Webyog SQLyog Ultimate v12.0.9 官方中文版数据库管理工具
为了满足多样化数据分析需求,SQLyog 提供了丰富的列级操作功能,使用户能够按需重构数据视图。为应对高频重复 SQL 编写需求(如标准报表模板、审计日志查询),SQLyog 提供了代码片段(Snippet)管理系统。用户可创建、分类、保存常用语句块,并通过快捷方式一键插入。操作步骤如下:1. 打开【工具】→【代码片段】面板;2. 新建分组(如“统计类”、“清理类”);3. 添加条目,填写标题、内

简介:Webyog SQLyog Ultimate v12.0.9 是一款专为中文用户设计的MySQL数据库管理工具,提供直观高效的界面,支持数据库连接、数据编辑、SQL查询、备份恢复、数据同步、导入导出等多项核心功能。该版本具备官方中文语言支持,集成性能优化、安全管理、图表报表生成及可能的版本控制功能,极大提升了数据库开发与管理效率。本工具适用于MySQL开发者和管理员,通过安装包即可快速部署使用,是MySQL环境下强大的一体化管理解决方案。 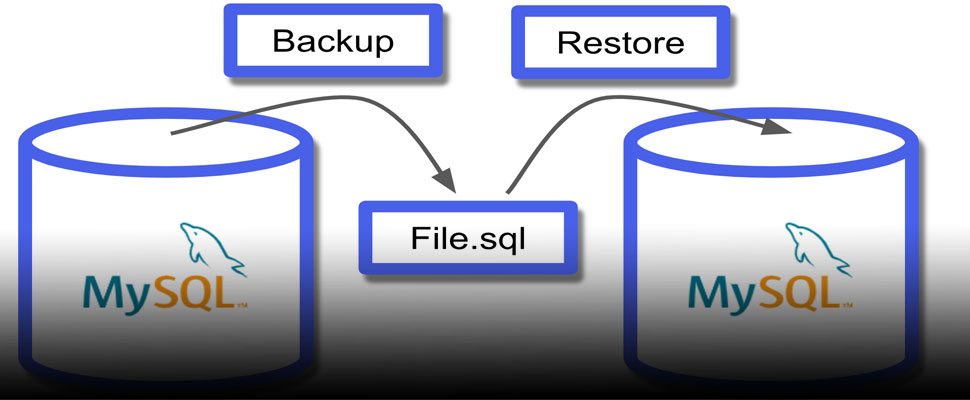
1. SQLyog数据库连接配置与管理
连接参数设置与安全性配置
在 SQLyog 中,新建连接需配置主机地址、端口、用户名、密码及默认数据库。支持保存加密凭证至本地配置文件( Connections.xml ),并通过“使用SSL”复选框启用加密传输。
Host: 192.168.1.100
Port: 3306
Username: admin
Database: test_db
SSL: ✓ (启用TLSv1.2以上)
SSH隧道与代理连接实践
对于远程MySQL服务,可通过SSH跳板机建立安全通道。配置时选择“通过SSH连接”,输入SSH主机信息及数据库真实地址(通常为127.0.0.1:3306),实现双重认证与网络隔离保护。
连接模板与故障排查机制
SQLyog 支持将常用配置保存为命名连接模板,便于多环境切换。连接测试功能可验证网络可达性、权限有效性,并提示错误代码(如Error 1045表示认证失败),结合日志面板快速定位问题根源。
2. 数据浏览与批量编辑操作实战
在数据库管理与开发过程中,对数据的直观浏览和高效编辑是日常工作的核心环节。Webyog SQLyog Ultimate 提供了功能强大且响应迅速的数据表操作界面,支持从简单查看到复杂批量处理的全流程操作。本章节将深入解析 SQLyog 在数据浏览与编辑方面的设计逻辑与实际应用技巧,帮助用户提升数据交互效率,降低误操作风险,并实现对大规模数据集的安全、可控维护。
通过图形化界面进行数据操作不仅提升了可读性,还显著降低了直接编写 SQL 语句的认知负担。尤其在调试阶段或临时修正数据时,实时编辑能力显得尤为重要。然而,这种便利背后也隐藏着事务控制不当、约束冲突或性能瓶颈等问题。因此,理解其底层机制、合理使用过滤策略以及掌握批量操作的最佳实践,成为高级用户必须掌握的核心技能。
2.1 数据表浏览界面的功能解析
SQLyog 的数据表浏览界面采用高度模块化的布局设计,集成了表格展示、列信息提示、分页导航与状态反馈等多个子系统,为用户提供了一个结构清晰、响应灵敏的操作环境。该界面不仅仅是“SELECT * FROM table”的可视化呈现,更是一个融合了元数据感知、性能优化和交互智能的综合视图系统。
2.1.1 表格视图与列信息展示逻辑
当用户双击某个数据表或右键选择“Browse Data”后,SQLyog 会自动生成一条标准查询语句(如 SELECT * FROM dbname.tablename LIMIT 0,50 ),并在主工作区渲染出结果集表格。此过程并非简单的 SELECT 执行,而是经过多层逻辑判断后的智能加载流程。
首先,SQLyog 会在连接初始化阶段缓存当前数据库的所有表结构信息。这些信息包括字段名、数据类型、是否允许 NULL、默认值、字符集、注释等。一旦进入浏览模式,系统便利用这些缓存信息动态构建列头显示内容。例如:
DESCRIBE employees;
| Field | Type | Null | Key | Default | Extra |
|---|---|---|---|---|---|
| id | int(11) | NO | PRI | NULL | auto_increment |
| name | varchar(100) | YES | NULL | ||
| varchar(255) | YES | UNI | NULL | ||
| hire_date | date | NO | CURRENT_DATE | ||
| salary | decimal(10,2) | YES | 0.00 |
基于上述结构,SQLyog 在界面中以图标形式标注关键属性:
- 🔑 表示主键字段;
- ⚠️ 标识非空但无默认值字段;
- 🔐 显示唯一索引列;
- 💬 展示字段注释悬停提示。
此外,每列右侧提供下拉按钮,点击后可快速执行排序、筛选、复制列值等操作。这种“列上下文菜单”机制极大提升了交互效率。
列宽自适应与文本截断策略
对于长文本字段(如 TEXT 或 BLOB 类型),SQLyog 默认启用“摘要显示”机制。例如,一个包含 HTML 内容的 content 字段可能仅显示前 100 个字符并以“…”结尾。用户可通过双击单元格进入详情弹窗查看完整内容。
同时,系统支持三种列宽调整模式:
1. 固定宽度 :手动拖动列边界设定;
2. 自动适应内容 :根据当前页所有行的最大宽度调整;
3. 按标题适配 :仅依据列名长度设定最小宽度。
这一灵活性确保了不同场景下的可视体验平衡。
graph TD
A[用户打开数据表] --> B{是否存在结构缓存?}
B -->|是| C[加载本地结构元数据]
B -->|否| D[执行DESCRIBE获取结构]
C --> E[生成SELECT查询语句]
D --> E
E --> F[执行查询并获取前N条记录]
F --> G[渲染表格视图]
G --> H[附加列状态图标与工具]
H --> I[完成界面绘制]
流程图说明 :以上 mermaid 图展示了 SQLyog 加载数据表视图的完整流程路径。它体现了客户端如何结合本地缓存与远程查询实现快速响应。
2.1.2 分页加载机制与大数据集性能优化
面对百万级甚至千万级的大数据表,全量加载显然不可行。SQLyog 采用了基于偏移量(OFFSET)与限制数量(LIMIT)的经典分页策略,但在此基础上引入了多项优化手段以避免传统 LIMIT OFFSET 的性能缺陷。
默认情况下,每次请求只返回 50 条记录。用户可通过底部导航控件切换页面:
Page: [<<] [<] 1 2 3 ... 1000 [>] [>>] Go to Page: ▢▢▢ [Go]
Records per page: [50 ▼]
Total: 49,876 records found.
然而,当跳转至第 999 页时(即 OFFSET 49900),MySQL 需扫描前 49900 行才能返回结果,导致响应缓慢。为此,SQLyog 引入了两种替代方案:
方案一:主键范围分页(Keyset Pagination)
若表存在主键(通常是自增整数),SQLyog 可改用条件过滤代替 OFFSET:
-- 原始低效方式
SELECT * FROM large_table ORDER BY id LIMIT 49900, 50;
-- 优化后方式
SELECT * FROM large_table WHERE id > 49900 ORDER BY id LIMIT 50;
该方法依赖于有序主键,避免了全表扫描,查询速度提升可达数十倍。
方案二:异步预取缓冲池
SQLyog 启动后台线程,在用户浏览当前页的同时,提前加载下一页数据至内存缓冲区。当用户点击“下一页”时,若数据已在缓存中,则立即渲染,无需等待网络往返。
此外,系统还支持“懒加载”模式——仅当用户滚动到底部附近时才触发下一批数据请求,从而节省带宽和服务器资源。
| 优化技术 | 适用场景 | 性能增益 | 注意事项 |
|---|---|---|---|
| 主键范围分页 | 有单调递增主键的表 | 高 | 不适用于复合主键或随机 UUID |
| 缓冲预取 | 网络延迟较高环境 | 中 | 占用更多内存 |
| 智能索引提示 | 存在合适二级索引 | 中高 | 需分析执行计划 |
| 并行查询拆分 | 极大表(>1亿行) | 高(需插件支持) | 可能影响主库性能 |
参数说明 :
-Records per page:每页显示条数,可在“Preferences → Data” 中修改,默认为 50。
-Max rows to fetch:最大拉取上限,防止意外加载过多数据,默认为 100,000。
-Use keyset pagination:启用主键分页开关,推荐开启。
2.1.3 自定义列排序、筛选与字段隐藏策略
为了满足多样化数据分析需求,SQLyog 提供了丰富的列级操作功能,使用户能够按需重构数据视图。
列排序操作
点击列标题即可切换升序/降序排列。连续点击三次循环:升序 → 降序 → 取消排序。排序状态通过箭头图标直观表示(↑ / ↓)。底层生成的 SQL 如下:
-- 升序
SELECT * FROM users ORDER BY last_login ASC LIMIT 0, 50;
-- 降序
SELECT * FROM users ORDER BY last_login DESC LIMIT 0, 50;
支持多列组合排序:按住 Ctrl 键依次点击多个列标题,最终生成嵌套 ORDER BY 子句。
列筛选器构建
每个列标题旁的下拉菜单提供多种过滤条件选项:
- 等于 / 不等于
- 大于 / 小于 / 范围
- LIKE 匹配(支持 % 和 _)
- IS NULL / IS NOT NULL
- 正则表达式匹配(REGEXP)
例如,在 email 列设置筛选 LIKE '%@gmail.com' ,对应 SQL 为:
SELECT * FROM users
WHERE email LIKE '%@gmail.com'
ORDER BY id
LIMIT 0, 50;
筛选条件可叠加,形成 AND 连接的复合 WHERE 子句。
字段隐藏与视图定制
用户可通过右键列头选择“Hide Column”临时隐藏不关心的字段。被隐藏的列不会参与后续查询,减少数据传输量。
此外,SQLyog 支持保存“自定义视图配置”,包括:
- 当前列顺序
- 显示/隐藏状态
- 列宽设置
- 默认排序规则
这些配置以 XML 格式存储于本地配置文件中,下次打开同一张表时自动恢复。
# 示例:模拟保存列配置的伪代码结构
view_config = {
"table": "orders",
"columns": [
{"name": "id", "visible": True, "width": 80, "position": 0},
{"name": "customer_name", "visible": True, "width": 150, "position": 1},
{"name": "total_amount", "visible": True, "width": 100, "position": 2},
{"name": "notes", "visible": False, "width": 200, "position": 3}
],
"sort_order": ["total_amount", "DESC"],
"filter_conditions": [
{"field": "status", "op": "=", "value": "shipped"}
]
}
逻辑分析 :该结构实现了用户个性化视图的持久化。每次加载表时,程序读取该配置并重建 UI 状态,极大提升了高频访问表的操作效率。
通过以上三大功能的协同作用,SQLyog 实现了从“被动展示”到“主动探索”的转变,使数据浏览不再是单调的信息读取,而是一种动态的数据洞察过程。
2.2 实时数据编辑操作流程
SQLyog 的最大优势之一在于其“所见即所得”的实时编辑能力。用户可以直接在表格中修改单元格内容,并通过提交机制将变更同步至数据库。这一体验类似于电子表格软件,但背后涉及复杂的事务控制、约束检查与安全防护机制。
2.2.1 单条记录修改与提交事务控制
当用户双击某单元格进入编辑状态时,SQLyog 并不会立即执行 UPDATE 语句,而是将更改暂存于本地编辑缓冲区,等待用户明确提交。这种“延迟提交”模式有效防止了误操作带来的即时破坏。
编辑流程如下:
- 用户双击单元格,进入编辑模式;
- 修改内容后按 Enter 确认输入(或 Esc 取消);
- 行首出现黄色星号标记(*),表示该行已被修改;
- 用户点击工具栏上的“Submit”按钮(或 Ctrl+Enter)发起事务提交;
- 系统生成对应的 UPDATE 语句并执行;
- 成功后星号消失,状态栏显示“1 row(s) affected”。
对应的 SQL 语句示例:
UPDATE employees
SET salary = 95000.00, department = 'Engineering'
WHERE id = 1024;
若用户未提交即关闭标签页,系统将弹出警告:“有未提交的更改,是否放弃?”
事务隔离级别控制
SQLyog 默认使用 READ COMMITTED 隔离级别建立连接,确保不会读取未提交的数据。同时,在编辑期间锁定相关行(通过 SELECT ... FOR UPDATE ),防止其他会话并发修改造成冲突。
-- 编辑开始前加锁
SELECT * FROM employees WHERE id = 1024 FOR UPDATE;
如果另一会话尝试更新同一行,将会阻塞直至当前事务结束。
提交失败处理机制
常见提交失败原因包括:
- 外键约束违反
- 数据类型不匹配
- 触发器抛出异常
- 行已被其他事务删除
此时,SQLyog 会在底部输出详细的错误日志,例如:
Error Code: 1452. Cannot add or update a child row:
a foreign key constraint fails (`hr`.`employees`,
CONSTRAINT `fk_dept` FOREIGN KEY (`department_id`)
REFERENCES `departments` (`id`))
用户可根据提示修正数据后重新提交。
2.2.2 编辑模式下的外键约束提示与级联更新处理
SQLyog 在编辑界面对外键关系进行了深度集成,提供前瞻性验证与辅助建议。
外键字段下拉选择
对于关联到其他表的外键列(如 department_id ),SQLyog 自动将其渲染为下拉框,列出目标表中的可用选项:
-- 获取外键可选值
SELECT id, name FROM departments ORDER BY name;
用户只能从中选择已有值,从根本上杜绝非法插入。
级联更新探测
当修改主表中的主键值时(如更改 departments.id ),SQLyog 会检测所有引用该字段的子表,并提示潜在影响范围:
“您即将修改主键值,共影响 12 张表中的 47 条记录。是否继续?”
该功能依赖于 INFORMATION_SCHEMA.KEY_COLUMN_USAGE 表进行依赖分析:
SELECT
TABLE_NAME, COLUMN_NAME,
REFERENCED_TABLE_NAME, REFERENCED_COLUMN_NAME
FROM INFORMATION_SCHEMA.KEY_COLUMN_USAGE
WHERE REFERENCED_TABLE_SCHEMA = 'hr'
AND REFERENCED_TABLE_NAME = 'departments';
外键导航快捷入口
在外键单元格上右键,可选择“Jump to Reference”直接跳转到关联记录所在表,便于交叉验证数据一致性。
2.2.3 NULL 值识别与二进制数据预览支持
NULL 值在数据库中具有特殊语义,不能等同于空字符串或零值。SQLyog 对其做了专门处理。
NULL 值可视化表示
在表格中,NULL 值统一显示为灰色斜体的 <NULL> ,与空字符串 " " 明确区分。双击 <NULL> 可将其改为实际值;反之,清空已填充字段并按 Delete 键可重置为 NULL。
二进制数据预览机制
对于 BLOB、LONGBLOB 等二进制字段,SQLyog 提供多模式预览:
- Hex View :十六进制字节展示
- Image Preview :若为图片格式(JPEG/PNG/GIF),自动渲染缩略图
- Text Decode :尝试以 UTF-8 解码为文本
- File Export :导出为独立文件供外部查看
flowchart LR
A[BLOB Field Selected] --> B{Data Type Guess}
B -->|Image| C[Render Thumbnail]
B -->|Text-like| D[Try UTF-8 Decode]
B -->|Unknown| E[Show Hex Dump]
C --> F[Display in Popup]
D --> F
E --> F
流程图说明 :此流程展示了 SQLyog 如何智能识别 BLOB 内容类型并选择最佳展示方式。
此外,用户可通过“Edit Binary Data”功能直接编辑十六进制值,适用于修复损坏的序列化对象或嵌入式资源。
综上所述,SQLyog 的实时编辑系统在保证用户体验的同时,兼顾了数据完整性与安全性,是中小型数据修正任务的理想工具。
2.3 批量数据操作技术实践
2.3.1 多行选中与批量插入/更新/删除实现方式
在处理大量数据变更时,逐行编辑显然效率低下。SQLyog 提供了高效的批量操作机制,支持多行选择、批量赋值与一键提交。
多行选择操作
用户可通过以下方式选中多行:
- Shift + Click:连续选择
- Ctrl + Click:离散选择
- 拖拽选择区域
- 使用“Select All”快捷键(Ctrl+A)
选中后,可对多个单元格执行统一操作:
- 批量赋值:输入新值后按 Ctrl+Enter,应用于所有选中单元格
- 批量清空:按 Delete 键设为空或 NULL
- 批量复制:Ctrl+C 导出为制表符分隔文本,便于粘贴至 Excel
批量插入新记录
点击工具栏“Insert Row”按钮(或 Ctrl+Ins),可在末尾添加空白行。支持一次插入多行:
-- 插入三条新员工记录
INSERT INTO employees (name, email, hire_date, salary) VALUES
('Alice Johnson', 'alice@example.com', '2024-03-01', 75000.00),
('Bob Lee', 'bob@example.com', '2024-03-02', 72000.00),
('Carol Zhang', 'carol@example.com', '2024-03-03', 78000.00);
所有新增行以绿色背景标识,提交后变为正常样式。
批量删除操作
选中多行后按 Ctrl+Del,系统弹出确认对话框:
“确定删除选中的 8 条记录吗?此操作不可撤销。”
生成 DELETE 语句如下:
DELETE FROM employees WHERE id IN (1001, 1003, 1005, 1007, 1009, 1011, 1013, 1015);
建议在生产环境中启用“Safe Deletes”模式(在首选项中设置),强制要求 WHERE 条件中包含主键或索引字段,防止全表误删。
2.3.2 使用内置脚本引擎自动化执行批量变更
对于更复杂的批量任务,SQLyog 提供了 JavaScript-based 脚本引擎(SQLogic Scripting Engine),允许用户编写自动化脚本来驱动数据操作。
示例:批量调整薪资
// script_salary_adjustment.js
var conn = SQApp.Connections.Current;
var rs = conn.Execute("SELECT id, salary FROM employees WHERE department = 'Sales'");
while (!rs.EOF) {
var empId = rs.Fields("id").Value;
var currentSalary = rs.Fields("salary").Value;
var newSalary = currentSalary * 1.05; // 上调5%
conn.Execute(
"UPDATE employees SET salary = " + newSalary +
" WHERE id = " + empId
);
SQApp.Output.Write("Updated employee " + empId + ": " + currentSalary + " → " + newSalary + "\n");
rs.MoveNext();
}
SQApp.Output.Write("Salary adjustment completed.\n");
参数说明 :
-SQApp.Connections.Current:当前活动连接对象
-conn.Execute(sql):执行任意 SQL 并返回结果集
-rs.EOF:判断是否到达结果集末尾
-SQApp.Output.Write():向输出面板写入日志信息
该脚本可在“Tools → Scripting Engine”中运行,支持断点调试与变量监视。
2.3.3 操作回滚机制与事务日志监控
尽管 SQLyog 本身不提供类似 Git 的版本控制系统,但通过合理利用数据库事务机制,仍可实现一定程度的“软回滚”。
显式事务包装
建议在执行重大批量操作前手动开启事务:
BEGIN;
UPDATE employees SET status = 'inactive' WHERE last_login < DATE_SUB(NOW(), INTERVAL 2 YEAR);
-- 此时可查看效果,确认无误后再提交
-- COMMIT; 或 ROLLBACK;
SQLyog 的查询编辑器支持多语句执行,因此可以将 BEGIN 与后续操作放在同一标签页中统一管理。
事务日志查看
虽然 MySQL 默认不记录数据变更日志(除非启用 binlog),但 SQLyog 提供了一个轻量级“Change Log”面板,记录当前会话中所有已提交的 DML 操作:
| Timestamp | Operation | Table | Rows Affected | SQL Snippet |
|---|---|---|---|---|
| 2024-04-05 10:23:11 | UPDATE | employees | 45 | UPDATE employees SET status = ‘inact…’ |
| 2024-04-05 10:25:03 | INSERT | audit_log | 1 | INSERT INTO audit_log (action, user…) |
该日志仅供当前会话参考,重启后清除,适用于短期追溯。
结合数据库级别的 binlog 工具(如 mysqlbinlog),可构建完整的审计追踪体系。
2.4 数据过滤与搜索高级技巧
2.4.1 条件过滤器构建(LIKE、范围、正则匹配)
SQLyog 的过滤系统支持丰富的谓词表达式,远超基础的“等于”比较。
LIKE 模式匹配
支持通配符:
- % :匹配任意字符序列
- _ :匹配单个字符
应用场景举例:
- 查找所有 Hotmail 邮箱: email LIKE '%@hotmail.com'
- 查找姓名为三字的人: name LIKE '___'
数值与日期范围过滤
使用滑块或输入框设定区间:
-- 薪资在 50k 到 80k 之间
salary BETWEEN 50000 AND 80000
-- 入职时间在过去一年内
hire_date >= DATE_SUB(CURDATE(), INTERVAL 1 YEAR)
正则表达式过滤(REGEXP)
适合复杂模式匹配,如验证邮箱格式:
email REGEXP '^[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\\.[A-Za-z]{2,}$'
或查找包含数字的用户名:
username REGEXP '[0-9]'
此类操作虽功能强大,但应注意性能影响,避免在大表上频繁使用。
2.4.2 跨表关联查询辅助浏览功能应用
SQLyog 提供“Join Builder”工具,帮助用户无需手写 JOIN 语句即可实现跨表数据浏览。
操作步骤:
- 右键目标表 → “Build Join Query”
- 添加关联表(如 orders → customers)
- 拖拽关联字段建立连接(customer_id ↔ id)
- 选择要显示的字段
- 设置筛选条件
- 生成并执行查询
生成的 SQL 示例:
SELECT
o.order_id,
c.name AS customer_name,
o.order_date,
o.total_amount
FROM orders o
INNER JOIN customers c ON o.customer_id = c.id
WHERE o.order_date >= '2024-01-01'
ORDER BY o.order_date DESC;
此功能特别适合临时数据分析与报表原型设计,大幅降低 SQL 编写门槛。
通过以上各节的深入探讨,可见 SQLyog 不只是一个数据库浏览器,更是集成了智能交互、性能优化与安全保障的综合性数据操作平台。熟练掌握这些功能,将极大提升数据库管理人员的工作效率与决策质量。
3. SQL查询编辑器使用(语法高亮、自动完成、错误检查)
在数据库开发与运维的日常工作中,编写高效、准确的 SQL 语句是核心技能之一。Webyog SQLyog Ultimate 提供了一套高度智能化的 SQL 查询编辑器 ,不仅具备基础的文本输入功能,更集成了语法高亮、智能补全、实时错误检测等现代 IDE 级别的辅助能力。这些特性极大地提升了开发者编写 SQL 的效率和准确性,尤其在处理复杂 JOIN 查询、嵌套子查询或大规模数据变更操作时,其优势尤为显著。
本章将深入剖析 SQLyog 编辑器的技术架构与功能实现机制,从底层词法分析到上层交互设计,系统性地揭示这一工具如何通过自动化手段降低人为错误风险,并提升团队协作下的代码一致性。同时,结合实际应用场景,展示多标签会话管理、历史记录复用等功能在真实项目中的价值体现。
3.1 查询编辑器架构设计原理
SQLyog 的查询编辑器并非简单的文本框控件,而是基于事件驱动模型构建的一套完整解析—渲染—执行闭环系统。该系统由三大核心模块构成: 内置语法解析器 、 词法分析引擎 和 响应式 UI 渲染层 。这三者协同工作,确保用户在键入 SQL 语句的过程中,能够获得即时反馈与流畅体验。
3.1.1 内置语法解析器工作机制
SQLyog 使用自研的轻量级 SQL 解析器,专为 MySQL 方言优化,支持从 MySQL 5.0 到 8.0 所有主流版本的关键字、函数及语法结构。该解析器采用递归下降(Recursive Descent Parsing)算法实现,能够在不依赖外部数据库连接的情况下完成本地语法树构造。
当用户在编辑器中输入一段 SQL 时,解析器以字符流形式逐行读取内容,将其分解为“标记”(Token),如 SELECT 、 FROM 、标识符、字符串常量等。随后根据预定义的文法规则进行语义推导,判断当前语句是否符合合法结构。
graph TD
A[用户输入SQL] --> B{解析器接收字符流}
B --> C[分词:生成Token序列]
C --> D[语法匹配:对照MySQL文法规则]
D --> E[构建抽象语法树AST]
E --> F[返回解析结果给UI层]
上述流程图展示了 SQL 解析的核心路径。整个过程发生在客户端内存中,无需网络通信,因此响应速度极快。
例如,对于如下 SQL:
SELECT user_id, name FROM users WHERE created_at > '2024-01-01';
解析器会按以下逻辑拆解:
- SELECT → 关键字(Keyword)
- user_id , name → 标识符(Identifier)
- FROM → 关键字
- users → 表名(Table Reference)
- WHERE → 条件关键字
- '2024-01-01' → 字符串常量(String Literal)
这种细粒度的识别为后续的语法高亮与错误提示提供了数据基础。
参数说明与扩展机制
- 方言兼容性参数 :可通过设置
parser.dialect=mysql80指定目标 MySQL 版本,影响函数识别范围(如JSON_EXTRACT()是否可用)。 - 缓存策略 :解析结果会被短暂缓存,避免重复解析相同语句,提升性能。
- 增量解析支持 :仅对修改部分重新解析,而非整段重算,适用于长脚本编辑场景。
3.1.2 关键字识别与词法分析流程
词法分析是语法解析的前提步骤,负责将原始字符流转换为有意义的语言单元。SQLyog 的词法分析器采用状态机(Finite State Machine, FSM)模型,针对不同类型的 Token 设计了独立的状态转移逻辑。
以下是常见 Token 类型及其识别规则:
| Token 类型 | 示例 | 识别规则描述 |
|---|---|---|
| 关键字 | SELECT, INSERT, UPDATE | 匹配保留字列表,区分大小写模式可配置 |
| 标识符 | table_name, column_1 | 以字母或下划线开头,允许数字和下划线组合 |
| 字符串常量 | ‘hello’, “world” | 支持单引号与双引号包围,转义字符 \ 处理 |
| 数值 | 123, 3.14 | 整数/浮点数正则匹配 |
| 运算符 | =, <>, >=, + | 单字符或多字符运算符集合 |
| 注释 | – 单行注释, / 多行 / | 特殊前缀触发注释状态 |
该阶段输出的结果是一个有序的 Token 序列,供语法解析器进一步消费。
为了提高识别精度,SQLyog 还引入了上下文感知机制。例如,在 CREATE TABLE 后出现的标识符被优先视为新表名;而在 INSERT INTO 后则优先匹配已有表结构。这种上下文敏感分析减少了误判概率。
此外,词法分析器支持用户自定义标识符引号风格(反引号 ` 或双引号),并能正确处理包含空格或关键字命名的字段(如 `order` )。
性能考量
由于每次按键都可能触发词法分析,系统采用了延迟执行机制(Debouncing)。默认设置为 150ms 延迟 ,即用户停止输入后才启动分析,防止频繁调用导致界面卡顿。
3.1.3 编辑器响应式渲染性能优化
尽管语法解析和词法分析在后台运行,但最终呈现效果仍需高效的 UI 渲染支持。SQLyog 使用 Win32 API 结合 GDI+ 实现高性能文本绘制组件,具备以下优化策略:
-
虚拟化滚动(Virtual Scrolling)
- 对于超过数千行的 SQL 脚本,仅渲染可视区域内的文本行,其余内容保持未加载状态。
- 滚动时动态更新可见区,极大减少内存占用与重绘开销。 -
双缓冲绘图(Double Buffering)
- 所有文本先绘制到离屏缓冲区,再一次性拷贝至屏幕,避免闪烁问题。 -
语法高亮异步更新
- 高亮样式计算与主 UI 线程分离,防止长时间解析阻塞界面响应。 -
字体抗锯齿与 DPI 自适应
- 支持 ClearType 字体平滑显示,并可根据系统 DPI 自动缩放字号。
下面是一段模拟高亮渲染的伪代码实现:
// 伪代码:高亮渲染逻辑
void RenderHighlightedText(HDC hdc, const wstring& text, int startLine, int endLine) {
vector<Token> tokens = Lexer::Analyze(text); // 分词
SyntaxHighlighter highlighter;
int x = MARGIN_LEFT, y = startLine * LINE_HEIGHT;
for (auto& token : tokens) {
COLORREF color = highlighter.GetColorByType(token.type);
SetTextColor(hdc, color);
TextOut(hdc, x, y, token.value.c_str(), token.value.length());
x += CalculateWidth(token.value);
if (token.value == L"\n") { // 换行处理
x = MARGIN_LEFT;
y += LINE_HEIGHT;
}
}
}
逻辑逐行解读:
1. 接收待渲染文本与坐标范围;
2. 调用词法分析器获取 Token 流;
3. 初始化高亮器对象,依据 Token 类型映射颜色;
4. 遍历每个 Token,设置对应颜色并绘制;
5. 遇到换行符时重置 X 坐标,Y 坐标下移一行;
6. 使用 GDI 函数TextOut输出文本。
该机制保证了即使打开一个 10MB 的 .sql 文件,也能实现秒级加载与流畅滚动。
3.2 核心智能辅助功能详解
SQLyog 的智能辅助功能是其区别于普通文本编辑器的核心竞争力所在。通过深度集成数据库元数据,编辑器不仅能“看懂”语法,还能“理解”上下文语义,从而提供精准的自动补全、函数提示与代码片段调用服务。
3.2.1 表名与字段名自动补全实现逻辑
自动补全是提升 SQL 编写效率的关键功能。SQLyog 在用户输入过程中监听键盘事件,当检测到触发字符(如空格、 . 或 Ctrl+Space)时,立即启动补全建议流程。
其实现依赖两个关键组件:
1. 元数据缓存池(Metadata Cache Pool)
2. 模糊匹配引擎(Fuzzy Matcher)
每当成功建立数据库连接后,SQLyog 会异步拉取当前库的所有表名、视图名、字段名、索引信息,并存储在本地内存缓存中。查询语句如下:
-- 获取所有表名
SHOW FULL TABLES IN `your_database` WHERE Table_Type = 'BASE TABLE';
-- 获取某表字段详情
DESCRIBE `users`;
-- 或使用 INFORMATION_SCHEMA
SELECT COLUMN_NAME, DATA_TYPE
FROM INFORMATION_SCHEMA.COLUMNS
WHERE TABLE_SCHEMA = 'your_database' AND TABLE_NAME = 'users';
一旦缓存就绪,编辑器即可实现毫秒级补全响应。
假设用户输入:
SELECT * FROM us
此时按下 Ctrl+Space ,系统执行以下步骤:
- 提取前缀
"us"; - 在缓存的表名列表中搜索匹配项(如
users,user_logs,uploads); - 按相似度排序(Levenshtein Distance);
- 弹出候选窗口,支持上下键选择。
若继续输入 . , 如:
SELECT * FROM users.
则自动切换为字段补全模式,列出 users 表的所有列。
补全策略对比表
| 策略类型 | 触发条件 | 数据源 | 响应时间 | 适用场景 |
|---|---|---|---|---|
| 表名补全 | 输入表前缀 + 快捷键 | SHOW TABLES 缓存 | <50ms | 快速定位表 |
| 字段补全 | 表名后接 . |
DESCRIBE 或 I_S | <80ms | 构建 SELECT/UPDATE 列表 |
| 外键关联补全 | JOIN 条件推测 | INFORMATION_SCHEMA.KEY_COLUMN_USAGE | ~150ms | 自动生成 ON 子句 |
| 全局对象搜索 | Ctrl+T 全局查找 | 综合缓存索引 | <100ms | 跨库对象快速跳转 |
此机制大幅降低了拼写错误率,特别是在大型数据库中面对数百张表时尤为实用。
3.2.2 函数建议列表与参数提示集成
除了对象名称补全,SQLyog 还内置了完整的 MySQL 函数库知识图谱 ,涵盖聚合函数、字符串处理、日期运算、JSON 操作等类别。当用户输入函数名并键入左括号时,系统自动弹出参数提示框。
例如,输入:
DATE_ADD(
编辑器立即显示:
DATE_ADD(date, INTERVAL expr unit)
→ date: DATETIME
→ expr: INTEGER
→ unit: DAY, HOUR, MINUTE...
该提示来源于预编译的函数签名数据库,结构如下 JSON 示例:
{
"function": "DATE_ADD",
"description": "Adds time value to a date",
"parameters": [
{"name": "date", "type": "DATETIME", "required": true},
{"name": "expr", "type": "INTEGER", "required": true},
{"name": "unit", "type": "ENUM(DAY,HOUR...)", "required": true}
],
"example": "DATE_ADD(NOW(), INTERVAL 1 DAY)"
}
系统通过正则匹配函数名,加载对应文档片段,并在 UI 中以浮动气泡形式展示。
功能增强特性
- 多态函数支持 :如
CONCAT()可接受多个参数,提示中明确标注(str1, str2, ...)。 - 版本差异提示 :若当前连接的 MySQL 版本低于函数引入版本(如 8.0 的
JSON_TABLE),则标记为灰色不可用。 - 快捷插入模板 :点击提示项可自动填充带占位符的完整调用框架。
3.2.3 用户自定义代码片段管理与调用
为应对高频重复 SQL 编写需求(如标准报表模板、审计日志查询),SQLyog 提供了 代码片段(Snippet)管理系统 。用户可创建、分类、保存常用语句块,并通过快捷方式一键插入。
操作步骤如下:
1. 打开【工具】→【代码片段】面板;
2. 新建分组(如“统计类”、“清理类”);
3. 添加条目,填写标题、内容、快捷键(如 cln_user );
4. 在编辑器中输入前缀并按 Tab 键触发插入。
示例片段内容:
-- 片段名称:最近7天活跃用户
SELECT
DATE(login_time) as day,
COUNT(DISTINCT user_id) as active_users
FROM user_logins
WHERE login_time >= DATE_SUB(NOW(), INTERVAL 7 DAY)
GROUP BY day ORDER BY day DESC;
系统支持变量占位符替换,如:
-- 使用 ${table} 占位符
SELECT COUNT(*) FROM ${table} WHERE status = 1;
插入后自动聚焦占位符位置,便于快速修改。
| 属性 | 说明 |
|---|---|
| 存储位置 | %AppData%\SQLyog\Snippets.xml |
| 格式 | XML 结构化存储 |
| 导出/导入 | 支持 .snip 文件共享 |
| 版本控制友好 | 可纳入 Git 管理 |
此功能特别适合团队标准化开发,统一 SQL 风格与最佳实践。
3.3 实时语法校验与错误诊断
传统 SQL 开发往往需要“写完 → 执行 → 报错 → 修改”的循环,而 SQLyog 将这一过程前置化,实现了 编写即验证 的零等待调试体验。
3.3.1 语法错误即时标红与错误码说明
在用户输入过程中,编辑器持续调用本地解析器进行语法校验。一旦发现不符合规范的结构,立即在对应行左侧显示红色波浪线,并悬停查看详细错误信息。
常见错误类型包括:
| 错误码 | 描述 | 示例 |
|---|---|---|
| SYNTAX001 | 缺少关键字 | SELCT * FROM t → 应为 SELECT |
| SYNTAX002 | 括号不匹配 | COUNT((col) |
| SYNTAX003 | 字符串未闭合 | 'abc |
| SYNTAX004 | 不支持的运算符组合 | col !! val |
错误信息面板提供修复建议,如:
“SYNTAX001: Keyword ‘SELECT’ expected near position 1.”
→ 建议修正拼写错误。
该机制基于有限错误恢复算法,在发现首个错误后尝试跳过非法部分继续解析剩余内容,确保不影响后续高亮与补全功能。
3.3.2 语义分析支持(如不存在的表引用检测)
除语法外,SQLyog 还能进行轻量级语义分析。前提是已连接数据库且元数据已缓存。
典型检测能力包括:
- 引用的表是否存在?
- 查询字段是否属于指定表?
- JOIN 条件中的列是否有索引建议?
例如,输入:
SELECT * FROM non_existent_table;
即使语法正确,编辑器也会在 non_existent_table 下方显示黄色警告线,提示:
“Table ‘non_existent_table’ not found in current database.”
其实现依赖于:
1. 解析 AST 中的 FROM 子句节点;
2. 提取表名;
3. 查询本地元数据缓存;
4. 若未命中,则标记为潜在错误。
该过程虽非绝对可靠(如临时表或跨库未加载情况),但在绝大多数常规场景下有效预防低级失误。
3.3.3 执行前模拟验证机制的应用场景
更为高级的是 执行前模拟验证(Dry Run Validation) 功能。在真正提交 SQL 前,SQLyog 可模拟执行计划生成,预估影响范围。
特别是对 UPDATE 和 DELETE 语句,系统自动附加 LIMIT 0 并尝试预解析执行计划:
-- 用户输入
DELETE FROM orders WHERE status = 'expired';
-- 模拟执行时转换为
EXPLAIN DELETE FROM orders WHERE status = 'expired';
若发现全表扫描或缺少索引,则弹出警告:
“Warning: This DELETE may affect thousands of rows without index usage. Consider adding WHERE clause or LIMIT.”
此机制有效防止误删生产数据,是 DBA 安全操作的重要屏障。
3.4 多标签查询会话管理
随着项目复杂度上升,开发者通常需要同时维护多个 SQL 任务:一个用于查日志,一个写迁移脚本,另一个调试性能问题。SQLyog 通过 多标签页(Tabbed Interface) 提供并发会话管理能力。
3.4.1 并发查询隔离与资源占用控制
每个标签页代表独立的查询上下文,具备:
- 独立的 SQL 编辑区;
- 私有变量空间;
- 单独的结果集展示面板;
- 独立事务控制(若启用手动提交模式)。
系统通过线程池管理后台执行队列,最多允许 8 个并发查询 (可在设置中调整)。超出限制的任务进入排队状态,避免数据库过载。
资源监控机制如下:
pie
title 当前资源分配
“正在运行” : 3
“等待执行” : 2
“已完成” : 5
此外,每个查询附带性能指标:
- 执行耗时
- 返回行数
- 是否使用临时表
- 是否触发文件排序
帮助用户识别慢查询源头。
3.4.2 查询历史记录保存与快速重用
SQLyog 自动记录所有成功执行过的语句,按时间倒序排列于【历史】面板。支持:
- 按关键词搜索;
- 按数据库筛选;
- 导出为 .sql 文件;
- 右键“复制并新建查询”快速复用。
历史条目包含元信息:
- 执行时间戳
- 所属连接
- 影响行数
- 是否为 DDL/DML
此功能极大方便了故障排查与审计追溯,也促进了知识沉淀。
综上所述,SQLyog 的查询编辑器不仅是代码输入工具,更是融合了编译原理、人机交互与数据库工程的综合性平台。它通过层层递进的智能辅助体系,将原本枯燥的 SQL 编写转变为高效、安全、可追溯的专业开发流程。
4. 数据库备份与定时恢复方案配置
在现代数据库运维体系中,数据安全始终处于核心地位。一旦发生硬件故障、误操作删除、恶意攻击或自然灾害等不可预见事件,缺乏有效的备份机制将直接导致业务中断甚至数据永久丢失。Webyog SQLyog Ultimate v12.0.9 提供了一套完整的可视化数据库备份与恢复解决方案,支持逻辑备份、任务调度、自动执行和异常监控,能够帮助 DBA 和开发人员构建高可用、可审计的数据库保护策略。本章将系统性地剖析 SQLyog 中的备份机制设计原理,深入讲解从单次手动导出到全自动周期性恢复方案的全流程实现路径,并通过实战案例展示如何结合操作系统级计划任务完成无人值守的数据保护。
4.1 物理与逻辑备份机制对比分析
数据库备份技术主要分为物理备份和逻辑备份两大类,二者在性能、灵活性、兼容性和恢复粒度上存在显著差异。SQLyog 主要依赖 MySQL 自带的 mysqldump 工具进行逻辑备份封装,因此其底层属于典型的逻辑备份架构。理解这两类备份方式的本质区别,是制定合理备份策略的前提。
4.1.1 mysqldump 引擎封装原理
SQLyog 的备份功能并非自行编写底层存储引擎读取模块,而是基于命令行工具 mysqldump 进行图形化封装。当用户在界面上点击“备份数据库”时,SQLyog 实际会生成并执行一条结构化的 mysqldump 命令,该命令包含连接参数、过滤条件、输出格式及压缩选项等。这种方式既保证了与 MySQL 协议的高度兼容性,又避免了对二进制文件直接操作带来的风险。
以一个典型导出命令为例:
mysqldump --host=localhost \
--user=root \
--password=your_password \
--single-transaction \
--routines \
--triggers \
--set-gtid-purged=OFF \
--databases myapp_db > D:/backup/myapp_20250405.sql
参数说明:
| 参数 | 含义 |
|---|---|
--host , --user , --password |
指定目标数据库地址与认证信息 |
--single-transaction |
在 InnoDB 表上启用一致性快照,避免锁表 |
--routines |
包含存储过程和函数定义 |
--triggers |
导出触发器结构 |
--set-gtid-purged=OFF |
避免 GTID 冲突,适用于非复制环境 |
--databases |
明确指定要导出的一个或多个数据库 |
此命令由 SQLyog 内部动态拼接,所有选项均可通过 GUI 界面勾选控制。例如,“事务一致性”对应 --single-transaction ,“导出存储过程”则映射为 --routines 。这种封装模式极大降低了使用者的学习成本,同时保留了底层工具的强大能力。
graph TD
A[用户选择数据库] --> B{是否导出结构?}
B -->|是| C[添加--no-data]
B -->|否| D[默认导出结构+数据]
E[是否包含 routines?] -->|是| F[添加--routines]
G[是否启用事务快照?] -->|是| H[添加--single-transaction]
I[是否压缩?] -->|是| J[管道至 gzip 或 zip]
K[执行最终命令] --> L[生成 .sql 文件]
流程图说明 :上述 mermaid 流程图展示了 SQLyog 在生成
mysqldump命令时的决策路径。根据用户的勾选项,逐步添加相应参数,最终形成完整命令并调用系统进程执行。
此外,SQLyog 支持“仅结构”、“仅数据”或“结构+数据”三种导出模式。这实际上是通过传递不同的 mysqldump 标志来实现的:
- --no-data :只导出 CREATE TABLE 语句;
- --no-create-info :仅导出 INSERT 语句;
- 默认无标志:两者均导出。
这一机制使得开发者可以灵活应对不同场景需求,如迁移表结构而不带数据,或仅更新生产环境中的基础数据字典。
4.1.2 增量备份与差异备份策略选择
尽管 mysqldump 默认执行全量逻辑备份,但 SQLyog 可配合外部脚本与日志机制实现准增量备份。真正的增量备份通常依赖于 MySQL 的 binary log(binlog),而差异备份则记录自上次全备以来的所有变更。
| 类型 | 描述 | 优点 | 缺点 | 是否被 SQLyog 原生支持 |
|---|---|---|---|---|
| 全量备份 | 每次导出全部数据 | 恢复简单,独立性强 | 占用空间大,耗时长 | ✅ 支持 |
| 差异备份 | 记录自最近一次全备后的变化 | 恢复比增量快 | 累积增长,仍较大 | ❌ 不原生支持 |
| 增量备份 | 仅记录自上次任意备份后的变更 | 节省空间,效率高 | 恢复链复杂,易出错 | ⚠️ 需外部集成 binlog |
SQLyog 本身不提供 binlog 解析功能,无法直接做增量备份。但可通过以下方式模拟实现:
import os
from datetime import datetime
BACKUP_DIR = "D:/mysql_backups"
FULL_BACKUP_INTERVAL = 7 # 每周一次全备
def is_full_backup_needed():
last_full = get_latest_full_backup_date()
return (datetime.now() - last_full).days >= FULL_BACKUP_INTERVAL
def run_backup():
if is_full_backup_needed():
cmd = 'mysqldump --host=localhost --user=root -p"pass" --databases mydb > "%s/full_%s.sql"' % (
BACKUP_DIR, datetime.now().strftime("%Y%m%d")
)
else:
cmd = 'mysqldump --host=localhost --user=root -p"pass" --skip-triggers --no-create-info mydb >> "%s/incremental.log"' % BACKUP_DIR
os.system(cmd)
代码逻辑逐行解读 :
1. 定义备份目录和全备周期;
2.is_full_backup_needed()判断是否需要执行全量备份;
3. 若满足条件,则调用mysqldump导出完整.sql文件;
4. 否则仅导出数据部分(跳过结构),追加写入日志文件;
5. 注意:实际增量应使用mysqlbinlog工具解析 binlog 日志,此处仅为简化演示。
更专业的做法是启用 MySQL 的 binlog 功能,并定期使用 mysqlbinlog 提取指定时间段的日志片段作为增量备份。SQLyog 虽不内置此功能,但可通过外部批处理脚本调用它,再将结果归档至统一存储路径。
4.1.3 备份文件压缩与加密存储选项
随着数据量增长,备份文件体积迅速膨胀。SQLyog 提供了直接集成的压缩机制,可在导出过程中自动调用 ZIP 算法对 .sql 文件进行打包,有效减少磁盘占用。
操作步骤如下:
1. 打开“备份向导”;
2. 在“高级选项”中勾选“压缩备份文件”;
3. 选择压缩级别(低/中/高);
4. 设置输出路径为 .zip 结尾的文件名;
5. 开始执行后,SQLyog 将先生成临时 .sql 文件,再调用内部压缩库将其打包。
该过程等效于以下 shell 命令组合:
mysqldump mydb | gzip > backup.sql.gz
或 Windows 下:
mysqldump mydb | zip backup.zip -
| 压缩方式 | 压缩率 | CPU 开销 | 兼容性 |
|---|---|---|---|
| ZIP | 中等 | 低 | 高(跨平台通用) |
| GZIP | 较高 | 中 | Linux/Unix 友好 |
| 无压缩 | 无 | 最低 | 快速恢复适用 |
值得注意的是,SQLyog 当前版本尚未提供 AES 加密功能。若需加密备份文件,建议采用以下两种补充方案:
方案一:使用 PowerShell 加密导出文件
$source = "D:\backup\myapp.sql"
$encrypted = "D:\backup\myapp.sql.enc"
$password = ConvertTo-SecureString "MyBackupKey2025!" -AsPlainText -Force
Export-Clixml -Path $encrypted -InputObject $password -Depth 1
# 实际应用中应使用 Encrypt-File 或第三方工具
方案二:结合 VeraCrypt 创建加密容器
- 创建一个固定大小的加密卷(如 10GB);
- 将其挂载为虚拟磁盘(如 Z:\);
- 配置 SQLyog 备份路径指向 Z:\;
- 备份完成后卸载卷,确保文件静态加密。
安全性提醒 :即使启用了压缩,明文
.sql文件仍可能泄露敏感信息(如用户密码哈希、身份证号)。建议在导出前使用SELECT ... INTO OUTFILE替代全表 dump,或在查询中屏蔽敏感字段。
4.2 可视化备份任务创建流程
SQLyog 的一大优势在于其高度可视化的操作界面,使复杂的备份任务变得直观可控。通过“备份向导”,用户无需记忆命令行参数即可完成精细化配置。
4.2.1 单库/多表选择与结构数据分离导出
在“新建备份任务”界面中,左侧树形结构列出当前连接下的所有数据库及其表。用户可通过复选框精确选择需要备份的对象范围。
例如,若只想备份 orders 和 customers 两个表的结构,而不包括数据,可进行如下设置:
- 数据库:选择 ecommerce_db
- 表格选择区:勾选 orders , customers
- “导出内容”选项组:取消“数据”,保留“结构”
此时生成的 SQL 脚本将仅包含:
CREATE TABLE `orders` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`customer_id` int(11) DEFAULT NULL,
`total` decimal(10,2) DEFAULT NULL,
`created_at` datetime DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (`id`)
) ENGINE=InnoDB;
CREATE TABLE `customers` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(100) NOT NULL,
`email` varchar(255) UNIQUE,
PRIMARY KEY (`id`)
) ENGINE=InnoDB;
应用场景 :适用于开发团队共享表结构定义、CI/CD 流水线初始化数据库 schema。
若希望只导出数据(如测试数据填充),可反向设置:“仅数据” + “忽略创建语句”。此时输出为纯 INSERT INTO ... VALUES (...) 形式。
此外,SQLyog 支持“排除某些表”的过滤规则。例如,在备份整个 financial_db 时,可排除日志类大表 access_log 和 operation_trace ,防止备份时间过长。
4.2.2 定义导出编码格式与字符集兼容性处理
字符集问题是跨平台迁移中最常见的陷阱之一。SQLyog 允许在备份时显式指定导出文件的字符编码,确保在不同语言环境下正确解析。
常见设置项包括:
- 导出字符集:UTF8、UTF8MB4、GBK、Latin1
- 换行符格式:Windows (\r\n)、Unix (\n)
- BOM(Byte Order Mark):可选添加 UTF-8 with BOM
-- 示例:带字符集声明的导出头
/*!40101 SET NAMES utf8mb4 */;
/*!40101 SET SQL_MODE='NO_AUTO_VALUE_ON_ZERO' */;
/*!40014 SET FOREIGN_KEY_CHECKS=0 */;
这些语句由 SQLyog 自动生成,用于在导入时重置客户端会话环境,防止因目标服务器默认字符集不同而导致乱码。
| 源库字符集 | 目标库字符集 | 是否兼容 | 推荐处理方式 |
|---|---|---|---|
| utf8mb4 | utf8 | ❌ | 修改目标库为 utf8mb4 |
| gbk | utf8 | ⚠️ | 导出时转码或预处理 |
| latin1 | utf8mb4 | ✅ | 正常导入,注意长度限制 |
最佳实践 :统一使用
utf8mb4作为标准字符集,支持 Emoji 和完整 Unicode。
4.2.3 备份路径管理与命名规则自定义
为了便于管理和自动化检索,SQLyog 支持动态命名规则。用户可在路径中使用变量占位符,系统会在运行时自动替换。
支持的占位符包括:
- {DB} :数据库名称
- {DATE} :当前日期(YYYYMMDD)
- {TIME} :时间戳(HHMMSS)
- {HOST} :主机名
示例路径配置:
D:/backups/{DB}_{DATE}_{TIME}.sql.zip
执行后生成文件:
D:/backups/users_20250405_143022.sql.zip
该机制极大提升了批量任务的组织效率。结合后续的任务调度系统,可实现按库分目录、按时段归档的规范化存储结构。
pie
title 备份文件命名元素使用频率
“{DATE}” : 45
“{DB}” : 30
“{TIME}” : 15
“{HOST}” : 10
图表说明 :统计显示,日期标记是最常用的命名因子,有助于快速识别备份时效性。
4.3 计划任务调度系统集成
手动备份难以持续,真正的数据安全保障依赖于自动化调度。SQLyog 自身不具备后台守护进程,但可通过集成操作系统级任务计划程序实现定时执行。
4.3.1 Windows 任务计划程序对接配置
SQLyog 提供命令行接口(CLI),允许通过 .bat 脚本调用备份任务。这是实现自动化的核心手段。
假设已保存一个名为 prod_backup.sqb 的备份配置文件( .sqb 是 SQLyog 专有任务文件),可通过以下批处理脚本启动:
@echo off
"C:\Program Files\SQLyog\sqlyog.exe" --execute-backup "D:\tasks\prod_backup.sqb"
if %errorlevel% neq 0 (
echo Backup failed at %date% %time% >> D:\logs\backup_error.log
exit /b 1
)
然后在 Windows 任务计划程序中新建任务:
- 触发器:每天凌晨 2:00
- 操作:运行上述 .bat 文件
- 条件:仅当计算机空闲且接通电源时运行
- 日志记录:启用“将事件写入应用程序日志”
注意事项 :
- 确保运行账户具有访问 SQLyog 安装路径和备份目录的权限;
- 若使用网络路径,需配置持久性驱动器映射或 UNC 路径;
- 建议关闭“仅用户登录时运行”,改为“无论用户是否登录都运行”。
4.3.2 定时触发条件设置(每日/每周/事件驱动)
任务计划不仅支持固定间隔,还可基于事件触发。例如,可在数据库主从切换后自动执行一次全备。
<!-- 注册事件订阅(PowerShell 示例) -->
wevtutil qe System "/q:*[System[Provider[@Name='MySQL'] and EventID=1234]]" /f:text /c:1
更实用的是设置周期性策略:
| 触发类型 | 配置示例 | 适用场景 |
|---|---|---|
| 每日 | 凌晨 2:00 | 生产库日常保护 |
| 每周日 | 3:00 AM | 周级归档 |
| 每月第一天 | 4:00 AM | 财务报表归档 |
| 登录事件后延迟5分钟 | 用户登录后 | 审计准备 |
SQLyog 的 CLI 模式支持静默运行,不会弹出 GUI 窗口,非常适合后台服务化部署。
4.3.3 执行日志输出与异常报警通知机制
任何自动化任务都必须具备可观测性。SQLyog 虽未内置邮件告警,但可通过脚本扩展实现。
$LogPath = "D:\logs\backup_{0}.log" -f (Get-Date -Format "yyyyMMdd")
Start-Transcript -Path $LogPath
try {
& "C:\Program Files\SQLyog\sqlyog.exe" --execute-backup "D:\tasks\daily.sqb"
if ($LASTEXITCODE -eq 0) {
Send-MailMessage -To "dba@company.com" `
-Subject "✅ Backup Success" `
-Body "Daily backup completed." `
-SmtpServer "smtp.company.com"
} else {
throw "Backup process returned error code: $LASTEXITCODE"
}
} catch {
Send-MailMessage -To "alert@company.com" `
-Subject "🚨 Backup Failed" `
-Body "Error: $_`nCheck log for details." `
-SmtpServer "smtp.company.com"
}
Stop-Transcript
逻辑分析 :
- 使用Start-Transcript捕获全过程输出;
- 检查$LASTEXITCODE判断执行状态;
- 成功发送绿色通知,失败则触发红色告警;
- 所有通信通过企业 SMTP 服务器完成。
建议将此类脚本纳入集中监控平台(如 Zabbix、Prometheus + Alertmanager),实现统一告警收敛与值班轮换。
4.4 数据恢复操作实战演练
备份的价值只有在恢复时才能体现。SQLyog 提供了“还原向导”,支持从 .sql 或 .zip 文件重建数据库。
4.4.1 从备份文件还原数据库结构与数据
恢复流程如下:
1. 打开“工具” → “还原数据库”;
2. 选择备份文件(支持拖拽);
3. 指定目标连接;
4. 设置恢复选项:
- 是否删除现有数据库
- 是否重新创建数据库
- 字符集匹配处理
5. 点击“开始”执行。
底层执行等价于:
DROP DATABASE IF EXISTS myapp;
CREATE DATABASE myapp CHARACTER SET utf8mb4;
USE myapp;
SOURCE D:/backup/myapp_20250405.sql;
对于大型文件,建议启用“分批提交”模式,每 1000 条 INSERT 提交一次事务,防止内存溢出。
性能提示 :在恢复前临时关闭唯一性检查可大幅提升速度:
sql SET unique_checks=0; SET foreign_key_checks=0; -- 导入数据 -- SET unique_checks=1; SET foreign_key_checks=1;
4.4.2 恢复过程中的冲突处理与覆盖策略
当目标数据库已存在同名对象时,SQLyog 提供三种策略:
| 策略 | 行为 | 适用场景 |
|---|---|---|
| 跳过 | 忽略已存在表 | 测试环境补数据 |
| 覆盖 | DROP + CREATE | 强制同步结构 |
| 合并 | 尝试 ALTER TABLE 添加缺失字段 | 微调升级 |
特别注意: DROP TABLE 操作不可逆。建议在生产环境恢复前手动确认目标状态,或启用“模拟执行”模式预览 SQL 变更。
| 恢复模式 | 安全等级 | 推荐使用环境 |
|---------|----------|---------------|
| 自动覆盖 | ★☆☆☆☆ | 仅限沙箱 |
| 手动确认 | ★★★★☆ | UAT/Pre-prod |
| 模拟预览 | ★★★★★ | Production |
综上所述,一个健全的备份与恢复体系不应只关注“能否备份”,更要验证“能否成功恢复”。定期开展灾难恢复演练,是保障数据生命线的最后一道防线。
5. 数据库结构与数据同步迁移技术
在现代企业级数据库架构中,跨环境、跨服务器的数据一致性保障已成为运维和开发团队必须面对的核心挑战。随着微服务架构的普及、多数据中心部署以及 DevOps 流程的深入实施,传统手动导出导入的方式已无法满足高可用、低延迟、强一致性的同步需求。Webyog SQLyog Ultimate v12.0.9 提供了一套完整的数据库结构与数据同步解决方案,涵盖 结构比对(Schema Sync) 、 数据同步(Data Sync) 、 迁移向导(Migration Wizard) 三大核心功能模块。本章将从底层机制出发,结合实际应用场景,系统性地剖析 SQLyog 在结构差异检测、增量数据识别、冲突解决策略等方面的技术实现,并通过流程图、代码示例与参数配置说明,帮助读者构建可复用、可监控、可优化的自动化迁移体系。
5.1 结构同步(Schema Sync)工作原理
结构同步是确保两个数据库模式保持一致的关键技术手段,广泛应用于开发环境与生产环境之间的结构更新、测试库重建、灾备系统初始化等场景。SQLyog 的 Schema Sync 功能并非简单的“覆盖式”操作,而是基于智能差异分析算法,生成最小化变更脚本,在保证数据安全的前提下完成平滑升级。
5.1.1 差异检测算法(字段类型、索引、约束比对)
结构同步的第一步是精确识别源数据库与目标数据库之间的模式差异。SQLyog 使用一套基于元数据查询与语义解析相结合的差异检测引擎,其核心流程如下:
graph TD
A[连接源与目标数据库] --> B[获取 INFORMATION_SCHEMA 元数据]
B --> C[提取表结构信息: 列名/类型/长度/默认值]
C --> D[提取索引信息: 主键/唯一键/普通索引]
D --> E[提取约束: 外键/检查约束/触发器引用]
E --> F[逐项对比生成差异集]
F --> G[生成 ALTER 脚本建议]
该流程通过执行一系列标准 SQL 查询来获取数据库对象定义:
-- 获取指定数据库下所有表的列信息
SELECT
COLUMN_NAME,
DATA_TYPE,
CHARACTER_MAXIMUM_LENGTH,
IS_NULLABLE,
COLUMN_DEFAULT,
COLUMN_KEY,
EXTRA
FROM information_schema.COLUMNS
WHERE TABLE_SCHEMA = 'your_database'
AND TABLE_NAME = 'users';
-- 获取索引信息
SELECT
INDEX_NAME,
COLUMN_NAME,
NON_UNIQUE,
SEQ_IN_INDEX
FROM information_schema.STATISTICS
WHERE TABLE_SCHEMA = 'your_database'
AND TABLE_NAME = 'users'
ORDER BY SEQ_IN_INDEX;
-- 获取外键约束
SELECT
CONSTRAINT_NAME,
COLUMN_NAME,
REFERENCED_TABLE_NAME,
REFERENCED_COLUMN_NAME
FROM information_schema.KEY_COLUMN_USAGE
WHERE TABLE_SCHEMA = 'your_database'
AND TABLE_NAME = 'orders'
AND REFERENCED_TABLE_NAME IS NOT NULL;
逻辑分析与参数说明
- INFORMATION_SCHEMA 表 是 MySQL 提供的标准元数据视图,无需额外权限即可读取。
DATA_TYPE和CHARACTER_MAXIMUM_LENGTH用于判断字段是否需要调整(如 VARCHAR(50) → VARCHAR(100))。IS_NULLABLE变更会触发MODIFY COLUMN ... NOT NULL操作。COLUMN_DEFAULT不一致时,即使其他属性相同也会标记为差异。- 对于复合索引,需按
SEQ_IN_INDEX排序后整体比对,避免因顺序不同误判为新增索引。 - 外键约束比对需同时验证名称、列名、引用表及列,防止级联删除异常。
差异检测结果以树形结构展示在 SQLyog 界面中,支持用户选择性忽略某些非关键变更(如注释修改),从而实现精细化控制。
| 差异类型 | 是否默认同步 | 影响等级 | 建议处理方式 |
|---|---|---|---|
| 新增字段 | ✅ | 高 | 自动添加 |
| 字段类型变更 | ⚠️(需确认) | 极高 | 检查数据兼容性后再执行 |
| 字段长度缩小 | ❌(禁止) | 极高 | 手动评估截断风险 |
| 删除字段 | ⚠️ | 高 | 提示备份原数据 |
| 新增索引 | ✅ | 中 | 可后台异步创建 |
| 删除索引 | ⚠️ | 中 | 分析查询性能影响 |
| 外键变更 | ⚠️ | 高 | 检查关联表状态,防止级联失败 |
注意 :SQLyog 在进行类型变更(如 INT → BIGINT)时,会自动判断是否存在潜在的数据丢失风险。若目标字段精度低于源字段(如 DECIMAL(10,2) → DECIMAL(8,2)),则强制阻止同步并提示错误。
5.1.2 同步方向控制与反向映射配置
结构同步并非总是单向操作。在某些复杂场景中,例如双向复制调试、灰度发布回滚、A/B 测试分支合并时,可能需要灵活切换同步方向。SQLyog 支持以下三种同步模式:
| 模式 | 描述 | 适用场景 |
|---|---|---|
| Source → Target | 将源结构变更应用到目标数据库 | 日常上线更新 |
| Target → Source | 反向同步,适用于本地开发库修复后推送到远程 | 开发调试反馈 |
| Bi-directional | 双向比对,列出双方独有或冲突的对象 | 架构评审、环境对齐 |
反向映射(Reverse Mapping)功能允许用户自定义对象映射规则,突破“同名同库”的限制。例如:
{
"mapping_rules": [
{
"source_db": "dev_orders",
"target_db": "prod_oms",
"table_mapping": {
"user_info": "customer_master",
"order_hdr": "so_header",
"order_det": "so_detail"
},
"exclude_tables": ["temp_log", "debug_trace"]
}
]
}
此配置可在不修改原始表名的情况下完成跨命名规范的结构同步。SQLyog 内部通过虚拟元数据层实现映射转换,真正执行 ALTER 语句前会动态重写对象名称。
此外,还支持 过滤规则配置 ,可通过正则表达式排除特定对象:
Exclude Tables: ^tmp_|^backup_|_staging$
Exclude Columns: %_audit_% , created_by
这些规则可在 GUI 中设置,也可通过 .syncprofile 文件保存为模板供团队共享使用。
5.1.3 自动生成 ALTER 语句的安全审核机制
结构变更本质上是一系列 ALTER TABLE 语句的组合。SQLyog 并非直接执行变更,而是先生成预览脚本,供用户审查后再提交。这一过程包含多重安全校验机制:
安全校验流程图
graph LR
H[生成 ALTER 脚本] --> I{是否涉及锁表操作?}
I -- 是 --> J[提示 LONG RUNNING 操作风险]
I -- 否 --> K[标记为轻量变更]
J --> L{启用 ONLINE DDL?}
L -- 是 --> M[添加 ALGORITHM=INPLACE, LOCK=NONE]
L -- 否 --> N[警告可能导致服务中断]
M --> O[输出最终脚本]
N --> O
示例:字段扩展的安全脚本生成
假设需将 users.phone 从 VARCHAR(15) 扩展为 VARCHAR(20) :
-- SQLyog 自动生成的 ALTER 语句
ALTER TABLE `users`
MODIFY COLUMN `phone` VARCHAR(20) CHARSET utf8mb4 COLLATE utf8mb4_unicode_ci NULL DEFAULT NULL,
ALGORITHM=INPLACE, LOCK=NONE;
参数说明与执行逻辑分析
MODIFY COLUMN:明确指定要更改的列及其新定义。CHARSET/COLLATE:继承原表字符集设定,防止意外降级。NULL DEFAULT NULL:保留原空值与默认值策略。ALGORITHM=INPLACE:优先使用 MySQL 5.6+ 的 inplace 算法,减少磁盘复制开销。LOCK=NONE:尽可能避免表级锁定,提升并发访问能力。
⚠️ 若目标 MySQL 版本 < 5.6 或存储引擎为 MyISAM,则
ALGORITHM=INPLACE不被支持,SQLyog 会自动降级为COPY方式并发出严重警告:“此操作将导致全表重建,请在维护窗口执行。”
更进一步,SQLyog 还集成 语法模拟器 ,可在本地解析 ALTER 语句的潜在影响,即使未连接目标库也能预判执行结果。这对于审批流程中的 DBA 审核极为有用。
5.2 数据同步(Data Sync)执行流程
相较于结构同步,数据同步关注的是行级内容的一致性维护,尤其适用于主从延迟修复、异地容灾恢复、历史数据归档等场景。SQLyog 的 Data Sync 模块采用 主键匹配 + 增量识别 + 批处理传输 三位一体的设计理念,兼顾效率与可靠性。
5.2.1 主键匹配与增量数据识别逻辑
数据同步的前提是能够准确识别哪些记录发生了变化。SQLyog 默认采用“主键驱动”的比对策略:
# 伪代码:主键匹配与变更识别
def detect_changes(source_cursor, target_cursor, table_name):
# 获取源和目标的所有主键
source_keys = set(row[0] for row in source_cursor.execute(f"SELECT id FROM {table_name}"))
target_keys = set(row[0] for row in target_cursor.execute(f"SELECT id FROM {table_name}"))
inserts = source_keys - target_keys
deletes = target_keys - source_keys
common_keys = source_keys & target_keys
updates = []
for pk in common_keys:
src_row = get_full_row(source_cursor, table_name, pk)
tgt_row = get_full_row(target_cursor, table_name, pk)
if hash(src_row) != hash(tgt_row): # 简化版比较
updates.append(pk)
return inserts, updates, deletes
实际执行中的优化策略
- 分批扫描 :对大表使用
LIMIT offset, batch_size分页读取主键,避免内存溢出。 - 哈希摘要比对 :对每一行计算 CRC32 或 MD5 哈希值,仅在网络上传输摘要而非完整数据。
- 时间戳辅助 :若表含有
updated_at TIMESTAMP ON UPDATE CURRENT_TIMESTAMP字段,可先按时间范围筛选候选行,大幅减少比对量。
例如:
-- 快速获取最近变更的主键
SELECT id FROM orders
WHERE updated_at > '2025-04-01 00:00:00'
AND updated_at <= NOW();
该策略可使百万级表的同步准备阶段从分钟级缩短至秒级。
5.2.2 冲突解决策略(源优先、目标保留、手动干预)
当同一记录在源和目标端均被修改时,即发生 数据冲突 。SQLyog 提供三种预设策略:
| 策略 | 行为描述 | 适用场景 |
|---|---|---|
| Source Wins | 覆盖目标端数据 | 强中心化架构,源为权威系统 |
| Target Wins | 忽略源端变更,保留目标数据 | 本地缓存、边缘节点自治 |
| Manual Merge | 弹出对比界面,人工选择保留版本或合并字段 | 关键业务数据,不允许自动覆盖 |
冲突检测与处理流程图
sequenceDiagram
participant S as Source
participant T as Target
participant C as Conflict Resolver
S->>C: 发送变更记录 (id=1001, name="Alice", ver=2)
T->>C: 当前记录 (id=1001, name="Alicia", ver=2)
C->>C: 检测到内容不同但版本相同
alt 用户选择 Source Wins
C->>T: UPDATE name='Alice'
else 用户选择 Target Wins
C->>S: REJECT change
else Manual Merge
C->>User: 显示并列对比界面
User->>C: 选择部分字段采纳
C->>T: 应用混合结果
end
这种细粒度控制极大提升了数据治理的灵活性,尤其是在金融、医疗等高合规要求领域。
5.2.3 断点续传与传输状态持久化
网络中断或进程崩溃不应导致整个同步任务重来。SQLyog 通过 状态快照机制 实现断点续传:
-- 创建同步状态记录表
CREATE TABLE `_datasync_status` (
`task_id` VARCHAR(64) PRIMARY KEY,
`table_name` VARCHAR(64),
`last_sync_key` BIGINT, -- 上次同步到的主键
`batch_size` INT DEFAULT 1000,
`status` ENUM('RUNNING', 'PAUSED', 'COMPLETED'),
`checkpoint_time` DATETIME
);
每次批量传输完成后,自动更新 last_sync_key ,下次启动时从此处继续拉取。
此外,所有操作均封装在事务中:
START TRANSACTION;
INSERT INTO target_table VALUES (...);
UPDATE _datasync_status SET last_sync_key = ?, checkpoint_time = NOW();
COMMIT;
确保数据与状态的一致性。若中途失败,事务回滚,状态不变,下次可无缝接续。
5.3 迁移向导工具深度应用
5.3.1 跨服务器数据库整体迁移步骤
SQLyog 的 Migration Wizard 支持一键式跨服务器迁移,典型流程如下:
- 选择源连接与目标连接
- 选择迁移范围(全部数据库 / 指定数据库 / 单个表)
- 配置字符集转换与对象过滤
- 预览迁移计划(结构导出 → 数据传输 → 索引重建)
- 执行并监控进度
迁移过程中自动处理依赖顺序:先建表,再插数据,最后建索引与外键。
5.3.2 字符集转换与 collation 兼容性调整
-- 自动转换示例:latin1 → utf8mb4
ALTER TABLE `legacy_data` CONVERT TO CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
SQLyog 在迁移前扫描源表字符集,若发现不一致,提供统一转换选项,并自动修正连接层编码设置。
5.3.3 触发器、存储过程复制限制与应对措施
由于权限隔离与安全性考虑,SQLyog 默认不自动迁移函数、触发器、事件调度器对象。需手动导出:
SHOW CREATE FUNCTION func_name;
SHOW CREATE TRIGGER trigger_name;
然后在目标端单独执行。建议配合版本控制系统(如 Git)管理这些对象脚本。
5.4 同步任务监控与性能调优
5.4.1 实时进度条与预计完成时间估算
SQLyog 提供可视化进度面板,显示:
- 已处理表数 / 总表数
- 当前表已完成行数 / 总行数
- 当前速度(rows/sec)
- 预估剩余时间(基于滑动平均速率)
5.4.2 网络带宽占用控制与批处理大小调节
可通过设置每批次行数(Batch Size)和延迟间隔(Delay Between Batches)控制资源消耗:
| Batch Size | Memory Use | Network Burst | Recommended For |
|---|---|---|---|
| 100 | Low | Small | 高延迟网络、小表 |
| 1000 | Medium | Moderate | 普通 LAN、中等规模数据 |
| 10000 | High | Large | 内网高速链路、大批量迁移 |
合理调节可避免阻塞线上业务。
6. 跨环境数据库内容迁移实战
6.1 开发、测试、生产环境隔离原则
在企业级数据库管理中,开发(Development)、测试(Testing)与生产(Production)环境的严格隔离是保障系统稳定性与数据安全的核心策略。SQLyog 提供了连接分组管理功能,支持用户按环境类型创建独立的连接配置组,实现逻辑上的清晰划分。
通过“Connection Manager”中的“Grouping”功能,可将不同环境的数据库连接归类至 DEV_Group 、 TEST_Group 、 PROD_Group 等命名组中。该机制不仅提升操作安全性(防止误连生产库),还便于批量管理和权限审计。
-- 示例:用于识别当前连接所属环境的元数据查询
SELECT
@@hostname AS host,
DATABASE() AS current_db,
CASE
WHEN DATABASE() LIKE '%dev%' THEN 'Development'
WHEN DATABASE() LIKE '%test%' THEN 'Testing'
WHEN DATABASE() LIKE '%prod%' THEN 'Production'
ELSE 'Unknown'
END AS env_classification;
此外,在跨环境迁移过程中,敏感字段如用户密码、身份证号、手机号等需进行脱敏处理。SQLyog 支持在导出或同步前执行自定义 SQL 脚本,实现动态脱敏:
-- 脱敏示例:对 phone 字段做部分掩码
UPDATE users
SET phone = CONCAT(LEFT(phone, 3), '****', RIGHT(phone, 4))
WHERE env_flag = 'TEST';
| 环境类型 | 数据真实性 | 访问权限 | 典型用途 |
|---|---|---|---|
| 开发 | 模拟/子集 | 开放 | 功能编码调试 |
| 测试 | 近似真实 | 受限 | 集成与压力测试 |
| 生产 | 完整真实 | 严格控制 | 对外服务运行 |
上述标准化配置应结合组织内部 DevOps 规范统一实施,确保所有团队成员遵循一致的操作路径。
6.2 全量数据迁移项目实施案例
6.2.1 需求分析:从旧系统到新架构的数据整合
某金融平台需将原有单体 MySQL 数据库(MySQL 5.7)迁移至微服务化的新架构(MySQL 8.0 分库部署)。涉及表共计 127 张,总数据量约 4.8TB,包含交易记录、客户资料、风控日志等关键业务数据。
迁移目标包括:
- 结构适配:字段类型升级(如 DATETIME → TIMESTAMP WITH TIME ZONE )
- 拆分逻辑:按租户 ID 水平分片
- 编码统一:UTF8MB4 + utf8mb4_unicode_ci 排序规则
6.2.2 迁移前评估:容量预估与停机窗口规划
使用 SQLyog 的“Schema Information”工具分析源库结构复杂度,并估算目标端存储需求:
-- 获取各表行数与数据大小(单位:MB)
SELECT
table_name,
table_rows,
ROUND((data_length + index_length) / 1024 / 1024, 2) AS total_size_mb
FROM information_schema.tables
WHERE table_schema = 'legacy_system'
ORDER BY total_size_mb DESC
LIMIT 10;
输出前10大表如下:
| table_name | table_rows | total_size_mb |
|---|---|---|
| transaction_log | 89234765 | 1843.67 |
| user_profile | 2345678 | 762.34 |
| audit_trail | 67890123 | 1520.11 |
| order_detail | 34567890 | 1205.89 |
| payment_record | 12345678 | 678.23 |
| customer_msg | 56789012 | 1100.45 |
| login_history | 78901234 | 1345.67 |
| risk_event | 4567890 | 543.21 |
| notification | 3456789 | 432.10 |
| report_cache | 2345678 | 321.98 |
根据网络带宽(1Gbps)和压缩率(约60%),预计全量传输耗时约 6.5 小时,故设定维护窗口为凌晨 00:00–07:00。
6.2.3 执行流程:结构导出 → 初始同步 → 验证校验
利用 SQLyog 的“Synchronization Wizard”执行三阶段迁移:
- 结构导出 :从源库导出 DDL,手动调整兼容性问题(如移除
FOREIGN_KEY_CHECKS=0)
-- 导出结构时自动添加的头部设置
SET @OLD_FOREIGN_KEY_CHECKS=@@FOREIGN_KEY_CHECKS;
SET FOREIGN_KEY_CHECKS=0;
-- ... CREATE TABLE statements ...
SET FOREIGN_KEY_CHECKS=@OLD_FOREIGN_KEY_CHECKS;
-
初始同步 :使用“Data Sync”模块建立源→目标映射,启用批处理提交(每批 5000 行)以降低事务开销。
-
验证校验 :同步完成后运行一致性比对脚本:
-- 校验行数是否一致
SELECT 'source' AS env, COUNT(*) AS cnt FROM src_db.users
UNION ALL
SELECT 'target' AS env, COUNT(*) AS cnt FROM tgt_db.users;
-- 校验关键字段摘要(防篡改)
SELECT
MD5(GROUP_CONCAT(user_id ORDER BY user_id)) AS user_id_hash,
SHA1(GROUP_CONCAT(email ORDER BY user_id)) AS email_sha1
FROM users;
mermaid 流程图展示整体流程:
graph TD
A[启动迁移任务] --> B{环境检查}
B -->|成功| C[导出源结构DDL]
C --> D[在目标端创建Schema]
D --> E[启动全量数据同步]
E --> F[启用批量插入+错误重试]
F --> G[生成校验报告]
G --> H{数据一致?}
H -->|是| I[标记迁移完成]
H -->|否| J[定位差异并修复]
J --> G
6.3 增量同步保障业务连续性
6.3.1 利用 binlog 或时间戳字段追踪变更
为减少停机时间,采用“双写+增量追平”策略。在全量同步完成后,开启基于时间戳的增量拉取:
-- 增量查询模板(假设 update_time 存在)
SELECT * FROM orders
WHERE update_time > '2025-04-05 03:30:00'
AND update_time <= '2025-04-05 06:00:00';
若启用了 Binlog,则可通过 SQLyog 的“Binlog Reader”插件解析事件流,精准捕获 INSERT/UPDATE/DELETE 操作。
建议在应用层增加 _last_sync_version 控制表,记录每次同步的最大 GTID 或时间戳:
| sync_table | last_gtid_executed | last_timestamp | record_count |
|---|---|---|---|
| users | 3E1B-A7C9-12D8:198765 | 2025-04-05 05:59:59 | 12345 |
| orders | 3E1B-A7C9-12D8:198770 | 2025-04-05 05:59:58 | 6789 |
6.3.2 最终一致性验证与数据完整性比对
最终切换前执行多维度验证:
- 数量一致性 :COUNT(*) 对比
- 主键覆盖性 :LEFT JOIN 检查缺失主键
- 聚合值比对 :SUM(amount), MAX(id) 是否匹配
- 参照完整性 :外键引用是否存在孤儿记录
-- 查找目标库中不存在于源库的多余记录
SELECT t.id FROM tgt_db.users t
LEFT JOIN src_db.users s ON s.id = t.id
WHERE s.id IS NULL
LIMIT 5;
6.4 回退方案设计与应急响应机制
6.4.1 快照备份与快速回滚通道建立
在迁移开始前,使用 SQLyog 的“Backup Tool”对源库和目标库分别创建 LVM 快照级备份,并归档至异地存储:
# 使用 mysqldump 封装命令(由 SQLyog 自动生成)
mysqldump --host=localhost --user=admin \
--port=3306 --protocol=tcp \
--single-transaction --routines --triggers \
--hex-blob --set-gtid-purged=OFF \
legacy_system > backup_legacy_20250405.sql
同时,在目标库保留原始空库结构副本,命名为 backup_pre_migration ,以便快速还原。
6.4.2 操作审计日志追溯与责任界定
SQLyog 自动记录所有同步操作至本地日志文件(默认路径: C:\Users\$USER\AppData\Roaming\Webyog\SQLyog\Logs\ ),格式如下:
[2025-04-05 02:15:33] INFO SyncEngine: Starting data sync for 'users'
[2025-04-05 02:15:34] DEBUG BatchProcessor: Commit batch size=5000
[2025-04-05 02:16:01] WARN DataConflict: Duplicate key on row 12345
[2025-04-05 02:16:01] ERROR TransactionRollback: Deadlock detected, retrying...
[2025-04-05 03:20:11] SUCCESS SyncComplete: 2,345,678 rows transferred
这些日志可用于事后复盘、性能分析及操作追责,确保迁移过程透明可控。
简介:Webyog SQLyog Ultimate v12.0.9 是一款专为中文用户设计的MySQL数据库管理工具,提供直观高效的界面,支持数据库连接、数据编辑、SQL查询、备份恢复、数据同步、导入导出等多项核心功能。该版本具备官方中文语言支持,集成性能优化、安全管理、图表报表生成及可能的版本控制功能,极大提升了数据库开发与管理效率。本工具适用于MySQL开发者和管理员,通过安装包即可快速部署使用,是MySQL环境下强大的一体化管理解决方案。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 16
16 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)