MySQL数据库系统八股文(基础篇)
本文系统介绍了MySQL数据库入门必备的核心知识点。内容包括:1)MySQL关系型数据模型及其ACID特性;2)SQL语言的四大分类(DDL、DML、DQL、DCL);3)数据库三大范式;4)SQL语句执行流程;5)常用数据类型对比;6)关键语法区别(WHERE/HAVING、DELETE/TRUNCATE/DROP等);7)事务四大特性与隔离级别;8)索引类型及B+树优势。重点解析了CHAR/V
想入门MySQL或准备面试打基础的话,这篇博客刚好能够帮到你,我们这部分内容不贪多求深,先专门聚焦MySQL入门必懂的基础点,把每个知识点都讲透彻,搭好框架,使后续学习进阶知识时,也能轻松应对。

1.说说你对MySQL数据模型的理解。
(重要程度:⭐⭐⭐)
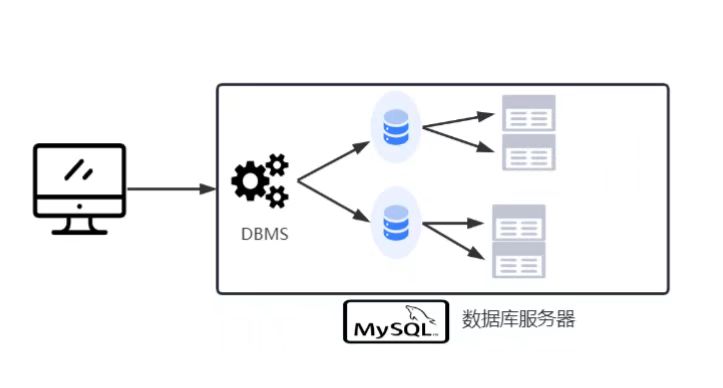
MySQL数据模型以SQL语言作为实现载体,本质是关系型数据模型,围绕表和关系组织数据,它遵循ACID原则,支持一对一、一对多、多对多的关联场景,同时结合约束、范式、索引等设计从而便于维护和查询,是适配各种业务场景的结构化数据存储与管理方案。
2.SQL(Structured Query Language,结构化查询语言)的分类:
(重要程度:⭐⭐⭐⭐)
· DDL(Data Definition Language,数据定义语言):
定义和管理数据库对象,常见操作有CREATE / ALTER / DROP / TRUNCATE;
· DML(Data Manipulation Language,数据操纵语言):
操作表中的数据,常见的操作有INSERT / UPDATE / DELETE;
· DQL(Data Query Language,数据查询语言):
从表中查询数据,唯一核心语句是SELECT;
-- DQL基础模板
SELECT
[DISTINCT] 字段1, 字段2, [聚合函数(字段)] -- DISTINCT去重
FROM
表名1
[LEFT/RIGHT/INNER JOIN 表名2 ON 表1.关联字段 = 表2.关联字段] -- 多表连接(可选)
WHERE
条件1 [AND/OR 条件2] -- 行级筛选
GROUP BY
分组字段1, 分组字段2 -- 按指定字段分组
HAVING
分组后条件 -- 筛选分组结果
ORDER BY
排序字段1 [ASC/DESC], 排序字段2 [ASC/DESC] -- 结果排序(ASC升序,DESC降序,默认ASC)
LIMIT
[偏移量, 行数] -- 限制查询出的数据量(分页)· DCL(Data Control Language,数据控制语言):
管理数据库权限和安全,常见的操作有GRANT / REVOKE / COMMIT。
3.什么是三大范式?
(重要程度:⭐⭐⭐⭐)
· 第一范式(1NF):最基本的范式,数据库表中的所有字段值都不可再分;
· 第二范式(2NF):满足第一范式,一个表必须有一个主键,非主键字段值必须完全依赖于主键;
· 第三范式(3NF):满足第二范式,非主键列必须直接依赖于主键,不能存在传递依赖。
4.请简述一条SQL语句的执行过程。
(重要程度:⭐⭐⭐⭐)
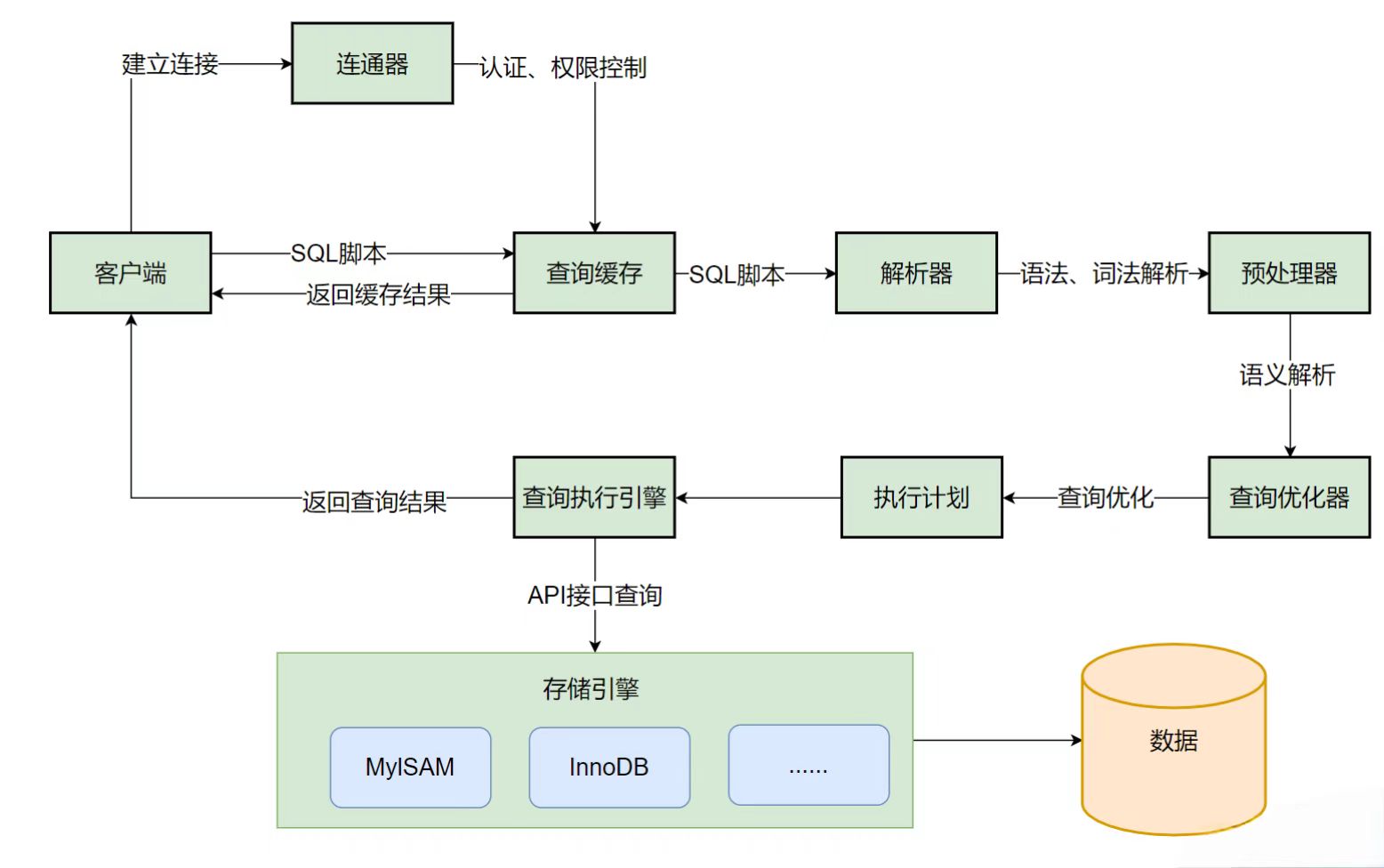
· 连接器:建立连接、身份认证;
· 查询缓存(MySQL 8.0 后废除);
· 解析器:生成语法树;
· 优化器:选择最优执行计划;
· 执行器:与存储引擎交互获取数据。
5.MySQL支持哪些数据类型?请分类说明。
(重要程度:⭐⭐⭐⭐)
· 数值型:
整数类型:TINYINT、INT、BIGINT(存储超大整数);
小数类型:FLOAT、DOUBLE、DECIMAL(m, d)(存储高精度数值);
· 字符串型 :CHAR(定长字符串)、VARCHAR、TEXT(大文本类型,查询效率低);
· 日期时间型:DATE、DATETIME、TIMESTAMP。
6.CHAR和VARCHAR的区别是什么?
(重要程度:⭐⭐⭐⭐⭐)
· CHAR(n):长度固定的字符串,占用n个字符空间,插入时若数据长度不足n也自动用空格补满n位,读写速度快(无需计算长度),查询性能好,适合存储身份证号、手机号等固定不变的数据;
· VARCHAR(n):长度可变的字符串,n为最大存储长度,读写速度较慢但无多余空间浪费,适合存储用户名、商品描述等数据长度波动较大的数据。
7.count(*)、count(1)、count(column)三者的区别:
(重要程度:⭐⭐⭐⭐)
· count(*)(最优选择):统计所有行的数量,包括包含NULL值的行,扫描全部数据行但不关心具体值,查询速度快;
· count(1):将“1”作为常量,逐行计数,与count(*)几乎完全等价
· count(colume):column指表中的具体字段(列),统计指定行中非NULL值的行数。
-- 统计学生表中分数高于80的人数
SELECT count(*) FROM student WHERE score > 80;
-- 统计客户表中手机号不为空的人数
SELECT count(phone) FROM customer;8.DELETE、TRUNCATE、DROP三者的区别有哪些?
(重要程度:⭐⭐⭐⭐)
· DELETE:逐行删除,可回滚,删除部分数据行时,使用该关键字并带上WHERE条件;
· TRUNCATE:整体删除,不可回滚,重置自增ID,想保留表而删除所有数据时用该关键字;
· DROP:删除整张表,包括表结构,不再需要一张表时使用该关键字。
性能:DROP > TRUNCATE > DELETE .
9.WHERE和HAVING的区别是什么?
(重要程度:⭐⭐⭐⭐)
· WHERE:出现在增删改的SQL语句中,用于在数据分组(GROUP BY)和聚合计算(SUM、COUNT)之前过滤数据,不能使用聚合函数作为筛选条件;
· HAVING:只能与SELECT语句配合使用,用于在数据分组和聚合计算之后过滤数据,可以使用聚合函数作为筛选条件。
10.主键和外键分别是什么?
(重要程度:⭐⭐⭐⭐)
· 主键:表中用于唯一标识一条记录的字段,唯一且非空,一张表只能有一个主键,确保记录的唯一性,便于快速定位和关联数据,如用户表的user_id;
· 外键:表A用于关联表B的主键的字段,建立表与表之间的关系,保证数据的一致性和完整性,如订单明细表中的order_id关联订单表的主键。
11.MySQL数据库中的auto_increment是什么?
(重要程度:⭐⭐⭐)
auto_increment(自动递增)是一种自动生成唯一值的机制,为表中的列生成唯一的自增值,通常用于主键(Primary Key)列,无需手动指定自增字段的值即可生成订单编号、用户ID等数据。
12.说说你对笛卡尔积、内连接、外连接的理解。
(重要程度:⭐⭐⭐)
· 笛卡尔积(CROSS JOIN):将A表的每一行与B表的每一行强行组合,即没有任何过滤条件的“全匹配”,通常无实际业务意义;
· 内连接(INNER JOIN):最常用的连接方式,只保留两张表中“匹配条件成立”的行,本质是笛卡尔积 + 过滤条件取交集;
· 外连接(OUTER JOIN):保留匹配的行和“主表”中未匹配的行,未匹配的字段用NULL填充;
· 左外连接(LEFT JOIN):保留左边表的全部行,以及右边表中全部匹配的行;
· 右外连接(RIGHT JOIN):保留右边表的全部行,以及左边表中全部匹配的行。
| 连接类型 | 匹配逻辑 | 结果范围 | 关键字 |
| 笛卡尔积 | 无匹配条件,全组合 | 表A行数 × 表B行数 | , 或CROSS JOIN |
| 内连接 | 只保留匹配成立的行 | 两表的交集 | JOIN / INNER JOIN |
| 左外连接 | 保留左表所有行,右表补NULL | 左表全部 + 右表中匹配的行 | LEFT JOIN |
| 右外连接 | 保留右表所有行,左表补NULL | 右表全部 + 左表中匹配的行 | RIGHT JOIN |
13.简要解释一下什么是子查询。
(重要程度:⭐⭐⭐)
· 条件:一条SQL语句的查询结果作为另一条SQL查询语句的条件或者或者主查询结果的一部分;
-- 查询成绩高于班级平均分的学生姓名和分数
SELECT name, score
FROM students
WHERE score > (SELECT AVG(score) FROM students);
-- 查询每个学生的姓名及选课数量
SELECT name, (SELECT COUNT(*) FROM courses WHERE student_id = s.id)
FROM students s;· 嵌套:多条SQL语句嵌套使用,内部的SQL查询语句称为子查询。
14.简要说明什么是数据库的事务。
(重要程度:⭐⭐⭐)
事务是一组不可分割的SQL语句,也是数据库并发控制的基本单位,其执行结果必须使数据库从一种一致性状态变到另一种一致性状态。
15.MySQL事务的四大特性(ACID):
(重要程度:⭐⭐⭐⭐⭐)
· 原子性(Atomicity):事务是不可分割的最小单位,要么全部执行成功,要么全部执行失败;
· 一致性(Consistency):事务完成时,必须使所有的数据都保持一致状态;
· 隔离性(Isolation):数据库系统提供的隔离机制,保证在事务正确提交之前不会把该事务对数据的任何改变提供给任何其他事务;
· 持久性(Durebility):事务一旦提交或回滚,它对数据库中的数据的改变就是永久的。
16.事务并发带来的问题:
(重要程度:⭐⭐⭐)
· 脏读:事务A读取到了事务B尚未提交的数据;
· 不可重复读:事务A多次读取数据,事务B修改数据,事务A读到了事务B修改的数据,导致多次读到的数据不一致;
· 幻读:事务A读取数据后,事务B插入数据并提交,事务A再次读时读取到表中原本不存在的数据。
17.数据库的四种隔离级别:
(重要程度:⭐⭐⭐⭐⭐)
· Read Uncommitted(读取未提交):
- 最低的隔离级别;
- 可能出现脏读、不可重复读、幻读;
· Read Committed(读取提交):
- 避免脏读;
- 但可能出现不可重复读、幻读;
· Repeated Read(可重复读):
- MySQL的默认隔离级别;
-- 查看当前会话的事务隔离级别
select @@transaction_isolation;| 数据 |
| @@transaction_is |
| REPEATABLE-READ |
- 避免脏读和不可重复读;
- 但可能出现幻读;
· Serialization(串行化):
- 最高的隔离级别;
- 避免所有并发问题;
- 但性能最差。
不难发现,隔离级别越高,数据的一致性越好,但并发性能越差。
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
| Read Uncommitted | ✅ | ✅ | ✅ |
| Read Committed | ❌ | ✅ | ✅ |
| Repeatable Read | ❌ | ❌ | ✅ |
| Serialization | ❌ | ❌ | ❌ |
18.为什么选B+树作为数据库索引结构?
(重要程度:⭐⭐⭐⭐)
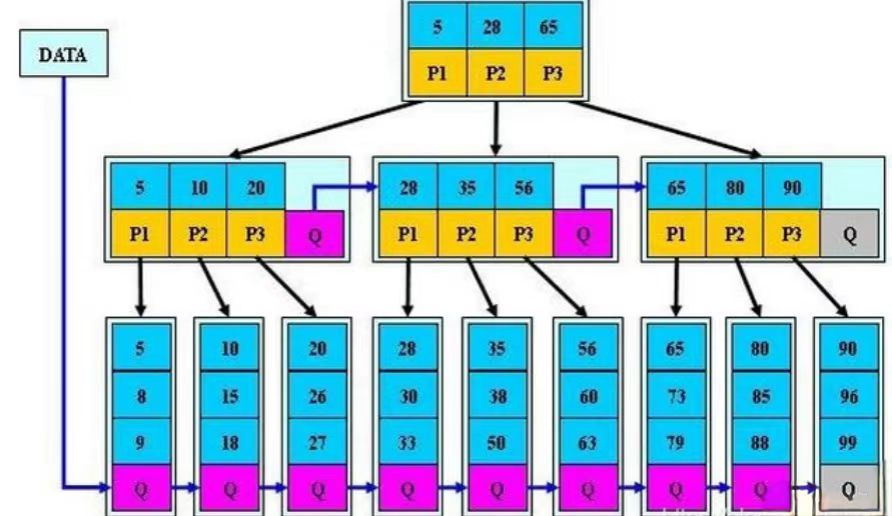
· B+树是多路平衡树,每个节点可存储多个关键字,树的高度极低,能多路性大幅降低磁盘I/O开销;
· B+树所有叶子节点通过双向链表连接,且存储全部数据,可快速获取某一范围的数据,即叶子节点天然支持范围查询;
· B+树的非叶子节点仅存储索引关键字,所有查询的时间复杂度均为O(log n),查询性能稳定且高效。
19.MySQL的五大索引类型:
(重要程度:⭐⭐⭐⭐)
· 主键索引(Primary Key Index):
· 默认自动创建,是表的核心索引,每个表只能有一个主键索引;
· 主键值必须唯一且不能为NULL;
· 在InnoDB存储引擎中,主键索引的叶子节点存储整行数据;
· 确保数据唯一性,快速定位单行数据;
· 唯一索引(Unique Index):
· 索引字段值唯一,允许为NULL,但最多存在一个NULL;
· 一个表可创建多个唯一索引;
· 保证数据唯一性(如用户名、手机号),避免重复数据插入,同时可提升查询性能;
· 普通索引(Normal Index):
· 最基础的索引,无其他约束;
· 提高查询速度;
· 全文索引(Full-Text Index):
· 仅支持CHAR、VARCHAR、TEXT类型字段;
· 用于全文检索(如搜索文章内容、商品描述), 替代低效的Like '%xxx%';
· 组合索引(Composite Index):
· 基于多个字段联合创建的索引(如(name, age)),遵循最左前缀原则;
· 优化多字段联合查询,比单字段索引更高效。
20.数据库中索引这一数据结构的优缺点各有哪些?
(重要程度:⭐⭐⭐⭐)
· 优点:
· 支持快速数据检索,提高了查询速度,降低了数据库IO操作的成本;
· 能快速匹配关联表的数据,降低多表连接的开销;
· 主键索引和唯一索引可防止数据重复插入;
· 缺点:
· 占用额外空间;
· 降低了增删改的性能;
· 增加了数据库系统的维护成本。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)