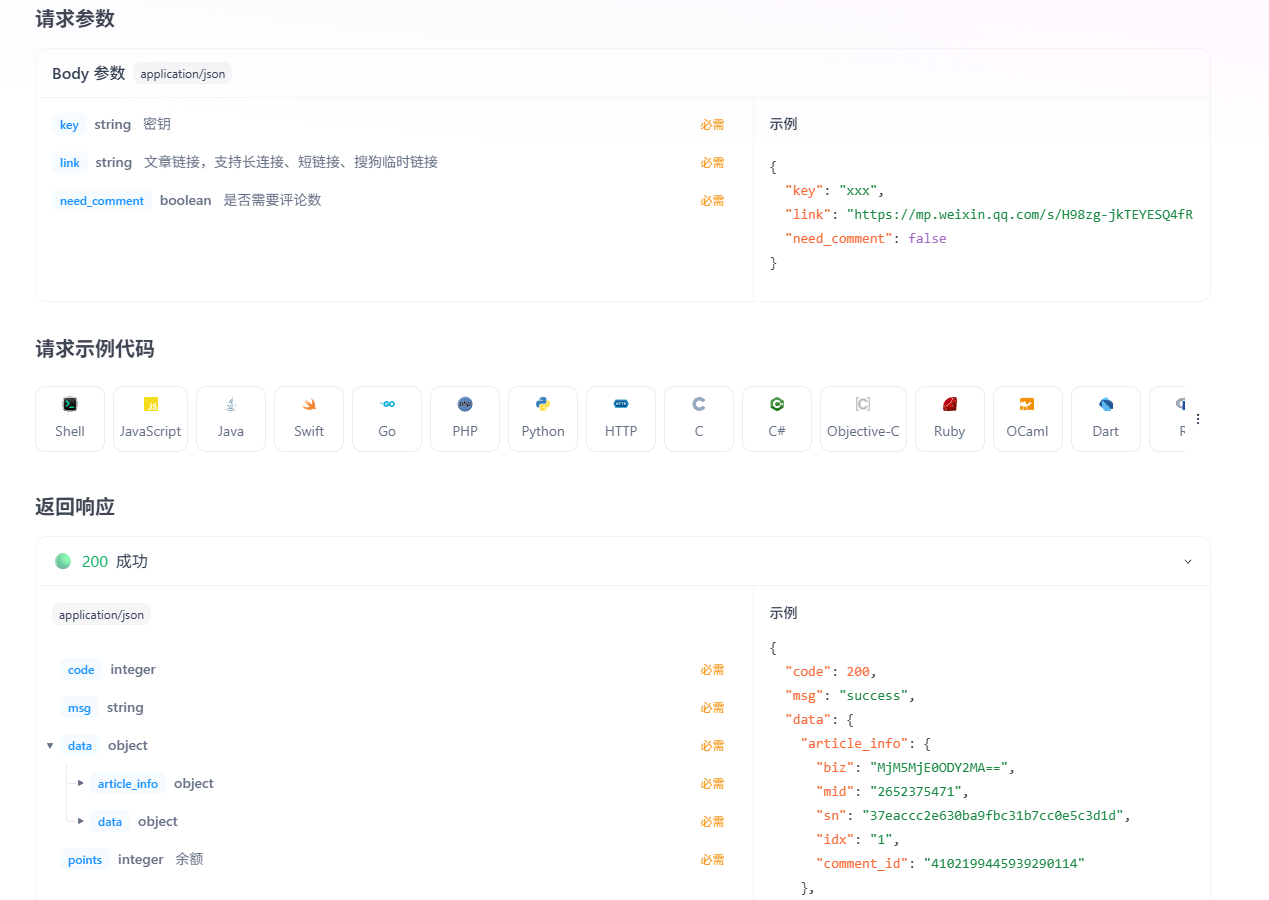
小红书数据采集
小红书数据采集面临动态加载、反爬机制(频率限制、设备指纹、加密参数)及登录验证等难点。解决方案包括:1) 使用Selenium模拟浏览器操作获取动态数据;2) 伪装请求头、控制访问频率、使用代理IP应对反爬;3) 处理Unicode编码和图片URL解密。采集流程需模拟滚动加载,并通过逆向获取核心加密参数x-sign。建议采用住宅IP轮换,控制日请求量≤300次,企业级应用应通过官方API获取数据。
·
一、主要采集难点
-
动态加载机制
- 内容通过AJAX异步加载(如滚动加载)
- 直接获取HTML源码无法捕获完整数据
- 需处理动态生成的
window.__INITIAL_STATE__对象
-
反爬虫策略
- 请求频率限制(每分钟超15次触发验证)【不一定,风控策略随时会调整】
- 设备指纹检测(WebGL/TLS指纹)
- 行为验证码(滑动拼图、点选等)
- 请求头校验(
x-sign加密参数)
-
数据加密保护
- 关键数据(如用户ID)使用
\uunicode编码 - 图片URL带有时效性签名参数
- 评论内容分段加载(limit=20)
- 关键数据(如用户ID)使用
-
登录验证
- 90%内容需登录可见
- 账号风控严格(新号/异地登录需短信验证)【频繁登录会触发生物验证无法破解】
二、采集解决方案
1. 核心采集方法例子
import requests
from selenium import webdriver
from bs4 import BeautifulSoup
import re
import json
# 初始化浏览器驱动
driver = webdriver.Chrome(executable_path='chromedriver')
driver.get('https://www.xiaohongshu.com/explore')
# 处理登录(需提前扫码)
input("请扫码登录后按回车...")
# 获取动态数据
html = driver.page_source
initial_state = re.search(r'window\.__INITIAL_STATE__=(\{.*?\})<', html)
if initial_state:
data = json.loads(initial_state.group(1))
# 提取笔记数据
notes = data['note']['notesList']
for note in notes:
print(f"标题: {note['title']}")
print(f"作者: {note['user']['nickname']}")
2. 关键反爬对策例子
# 请求头伪装
headers = {
'User-Agent': 'Mozilla/5.0 (iPhone; CPU iPhone OS 15_4 like Mac OS X)',
'Referer': 'https://www.xiaohongshu.com/',
'X-Sign': '生成算法见下方' # 需逆向JS获取
}
# IP代理池示例
proxies = {
'http': 'http://user:pass@ip:port',
'https': 'https://user:pass@ip:port'
}
# 请求频率控制
import time
time.sleep(random.uniform(1.5, 3.0)) # 随机延迟
3. 数据解密处理
# Unicode解码示例
def decode_unicode(text):
return re.sub(r'\\u([0-9a-fA-F]{4})',
lambda m: chr(int(m.group(1), 16)), text)
# 图片URL解密
def get_image_url(encrypted_url):
base = "https://ci.xiaohongshu.com/"
params = encrypted_url.split('?')[1]
return f"{base}xxx?{params}"
三、部分采集流程
def xhs_crawler(keyword, max_notes=50):
driver = webdriver.Chrome()
driver.get(f"https://www.xiaohongshu.com/search_result?keyword={keyword}")
# 模拟滚动加载
for _ in range(max_notes//20 + 1):
driver.execute_script("window.scrollTo(0, document.body.scrollHeight)")
time.sleep(2)
# 提取动态数据
html = driver.page_source
data = json.loads(re.search(r'__INITIAL_STATE__=(\{.+?\})<', html).group(1))
results = []
for note in data['note']['notesList'][:max_notes]:
results.append({
'note_id': note['id'],
'title': note['title'],
'content': decode_unicode(note['desc']),
'user': note['user']['nickname'],
'images': [get_image_url(img) for img in note['images']]
})
driver.quit()
return results
重要提示:
- 实际使用时需逆向
x-sign生成算法(核心加密参数)- 建议使用住宅代理IP轮换(AWS/GCP等数据中心IP易被封)
- 遵守
robots.txt协议,单账号日请求量建议≤300次- 企业级采集需通过官方API接口申请(小红书开放平台)
此方案需配合动态IP和验证码识别服务才能稳定运行,建议在测试环境中验证后再部署。
如需要成熟的解决方案进行测试,主页简介有联系方式。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 13
13 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)