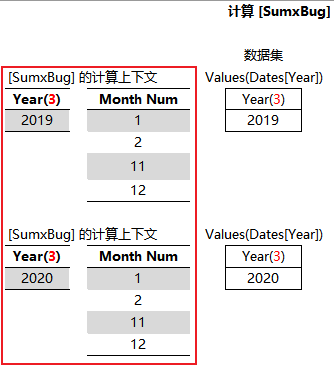
4、计算 SUMX(VALUES(Dates[Year]),[SumAmount])
迭代 Dates[Year] 并计算 [SumAmount] ,这里出现第二层行上下文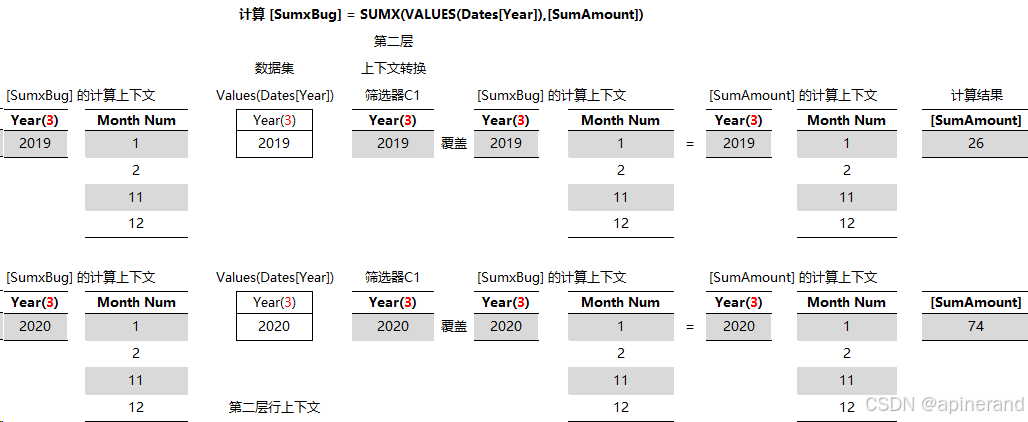
5、合并成最终的结果
完整的分析流程如下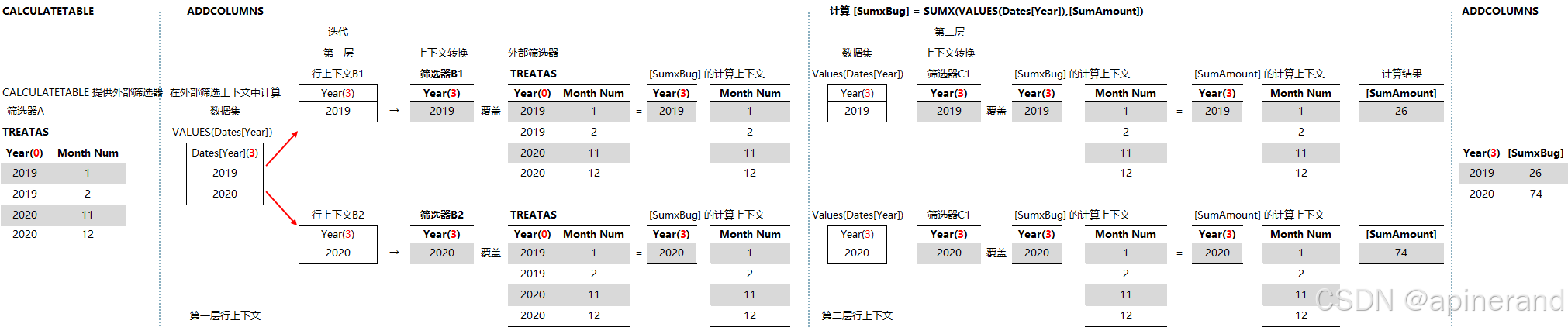
注意在这个过程中存在多层行上下文的事实。
DAX 底层计算过程
以下内容将涉及 DAX 引擎和查询计划,相关资料可查看《权威指南》第二版第17、19章。
存储引擎部分
在 DAX Studio 中通过 Server Timings 窗口,了解到存储引一共执行了 3个 xmSQL 查询。
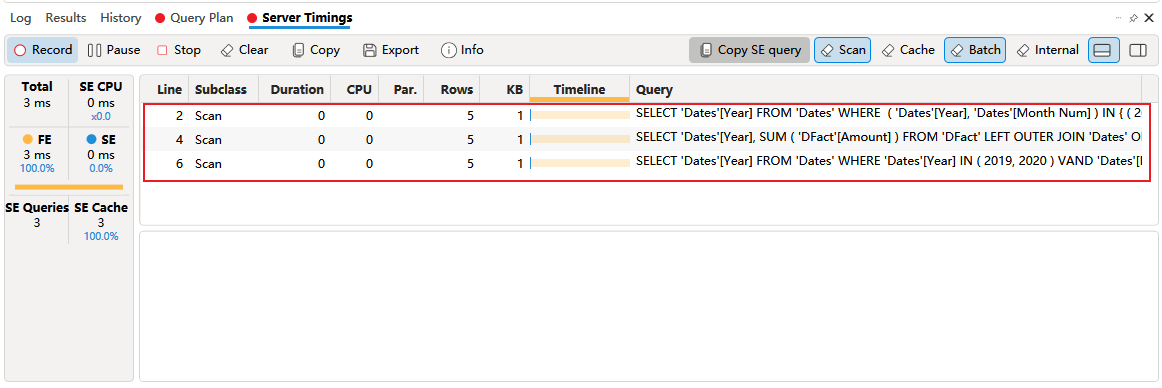
注意 xmSQL 与标准 SQL 不同,xmSQL 语句中的 SELECT 子句中出现的列会自动进行分组,举个例子,有 xmSQL 代码
// xmSQL
SELECT customer[country], customer[state], SUM ( customer[amount] )
FROM customer
与下面的标准 SQL 代码的作用是一样的
// 标准 SQL
SELECT customer.country, customer.state, SUM ( customer.amount )
FROM customer
GROUP BY customer.country, customer.state
为了方便后文指代,这里将这 Server Timings 窗口中的 3 次查询从上往下分别命名为 VQ1、VQ2、VQ3,每个查询的代码、作用和数据如下。
1、VQ1
以 ( 'Dates'[Year], 'Dates'[Month Num] ) IN { ( 2020, 12 ) , ( 2019, 2 ) , ( 2020, 11 ) , ( 2019, 1 ) }为条件,从 Dates 表中分组获取 Year 列上的值
// xmSQL VQ1
SELECT
'Dates'[Year]
FROM 'Dates'
WHERE
( 'Dates'[Year], 'Dates'[Month Num] ) IN { ( 2020, 12 ) , ( 2019, 2 ) , ( 2020, 11 ) , ( 2019, 1 ) };
查询结果包含1个字段列
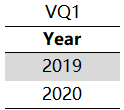
2、VQ2
以'Dates'[Year] IN ( 2019, 2020 ) VAND 'Dates'[Month Num] IN ( 12, 1, 2, 11 ) 为条件,从 DFact 的扩展表中按 Dates[Year] 分组汇总 SUM(DFact[Amount])
// xmSQL VQ2
SELECT
'Dates'[Year],
SUM ( 'DFact'[Amount] )
FROM 'DFact'
LEFT OUTER JOIN 'Dates'
ON 'DFact'[Date]='Dates'[Date]
WHERE
'Dates'[Year] IN ( 2019, 2020 ) VAND
'Dates'[Month Num] IN ( 12, 1, 2, 11 ) ;
查询结果包含1个字段列,1个值列,这里用 Row1 命名该值列
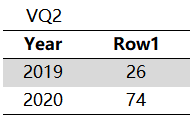
3、VQ3,F1V0
以'Dates'[Year] IN ( 2019, 2020 ) VAND 'Dates'[Month Num] IN ( 12, 1, 2, 11 ) 为条件,从 Dates 表中分组获取 Year 列上的值
// xmSQL VQ3
SELECT
'Dates'[Year]
FROM 'Dates'
WHERE
'Dates'[Year] IN ( 2019, 2020 ) VAND
'Dates'[Month Num] IN ( 12, 1, 2, 11 ) ;
查询结果包含1个字段列

注意在 3 次查询中, VQ1 与 VQ3 的查询结果完全相同,但 WHERE 子句内容不同。
公式引擎部分
在 DAX Studio 中通过 Query Plan 窗口可以查看逻辑查询计划和物理查询计划
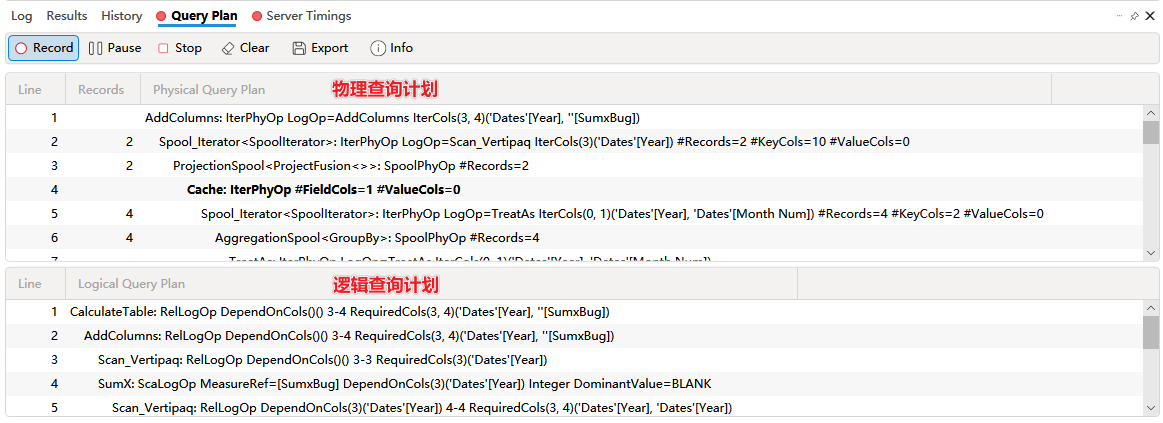
逻辑查询计划略过,物理查询计划完整截图如下:

按照缩进关系画出树状线,方便了解结构层次。
AddColumns: IterPhyOp LogOp=AddColumns IterCols(3, 4)('Dates'[Year], ''[Total])
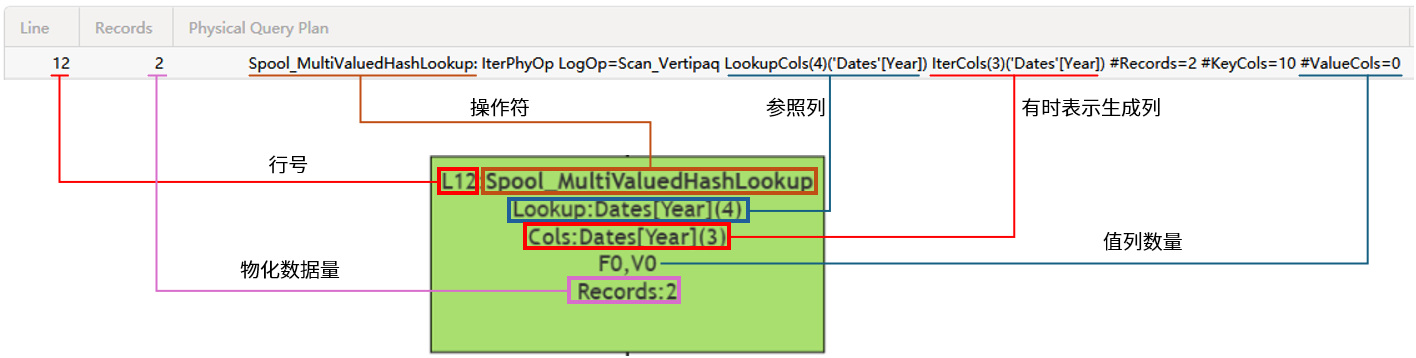
├── Spool_Iterator<SpoolIterator>: IterPhyOp LogOp=Scan_Vertipaq IterCols(3)('Dates'[Year]) #Records=2 #KeyCols=10 #ValueCols=0
│ └── ProjectionSpool<ProjectFusion<>>: SpoolPhyOp #Records=2
│ └── Cache: IterPhyOp #FieldCols=1 #ValueCols=0
│ └── Spool_Iterator<SpoolIterator>: IterPhyOp LogOp=TreatAs IterCols(0, 1)('Dates'[Year], 'Dates'[Month Num]) #Records=4 #KeyCols=2 #ValueCols=0
│ └── AggregationSpool<GroupBy>: SpoolPhyOp #Records=4
│ └── TreatAs: IterPhyOp LogOp=TreatAs IterCols(0, 1)('Dates'[Year], 'Dates'[Month Num])
│ └── TableCtor: IterPhyOp LogOp=TableCtor IterCols(0, 1, 2)(''[Value1], ''[Value2], ''[])
└── SpoolLookup: LookupPhyOp LogOp=SumX LookupCols(3)('Dates'[Year]) Integer #Records=2 #KeyCols=1 #ValueCols=1 DominantValue=BLANK
└── AggregationSpool<Sum>: SpoolPhyOp #Records=2
└── CrossApply: IterPhyOp LogOp=Sum_Vertipaq IterCols(4)('Dates'[Year])
├── Spool_MultiValuedHashLookup: IterPhyOp LogOp=Scan_Vertipaq LookupCols(4)('Dates'[Year]) IterCols(3)('Dates'[Year]) #Records=2 #KeyCols=10 #ValueCols=0
│ └── ProjectionSpool<ProjectFusion<>>: SpoolPhyOp #Records=2
│ └── Cache: IterPhyOp #FieldCols=1 #ValueCols=0
│ ├── Spool_Iterator<SpoolIterator>: IterPhyOp LogOp=TreatAs IterCols(0, 1)('Dates'[Year], 'Dates'[Month Num]) #Records=4 #KeyCols=2 #ValueCols=0
│ │ └── AggregationSpool<GroupBy>: SpoolPhyOp #Records=4
│ │ └── TreatAs: IterPhyOp LogOp=TreatAs IterCols(0, 1)('Dates'[Year], 'Dates'[Month Num])
│ │ └── TableCtor: IterPhyOp LogOp=TableCtor IterCols(0, 1, 2)(''[Value1], ''[Value2], ''[])
│ └── Spool_Iterator<SpoolIterator>: IterPhyOp LogOp=Scan_Vertipaq IterCols(3)('Dates'[Year]) #Records=2 #KeyCols=10 #ValueCols=0
│ └── ProjectionSpool<ProjectFusion<>>: SpoolPhyOp #Records=2
│ └── Cache: IterPhyOp #FieldCols=1 #ValueCols=0
│ └── Spool_Iterator<SpoolIterator>: IterPhyOp LogOp=TreatAs IterCols(0, 1)('Dates'[Year], 'Dates'[Month Num]) #Records=4 #KeyCols=2 #ValueCols=0
│ └── AggregationSpool<GroupBy>: SpoolPhyOp #Records=4
│ └── TreatAs: IterPhyOp LogOp=TreatAs IterCols(0, 1)('Dates'[Year], 'Dates'[Month Num])
│ └── TableCtor: IterPhyOp LogOp=TableCtor IterCols(0, 1, 2)(''[Value1], ''[Value2], ''[])
└── Spool_Iterator<SpoolIterator>: IterPhyOp LogOp=Sum_Vertipaq IterCols(4)('Dates'[Year]) #Records=2 #KeyCols=10 #ValueCols=1
└── ProjectionSpool<ProjectFusion<Copy>>: SpoolPhyOp #Records=2
└── Cache: IterPhyOp #FieldCols=1 #ValueCols=1
└── Spool_Iterator<SpoolIterator>: IterPhyOp LogOp=TreatAs IterCols(0, 1)('Dates'[Year], 'Dates'[Month Num]) #Records=4 #KeyCols=2 #ValueCols=0
└── AggregationSpool<GroupBy>: SpoolPhyOp #Records=4
└── TreatAs: IterPhyOp LogOp=TreatAs IterCols(0, 1)('Dates'[Year], 'Dates'[Month Num])
└── TableCtor: IterPhyOp LogOp=TableCtor IterCols(0, 1, 2)(''[Value1], ''[Value2], ''[])
为了更好地了解物理查询计划的结构,按照层次关系绘制流程结构图。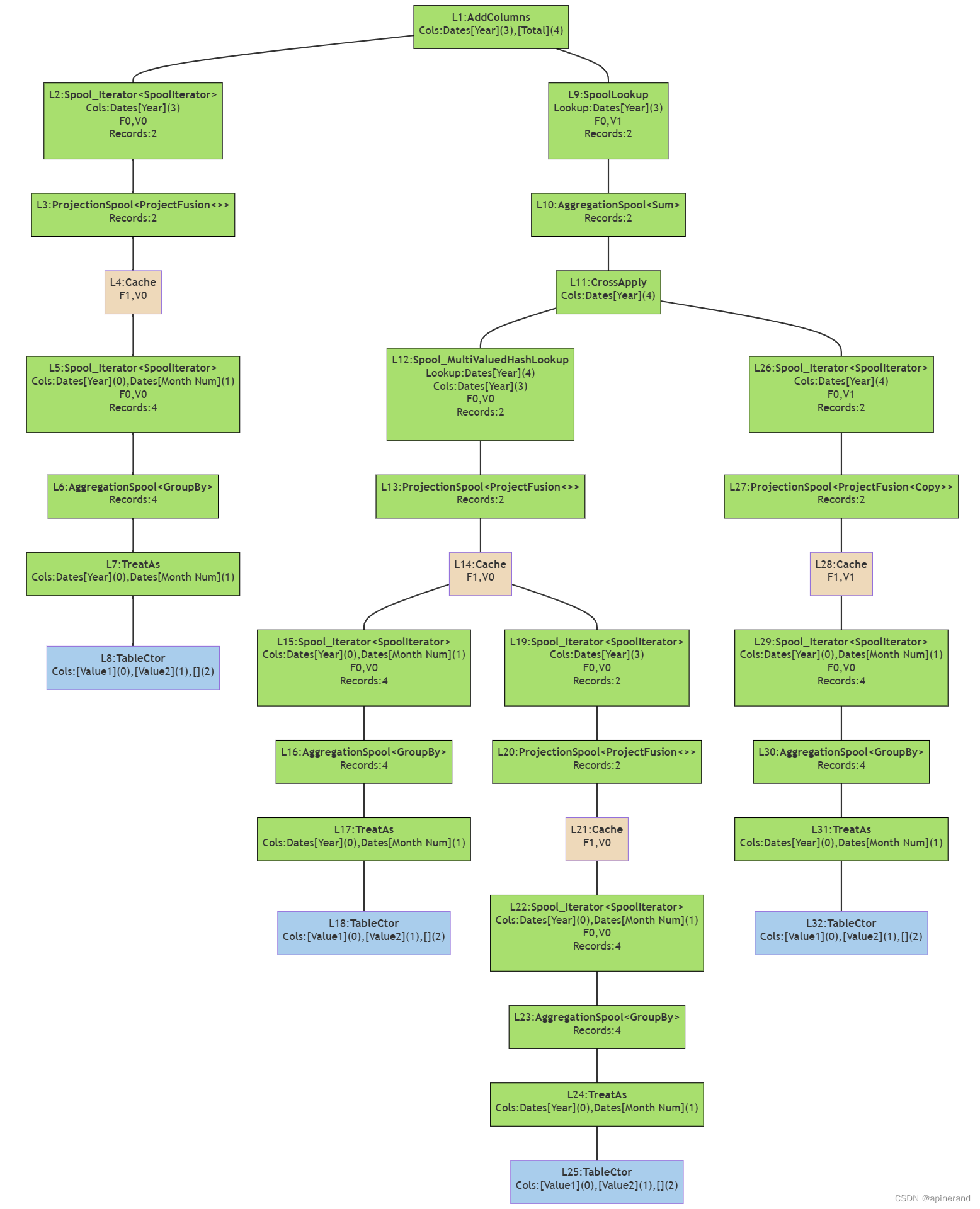
图中每个方块各代表一行代码,对应关系如下图所示。
绿色方块代表数据操作,棕色方块代表 xmSQL 查询的数据缓存,蓝色方块代表其他
底层计算过程
在物理查询的流程结构图上标出各部分生成和组装的数据,从下往上看。
建议右键点击图片,选择【在新标签页中打开图像】以查看大图,详细了解各个部分的说明。
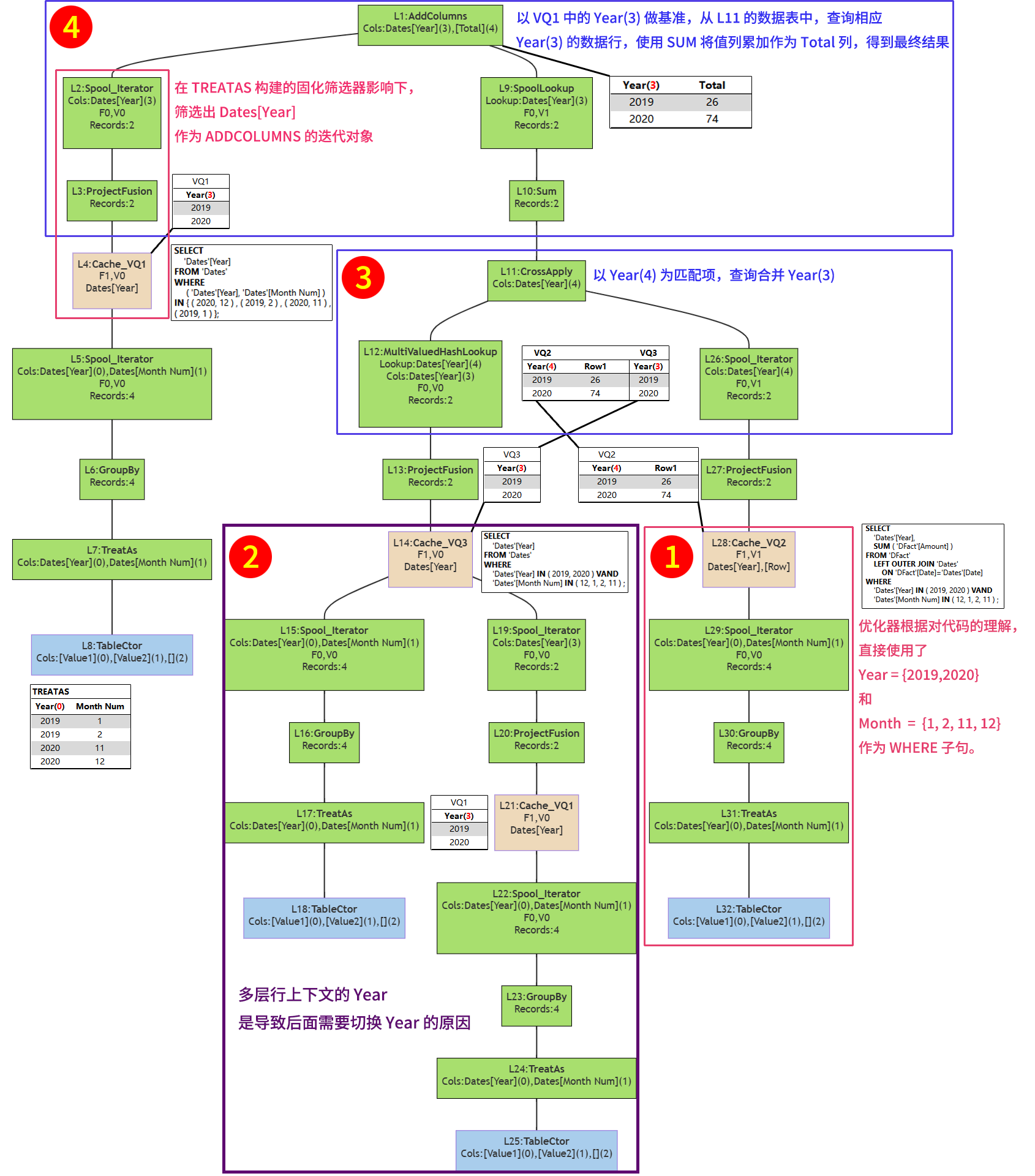
几个说明
1、VQ2 的 WHERE 子句
回顾一下存储引擎执行的 xmSQL VQ2 的内容,WHERE 子句以 Dates[Year] IN ( 2019, 2020 ) 和 Dates[Month Num] IN ( 12, 1, 2, 11 )做条件
SELECT
'Dates'[Year],
SUM ( 'DFact'[Amount] )
FROM 'DFact'
LEFT OUTER JOIN 'Dates'
ON 'DFact'[Date]='Dates'[Date]
WHERE
'Dates'[Year] IN ( 2019, 2020 ) VAND
'Dates'[Month Num] IN ( 12, 1, 2, 11 ) ;
DAX 查询代码中,CALCULATETABLE 使用 TREATAS 构建的固化筛选器作为 ADDCOLUMNS 的筛选上下文,为什么这里的 xmSQL 没有使用固化筛选器,而是将 Year 和 Month Num 拆开了?
如果以固化筛选器为条件,这里的 WHERE 子句应该是这样:
WHERE ( 'Dates'[Year], 'Dates'[Month Num] ) IN { ( 2020, 12 ) , ( 2019, 2 ) , ( 2020, 11 ) , ( 2019, 1 ) }
对照上一节的 DAX 理论分析,真正需要的计算发生在 [SumAmount] = SUM(DFact[Amount]) 这部分,这一部分的计算上下文是什么?
是下图中红框标记出来的这部分,包括 Year = {2019,2020} 和 Month Num = {1, 2, 11, 12},DAX 底层根据对代码的理解,对存储引擎申请的数据查询直接使用了该条件作为 WHERE 子句。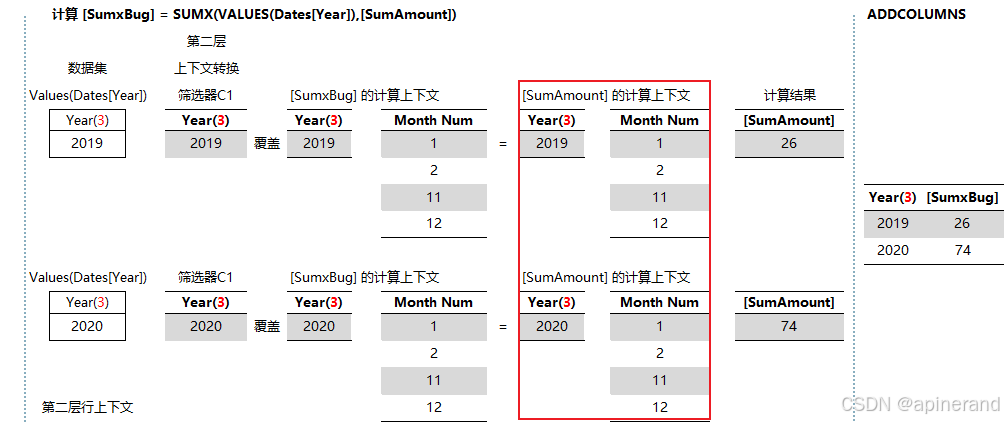
2、为什么 VQ1 和 VQ3 重复查询 Dates[Year]
理论分析部分出现过两个迭代器,均以 Dates[Year] 为迭代对象,形成两套行上下文。
回顾下这两个迭代器的计算上下文:
1)第一个迭代器 ADDCOLUMNS 计算一参时
以 TREATAS 构建的固化筛选器为条件,这对应了 VQ1 的 WHERE 子句
// xmSQL VQ1
SELECT
'Dates'[Year]
FROM 'Dates'
WHERE
( 'Dates'[Year], 'Dates'[Month Num] ) IN { ( 2020, 12 ) , ( 2019, 2 ) , ( 2020, 11 ) , ( 2019, 1 ) };
2)第二个迭代器 SUMX 计算一参时
以 [Year] = {2019,2020} AND [Month Num] = {1, 2, 11, 12} 为条件,对应了 VQ3 的 WHERE 子句
// xmSQL VQ3
SELECT
'Dates'[Year]
FROM 'Dates'
WHERE
'Dates'[Year] IN ( 2019, 2020 ) VAND
'Dates'[Month Num] IN ( 12, 1, 2, 11 ) ;
由此可知:
-
VQ1 对应了
ADDCOLUMNS(VALUES(Dates[Year]),...)中的VALUES(Dates[Year]),对应第一层行上下文 -
VQ3 对应了
SUMX(VALUES(Dates[Year]),...) 中的VALUES(Dates[Year]),对应第二层行上下文
存储引擎需要执行两个 xmSQL 查询,重复获取 Dates[Year] 的值,正是基于有两个迭代器需要在不同的上下文中扫描Dates[Year]。
3、物理查询计划流程结构图中 3# 号框在做什么?
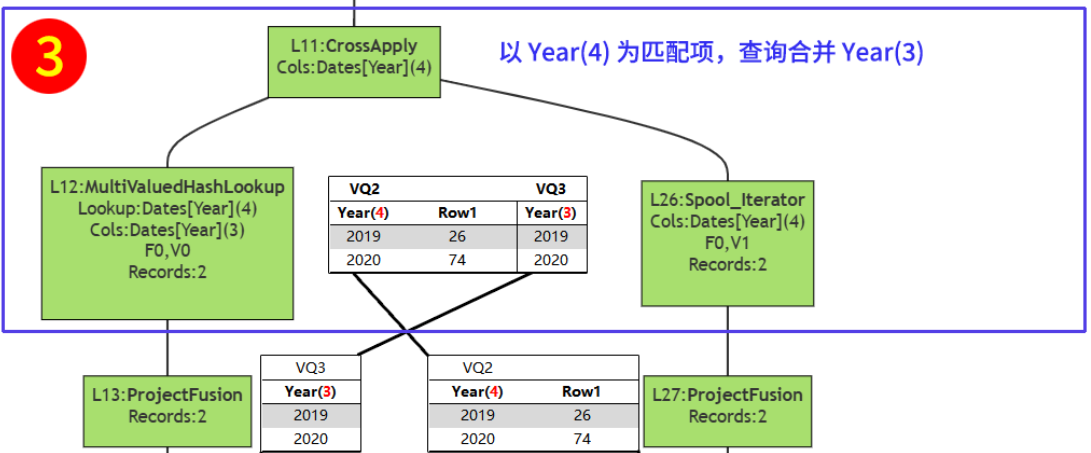
从数据表来看,这一步的作用是将 VQ2 与 VQ3 通过 [Year] 的 hash 值进行匹配合并,在本案例中,VQ2 和 VQ3 是一对一的关系( VQ2(1)—(1)VQ3),合并后的结果有2行。
4、为什么要将 Year(4) 和 Year(3) 合并到一张表里?
因为再往上,ADDCOLUMNS 操作符需要使用 Year(3) 查找对应值,而 VQ2 数据缓存中保存的是 Year(4),不是 Year(3),无法直接进行查找。虽然是同一列,但 DAX 底层会区分来自不同来源的同一列,Year(4) 来自 VQ2,Year(3) 来自 VQ1。
3#号框将 Year(4) 和 Year(3) 匹配合并到一张表中,使得 ADDCOLUMNS 可以从其中通过 Year(3) 找到对应的 Row1 值,形成最终的结果表。
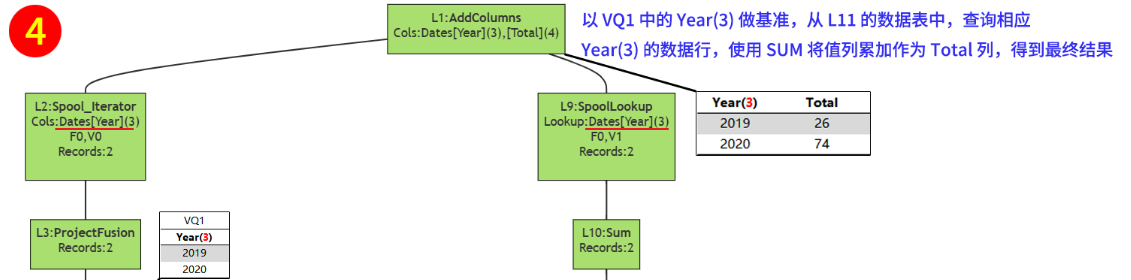
DAX 理论与实际计算过程的关系
有了以上分析后,现在可以将 DAX 理论、存储引擎、公式引擎3者的关系,标记在同一张图上。
(使用鼠标右键点击该图片,选择 “在新标签页中打开图像” 以查看大图)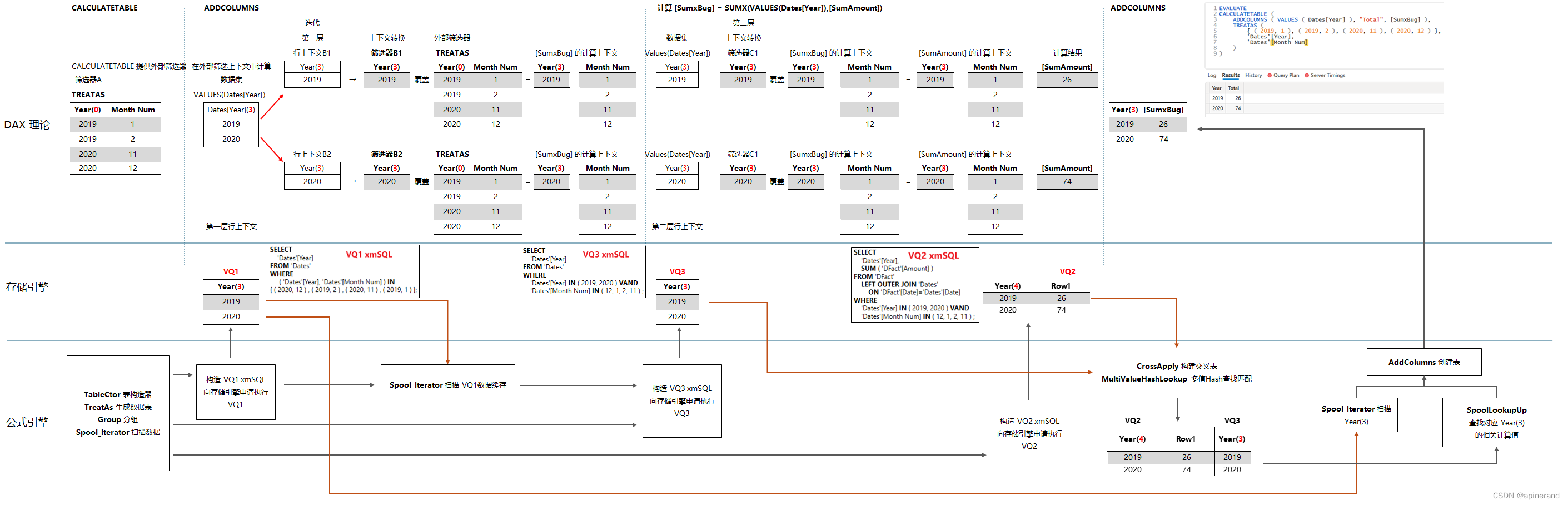
以上便是关于这段 DAX 查询代码,CALCULATETABLE 以 TREATAS 作为调节器,为ADDCOLUMNS 提供筛选上下文,ADDCOLUMNS 在该上下文中扫描 Dates[Year]并计算度量值[SumxBug] 的过程。
其他
这里我给度量值取的名称叫 SumxBug,是因为如果在 PowerBI 搭建报表完成完全相同的计算时会出现 bug,得到不一样的结果,如下图所示
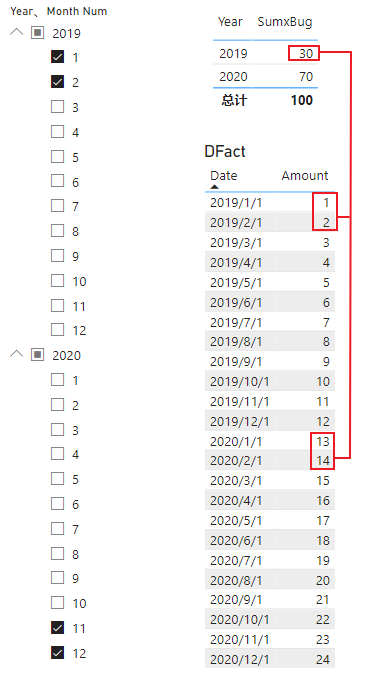
在计算 2019 年的 [SumxBug] 时,实际是将 2019 年 1、2 月和 2020 年 1、2 月的 Amount 累加了起来,1+2+13+14 = 30
在计算 2020 年的 [SumxBug] 时,实际是以 2019 年 11、12 月和 2020 年 11 月、12 月的 Amount 来算的,11+12+23+24 = 70
PowerBI 计算出的结果与 DAX 理论预测的结果不符,与 CALCULATETABLE + ADDCOLUMNS 计算得到的结果不一致,这是由于 PowerBI 中计算报表时使用了 SUMMARIZECOLUMNS,关于 SUMMARIZECOLUMNS 的 bug,可以跳转到下面这篇文章进行了解。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 19
19 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)