计算机视觉·LDVC
本文提出LDVC方法,针对零样本语义分割任务中的不可见类别过拟合问题。通过视觉-语言提示机制,在视觉和文本编码器中引入提示token,其中视觉提示采用VPT初始化,语言提示则基于手工设计的提示语嵌入。此外,沿用ZegCLIP的文本适配器设计,并将视觉共识解码器与路由注意力机制结合,重点关注图像中相关性强的区域。实验表明,该方法在归纳设置下对可见类和不可见类均有提升,但在转导设置下效果有限。消融实验
LDVC
创新点
视觉共识:路由注意力。视觉特征离散,容易出现较多碎片化掩码。
文本驱动视觉:文本作为查询。视觉特征不够结构化,应该让视觉特征对齐文本。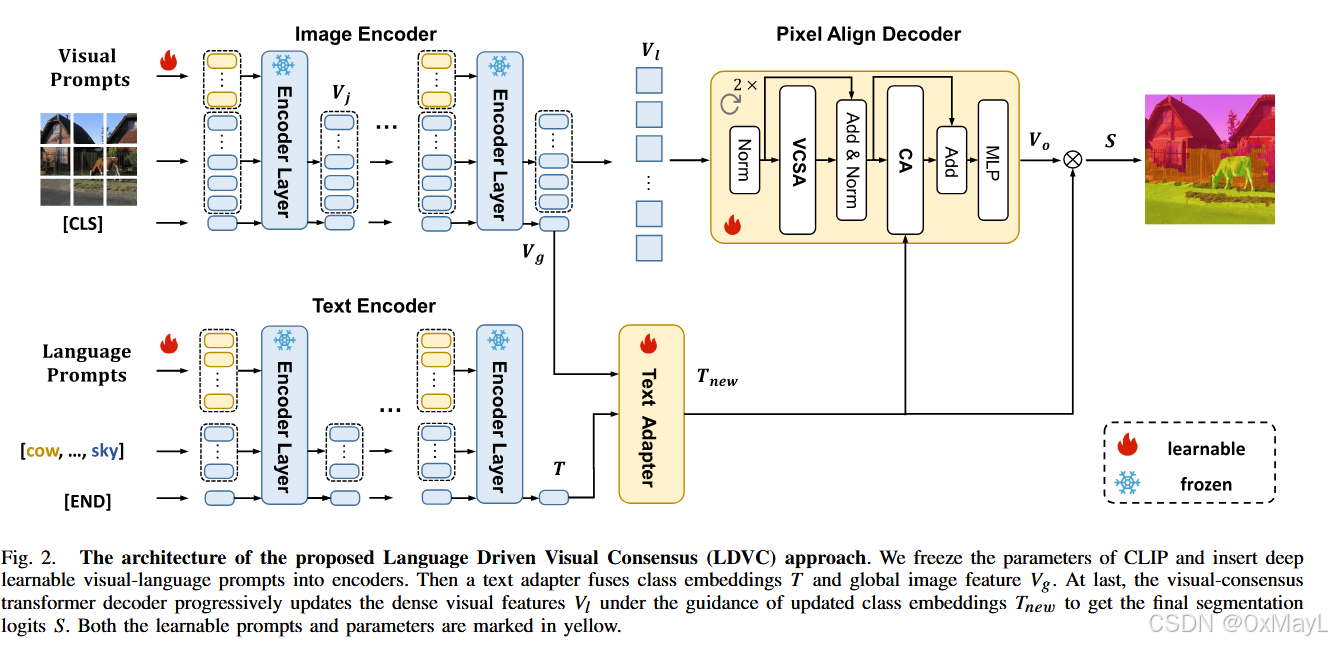
动机
- 之前的工作仍然有对不可见类的过拟合
- 这归咎于解码器的不合理设计:解码器使用文本嵌入进行查询,不适合零样本任务。因为视觉空间相比文本并不足够结构化用于分割。
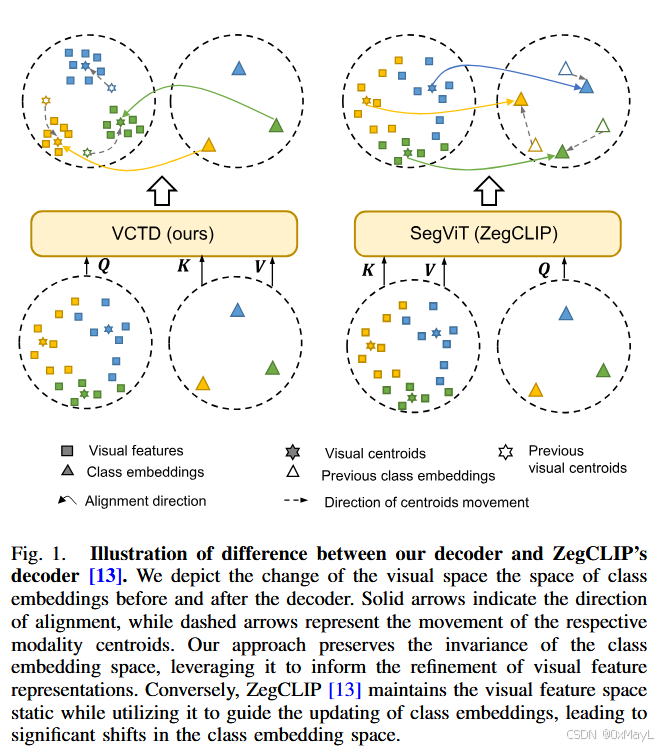
- 让文本嵌入对齐视觉嵌入,会造成较大的嵌入空间迁移,损害分割性能。

方法
视觉-语言提示
- 就是视觉和语义编码器中都引入了提示token
- 初始化时,视觉提示与VPT中的初始化形式一样
- 对文本侧,作者还做了一个关键 trick:用“手工 prompt 模板”的中间层特征来初始化ep(i)e_p^{(i)}ep(i),比如把 “a photo of a {class}” 送入预训练 CLIP 文本编码器,取各层中 template token 的 embeddings 作为初始化,比随机高斯初始化效果好很多。
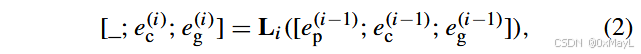

文本适配器
- 将关系描述符表达为文本适配器,与ZegCLIP完全一致,毫无区别
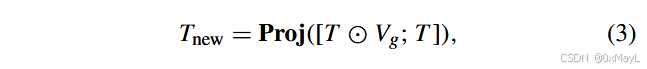
视觉共识解码器
总体流程
- VjV_jVj是视觉编码器中的某一层输出,
作者好像没有具体给出j的取值?

视觉共识自注意力
- 基于路由注意力的机制
- 简单来说就是关注图片中相关的区域,例如“草”的区域关注“草”的区域。
- 首先要对图像窗口化,然后计算注意力权重,保留权重高的窗口,还原得到高度相关的KsK_sKs和VsV_sVs(只有部分patch)
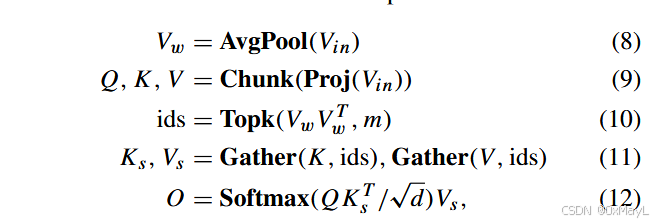
掩码产生机制
- 掩码产生机制几乎完全一样
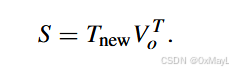
实验
对比实验
- 在归纳设置下,可见类和不可见类都有一定提升
- 在转导设置下,几乎没有任何有效提升。
消融实验
- 交叉注意力图可以学习一下。

GPT总结
- 摘要翻译
预训练视觉-语言模型(如 CLIP)通过在 transformer 解码器中将视觉特征与类别嵌入对齐来生成语义掩码,从而推动了零样本语义分割的发展。然而,这一范式下现有方法仍然存在两个问题:在已见类别上过拟合以及分割掩码出现小碎块。为缓解这些问题,作者提出了一种语言驱动的视觉共识(Language-Driven Visual Consensus, LDVC)方法,以促进视觉与语言信息的更好对齐。具体地,他们利用类别嵌入的离散且抽象的特性,将其视为锚点,引导视觉特征向类别嵌入靠拢。为了获得更加紧凑的视觉空间,他们在 transformer 解码器中引入了**路径注意力(route attention)**来寻找视觉共识,从而提升同一物体内部的语义一致性。配合一种视觉-语言提示策略,该方法显著提升了分割模型在未见类别上的泛化能力。实验结果表明,与最新方法相比,该方法在 PASCAL VOC 2012 和 COCO-Stuff 164K 数据集的未见类别上分别提升了 4.5% 和 3.6% 的 mIoU。
1. 方法动机
1.a 为什么要提出这个方法?
一阶段 CLIP-based ZS3(如 ZegCLIP)已经能把 CLIP 的图像级零样本能力迁移到像素级,但仍有两个关键痛点:
-
过拟合已见类别
- 训练时只有已见类标签,解码器不断把“视觉空间”/“文本空间”往训练类别方向挤,未见类的判别边界被破坏,推理时泛化能力变差。
-
掩码“小碎块”(fragmentation)严重
- 同一物体内部像素的特征不够一致,导致解码器在同一个物体里划出一堆零散的小块,视觉效果差、mIoU 也受影响。
作者认为:关键不只是用 CLIP,而是“怎么在像素层面对齐视觉与文本空间、调谁的空间”。之前方法主要动的是“类嵌入空间”;他们则想反过来——尽量固定文本空间,用文本去“拉拢”视觉空间。再加上在视觉特征内部做“语义聚类”,减少碎块。
1.b 现有方法的痛点/不足
以 ZegCLIP 为代表的一阶段方法,大多:
-
解码器设计:
- 用“类嵌入(文本)做 query,图像特征做 key/value” 的 cross-attention(基本沿用 SegViT / MaskFormer 风格)。
- cross-attention 主要更新的是类嵌入 T,视觉特征 V 几乎不动。
-
问题 1:类嵌入漂移(class embedding drift)
- 文本空间原本在 CLIP 上已经对 ImageNet 等数据集具有很好泛化。
- 训练时反复用噪声较大的视觉特征去“牵引”类嵌入,使得文本空间严重变形,破坏了 CLIP 原本良好的零样本结构(Fig.1 右侧示意)。
-
问题 2:视觉空间不够结构化
- 视觉特征冗余、噪声大,同一物体内部的像素点在特征空间并不紧凑——掩码容易碎。
- 解码器几乎不改变视觉空间结构,导致 pixel–text 对齐变得困难。
1.c 论文的研究直觉 / 假设
作者的核心直觉可以概括为三点:
-
语言空间更抽象、更结构化
→ CLIP 文本编码器输出的类别嵌入,可以被视作视觉聚类中心(anchors)。 -
应该让视觉特征“向文本靠拢”,而不是反过来拉文本
→ 在 cross-attention 中以图像特征为查询、以类别嵌入为键和值,更新的是视觉特征,把视觉投射到由类嵌入张成的低秩空间中。 -
在对齐文本之前,先在视觉内部“达成共识”
→ 用 route attention 做局部/块级自注意力,强制同一物体内部的像素更多地互相关注,使得视觉特征域更紧凑,减少小碎块。
2. 方法设计(pipeline + 结构 + 公式)
整体架构见 Fig.2:上半部分是插入视觉 prompts 的图像编码器,下半部分是插入语言 prompts 的文本编码器,右侧是 Text Adapter + Visual Consensus Transformer Decoder(VCTD)。
我按“输入→编码→适配→解码→输出”五步讲,并穿插矩阵维度。
2.a 总体流程
记号:
-
输入图像:(I \in \mathbb{R}^{H\times W \times 3})
-
视觉编码器输出:
- 稠密特征:(V_l \in \mathbb{R}^{h\times w \times d})
- 多层中间特征:({V_j}_{j=1}^N),其中每个 (V_j \in \mathbb{R}^{h\times w \times d})(或尺度相近)
- 全局特征:(V_g \in \mathbb{R}^{d})([CLS])
-
文本编码器输出:
- 类别嵌入:(T \in \mathbb{R}^{c\times d})(c 是类数)
-
解码器最终输出:
- logits:(S \in \mathbb{R}^{c \times h \times w})
第一步:带视觉/语言提示的 CLIP 编码
1)在每层 transformer 中插入深度 prompts
对任一层 (i),该层的输入序列拆成三部分:
[
e^{(i)} = [e_p^{(i)}; e_c^{(i)}; e_g^{(i)}]
]
-
(e_p^{(i)}):这一层的可学习 prompt token(视觉或语言)
-
(e_c^{(i)}):内容 token
- 视觉侧:patch tokens(像素块)
- 文本侧:词级 token,包括 class name 的词
-
(e_g^{(i)}):全局 token
- 视觉侧:[CLS],代表整图
- 文本侧:[EOS],代表整句
经过第 i 层 transformer:
[
[_;,e_c{(i)};,e_g{(i)}] = L_i([e_p^{(i-1)}; e_c^{(i-1)}; e_g^{(i-1)}])
]
- 训练时 冻结所有 L_i 的参数,只更新每层的 e_p^{(i)}。
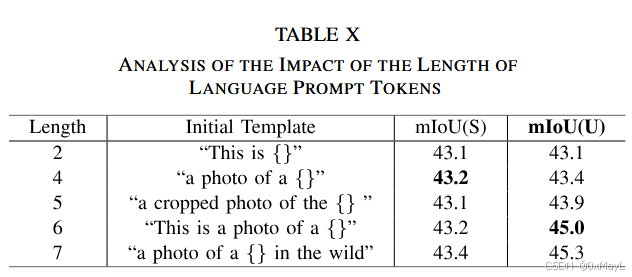
- 对文本侧,作者还做了一个关键 trick:用“手工 prompt 模板”的中间层特征来初始化 e_p^{(i)},比如把 “a photo of a {class}” 送入预训练 CLIP 文本编码器,取各层中 template token 的 embeddings 作为初始化,比随机高斯初始化效果好很多(表 IX 在 unseen 上 +4.5 mIoU)。
维度:
- 视觉侧:假设 patch 数量为 (L = h\cdot w),视觉 prompt 长度为 (P_v),则每层输入长度为 (P_v + L + 1)(+1 是 CLS)。
- 文本侧:假设文本 token 长度为 (L_t),语言 prompt 长度为 (P_t),则每层长度为 (P_t + L_t + 1)(+1 是 EOS)。
2)得到最终编码结果
-
视觉 encoder:
- 最后一层 patch tokens reshape 成 (V_l \in \mathbb{R}^{h\times w\times d})。
- 每一层对应的特征记作 (V_j) 供后续多层融合。
- CLS token 作为 (V_g \in \mathbb{R}^d)。
-
文本 encoder:
- 每个类别名对应一条文本(带模板 + prompt),取其 [EOS] 或聚合后的向量作为类嵌入:(T \in \mathbb{R}^{c\times d})。
第二步:Text Adapter 融合图像全局信息与类别嵌入
在对像素做对齐之前,作者先用全图的视觉信息 (V_g) 对类嵌入 T 做一次“调味”:
[
T_{\text{new}} = \text{Proj}([T \odot V_g;,T]) \tag{3}
]
- (T \odot V_g):广播逐元素乘,形状还是 (c \times d)。
- ([T \odot V_g; T]):在通道维 concat,得到 (c \times 2d)。
- Proj:线性层 (\mathbb{R}{2d}\to\mathbb{R}d),输出 (T_{\text{new}} \in \mathbb{R}^{c\times d})。
直观理解:每个类嵌入在不大幅变形的前提下,稍微根据当前图像的全局特征做一下偏移,提高“图像特定(image-specific)”的判别力。
第三步:Visual Consensus Transformer Decoder (VCTD)
这是本文的核心创新:更新的是视觉特征 V,而 T_new 基本视作稳定的 anchor。每个 decoder block 由:
- 1×1 Conv 融合 CLIP 中间层特征(增强局部语义)
- Visual Consensus Self-Attention(VCSA:带 route attention 的 self-attention)
- Cross-Attention(Q 来自图像,K/V 来自类别)
- MLP
设:
- 进入该 block 的图像特征为 (V_\text{in} \in \mathbb{R}^{h\times w\times d}),展平成 (L\times d)(L=h·w)。
- 该 block 对应的 CLIP 中间特征为 (V_j),通过 1×1 Conv 调整通道数。
Block 内公式:
1)多尺度融合
[
V = V_{\text{in}} + \text{Conv}(V_j) \tag{4}
]
- Conv 的输出与 V_in 尺寸相同(h×w×d),做逐元素相加,相当于引入高层或低层的语义/细节。
2)Visual Consensus Self-Attention (VCSA)
[
V = V + \text{VCSA}(\text{Norm}(V)) \tag{5}
]
VCSA 是一个带 route attention 的自注意力模块,目标是:让每个区域主要跟与它语义相关的少数几个区域互相注意,从而增强同物体内部的“一致性”。
VCSA 的具体步骤(在空间上做窗口分组):
-
对 (V_{\text{in}}) 做平均池化,窗口大小 n×n(文中用 n=4,相当于把 h×w 切成 8×8=64 个窗口):
[
V_w = \text{AvgPool}(V_{\text{in}}) \in \mathbb{R}^{\frac{h}{n}\times \frac{w}{n}\times d} \tag{8}
]展平为 (M \times d),M=64。
-
线性变换得到 Q,K,V:
[
Q, K, V = \text{Chunk}(\text{Proj}(V_{\text{in}})) \tag{9}
]- Proj 把 d 映射到 3d,Chunk 按最后一维切成三个 (L\times d) 矩阵。
-
计算窗口间相似度 & 选出每个窗口最相关的 m 个窗口(文中 m=16):
[
\text{ids} = \text{Topk}(V_w V_w^\top,m) \tag{10}
]- (V_w V_w^\top \in \mathbb{R}^{M\times M}) 是窗口间的 Cos 类似度(或点积),Topk 取每一行最大的 m 个索引。
-
根据 ids,从全局 K,V 里 只取与这些窗口对应的 token:
[
K_s, V_s = \text{Gather}(K,\text{ids}),\ \text{Gather}(V,\text{ids}) \tag{11}
] -
最后做局部化的自注意力:
[
O = \text{Softmax}\left( \frac{Q K_s^\top}{\sqrt d} \right) V_s \tag{12}
]
维度直觉:
- 原始 self-attention 的注意力图是 (L\times L),复杂度 O(L²)。
- Route attention 只在 m 个窗口(以及窗口内 token)上计算,既降低计算量,也约束了注意范围,类似“语义簇内的聚类”。
3)跨模态 Cross-Attention(视觉向文本靠拢)
[
V = V + \text{CA}(\text{Norm}(V),\text{Norm}(T_\text{new})) \tag{6}
]
- Query:图像特征 (V \in \mathbb{R}^{L\times d})
- Key / Value:类嵌入 (T_\text{new} \in \mathbb{R}^{c\times d})
标准 cross-attention:
[
\text{Attention}(Q,K,V) = \text{Softmax}\left(\frac{QK^\top}{\sqrt d}\right)V
]
关键点:
- 每个像素的更新是若干类嵌入的线性组合。
- 因为 c(类数)远小于 L(像素数),像素特征被压进一个 由类别向量张成的低秩子空间,这就是作者说的“更紧凑的视觉空间”。
4)MLP 残差
[
V_{\text{out}} = V + \text{MLP}(\text{Norm}(V)) \tag{7}
]
多层 decoder 堆叠后得到最终特征 (V_o)。
第四步:点积生成像素级 logits
最后一步非常“CLIP 风格”:
- 把 (V_o \in \mathbb{R}^{h\times w\times d}) 展平为 (\mathbb{R}^{L\times d}) 并转置为 (d\times L)。
- 类嵌入 (T_\text{new} \in \mathbb{R}^{c\times d})。
- 做矩阵乘法:
[
S = T_\text{new} V_o^\top \in \mathbb{R}^{c\times L} \tag{13}
]
再 reshape 回 (c\times h\times w),得到每类每像素的 logits,即分割结果。
第五步:损失函数
损失是 Focal Loss + Dice Loss 的加权和:
- Focal loss(按像素、按类):
[
L_\text{focal} = -\frac{1}{HW}\sum_{i=1}^{HW} (1-y_i)^\gamma \log y_i \tag{14}
]
- Dice loss:
[
L_\text{dice} = 1 - \frac{2\sum_i y_i \hat y_i}{\sum_i y_i^2 + \sum_i \hat y_i^2} \tag{15}
]
- 总损失:
[
L_\text{seg} = \beta \cdot L_\text{focal} + L_\text{dice} \tag{16}
]
实现中 (\beta = 100.0),Dice 权重 1.0。
2.b 模块作用总结
-
Vision/Text Encoders + Deep Prompts(VLPT)
- 冻结 CLIP 主体,利用每层少量 prompt token 调整其行为,达到 “小改动,大收益” 的参数高效微调。
- 视觉 prompt 负责让视觉特征更适合分割;语言 prompt 负责改写文本空间但尽量不破坏原有的类结构。
-
Text Adapter
- 用全局图像特征 (V_g) 轻微调节类嵌入,使其图像相关,更容易对齐 pixel 特征。
-
Visual Consensus Self-Attention(VCSA)
- 通过 route attention 只在“语义相近”的窗口间做自注意力,增强同一物体内部的特征一致性,抑制掩码碎片(Fig.4 可视化确实噪声更少)。
-
Cross-Attention with Image as Query
- 把像素特征拉向类别 anchors,在保证文本空间相对稳定的前提下,使视觉空间更“按类别分簇”。
-
Dot-Product Segmentation Head
- 简单点积,保持与原始 CLIP 兼容的对齐方式。
3. 与其他方法对比
3.a 与主流方法的本质差异
-
与两阶段方法(如 MaskCLIP 系、ZS3 baseline)
-
两阶段:
- 先用一个分割网络产生 class-agnostic masks。
- 再用 CLIP 对每个 mask cropped 出来的图或特征做图像级分类。
- 优点:几乎不改 CLIP,零样本能力强;缺点:推理成本高(每个 mask 一次 CLIP),而且 mask proposal 与 CLIP 解耦。
-
LDVC:
- 一阶段 end-to-end,把 CLIP 的视觉/文本编码器 + 解码器合成一个体系。
- 通过 VLPT + VCTD 兼顾 低推理开销和较强的 zero-shot 能力。
-
-
与 ZegCLIP / SegViT 式一阶段方法
主要差别有三:
-
Cross-Attention 方向相反
- ZegCLIP:query = 类嵌入,key/value = 图像特征 → 更新 T,V 不变。
- LDVC:query = 图像特征,key/value = 类嵌入 → 更新 V,T 近乎稳定。
-
显式的“视觉共识”模块
- ZegCLIP 解码器的 self-attention 是 vanilla,全局关注易引入噪声,物体内不够一致。
- LDVC 在 self-attention 中加入 route attention,仅在少数相关窗口内做注意力,更像“语义簇内部 refine”。
-
视觉 + 语言双侧深度 prompt 调节
- ZegCLIP 主要侧重视觉 prompt;
- LDVC 同时在视觉和语言侧做 deep prompt tuning,并提出利用手工模板来初始化语言 prompts。
-
3.b 创新点与贡献
-
Language-Driven Visual Consensus Decoder(VCTD+VCSA)
- 以类嵌入为 anchor,用 cross-attention 把像素特征投射到低秩类别空间;
- 在 self-attention 内用 route attention 做“局部语义聚集”,缓解 mask 碎片。
-
Vision-Language Prompt Tuning (VLPT) 在 ZS3 任务上的系统性使用
- 深度视觉+语言 prompt;
- 语言 prompt 的“pretrain”初始化策略实验证明显著有益。
-
在相对更少参数下取得更好的性能 & 数据效率
- 只有 11M 可学习参数,却在全监督 COCO-Stuff 164K 上 mIoU 比 ZegCLIP 高 3.7 点。
- 只用 60% 训练数据就能超过 ZegCLIP 用 100% 数据的表现(表 VI)。
3.c 适用范围
更适合的场景包括:
-
开放类别、训练数据有限的分割任务
- 如需要泛化到新类别的自动驾驶、机器人场景。
-
希望在单阶段框架下兼顾精度与效率
- 不想每个 mask 再跑一次 CLIP。
-
已有 ViT-B CLIP 权重,希望做参数高效微调
- 对显存限制和部署成本敏感的场景。
相对不那么合适的情况:
- 类别完全固定、没有 zero-shot 需求,且可以全参数微调一个分割模型时,一些更重的全监督架构可能略优。
- 对实时性极端敏感、硬件极弱的场景(虽然他们的 GFLOPs/FPS 比 ZegCLIP 略优,但毕竟 CLIP+Transformer 本身不算“极轻量级”)。
3.d 方法对比表(概略)
| 方法 | 解码器 cross-attn 方向 | 是否显式视觉聚类 | 微调方式 | 优点 | 缺点 |
|---|---|---|---|---|---|
| 两阶段 CLIP | 无像素级 cross-attn | 否 | 多为冻结 CLIP | 零样本强、设计简单 | 推理慢、pipeline 解耦 |
| ZegCLIP | Text→Image(Q=T) | 否 | 视觉 prompt 为主 | 一阶段、性能不错 | 类嵌入漂移,未见类泛化受损,小碎块 |
| LDVC | Image→Text(Q=V) | 是(VCSA) | 视觉+语言深度 prompt | 未见类 mIoU 提升明显、掩码更干净、参数更少 | 结构稍复杂、实现成本更高 |
4. 实验表现与优势
4.a 如何验证有效性(实验设计)
-
数据集:PASCAL VOC 2012、COCO-Stuff 164K(GZS3 设置),以及 COCO-Stuff 10K(全监督对比)。
-
设置:
- Inductive GZS3:训练时未知 unseen 类名字,只在 seen 类上训练,测试时评估 seen+unseen。
- Transductive GZS3:训练时已知 unseen 类名字,并加一轮 self-training。
- Fully-supervised:所有类别都视作 seen,测上限。
-
指标:
- mIoU(S)(seen 类)、mIoU(U)(unseen 类)、hIoU(调和平均)。
-
基线:SPNet, ZS3, SIGN, ZegFormer, DeOP, SPT-SEG, Cascade-CLIP, ZegCLIP, ZegOT, MAFT 等。
4.b 关键结果(代表性数字)
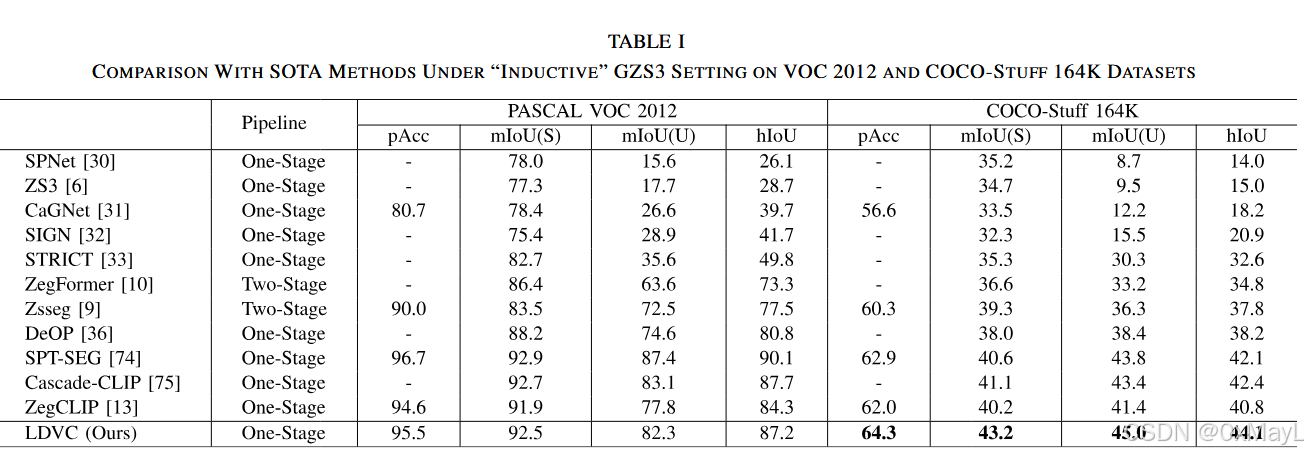
Inductive GZS3(表 I):
-
VOC 2012:
- ZegCLIP:mIoU(S)=91.9, mIoU(U)=77.8, hIoU=84.3
- LDVC:mIoU(S)=92.5, mIoU(U)=82.3, hIoU=87.2
→ 未见类 +4.5,hIoU +2.9。
-
COCO-Stuff 164K:
- ZegCLIP:mIoU(S)=40.1, mIoU(U)=41.4, hIoU=40.8
- LDVC:mIoU(S)=43.2, mIoU(U)=45.0, hIoU=44.1
→ 未见类 +3.6,seen 也 +3.1,说明不是单纯“迁就 unseen”。
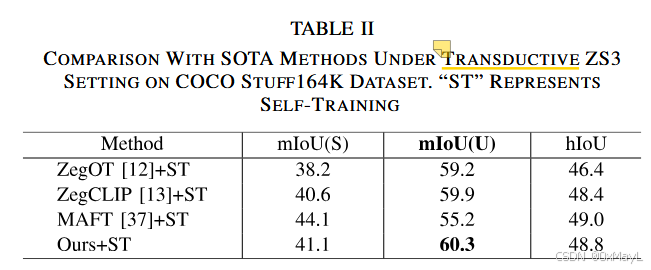
Transductive(表 II):
-
在 COCO-Stuff 164K 上,带 self-training:
- ZegCLIP+ST:mIoU(S)=40.6, mIoU(U)=59.9
- LDVC+ST:mIoU(S)=41.1, mIoU(U)=60.3
→ 仍然有小幅提升,说明方法与自训练兼容。
Fully-supervised(表 III & IV):
-
COCO-Stuff 164K:
- ZegOT:40.1
- ZegCLIP:42.7
- LDVC:46.4(参数量仅 11M,少于 ZegCLIP 的 14M 和 ZegOT 的 21M)
-
COCO-Stuff 10K:
- ViT-B backbone 时,LDVC 优于 RWS;
- ViT-L 时,性能接近 SegViT。
数据效率(表 VI):
-
在 COCO-Stuff 164K:
- ZegCLIP(100% 训练数据):mIoU(S)=40.2, mIoU(U)=41.4
- LDVC(仅 60% 训练数据):mIoU(S)=42.1, mIoU(U)=43.1
→ 用更少数据达到更好性能,说明对数据更友好。
定性可视化(Fig.3 & Fig.4):
-
Fig.3:在 COCO-Stuff 验证集上,LDVC 比 ZegCLIP:
- 能更好地区分 “road” vs “pavement”、“clouds” vs “sky-other”。
- 未见类区域(红色标记类)预测更准确,边界更干净。
-
Fig.4:有 VCSA 时的 cross-attention map 噪声明显更少,聚焦在语义一致的区域。
4.c 优势最明显的场景/数据集
-
GZS3 的未见类别,尤其是 COCO-Stuff 164K 上的 stuff 类(如 road, grass, sky 等):
- 这些类空间上大、形态多变、容易碎片化,VCSA 对减少碎片尤其有帮助。
-
数据不足场景:
- 60% 数据仍优于 ZegCLIP 的 100%,说明对标注比例不那么敏感。
4.d 局限性与不足
论文显式或隐含的不足包括:
-
复杂度仍不算极低
- 虽然比 ZegCLIP 参数更少,但依然要跑 CLIP ViT-B + 多层 decoder + 视觉/语言 prompts。
- 对极端实时场景仍有挑战。
-
路由注意力引入了额外超参数
- 需要设定窗口大小 n、选窗数 m,过大时退化成普通 self-attention、会带来性能下降(表 XII)。
-
依赖 CLIP 的文本空间质量
- 方法假设 CLIP 文本空间已经很好;如果底层 VLM 较弱,类嵌入作为 anchor 的假设就会变弱。
-
论文未详细讨论 OOD 类/长尾类极端情况
- 主实验还是在 VOC/COCO 这类相对标准的数据集上。
5. 学习与应用
5.a 是否开源 & 复现关键步骤
论文中只提到“基于 MMSegmentation 实现,使用 CLIP ViT-B 作为默认编码器”,正文没有明确 GitHub 链接。
建议:实际复现时你可以搜索论文题目 + GitHub,看是否已经放出代码;没有的话就参考 ZegCLIP/DenseCLIP 的实现框架改。
复现的关键步骤:
-
选取公开 CLIP 权重(如 ViT-B/16)。
-
在视觉 & 语言 encoder 的每层插入深度 prompts,并冻结所有原始参数。
-
实现 Text Adapter:(T_\text{new} = \text{Proj}([T\odot V_g; T]))。
-
实现 VCTD:
- 多层 block,每层做 Conv 融合 + VCSA + cross-attn + MLP。
- 注意 cross-attn 的方向:Q=视觉,K/V=类嵌入。
-
最终用 (S = T_\text{new} V_o^\top) 得到 logits,按像素 softmax + Focal+Dice 训练。
5.b 重要超参数 & 训练细节建议
根据实现细节(Sec. IV.A.3 & Ablation):
-
Prompt 相关
-
视觉 prompt 数量:VOC 每层 60 个,COCO 每层 100 个。
-
语言 prompt 数量:每层 6 个(表 X 中 6 左右性能基本饱和)。
-
语言 prompt 初始化:
- 强烈建议用“模板句子”的中间层 embedding 初始化,而不是随机。
- 模板如 “a cropped photo of a {}”, “this is a photo of a {}”, “a photo of a {} in the wild” 等。
-
-
VCTD 相关
-
decoder block 数:2 层即可,更多层对 unseen 类不一定更好(表 XI)。
-
route attention:
- window size n=4 → 8×8 窗口;
- 总窗口数 M=64;
- 选窗数 m=16 或 32,性能类似;m 太大(如 48)会退化。
-
-
优化与数据处理
- 图像 crop 大小:训练和测试都用 512×512。
- 优化器:AdamW,初始 lr=2e-4,多项式衰减。
- 迭代次数:COCO-Stuff 164K 80k iter,VOC2012 20k iter。
- 损失权重:Focal=100.0, Dice=1.0。
实践建议:
- 先在小数据集(如 VOC)上跑通,再扩展到 COCO。
- 可以先只实现“Image as Query + Class as KV 的 cross-attn”,不加 VCSA,验证方向改变带来的增益,再逐步加入 route attention。
- 训练时预先算好所有类文本嵌入并缓存起来,推理时直接加载,可大幅下降 GFLOPs(论文中从 166 降到 71)。
5.c 迁移到其他任务的可行性
这个思想比较通用,尤其是两点:
-
“文本 anchor 引导视觉特征”
-
可迁移到:
- 零样本实例分割 / panoptic segmentation:用实例级特征做 Q,类嵌入做 K/V。
- 开放词汇检测:proposal feature 作为 Q,文本类嵌入为 K/V。
-
-
“视觉共识” / route attention
-
任何需要“同一对象 / 区域内部特征更一致”的 dense 预测任务都能受益:
- 视频分割:在时空上做 route attention;
- 深度估计 / 光流:在空间上聚集相似局部区域。
-
迁移时重点保持两点:
- 把 task-specific 的 region / object 特征当作 query;
- 保证文本/标签空间相对稳定,让其作为 anchor。
6. 总结
6.a 一句话概括核心思想(≤20 字)
用类别向量做锚点,重塑像素特征并增强局部一致性。
6.b 速记版 Pipeline(3–5 步,尽量用自明词)
- 把图像和类别名称同时送入一个图文模型,得到每个像素的向量和每个类别的向量。
- 用整张图的向量稍微调整每个类别向量,使其更贴合当前图像。
- 在像素向量内部先让语义相近的区域互相关注,使同一物体内部的向量更相似。
- 再让每个像素根据所有类别向量重新计算自己的表示,使它更靠近某些类别。
- 用类别向量与像素向量做点积,得到每个像素属于各个类别的分数,生成分割图。
如果你之后想针对某一块(比如只看“Image as Query”的 cross-attn,或者 VCSA 的 route attention)单独推公式/画简化示意图,我们也可以分段再深挖一遍。
下面我将针对你指定的部分 “根据 ids,从全局 K,V 里只取与这些窗口对应的 token”
进行 (1)矩阵维度分析 + (2)实现逻辑解释 + (3)用一个小型具体例子说明,让你真正理解 “route attention” 在 VCSA 中是怎样实现的。
✅ 一、先回顾上下文:VCSA(Visual Consensus Self-Attention)
在 VCSA 中,为了减少注意力范围(让注意力只在“语义相似的 window 里”),作者进行了:
- 将图像 token 进行窗口池化 → 得到 window-level 特征
- 计算窗口间相似度 → 得到相关窗口 top-k
- 对于每个 window,只从 K, V 中选出对应窗口的 token
- 用这些 token 做局部 self-attention(而不是全局 L×L)
你关心的是 步骤 3。
✅ 二、矩阵维度分析(逐步拆解)
我们假设:
- 输入视觉特征 flatten 后为
[
V_{\text{in}} \in \mathbb{R}^{L \times d}
]
例如:
H = 32, W = 32 → L = 1024
d = 768(CLIP ViT-B 维度)
1. 对视觉特征做窗口平均池化
作者设定窗口大小 n=4,于是:
- 特征图 H=W=32 → 32/4=8
- 总窗口数:
[
M = 8\times 8 = 64
]
得到 window 特征:
[
V_w \in \mathbb{R}^{M \times d} = 64 \times 768
]
2. 计算窗口间相似度
[
A = V_w V_w^\top \in \mathbb{R}^{64 \times 64}
]
3. Top-k 选择最相关窗口(论文默认 m=16)
对每个 window i,找到最相似的 16 个窗口:
[
\text{ids}[i] \in \mathbb{R}^{16}
]
所以最终
[
ids \in \mathbb{R}^{64 \times 16}
]
4. 全局 K,V 的维度
Q、K、V 都来自一次线性变换:
[
K, V \in \mathbb{R}^{L \times d} = 1024 \times 768
]
5. Gather:根据 ids,只取对应窗口内的 token
关键点:
❗ 每个 window 包含 (n\times n = 16) 个 token
因为窗口大小为 4×4。
因此:
- 每个 window i 选到的 16 个“相关窗口”
- 每个相关窗口有 16 个 token
→ 所以每个 window 最终要取 16 × 16 = 256 个 token 参与注意力。
矩阵化后:
对于 window i:
[
K_s[i] \in \mathbb{R}^{256 \times d}
]
[
V_s[i] \in \mathbb{R}^{256 \times d}
]
扩展到全部 64 个窗口:
[
K_s \in \mathbb{R}^{64 \times 256 \times d}
]
[
V_s \in \mathbb{R}^{64 \times 256 \times d}
]
6. 最后的 attention 是:
对每个 window:
[
\text{Att}i = \text{Softmax}\left(\frac{Q_i K{s,i}^\top}{\sqrt{d}} \right) V_{s,i}
]
其中:
- (Q_i \in \mathbb{R}^{16 \times d}) (window 内的 16 个 token)
- (K_{s,i} \in \mathbb{R}^{256 \times d})
- 输出为:
[
O_i \in \mathbb{R}^{16 \times d}
]
最后将所有 window 重新拼回 ((H \times W) \times d)。
✅ 三、具体例子(让你彻底理解 Gather)
我们用一个极简版本示范:
- 图像特征:H = 4, W = 4(方便演示)
- 窗口大小 n = 2 → 每个 window = 2×2 = 4 个 token
- 总窗口数:4(划分为 2×2 grid)
- 每个 window 选择 m = 2 个相关窗口
- d = 3(embedding 维度)
1. 图像分成 4 个 window
| window id | token index(flatten后) |
|---|---|
| w0 | [0,1,4,5] |
| w1 | [2,3,6,7] |
| w2 | [8,9,12,13] |
| w3 | [10,11,14,15] |
2. 假设 Top-k 的结果 ids 为
[
ids =
\begin{bmatrix}
1 & 2
0 & 2
0 & 1
1 & 3
\end{bmatrix}
]
含义:
- window 0 的相关窗口是 w1 和 w2
- window 1 的相关窗口是 w0 和 w2
- ……
3. Gather K,V token
假设 K 的 token 索引:
| window | token index |
|---|---|
| w0 | [0,1,4,5] |
| w1 | [2,3,6,7] |
| w2 | [8,9,12,13] |
| w3 | [10,11,14,15] |
举例:对 window 0
它相关窗口是:
ids[0] = [1, 2]
对应 token:
- w1 → [2,3,6,7]
- w2 → [8,9,12,13]
拼起来:
[
K_{s,0} = [K[2],K[3],K[6],K[7],\ K[8],K[9],K[12],K[13]]
]
维度:
[
K_{s,0} \in \mathbb{R}^{8 \times d}
]
对 window 1
ids[1] = [0, 2]
token:
- w0 → [0,1,4,5]
- w2 → [8,9,12,13]
[
K_{s,1} \in \mathbb{R}^{8 \times d}
]
……
✅ 四、从这个机制你应该理解的关键点
1. 不是对 K,V 取某些行,而是按“window → tokens”映射来取
也就是说:
- ids 是 window-level(64×16)
- Gather 会把这些 window 的所有 token(每窗 16 个)全部收集起来
2. 目的是限制 Q 只关注语义相关的局部 token,而不是全局
这样:
- 计算量从 L² 降到 (L × 256)
- 更强的局部一致性,同物体内像素更一致
- 抑制噪声,减少 mask 碎片(论文 Fig.4 的效果)
3. 最终 attention 是分 window 独立计算的
这本质上是一种分块的、动态范围的稀疏注意力(sparse local attention)。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 6
6 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)