(AAAI2025) TimeCMA:LLM赋能时序预测
·

论文:TimeCMA: Towards LLM-Empowered Multivariate Time Series Forecasting via Cross-Modality Alignment
代码:https://github.com/ChenxiLiu-HNU/TimeCMA
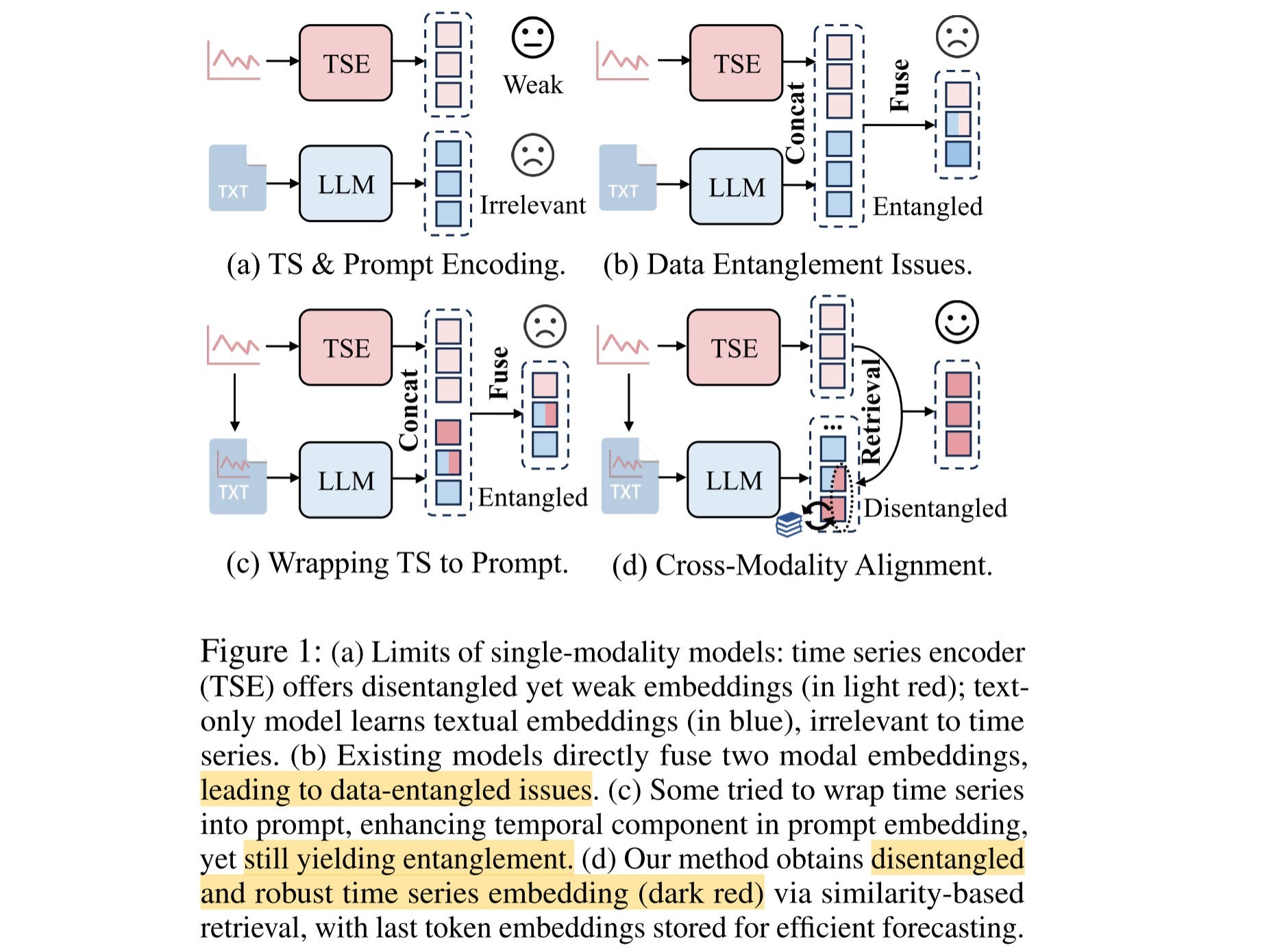
这个论文研究多变量时序预测问题,一般情况下,单个样本的数据量比较小,我之前认为是很难和LLM相结合的。如下图所示,现在有两种结合方法:第一种如(b)所示,直接将两个模态特征拼接。第二种如©所示,将时间序列包装成文本提示,再将多模态特征拼接。这两种方法的问题是:混合后的表示保留了弱的时间信息,也夹杂了噪声,降低了预测性能。
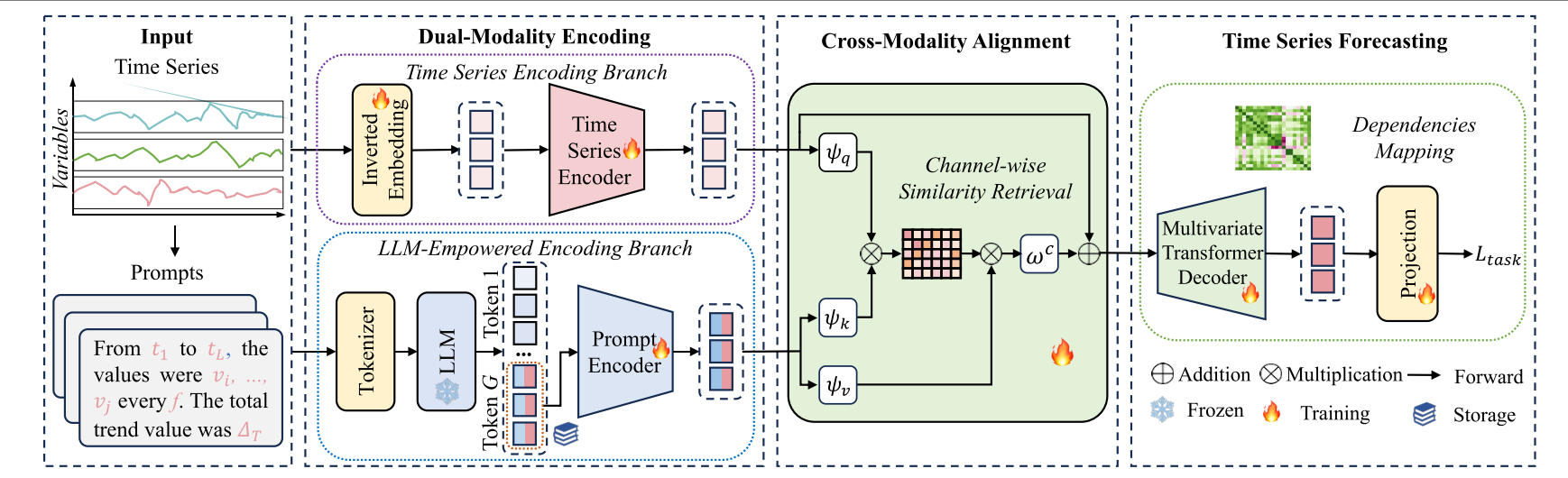
模型的总体框架如下图所示,首先是双模态编码提取特征,然后进行 cross-attention 融合,最后输入decoder预测。模型核心创新在于LLM-Empowered encoding,将时序数据包装成text prompts,包含时间信息和数值信息。然后使用GPT-2处理文本得到 token 序列。作者指出,最后一个token知识最全面,因此只使用最后一个token用于后续跨模态特征融合。
实验部分可以参考作者论文,这里不过多介绍。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)