DataWhale具身智能课程学习——图像分割与深度估计
本文介绍了结合SAM分割模型与DPT深度估计的技术方案,实现3D物体感知。SAM提供高质量实时图像分割,DPT从单张图片估计相对深度,两者结合可同时获取物体轮廓和距离信息。文章详细说明了技术原理:SAM通过编码器-解码器架构实现交互式分割,DPT利用上下文线索推测深度。代码实现展示了完整的处理流程,包括深度图生成和SAM分割可视化。关键创新点在于将分割与深度信息融合,使机器人能同时识别物体及其空间
SAM分割与单目深度估计
参考:DataWhale具身智能课程every-embodied
SAM与DPT是什么
-
技术组合:
◦ Segment Anything Model (SAM):提供高质量、实时的交互式图像分割。
◦ DPT (Dense Prediction Transformer):从单张图片中估计相对深度图。 -
目标与价值:单纯的分割(SAM)提供物体轮廓但无距离信息,单纯的深度图提供距离但物体边界模糊。两者结合可实现3D物体感知,使机器人能同时知道“是什么物体”以及“它有多远”。
-
关键原理:
◦ SAM 由图像编码器、提示编码器和掩码解码器组成,能实现实时交互分割。
◦ 单目深度模型(如DPT)通过学习透视、遮挡等上下文线索来推测深度,其输出通常是逆深度,即值越大(越亮)表示物体越近,值越小(越暗)表示物体越远。 -
应用场景:文档旨在构建一个交互式系统,用户点击图片中的物体,系统即可实时分割出该物体并计算出其平均相对深度。
代码实现交互式分割与深度估计
import torch
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
import os
import time
# --- 模型导入 ---
from transformers import DPTImageProcessor, DPTForDepthEstimation
from segment_anything import sam_model_registry, SamAutomaticMaskGenerator
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"使用设备: {device}")
# --- 辅助函数:显示并保存结果 ---
def save_visualization(image, mask_or_depth, mode="sam", output_name="output.png"):
plt.figure(figsize=(12, 8))
if mode == "depth":
# 并排显示:原图 vs 深度图
plt.subplot(1, 2, 1)
plt.imshow(image)
plt.title("Original Image")
plt.axis('off')
plt.subplot(1, 2, 2)
plt.imshow(mask_or_depth, cmap="inferno")
plt.colorbar(label="Relative Depth")
plt.title("Depth Estimation")
plt.axis('off')
elif mode == "sam":
# 叠加显示 SAM Mask
plt.imshow(image)
ax = plt.gca()
ax.set_autoscale_on(False)
# 将 Mask 按面积排序,大的在下,小的在上
sorted_anns = sorted(mask_or_depth, key=(lambda x: x['area']), reverse=True)
img_overlay = np.ones((sorted_anns[0]['segmentation'].shape[0], sorted_anns[0]['segmentation'].shape[1], 4))
img_overlay[:,:,3] = 0 # 透明度初始化
for ann in sorted_anns:
m = ann['segmentation']
color_mask = np.concatenate([np.random.random(3), [0.4]]) # 随机颜色 + 0.4 透明度
img_overlay[m] = color_mask
ax.imshow(img_overlay)
plt.title("SAM Segmentation")
plt.axis('off')
plt.savefig(output_name, bbox_inches='tight')
plt.close()
print(f"结果已保存至: {output_name}")
# --- 主流程 ---
def main():
# 1. 路径设置
rgb_path = "image_d61af3.jpg" # 此处替换为实际图片
sam_ckpt = "sam_vit_h_4b8939.pth"
if not os.path.exists(rgb_path):
print(f"错误: 找不到图片 {rgb_path}")
return
# 加载图片
image_pil = Image.open(rgb_path).convert("RGB")
image_np = np.array(image_pil)
# ---------------------------------------------------------
# 任务 1: 深度估计 (Depth Estimation)
# ---------------------------------------------------------
print("\n--- [1/2] 正在运行深度估计 ---")
try:
depth_processor = DPTImageProcessor.from_pretrained("Intel/dpt-large")
depth_model = DPTForDepthEstimation.from_pretrained("Intel/dpt-large").to(device)
inputs = depth_processor(images=image_pil, return_tensors="pt").to(device)
with torch.no_grad():
outputs = depth_model(**inputs)
predicted_depth = outputs.predicted_depth
# 插值还原尺寸
prediction = torch.nn.functional.interpolate(
predicted_depth.unsqueeze(1),
size=image_pil.size[::-1],
mode="bicubic",
align_corners=False,
).squeeze().cpu().numpy()
# 保存深度图结果
save_visualization(image_np, prediction, mode="depth", output_name="result_01_depth.png")
except Exception as e:
print(f"深度估计失败: {e}")
# ---------------------------------------------------------
# 任务 2: SAM 全图分割 (Segment Anything)
# ---------------------------------------------------------
print("\n--- [2/2] 正在运行 SAM 分割 ---")
if os.path.exists(sam_ckpt):
try:
sam = sam_model_registry["vit_h"](checkpoint=sam_ckpt).to(device)
mask_generator = SamAutomaticMaskGenerator(sam)
masks = mask_generator.generate(image_np)
# 保存 SAM 结果 (注意文件名不同,避免覆盖)
save_visualization(image_np, masks, mode="sam", output_name="result_02_sam_seg.png")
except Exception as e:
print(f"SAM 分割失败: {e}")
else:
print(f"跳过 SAM: 未找到权重文件 {sam_ckpt}")
if __name__ == "__main__":
main()


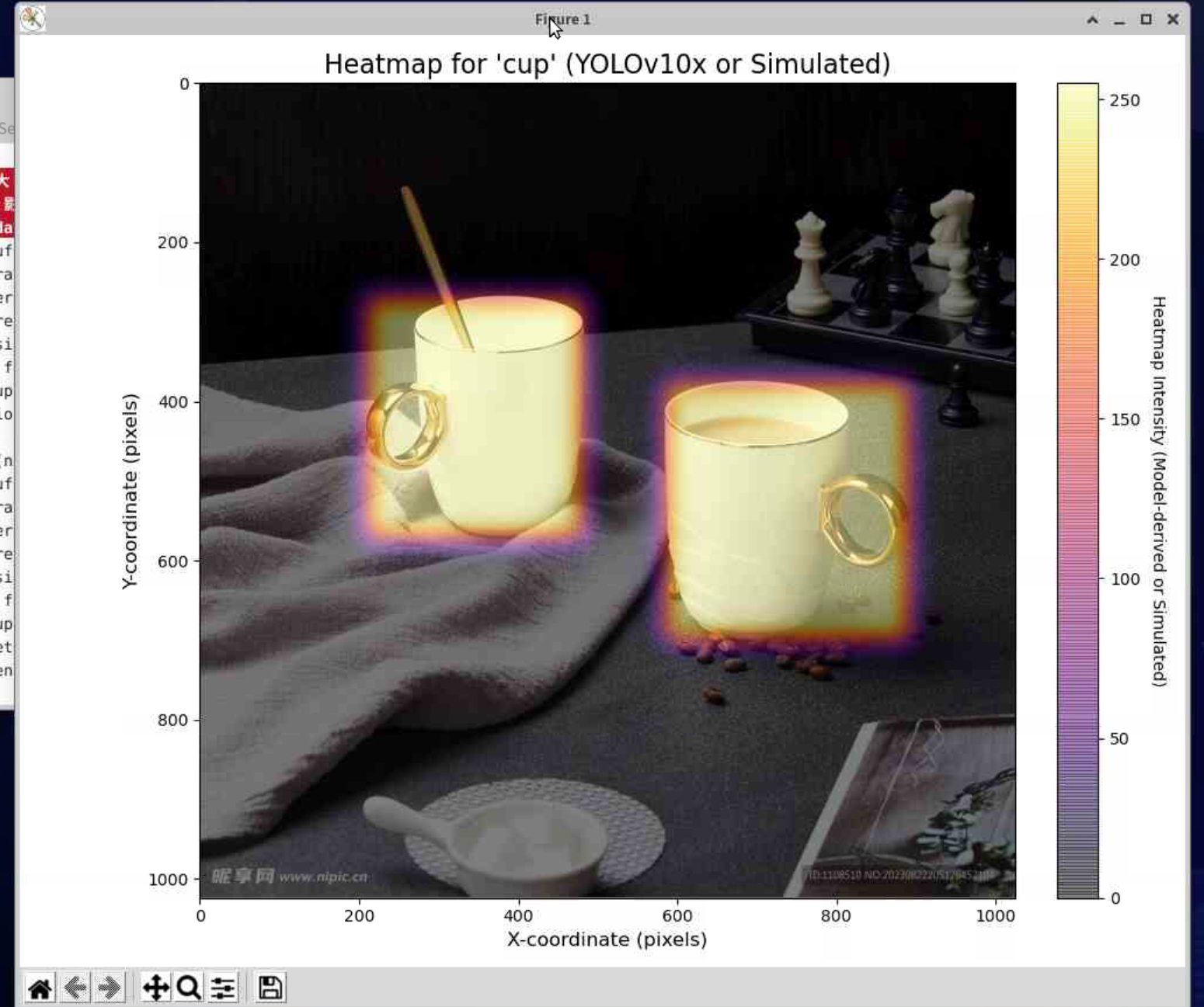
注意力热图
核心知识要点
-
两种“热图”的区分
◦ YOLO生成的“检测置信度热图”:显示模型认为哪些区域可能存在物体及其置信度,是基于模型检测输出的结果可视化。
◦ 学术上的“注意力热图”(如Grad-CAM):揭示模型在做出特定分类决策时,其“注意力”聚焦在输入图像的哪些区域。这是一种模型可解释性(XAI) 技术,用于理解神经网络的内部决策依据。 -
注意力热图(Grad-CAM)的工作原理
其核心思想是通过梯度定位对分类决策最重要的图像区域。简要步骤为:
◦ 正向传播:得到目标类别(如“杯子”)的预测分数。
◦ 梯度计算:计算该预测分数相对于最后一个卷积层特征图的梯度。梯度值大的位置,意味着该处的特征对“判断为杯子”这一决策贡献大。
◦ 加权求和:用梯度信息对特征图进行加权平均,生成一张与原始图像对应的热力图,高亮区域即为模型的“注意力焦点”。 -
YOLOv10的核心创新:NMS-Free
◦ 痛点:传统YOLO依赖非极大值抑制(NMS) 这一后处理步骤来过滤冗余检测框,这会增加延迟且阻碍真正的端到端部署。
◦ 解决方案:YOLOv10提出了一致性双重分配训练策略。
▪ 在训练时,一个分支执行一对一匹配,学习为每个物体只生成一个高质量预测框。
▪ 另一个分支执行传统一对多匹配,提供丰富的监督信号。
▪ 模型被约束使两个分支的输出趋于一致,从而学会了在推理时自主抑制冗余框,无需NMS。
基于YOLOv10的目标检测热力图生成实现代码
import os
from pathlib import Path
import matplotlib.pyplot as plt
import numpy as np
from PIL import Image
import cv2
from ultralytics import YOLO
def generate_and_save_heatmap_for_image(model, img_path, output_dir, target_class_name='cup', conf_threshold=0.25):
"""
对单张图片进行推理,生成检测热力图并保存。
Args:
model: 加载好的YOLO模型。
img_path (str): 输入图片路径。
output_dir (str): 输出目录。
target_class_name (str): 需要生成热力图的目标类别名称。
conf_threshold (float): 检测置信度阈值。
"""
# 1. 加载图片
img_np = cv2.imread(img_path)
if img_np is None:
print(f" 警告: 无法读取图片 {img_path},跳过。")
return
img_np_rgb = cv2.cvtColor(img_np, cv2.COLOR_BGR2RGB)
img_height, img_width = img_np.shape[:2]
# 2. 获取目标类别的ID
class_names = model.names # 模型支持的类别名称字典 {id: name}
target_cls_id = None
for cls_id, name in class_names.items():
if name == target_class_name:
target_cls_id = cls_id
break
if target_cls_id is None:
print(f" 警告: 模型不支持类别 '{target_class_name}',跳过 {img_path}。")
return
# 3. 模型推理
results = model(img_np, verbose=False, conf=conf_threshold)
# 4. 创建空白热力图并填充
heatmap = np.zeros((img_height, img_width), dtype=np.float32)
for result in results:
for box in result.boxes:
cls = int(box.cls)
conf = float(box.conf)
if cls == target_cls_id: # 只处理目标类别
x1, y1, x2, y2 = map(int, box.xyxy[0])
# 用检测框的置信度值填充其区域
cv2.rectangle(heatmap, (x1, y1), (x2, y2), conf, thickness=cv2.FILLED)
# 5. 后处理热力图(高斯模糊使其更平滑)
if heatmap.max() > 0:
# 应用高斯模糊,核大小可根据需要调整,必须是正奇数
kernel_size = (51, 51) if min(img_height, img_width) > 100 else (25, 25)
kernel_size = (kernel_size[0] // 2 * 2 + 1, kernel_size[1] // 2 * 2 + 1) # 确保为奇数
heatmap = cv2.GaussianBlur(heatmap, kernel_size, 0)
# 归一化到 [0, 255] 便于可视化
heatmap = (heatmap / heatmap.max()) * 255
heatmap_uint8 = heatmap.astype(np.uint8)
# 6. 生成并保存可视化结果图
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 6))
# 子图1:原始图片
ax1.imshow(img_np_rgb)
ax1.set_title('Original Image')
ax1.axis('off')
# 子图2:热力图
im = ax2.imshow(heatmap_uint8, cmap='inferno')
ax2.set_title(f'Heatmap for "{target_class_name}"')
ax2.axis('off')
plt.colorbar(im, ax=ax2, fraction=0.046, pad=0.04)
# 保存图片
img_stem = Path(img_path).stem
output_path = os.path.join(output_dir, f"{img_stem}_heatmap.png")
plt.tight_layout()
plt.savefig(output_path, dpi=150, bbox_inches='tight')
plt.close(fig) # 关闭图形以释放内存
print(f" 已保存: {output_path}")
def batch_process_heatmap(image_folder, output_folder, model_weights='yolov10x.pt', target_class='cup'):
"""
批处理主函数:处理一个文件夹中的所有图片。
Args:
image_folder (str): 存放输入图片的文件夹路径。
output_folder (str): 保存输出热力图的文件夹路径。
model_weights (str): YOLO模型权重文件名称或路径。
target_class (str): 感兴趣的目标物体类别。
"""
# 创建输出目录
os.makedirs(output_folder, exist_ok=True)
# 1. 加载模型
print(f"[1/3] 正在加载模型 {model_weights}...")
try:
model = YOLO(model_weights)
except Exception as e:
print(f" 错误: 加载模型失败 - {e}")
print(" 请确保模型文件存在,或它将自动从网上下载。")
return
# 2. 获取图片列表
print(f"[2/3] 正在扫描图片目录 {image_folder}...")
valid_extensions = ('.jpg', '.jpeg', '.png', '.bmp')
image_paths = []
for file in os.listdir(image_folder):
if file.lower().endswith(valid_extensions):
image_paths.append(os.path.join(image_folder, file))
if not image_paths:
print(" 错误: 未在指定文件夹中找到支持的图片文件。")
return
print(f" 找到 {len(image_paths)} 张待处理图片。")
# 3. 批量处理
print(f"[3/3] 开始批处理,目标类别为 '{target_class}'...")
for i, img_path in enumerate(image_paths):
print(f" 处理中 ({i+1}/{len(image_paths)}): {os.path.basename(img_path)}")
generate_and_save_heatmap_for_image(model, img_path, output_folder, target_class)
print("批处理完成!")
# --- 使用示例 ---
if __name__ == "__main__":
# 配置参数
INPUT_IMAGE_DIR = "./input_images" # 你的输入图片文件夹
OUTPUT_RESULT_DIR = "./heatmap_results" # 输出结果文件夹
TARGET_OBJECT = "cup" # 你关心的物体类别
MODEL_TO_USE = "yolov10x.pt" # 可改为 yolov10n/s/m/l/x 等不同规格
# 运行批处理
batch_process_heatmap(INPUT_IMAGE_DIR, OUTPUT_RESULT_DIR, MODEL_TO_USE, TARGET_OBJECT)
代码核心说明:
- 批处理逻辑:核心函数 batch_process_heatmap 会遍历 INPUT_IMAGE_DIR 文件夹下所有图片,自动处理,并将带有热力图的结果保存到 OUTPUT_RESULT_DIR。
- 热力图生成:generate_and_save_heatmap_for_image 函数完成了核心工作:
◦ 加载图片并进行模型推理。
◦ 根据 target_class 筛选特定类别的检测框。
◦ 用检测框的置信度填充生成初始热力图,并通过高斯模糊使其平滑、可视化效果更佳。
◦ 将原始图片与热力图并列显示,并保存为图片。- 模型加载:代码使用 Ultralytics 的 YOLO 接口。指定 MODEL_TO_USE(如 yolov10x.pt),首次运行时会自动下载权重文件。
- 可定制性:您可以轻松修改目标类别(TARGET_OBJECT)、模型大小、置信度阈值等参数以适应不同任务。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)