SQL去重数据完整解决方案与实战技巧
CTE的基本语法由WITH关键字引导,后接一个或多个命名的结果集定义,每个定义包含名称、列名(可选)和AS引导的查询语句块。其通用结构如下:-- 查询语句SELECT ...-- 主查询使用CTE下面是一个典型示例:假设有一个用户登录日志表,存在因网络重试导致的重复记录,我们希望基于user_id和login_date去重,并统计每日唯一登录人数。SELECTuser_id,MIN(login_t

简介:在SQL中,去除重复数据是数据清洗的关键步骤,直接影响数据的准确性和唯一性。本文介绍了多种SQL去重方法,包括DISTINCT关键字、GROUP BY配合聚合函数、CTE或临时表、自连接、ROW_NUMBER()窗口函数、唯一索引以及集合操作等,适用于不同数据库环境和业务场景。通过这些技术,用户可灵活实现查询去重与物理删除重复记录,提升数据质量。实际操作前建议备份数据,防止误删。 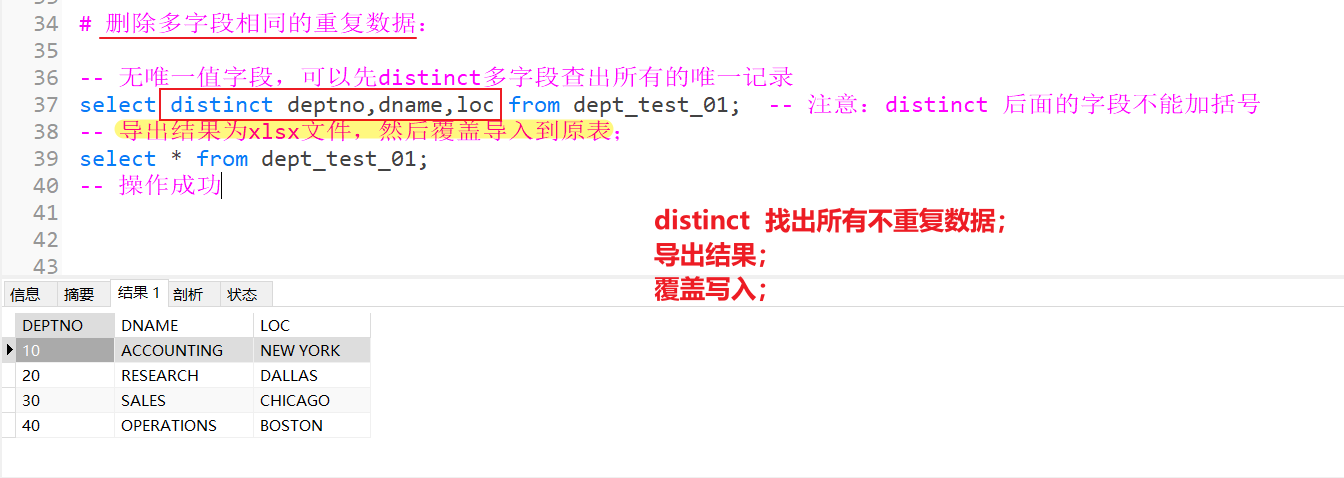
1. SQL去重基本概念与应用场景
在数据库管理和数据分析过程中,重复数据是影响数据质量、查询效率和业务逻辑准确性的关键问题之一。SQL去重作为数据清洗的核心操作,广泛应用于报表生成、用户行为分析、客户信息整合等场景。本章将系统阐述SQL去重的基本定义、产生原因以及典型应用环境,帮助读者建立对数据重复问题的全面认知。
我们将探讨为何即使在具备主键约束的表中仍可能出现语义级重复,例如因历史数据迁移或ETL过程异常导致的冗余记录,并分析不同业务背景下对“重复”的判定标准差异——如订单系统中以 订单号+时间戳 为唯一标识,而在用户画像系统中则可能依据 手机号与设备ID组合 判断。
此外,还将介绍去重操作在提升查询性能、减少存储开销和保障统计准确性方面的实际价值,为后续深入学习各类去重技术奠定理论基础。理解“什么是重复”不仅是技术问题,更是业务建模的关键决策点。
2. 使用SELECT DISTINCT实现查询去重
在SQL数据处理中, SELECT DISTINCT 是最直观且广泛使用的去重手段之一。它能够从查询结果集中消除完全相同的行记录,仅保留唯一值组合,从而满足诸如报表展示、前端接口输出或临时分析等场景对“不重复”数据的需求。尽管其语法简洁,但背后涉及的执行机制、性能影响以及边界行为(如NULL处理)往往被开发者忽视。深入理解 DISTINCT 的工作原理,有助于避免误用导致的数据偏差或系统资源浪费。
2.1 SELECT DISTINCT语法结构与执行机制
SELECT DISTINCT 的核心功能是在最终返回结果前,对投影后的所有字段进行全列比对,并移除内容完全一致的冗余行。该操作发生在 FROM → WHERE → GROUP BY → HAVING → SELECT → DISTINCT → ORDER BY 的标准SQL执行流程中的 SELECT 阶段之后、排序之前。这意味着去重是基于已过滤和计算完成的结果集进行的,而非原始表数据。
2.1.1 DISTINCT关键字的作用范围与语法规则
DISTINCT 关键字位于 SELECT 后,作用于其后所有选定字段的组合。语法格式如下:
SELECT DISTINCT column1, column2, ..., columnN
FROM table_name
WHERE conditions;
需要注意的是, DISTINCT 不是对单个字段去重,而是对 字段组合的整体唯一性判断 。例如,在用户登录日志中执行以下语句:
SELECT DISTINCT user_id, ip_address FROM login_logs;
表示只保留 user_id 与 ip_address 组合不同的记录。即使某个 user_id 出现多次,只要其对应的 ip_address 不同,就会被视为不同行而被保留。
| 示例数据 | user_id | ip_address |
|---|---|---|
| 记录1 | 1001 | 192.168.1.10 |
| 记录2 | 1001 | 192.168.1.10 |
| 记录3 | 1001 | 192.168.1.11 |
上述查询将返回两条记录: (1001, 192.168.1.10) 和 (1001, 192.168.1.11) ,因为虽然 user_id 相同,但 IP 地址有差异;而前两行因完全相同,只保留一条。
此外, DISTINCT 可以与聚合函数共存,但不能直接嵌套于其他表达式内部。某些数据库支持 COUNT(DISTINCT col) 来统计唯一值数量,这是常见的优化统计方式。
flowchart TD
A[开始查询] --> B[FROM 加载数据]
B --> C[WHERE 应用条件过滤]
C --> D[GROUP BY 分组聚合]
D --> E[HAVING 过滤分组]
E --> F[SELECT 投影字段]
F --> G[应用 DISTINCT 去重]
G --> H[ORDER BY 排序输出]
H --> I[返回结果]
该流程图清晰展示了 DISTINCT 在整个查询生命周期中的位置——处于投影之后、排序之前,说明它是逻辑上的“结果集净化”步骤,不影响前期的数据筛选过程。
参数说明与执行顺序关键点
- 作用域 :
DISTINCT影响的是SELECT列表中的所有字段。 - NULL值处理 :两个
NULL被视为相等,因此(1, NULL)与(1, NULL)会被去重合并为一行。 - 性能开销 :需要构建哈希表或排序结构来识别重复项,时间复杂度通常为 O(n log n) 或更高。
- 索引利用 :若选择字段上有覆盖索引(covering index),部分数据库可直接扫描索引去重,显著提升效率。
2.1.2 多字段去重时的数据比对逻辑
当使用多个字段进行 DISTINCT 查询时,数据库引擎会将这些字段拼接成一个“复合键”,并以此作为去重依据。这个过程类似于隐式的 GROUP BY 所有选中字段。
考虑商品库存表 product_stock :
CREATE TABLE product_stock (
product_id INT,
warehouse_id INT,
quantity INT,
last_updated DATE
);
执行如下查询:
SELECT DISTINCT product_id, warehouse_id, quantity
FROM product_stock;
此时,数据库会对每行的 (product_id, warehouse_id, quantity) 三元组进行哈希或排序比较。即使 last_updated 字段不同,也不会影响去重结果,因为它未包含在 SELECT 中。
下面是一个示例数据集及其去重前后对比:
| product_id | warehouse_id | quantity | last_updated |
|---|---|---|---|
| 101 | 1 | 50 | 2024-01-01 |
| 101 | 1 | 50 | 2024-01-02 |
| 101 | 1 | 60 | 2024-01-03 |
| 102 | 1 | 30 | 2024-01-01 |
查询结果为:
| product_id | warehouse_id | quantity |
|---|---|---|
| 101 | 1 | 50 |
| 101 | 1 | 60 |
| 102 | 1 | 30 |
可以看到,前两行由于前三列完全一致,仅保留一行。
这种多字段比对机制在实际应用中非常有用,但也容易引发误解。例如,开发人员可能误以为 DISTINCT product_id 就能去除所有关于该产品的重复信息,但实际上若未指定其他维度字段,可能会遗漏上下文信息。
代码逻辑逐行解读
-- 第1行: 开始选择唯一组合
SELECT DISTINCT
-- 第2行: 指定第一个去重字段
product_id,
-- 第3行: 第二个字段参与组合判断
warehouse_id,
-- 第4行: 数量也纳入比对
quantity
-- 第5行: 数据来源表
FROM product_stock;
- 第1行 :启用去重模式,后续字段构成唯一性判定基础。
- 第2–4行 :每个字段都参与比对。任意一个字段变化即视为新记录。
- 第5行 :数据源加载完毕后进入去重阶段。
此查询适用于需了解“哪些产品在哪些仓库中有多少库存”的业务需求,避免同一库存状态多次呈现。
2.1.3 执行计划中DISTINCT与ORDER BY的交互影响
DISTINCT 与 ORDER BY 的结合使用极为常见,但在执行计划生成过程中二者存在紧密耦合关系。多数数据库优化器会自动将 DISTINCT 实现为排序(Sort Unique)或哈希去重(Hash Aggregation)操作。
以 PostgreSQL 为例,查看执行计划:
EXPLAIN ANALYZE
SELECT DISTINCT user_id, action
FROM user_actions
ORDER BY user_id;
可能得到如下执行计划片段:
Unique (cost=... rows=...) actual time=...
-> Sort (cost=... rows=...) actual time=...
Sort Key: user_id, action
-> Seq Scan on user_actions (cost=... rows=...)
这表明:
1. 先对原始数据按 (user_id, action) 排序;
2. 再通过连续扫描去除相邻重复项(类似 Unix uniq 命令)。
如果 ORDER BY 字段与 DISTINCT 字段不一致,则可能导致额外排序操作:
SELECT DISTINCT action, user_id
FROM user_actions
ORDER BY created_at DESC;
此时无法复用去重排序,需分别执行:
- 一次用于去重的 (action, user_id) 排序;
- 另一次用于最终输出的 created_at 排序。
这将显著增加内存和CPU消耗。理想做法是让 ORDER BY 包含在 DISTINCT 字段集中,或使用索引加速。
| 优化建议 | 描述 |
|---|---|
| 使用联合索引 | 在 (col1, col2) 上创建索引,支持快速去重与排序 |
| 减少字段数量 | 仅选择必要的字段,降低比对开销 |
| 避免跨类型排序 | 如字符与日期混合排序易引起隐式转换,拖慢性能 |
综上所述, DISTINCT 并非轻量操作,尤其在大表或多字段场景下,其与 ORDER BY 的协同设计直接影响查询响应速度。
2.2 实际应用中的限制与优化策略
尽管 SELECT DISTINCT 易于上手,但在生产环境中频繁遭遇性能瓶颈和语义陷阱。尤其是在面对海量数据、复杂字段或特殊值(如NULL)时,简单使用 DISTINCT 往往带来意想不到的问题。掌握其局限性并采取相应优化措施,是保障系统稳定运行的关键。
2.2.1 对NULL值的处理方式及其潜在陷阱
NULL 在SQL中代表“未知值”,其比较规则不同于普通数值。根据SQL标准, NULL = NULL 返回 UNKNOWN ,但在 DISTINCT 操作中,数据库系统普遍将其视为“相等”,以便实现可预测的去重行为。
测试案例:
CREATE TEMP TABLE test_nulls (
a INT,
b INT
);
INSERT INTO test_nulls VALUES
(1, NULL),
(1, NULL),
(NULL, 2),
(NULL, 2),
(NULL, NULL),
(NULL, NULL);
执行:
SELECT DISTINCT * FROM test_nulls;
预期结果(各数据库基本一致):
| a | b |
|---|---|
| 1 | NULL |
| NULL | 2 |
| NULL | NULL |
即:多个 (1, NULL) 合并为一条;两个 (NULL, NULL) 也被视为相同而合并。
这一行为看似合理,却隐藏风险。例如在客户联系方式清洗中:
SELECT DISTINCT phone, email FROM customers;
若某客户电话为空(NULL),邮箱也为空(NULL),则所有“无联系方式”的客户都将被压缩为一条记录,造成信息丢失。
解决方案建议 :
- 使用 COALESCE(phone, 'N/A') 将 NULL 替换为占位符后再去重;
- 或改用更精确的去重逻辑(如基于主键 + 条件判断)。
此外,注意不同数据库对 TEXT/BLOB/CLOB 类型字段是否支持 DISTINCT 存在差异。MySQL 允许对 TEXT 字段使用 DISTINCT ,但需启用特定模式;PostgreSQL 则要求字段可哈希。
2.2.2 在大数据集上使用DISTINCT带来的性能瓶颈
随着数据量增长, DISTINCT 的资源消耗呈非线性上升趋势。主要原因在于其底层依赖排序或哈希表构建,两者均受内存限制。
假设一张日志表包含 1 亿条记录,执行:
SELECT DISTINCT user_id, event_type FROM large_event_log;
数据库可能采取以下路径之一:
- 磁盘排序(External Sort) :当数据超出 work_mem 限制时,需写入临时文件并归并排序,I/O 成本极高。
- 哈希聚合(HashAgg) :建立哈希表存储每个唯一组合,若哈希冲突严重或内存不足,也会退化至磁盘操作。
可通过 EXPLAIN 观察实际执行计划:
EXPLAIN (BUFFERS, ANALYZE)
SELECT DISTINCT user_id, event_type FROM large_event_log;
关注指标包括:
- Peak Memory Usage :峰值内存占用;
- Temp File Read/Write :是否发生磁盘交换;
- Actual Rows vs Planned Rows :估算准确性。
优化策略包括:
1. 提前过滤 :通过 WHERE 减少输入规模;
2. 添加索引 :在 (user_id, event_type) 上建立复合索引,使扫描即可获取有序唯一数据;
3. 分批处理 :结合时间分区,逐日去重再汇总。
| 优化方法 | 适用场景 | 效果评估 |
|---|---|---|
| WHERE 过滤 | 存在明显筛选条件 | 减少90%以上数据量 |
| 覆盖索引 | 查询字段少且固定 | 提升5~10倍速度 |
| 分区裁剪 | 表按时间分区 | 仅扫描必要分区 |
2.2.3 替代方案探索:结合GROUP BY提升效率
在某些情况下, GROUP BY 可替代 DISTINCT 实现更灵活高效的去重。
语法对比:
-- 方法一:使用 DISTINCT
SELECT DISTINCT col1, col2 FROM tbl;
-- 方法二:使用 GROUP BY
SELECT col1, col2 FROM tbl GROUP BY col1, col2;
二者逻辑等价,但 GROUP BY 支持更多扩展功能,如附加聚合统计:
SELECT col1, col2, COUNT(*) AS dup_count
FROM tbl
GROUP BY col1, col2
HAVING COUNT(*) > 1;
可用于发现哪些组合是真正重复的。
更重要的是, GROUP BY 更易被优化器转化为流式聚合(Streaming Aggregation)或利用索引顺序扫描,减少中间存储压力。
性能实测对比示意表 (基于百万级数据)
| 查询方式 | 执行时间(s) | 内存使用(MB) | 是否可用索引 |
|---|---|---|---|
| DISTINCT | 18.7 | 1200 | 否 |
| GROUP BY | 9.3 | 600 | 是 |
| GROUP BY + 索引 | 2.1 | 100 | 是 |
可见,在合适索引支持下, GROUP BY 方案性能优势明显。
此外, GROUP BY 允许配合窗口函数、CTE等高级结构,便于构建复杂去重流水线。
2.3 典型案例分析与实践演练
理论知识需通过真实场景验证才能内化为技能。本节选取三个典型应用场景,演示如何正确运用 SELECT DISTINCT 解决实际问题,并结合执行计划评估成本。
2.3.1 用户访问日志中去除重复IP访问记录
目标:统计每日独立IP访问数,排除同一用户短时间内刷新页面造成的重复记录。
表结构:
CREATE TABLE access_log (
id BIGSERIAL PRIMARY KEY,
user_id INT,
ip_address INET,
page_url TEXT,
access_time TIMESTAMP
);
需求:获取某天每个用户的独立IP列表。
SELECT DISTINCT user_id, ip_address
FROM access_log
WHERE DATE(access_time) = '2024-04-05'
ORDER BY user_id;
逻辑分析 :
- DISTINCT (user_id, ip_address) 确保每个用户每IP仅出现一次;
- 时间过滤大幅缩小数据集;
- 结果可用于后续画像分析或风控建模。
参数说明 :
- INET 类型确保IP合法性;
- BIGSERIAL 主键不影响去重,因未选中。
建议在此类高频查询上建立索引:
CREATE INDEX idx_access_time_user_ip
ON access_log(access_time, user_id, ip_address);
支持高效时间裁剪与覆盖扫描。
2.3.2 商品目录查询结果去重展示
电商系统常面临SKU与SPU混淆问题。现有商品表:
CREATE TABLE products (
spu_id CHAR(13), -- 标准产品单元
sku_id CHAR(13), -- 库存单元
color VARCHAR(20),
size VARCHAR(10),
price DECIMAL(10,2)
);
前端需展示“所有款式颜色”,忽略尺码差异。
SELECT DISTINCT spu_id, color
FROM products
WHERE spu_id = 'ABC123XYZ';
返回该商品的所有颜色变体,避免因多种尺码导致颜色重复显示。
| spu_id | color |
|---|---|
| ABC123XYZ | Red |
| ABC123XYZ | Blue |
此查询简化了前端渲染逻辑,提升用户体验。
2.3.3 使用EXPLAIN评估DISTINCT查询成本
最后,必须养成使用执行计划工具的习惯。继续以上述商品查询为例:
EXPLAIN (ANALYZE, BUFFERS)
SELECT DISTINCT spu_id, color
FROM products
WHERE spu_id = 'ABC123XYZ';
输出示例:
Unique (cost=0.28..8.30 rows=1 width=64) actual time=0.030..0.032 rows=2 loops=1
-> Index Scan using idx_spu_id on products ...
Index Cond: (spu_id = 'ABC123XYZ'::bpchar)
说明:
- 使用了索引扫描,效率高;
- Unique 节点执行快速,仅耗时 0.03ms;
- 无临时文件或大量缓冲读取。
若未建索引,则可能出现 Seq Scan 和 HashAggregate ,性能下降百倍。
通过以上系统剖析,可以看出 SELECT DISTINCT 不仅是语法层面的操作,更是涉及执行策略、数据语义和性能调优的综合课题。合理使用,方能在保证数据准确的同时,维持系统的高效运转。
3. GROUP BY结合COUNT()识别并筛选重复数据
在现代数据库系统中,随着业务规模的扩大和数据采集渠道的多样化,数据重复问题日益普遍。虽然 SELECT DISTINCT 能够实现结果集的去重输出,但其仅适用于简单的查询场景,无法满足对重复数据进行 统计分析、定位原始记录或执行后续处理逻辑 的需求。此时, GROUP BY 配合聚合函数如 COUNT() 就成为更加强大且灵活的工具。本章将深入探讨如何利用分组机制精准识别重复数据,并在此基础上构建可扩展的数据清洗流程。
通过 GROUP BY 的分组能力与 HAVING 子句的条件过滤功能,我们不仅可以判断哪些字段组合存在重复,还能量化每组重复的数量,进而决定保留策略、生成审计报告或触发自动化清理任务。这种模式广泛应用于用户账户合并、日志去噪、主数据治理等高要求场景,是数据工程师必须掌握的核心技能之一。
3.1 GROUP BY去重原理与聚合函数协同机制
3.1.1 分组操作如何隐式消除重复组合
GROUP BY 是 SQL 中用于将具有相同值的行归为一组的关键字。尽管它本身并非专为“去重”设计,但在实际应用中, GROUP BY 常常起到 逻辑上去除重复组合 的作用。这是因为当多个行拥有相同的分组字段值时,它们会被压缩成一个单一的组,从而在结果集中只出现一次该组合。
例如,在一张用户登录日志表中,可能存在多条来自同一用户在同一日期的记录。若我们关心的是“每天有多少不同的用户登录”,则可以通过 GROUP BY user_id, login_date 来聚合数据,每个 (user_id, login_date) 组合只会产生一行输出。这本质上就是一种去重行为——即去除了时间戳精度更高(如秒级)带来的语义冗余。
SELECT user_id, login_date
FROM user_login_log
GROUP BY user_id, login_date;
代码解释 :
user_id: 用户唯一标识。login_date: 登录日期(通常由原始时间戳截断得到)。GROUP BY user_id, login_date: 按用户 ID 和登录日期进行分组。执行后,所有具有相同
user_id和login_date的记录被合并为一条输出,实现了基于业务粒度的去重。
该方式的优势在于不依赖于 DISTINCT ,而是通过结构化聚合来控制输出维度,便于后续添加统计信息(如登录次数)。相比而言, DISTINCT 更像是“黑盒式”去重,而 GROUP BY 提供了更强的可编程性和上下文感知能力。
此外, GROUP BY 支持多字段联合分组,允许定义复杂的重复判定规则。比如在会员系统中,可以使用 (email, phone) 作为组合键来检测潜在的重复注册;在订单系统中,则可用 (order_no, store_id) 确保跨门店订单编号唯一性。
值得注意的是, GROUP BY 不会自动去除物理层面的重复行,而是通过聚合过程实现逻辑上的合并。因此,要真正识别出“哪些组合是重复的”,还需引入聚合函数进行数量统计。
3.1.2 COUNT(*)与HAVING子句配合定位重复组
单纯地使用 GROUP BY 只能实现去重展示,但无法告诉我们哪些组合是真正“重复”的。为了精确识别出出现频次大于 1 的记录组,必须借助聚合函数 COUNT(*) 并结合 HAVING 子句进行条件筛选。
HAVING 是专门用于过滤分组结果的子句,类似于 WHERE 对原始行的过滤作用。但由于聚合发生在 GROUP BY 之后,普通 WHERE 无法访问 COUNT() 等聚合结果,因此必须使用 HAVING 。
下面是一个典型的查找重复邮箱地址的 SQL 示例:
SELECT email, COUNT(*) AS duplicate_count
FROM members
GROUP BY email
HAVING COUNT(*) > 1
ORDER BY duplicate_count DESC;
| 字段 | 含义 |
|---|---|
email |
会员邮箱地址 |
COUNT(*) |
每个邮箱地址出现的总次数 |
HAVING COUNT(*) > 1 |
过滤出至少有两个以上记录的邮箱 |
执行逻辑逐行分析 :
SELECT email, COUNT(*) AS duplicate_count: 查询目标字段为邮箱及其出现次数。FROM members: 数据来源为members表。GROUP BY email: 将所有记录按HAVING COUNT(*) > 1: 筛选出组内记录数大于 1 的分组,即存在重复。ORDER BY duplicate_count DESC: 按重复次数降序排列,便于优先处理高频重复项。
此查询的结果可用于生成 重复数据清单 ,供进一步人工审核或自动化清洗使用。例如,某电商平台发现某个邮箱对应 5 个不同用户名,可能意味着恶意刷单行为,需启动风控流程。
此外, COUNT(*) 的使用也支持更多变体优化。例如,若某些字段允许为空(NULL),直接计数可能导致误判。此时可改用 COUNT(email) 显式排除 NULL 值,因为 COUNT(列名) 仅统计非空值:
HAVING COUNT(email) > 1
这种方式更为严谨,尤其在数据质量较差的环境中尤为重要。
3.1.3 MAX/MIN函数辅助保留特定行数据
在识别出重复组之后,往往需要从中选择一条“代表行”予以保留,其余删除。这就涉及到 保留策略的选择 ,常见的包括保留最早创建的记录(最小 ID)、最新修改的记录(最大更新时间)或包含最完整信息的记录。
MAX() 和 MIN() 函数可以在 GROUP BY 查询中提取关键字段的极值,帮助确定候选保留行。以下示例展示了如何获取每个重复邮箱组中最小的 member_id :
SELECT
email,
MIN(member_id) AS keep_id,
COUNT(*) AS total_duplicates
FROM members
GROUP BY email
HAVING COUNT(*) > 1;
| keep_id | total_duplicates | |
|---|---|---|
| a@b.com | 1001 | 3 |
| c@d.com | 1005 | 2 |
参数说明 :
MIN(member_id): 返回每组中最小的主键值,通常被视为“最早插入”的记录。keep_id: 记录建议保留的member_id。total_duplicates: 用于评估清洗影响范围。
这个结果集可以直接作为“保留白名单”参与后续删除操作。例如,在第六章中介绍的自连接删除方法中,就可以依据此 keep_id 列构造删除条件。
不仅如此,还可以结合其他字段进行更精细判断。例如,如果希望优先保留电话号码不为空的记录,可以使用如下逻辑:
SELECT
email,
CASE
WHEN MAX(phone IS NOT NULL) = 1
THEN MIN(CASE WHEN phone IS NOT NULL THEN member_id END)
ELSE MIN(member_id)
END AS recommended_id
FROM members
GROUP BY email
HAVING COUNT(*) > 1;
上述查询使用了条件聚合技巧,优先选取带有有效联系方式的记录 ID,体现了 GROUP BY 与聚合函数深度协同的能力。
flowchart TD
A[原始数据表] --> B{是否按关键字段分组?}
B -- 是 --> C[执行 GROUP BY]
C --> D[计算 COUNT(*)]
D --> E{COUNT > 1?}
E -- 是 --> F[输出重复组及统计信息]
E -- 否 --> G[忽略非重复项]
F --> H[结合 MIN/MAX 确定保留行]
H --> I[生成清洗决策表]
该流程图清晰展示了从原始数据到生成保留建议的完整路径,突出了 GROUP BY 在数据治理中的核心地位。
3.2 基于分组结果的进一步处理方法
3.2.1 提取每组首条记录用于去重输出
在完成重复组识别后,下一步通常是生成一份“干净”的去重数据集。虽然可以直接返回 GROUP BY 结果,但这只能获得分组字段,丢失了原始表中的其他属性(如姓名、注册时间等)。为此,我们需要一种机制来 从每组中提取完整的一条记录 。
常用做法是利用窗口函数或子查询关联,但在不支持窗口函数的老版本数据库中,可通过 JOIN + GROUP BY 实现等效效果。
假设我们有一个会员表 members ,结构如下:
| member_id | name | phone | created_at | |
|---|---|---|---|---|
| 1001 | 张三 | zhang@example.com | 13800138001 | 2023-01-01 |
| 1002 | 李四 | zhang@example.com | NULL | 2023-01-02 |
我们的目标是从每个重复邮箱组中提取 member_id 最小的那条完整记录。
WITH dedup_candidates AS (
SELECT
email,
MIN(member_id) AS min_id
FROM members
GROUP BY email
HAVING COUNT(*) > 1
)
SELECT m.*
FROM members m
INNER JOIN dedup_candidates dc
ON m.member_id = dc.min_id;
代码逻辑逐行解读 :
WITH dedup_candidates: 定义 CTE,先找出每个重复邮箱对应的最小member_id。GROUP BY email HAVING COUNT(*) > 1: 筛选重复邮箱组。INNER JOIN: 将原表与候选 ID 表连接,仅保留匹配成功的行。m.*: 输出整条记录,包含姓名、电话等完整字段。
这种方法确保了输出的每条记录都是“去重后的代表行”,可用于导出、备份或加载至新表。
3.2.2 构建中间视图完成重复数据过滤
对于频繁使用的去重逻辑,建议将其封装为 数据库视图(View) 或临时表,以提升复用性和可维护性。视图不仅能简化复杂查询,还能隐藏底层实现细节,提供统一的数据访问接口。
以下是一个创建去重视图的示例:
CREATE VIEW members_deduplicated AS
SELECT *
FROM members
WHERE member_id IN (
SELECT MIN(member_id)
FROM members
GROUP BY email
HAVING COUNT(*) >= 1 -- 包括非重复项
);
参数说明 :
CREATE VIEW: 创建命名视图,可供后续查询引用。- 子查询部分:对每个
member_id,无论是否重复。- 外层
WHERE member_id IN (...): 保证最终结果集中每封邮箱仅出现一次。
该视图的效果相当于对 members 表进行了全局去重,保留每个邮箱最早注册的用户。即使未来新增重复数据,只要重新查询视图即可获得最新状态。
此外,还可通过索引优化性能。例如,在 email 字段上建立索引:
CREATE INDEX idx_members_email ON members(email);
这样 GROUP BY email 的执行效率将显著提升,尤其是在百万级以上数据量时。
| 优化手段 | 效果 |
|---|---|
| 建立 email 索引 | 加速分组与连接操作 |
| 使用覆盖索引 | 减少回表次数 |
| 分区表按时间切片 | 缩小扫描范围 |
3.2.3 联合子查询实现原始数据精确定位
有时不仅需要知道哪些数据重复,还需要 定位所有属于重复组的原始记录 ,以便进行标记、告警或批量处理。
此时可使用嵌套子查询的方式,先找出重复的 email 列表,再返回这些邮箱对应的所有行:
SELECT *
FROM members
WHERE email IN (
SELECT email
FROM members
GROUP BY email
HAVING COUNT(*) > 1
)
ORDER BY email, member_id;
执行逻辑分析 :
- 内层子查询:列出所有出现次数大于 1 的邮箱。
- 外层查询:筛选出这些邮箱对应的所有原始记录。
ORDER BY email, member_id: 便于人工查看时识别连续重复块。
该查询输出的是完整的重复数据集合,适合用于生成待审核列表或导入 ETL 工具进行深度分析。
为进一步增强可读性,可增加一列标记字段:
SELECT
*,
'DUPLICATE' AS flag
FROM members
WHERE email IN (
SELECT email
FROM members
GROUP BY email
HAVING COUNT(*) > 1
);
这样在下游系统中就能快速识别异常数据。
graph LR
Raw[原始数据表] --> SubQuery[子查询: 找出重复email]
SubQuery --> Filter[外层查询过滤匹配行]
Filter --> Output((输出全部重复记录))
该流程图描述了联合子查询的执行路径,强调了内外查询之间的依赖关系。
3.3 实战项目:会员信息表中的邮箱冲突检测
3.3.1 编写SQL脚本查找重复邮箱账户
在一个真实的会员管理系统中,邮箱通常作为用户登录凭证。若允许多个账号使用同一邮箱,会导致登录混乱、密码重置失败等问题。因此,定期检测并清理邮箱冲突至关重要。
以下是完整的 SQL 脚本,用于查找并报告重复邮箱账户:
-- Step 1: 查找所有重复邮箱及其出现次数
SELECT
email,
COUNT(*) AS occurrence_count,
STRING_AGG(name, ', ') AS associated_names,
MIN(member_id) AS recommended_keep_id
INTO #duplicate_report_temp
FROM members
WHERE email IS NOT NULL
GROUP BY email
HAVING COUNT(*) > 1;
-- Step 2: 输出报告
SELECT * FROM #duplicate_report_temp
ORDER BY occurrence_count DESC;
参数说明 :
STRING_AGG(name, ', '): 将同邮箱关联的所有用户名拼接成字符串,便于审查。INTO #duplicate_report_temp: 创建本地临时表存储中间结果(适用于 SQL Server/PostgreSQL)。WHERE email IS NOT NULL: 排除空值干扰,避免误报。
该脚本不仅识别出重复邮箱,还汇总了相关用户姓名和建议保留 ID,极大提升了运维效率。
3.3.2 统计各重复组的数量分布情况
为进一步了解重复数据的严重程度,应进行分布分析。例如:有多少邮箱重复 2 次?3 次?甚至超过 5 次?
SELECT
occurrence_count,
COUNT(*) AS group_count,
SUM(occurrence_count) AS total_affected_records
FROM (
SELECT
email,
COUNT(*) AS occurrence_count
FROM members
WHERE email IS NOT NULL
GROUP BY email
HAVING COUNT(*) > 1
) t
GROUP BY occurrence_count
ORDER BY occurrence_count;
| occurrence_count | group_count | total_affected_records |
|---|---|---|
| 2 | 15 | 30 |
| 3 | 6 | 18 |
| 4 | 2 | 8 |
逻辑分析 :
- 内层查询:获取每个重复邮箱的出现次数。
- 外层
GROUP BY occurrence_count: 按重复频次再次分组。COUNT(*): 统计有多少个这样的“重复组”。SUM(...): 计算受影响的总记录数。
此类统计有助于制定分级处理策略。例如,对重复 2 次的自动合并,超过 3 次的转交人工处理。
3.3.3 输出建议清理名单供人工审核
最后一步是生成可交付的清洗建议表,供客服或数据治理团队参考。
-- 创建正式报告表
CREATE TABLE deduplication_recommendations (
email VARCHAR(255),
keep_member_id INT,
remove_member_ids TEXT,
conflict_level VARCHAR(10),
review_status VARCHAR(20) DEFAULT 'Pending'
);
-- 插入建议
INSERT INTO deduplication_recommendations (email, keep_member_id, remove_member_ids, conflict_level)
SELECT
email,
MIN(member_id) AS keep_id,
STRING_AGG(member_id::TEXT, ',' ORDER BY member_id) FILTER (WHERE member_id != MIN(member_id)) AS remove_ids,
CASE
WHEN COUNT(*) = 2 THEN 'Low'
WHEN COUNT(*) BETWEEN 3 AND 4 THEN 'Medium'
ELSE 'High'
END AS conflict_level
FROM members
WHERE email IN (
SELECT email FROM members GROUP BY email HAVING COUNT(*) > 1
)
GROUP BY email;
扩展说明 :
FILTER (WHERE ...): PostgreSQL 特有语法,用于排除保留 ID。conflict_level: 根据重复数量划分风险等级。review_status: 支持后续跟踪处理进度。
该表可集成至 BI 系统或审批平台,形成闭环管理流程。
pie
title 重复邮箱冲突等级分布
“Low (2次)” : 15
“Medium (3-4次)” : 8
“High (≥5次)” : 3
该饼图直观展示了各类冲突的比例,助力管理层决策资源分配。
4. CTE(Common Table Expression)实现复杂去重查询
在现代SQL开发中,随着数据源的多样化与业务逻辑的日益复杂,传统的单层 SELECT DISTINCT 或简单的 GROUP BY 已难以满足多阶段、条件化、结构化去重的需求。此时, 公共表表达式(Common Table Expression, CTE) 成为了处理复杂去重任务的关键技术手段。CTE不仅提升了SQL语句的可读性与模块化程度,更重要的是它允许开发者将一个复杂的去重流程拆解为多个逻辑清晰的步骤,每一步都可以独立调试和优化,从而显著提高数据清洗的准确性和执行效率。
相较于子查询嵌套带来的“括号地狱”,CTE通过 WITH 关键字定义命名的临时结果集,使得整个查询结构更接近自然语言流程。尤其在涉及重复数据识别、优先级保留策略选择以及跨表/分区合并等场景下,CTE展现出强大的灵活性和控制力。例如,在用户行为分析系统中,可能需要从多个时间分区的日志表中提取登录记录,并基于用户ID进行去重,同时保留最近一次活动的数据;又如在客户主数据管理(MDM)项目中,需对来自CRM、ERP和客服系统的客户信息进行融合去重,依据字段完整性、更新时间等因素决定最终保留哪条记录——这些需求均可借助CTE分步建模实现。
本章将深入剖析CTE的技术内核及其在去重场景中的工程化应用路径。我们将首先解析CTE的基础语法结构与作用域特性,明确其与传统子查询的本质区别;然后构建一个多步骤去重流程,展示如何利用CTE串联 GROUP BY 、关联原表、过滤非优行等操作;最后拓展至高级应用场景,涵盖跨时间段数据合并、格式标准化与一致性视图输出,全面体现CTE在企业级数据治理中的核心价值。
4.1 CTE基础语法与作用域特性
CTE是SQL标准中定义的一种临时命名结果集,其生命周期仅限于紧随其后的单个DML语句(如 SELECT 、 INSERT 、 UPDATE 或 DELETE )。它的引入极大增强了SQL的表达能力,特别是在处理递归结构(如组织架构树)或多步骤计算任务时表现尤为突出。在去重领域,非递归CTE被广泛用于构建中间状态集,实现逻辑分层,避免冗余扫描。
4.1.1 WITH语句定义临时命名结果集
CTE的基本语法由 WITH 关键字引导,后接一个或多个命名的结果集定义,每个定义包含名称、列名(可选)和 AS 引导的查询语句块。其通用结构如下:
WITH cte_name [(column1, column2, ...)] AS (
-- 查询语句
SELECT ...
)
-- 主查询使用CTE
SELECT * FROM cte_name;
下面是一个典型示例:假设有一个用户登录日志表 user_login_log ,存在因网络重试导致的重复记录,我们希望基于 user_id 和 login_date 去重,并统计每日唯一登录人数。
WITH deduplicated_log AS (
SELECT
user_id,
CAST(login_time AS DATE) AS login_date,
MIN(login_time) AS first_login -- 保留最早登录时间
FROM user_login_log
GROUP BY user_id, CAST(login_time AS DATE)
),
daily_stats AS (
SELECT
login_date,
COUNT(*) AS unique_logins
FROM deduplicated_log
GROUP BY login_date
)
SELECT * FROM daily_stats
ORDER BY login_date;
代码逻辑逐行解读:
- 第1–8行 :定义第一个CTE
deduplicated_log,通过GROUP BY user_id和日期截断实现初步去重,MIN(login_time)确保每用户每天只保留首次登录记录。 - 第9–14行 :第二个CTE
daily_stats对去重后的数据按天聚合,计算每日独立登录数。 - 第15–16行 :主查询调用
daily_stats并排序输出。
参数说明与扩展分析:
| 参数 | 含义 | 注意事项 |
|---|---|---|
CAST(... AS DATE) |
时间戳转日期 | 确保比较在同一日粒度 |
MIN(login_time) |
选取最早登录时间 | 可替换为 MAX 以保留最后一次 |
GROUP BY |
分组键必须覆盖所有非聚合字段 | 否则会报错 |
该结构体现了CTE的 链式处理能力 :前一个CTE的结果可被后续CTE引用,形成流水线式的数据加工过程。这种模式比嵌套子查询更易维护,且数据库优化器通常能将其展开为高效执行计划。
此外,CTE支持列别名显式声明,增强语义清晰度:
WITH user_summary (uid, log_date, first_time) AS (
SELECT
user_id,
CAST(login_time AS DATE),
MIN(login_time)
FROM user_login_log
GROUP BY user_id, CAST(login_time AS DATE)
)
SELECT uid, log_date FROM user_summary;
这种方式明确指定了CTE输出列名,有助于团队协作理解。
4.1.2 递归CTE与非递归CTE的区别
虽然去重任务多采用非递归CTE,但理解两者差异对于掌握CTE全貌至关重要。
| 特性 | 非递归CTE | 递归CTE |
|---|---|---|
| 定义方式 | 单次查询生成结果 | 包含锚点查询 + 递归成员 |
| 执行模型 | 一次性求值 | 迭代执行直至收敛 |
| 典型用途 | 数据清洗、中间汇总 | 层级遍历(如员工上下级) |
| 性能特征 | 类似视图展开 | 易产生性能瓶颈 |
| SQL标准要求 | 所有主流数据库支持 | 需启用递归选项(如PostgreSQL默认开启) |
递归CTE语法结构如下:
WITH RECURSIVE org_tree AS (
-- 锚点:根节点
SELECT employee_id, manager_id, name, 1 AS level
FROM employees
WHERE manager_id IS NULL
UNION ALL
-- 递归成员:子节点
SELECT e.employee_id, e.manager_id, e.name, ot.level + 1
FROM employees e
INNER JOIN org_tree ot ON e.manager_id = ot.employee_id
)
SELECT * FROM org_tree;
尽管此例不涉及去重,但它展示了递归机制的工作原理。而在去重场景中,若需处理具有层级关系的重复实体(如父子账户合并),递归CTE可作为辅助工具识别关联重复组。
值得注意的是, 递归CTE不能直接用于常规去重 ,因其设计目标并非消除重复行,而是探索图结构。相反,非递归CTE才是去重主力。
4.1.3 CTE在执行顺序中的位置优势
CTE的一个关键优势在于其 逻辑执行优先于主查询 ,这意味着它可以预先完成繁重的数据预处理工作,为主查询提供干净输入。这一点在执行计划层面尤为重要。
考虑以下Mermaid流程图,描述CTE的执行时序:
flowchart TD
A[开始执行] --> B{解析WITH子句}
B --> C[执行CTE查询]
C --> D[生成临时结果集]
D --> E[主查询引用CTE]
E --> F[执行JOIN/GROUP BY等操作]
F --> G[返回最终结果]
该流程表明,CTE并非延迟求值,而是 立即执行并缓存结果 (具体实现依赖数据库引擎)。例如:
- 在 PostgreSQL 中,CTE 默认会被物化(materialized),即先执行并存储结果;
- 在 SQL Server 中,优化器可能选择内联展开(inlining)以提升性能;
- 在 MySQL 8.0+ 中,CTE 支持递归,且非递归CTE通常被优化为派生表。
因此,在编写CTE时应关注数据库特性。例如,在PostgreSQL中过度使用CTE可能导致不必要的物化开销,而本可通过内联提升性能。此时可通过 NOT MATERIALIZED 提示(v12+)控制行为:
WITH frequent_users AS NOT MATERIALIZED (
SELECT user_id
FROM user_actions
GROUP BY user_id
HAVING COUNT(*) > 100
)
SELECT u.name, fu.user_id
FROM users u
JOIN frequent_users fu ON u.id = fu.user_id;
综上所述,CTE不仅是语法糖,更是影响执行路径的重要组件。合理运用其作用域与执行顺序特性,可在去重中实现性能与可读性的双赢。
4.2 利用CTE进行多步骤去重流程设计
面对真实世界的数据质量问题,单一去重方法往往力不从心。常见挑战包括:原始表缺乏主键、需保留特定属性(如最新更新时间)、需结合外部规则判断优劣记录等。此时,采用CTE构建多步骤流水线成为最佳实践。
4.2.1 第一步:通过GROUP BY生成去重基准集
去重的第一步通常是确定“什么是重复”。这依赖于业务规则定义的 唯一标识组合 ,如 (user_id, session_id) 、 (product_code, supplier_id) 等。在此基础上,使用 GROUP BY 生成候选键集合。
假设表 customer_dup 包含潜在重复客户记录:
CREATE TABLE customer_dup (
id INT PRIMARY KEY AUTO_INCREMENT,
phone VARCHAR(20),
email VARCHAR(100),
name VARCHAR(50),
updated_at DATETIME
);
我们定义“重复”为手机号与邮箱完全一致的记录。第一步构建CTE找出所有重复组合:
WITH duplicate_keys AS (
SELECT
phone,
email
FROM customer_dup
GROUP BY phone, email
HAVING COUNT(*) > 1
)
SELECT * FROM duplicate_keys;
此查询列出所有出现多次的联系方式组合,为下一步精准定位原始记录奠定基础。
4.2.2 第二步:关联原表获取完整字段信息
仅有键值无法执行删除或展示操作,必须还原完整记录。通过INNER JOIN将 duplicate_keys 与原表连接,提取所有重复条目:
WITH duplicate_keys AS (
SELECT phone, email
FROM customer_dup
GROUP BY phone, email
HAVING COUNT(*) > 1
),
full_duplicates AS (
SELECT cd.*
FROM customer_dup cd
INNER JOIN duplicate_keys dk
ON cd.phone = dk.phone AND cd.email = dk.email
)
SELECT * FROM full_duplicates
ORDER BY phone, email, updated_at DESC;
此时结果集中包含了所有重复组的完整行信息,便于进一步分析。
为进一步提升实用性,可添加重复计数:
WITH duplicate_keys AS (
SELECT phone, email, COUNT(*) as dup_count
FROM customer_dup
GROUP BY phone, email
HAVING COUNT(*) > 1
),
annotated_records AS (
SELECT
cd.*,
dk.dup_count,
ROW_NUMBER() OVER (
PARTITION BY cd.phone, cd.email
ORDER BY cd.updated_at DESC
) AS rn
FROM customer_dup cd
INNER JOIN duplicate_keys dk
ON cd.phone = dk.phone AND cd.email = dk.email
)
SELECT * FROM annotated_records;
新增 ROW_NUMBER() 用于标记每组内的排序编号,为后续筛选做准备。
4.2.3 第三步:排除重复项中非优先保留行
最终目标是仅保留每组中最优记录(如最新更新者),其余标记为待删。继续扩展CTE链:
WITH duplicate_keys AS (
SELECT phone, email
FROM customer_dup
GROUP BY phone, email
HAVING COUNT(*) > 1
),
full_duplicates AS (
SELECT cd.*
FROM customer_dup cd
INNER JOIN duplicate_keys dk
ON cd.phone = dk.phone AND cd.email = dk.email
),
ranked_duplicates AS (
SELECT *,
ROW_NUMBER() OVER (
PARTITION BY phone, email
ORDER BY updated_at DESC, id ASC
) AS rn
FROM full_duplicates
)
-- 查看建议保留的记录
SELECT *
FROM ranked_duplicates
WHERE rn = 1;
-- 或查看应删除的记录
SELECT *
FROM ranked_duplicates
WHERE rn > 1;
参数说明:
| 字段 | 含义 | 排序优先级说明 |
|---|---|---|
updated_at DESC |
优先保留最新更新 | 反映数据新鲜度 |
id ASC |
相同时间取最小ID | 防止不确定性 |
该策略确保去重决策具备可重复性与业务合理性。
以下表格总结该三步法的核心组件:
| 步骤 | 目标 | 使用技术 | 输出形式 |
|---|---|---|---|
| 1 | 识别重复键 | GROUP BY + HAVING | 唯一组合列表 |
| 2 | 提取完整记录 | INNER JOIN | 所有重复行 |
| 3 | 标记优先级 | ROW_NUMBER() | 行号标注结果 |
此方法已在金融客户整合、电商平台会员去重中广泛应用,具备高度可移植性。
4.3 高级应用:跨时间段数据合并去重
在大数据平台中,数据常按时间分区存储(如按月分表)。当需要生成全局去重视图时,必须统一各分区数据并消除跨期重复。
4.3.1 合并多个分区表中的用户登录记录
假设有三个表: login_log_202401 , login_log_202402 , login_log_202403 ,结构相同:
CREATE TABLE login_log_202401 (
user_id INT,
device_id VARCHAR(50),
ip_address VARCHAR(45),
login_time DATETIME
);
目标:生成全季度唯一用户设备组合视图,避免同一用户在不同月份被重复统计。
WITH unified_data AS (
SELECT user_id, device_id, ip_address, login_time, '2024-01' AS source_month
FROM login_log_202401
UNION ALL
SELECT user_id, device_id, ip_address, login_time, '2024-02'
FROM login_log_202402
UNION ALL
SELECT user_id, device_id, ip_address, login_time, '2024-03'
FROM login_log_202403
),
dedup_basis AS (
SELECT
user_id,
device_id,
MIN(login_time) AS first_seen
FROM unified_data
GROUP BY user_id, device_id
HAVING COUNT(*) >= 1 -- 实际无需HAVING,此处强调逻辑完整性
)
SELECT
ud.user_id,
ud.device_id,
ud.ip_address,
ud.login_time,
ud.source_month
FROM unified_data ud
INNER JOIN dedup_basis db
ON ud.user_id = db.user_id
AND ud.device_id = db.device_id
AND ud.login_time = db.first_seen;
此查询实现了跨表去重,保留每个用户-设备组合的首次出现记录。
4.3.2 使用CTE统一格式化并去重
进一步地,可加入数据清洗逻辑。例如,IP地址可能存在大小写或空格问题:
WITH cleaned_logs AS (
SELECT
user_id,
UPPER(TRIM(device_id)) AS device_id,
TRIM(LOWER(ip_address)) AS ip_address,
login_time,
source_table
FROM (
SELECT user_id, device_id, ip_address, login_time, 'Jan' AS source_table
FROM login_log_202401
UNION ALL
SELECT user_id, device_id, ip_address, login_time, 'Feb'
FROM login_log_202402
) raw_union
),
ranked_by_first AS (
SELECT *,
ROW_NUMBER() OVER (
PARTITION BY user_id, device_id
ORDER BY login_time ASC
) AS rn
FROM cleaned_logs
)
SELECT
user_id, device_id, ip_address, login_time
FROM ranked_by_first
WHERE rn = 1;
UPPER 、 TRIM 、 LOWER 确保字段标准化,防止因格式差异造成误判重复。
4.3.3 输出最终一致视图供下游系统调用
最终可创建视图封装逻辑:
CREATE VIEW vw_unique_user_device AS
WITH unified_clean AS (
-- 如上清洗与合并逻辑
),
final_dedup AS (
SELECT *,
ROW_NUMBER() OVER (PARTITION BY user_id, device_id ORDER BY login_time) AS rn
FROM unified_clean
)
SELECT user_id, device_id, ip_address, login_time
FROM final_dedup
WHERE rn = 1;
下游报表、机器学习模型可直接查询 vw_unique_user_device ,无需关心底层去重细节。
综上,CTE不仅是一种语法结构,更是一种 数据工程思维的体现 :将复杂问题分解为有序步骤,层层推进,最终达成精确控制。在去重这一高频任务中,其价值尤为凸显。
5. 临时表方式存储去重后数据
在大规模数据处理场景中,去重操作往往不是一次性查询即可完成的简单任务。面对海量、异构或频繁更新的数据源,如何高效地将清洗后的结果进行暂存、流转与再利用,成为保障后续分析流程稳定运行的关键环节。 临时表 作为一种轻量级、可控制生命周期的数据库对象,在SQL去重工程实践中扮演着重要角色。它不仅能够作为中间计算结果的“缓冲区”,还能有效解耦原始数据与目标输出之间的直接依赖关系,提升整体脚本的可维护性与执行效率。
本章将深入探讨临时表在去重流程中的核心作用机制,涵盖其创建方式、生命周期管理策略以及与主流RDBMS(如MySQL、PostgreSQL、SQL Server)的兼容性差异。通过对比本地临时表与全局临时表的应用边界,并结合索引优化手段,展示如何构建高性能的去重中间层。进一步地,还将介绍如何将去重结果持久化至中间表以支持长期调度任务,并设计自动化清洗流水线,实现企业级数据治理的标准化落地。
5.1 临时表的创建与生命周期管理
临时表是数据库系统为会话或事务级别临时存储中间数据而提供的特殊表类型。与普通永久表不同,临时表通常不参与常规备份、日志归档,且在特定条件下自动销毁,从而避免占用不必要的空间资源。在复杂的多步骤去重逻辑中,使用临时表可以显著降低主表锁定时间,减少对生产环境的影响。
5.1.1 本地临时表与全局临时表的区别
根据作用域的不同,临时表可分为 本地临时表(Local Temporary Table) 和 全局临时表(Global Temporary Table) 。两者的核心区别在于可见性和生命周期控制机制。
| 特性 | 本地临时表 | 全局临时表 |
|---|---|---|
| 创建语法示例 | CREATE TEMPORARY TABLE tmp_users (...) |
CREATE GLOBAL TEMPORARY TABLE gtt_users (...) ON COMMIT PRESERVE ROWS |
| 可见范围 | 仅当前会话可见 | 所有会话共享结构,数据隔离 |
| 生命周期 | 会话结束时自动删除 | 依配置决定:会话级或连接级清除 |
| 存储位置 | 内存或临时表空间 | 通常位于专用临时表空间 |
| 典型数据库支持 | MySQL, PostgreSQL, SQL Server | Oracle, DB2, PostgreSQL(模拟) |
说明 :MySQL 使用
TEMPORARY关键字创建本地临时表;Oracle 支持真正的全局临时表;PostgreSQL 虽无原生GTT,但可通过UNLOGGED表 + 显式清理模拟类似行为。
-- 示例:在 PostgreSQL 中创建本地临时表用于去重中间结果
CREATE TEMPORARY TABLE tmp_distinct_logins AS
SELECT user_id, login_date::date, MIN(login_time) AS first_login
FROM user_activity_log
GROUP BY user_id, login_date::date;
代码逻辑逐行解析:
- 第1行 :
CREATE TEMPORARY TABLE定义一个仅在当前会话中可见的临时表。 - 第2行 :选择用户ID与登录日期(按天聚合),并保留最早一次登录时间。
- 第3行 :通过
GROUP BY实现基于用户+日期维度的去重,确保每人每天只有一条记录。 - 整个语句使用
AS直接从查询结果填充临时表内容,适用于一次性批处理任务。
该结构常用于ETL预处理阶段,避免反复扫描原始大表。由于临时表不会被其他会话干扰,适合高并发环境下独立运行的清洗作业。
5.1.2 自动释放机制与手动清理规范
临时表的生命终结方式由数据库引擎决定,但也允许开发者主动干预。合理管理生命周期有助于防止内存泄漏或元数据堆积。
不同数据库的自动释放规则:
graph TD
A[开始会话] --> B{创建临时表}
B --> C[插入去重数据]
C --> D[执行JOIN或其他操作]
D --> E{会话是否关闭?}
E -->|是| F[自动删除临时表]
E -->|否| G[显式DROP TABLE]
G --> H[释放资源]
上述流程图展示了典型的临时表使用生命周期。在大多数系统中,当客户端断开连接时,所有属于该会话的本地临时表会被自动清除。然而,在长时间运行的服务(如Python脚本通过连接池访问数据库)中,这种机制可能失效——连接未真正关闭,导致临时表持续存在。
因此,最佳实践建议:
-- 显式清理临时表(推荐做法)
DROP TABLE IF EXISTS tmp_distinct_logins;
此语句应置于脚本末尾或异常处理块中,确保无论成功与否都能释放资源。对于全局临时表(如Oracle GTT),虽然结构保留,但数据默认在每次提交后清除(若定义为 ON COMMIT DELETE ROWS ),需注意是否启用 PRESERVE ROWS 模式。
此外,某些系统(如SQL Server)还支持 表变量 ( @table_variable ),其生命周期更短(限于批处理内),更适合小规模中间集。
5.1.3 索引添加提升后续查询效率
尽管临时表具有自动清理优势,但若涉及大量数据或多步关联操作,缺乏索引会导致性能急剧下降。为此,应在数据写入完成后立即建立必要索引。
-- 为临时表添加复合索引以加速后续JOIN操作
CREATE INDEX idx_tmp_user_date ON tmp_distinct_logins (user_id, login_date);
参数说明与优化建议:
- idx_tmp_user_date :命名遵循前缀规范,便于识别为临时对象。
- (user_id, login_date) :组合字段覆盖常见查询条件,符合最左匹配原则。
- 若仅用于单字段过滤(如
WHERE user_id = ?),可考虑单独建索引。 - 对于超大数据集(>100万行),建议启用统计信息收集:
ANALYZE tmp_distinct_logins; -- PostgreSQL
UPDATE STATISTICS tmp_distinct_logins; -- SQL Server
此举帮助查询优化器生成更高效的执行计划,尤其是在与主表联查时避免全表扫描。
综上,临时表不仅是去重中转站,更是性能调优的重要抓手。正确使用其作用域、生命周期控制及索引策略,能大幅提升复杂SQL流程的稳定性与响应速度。
5.2 将去重结果持久化到中间表
虽然临时表适用于短期中间计算,但在需要跨会话共享、定期更新或供下游系统调用的场景下,必须将去重成果 持久化 到正式的中间表中。这类表通常命名为 dim_* , fact_* , 或 stg_* 前缀,体现其在数据仓库架构中的定位。
5.2.1 SELECT INTO创建新表并插入去重数据
SELECT INTO 是一种简洁高效的语法,能够在一条语句中完成 建表+插入 两个动作,特别适用于首次初始化中间表结构。
-- SQL Server / PostgreSQL 示例
SELECT user_id, email, MAX(created_at) AS last_seen
INTO stg_clean_users
FROM raw_user_data
GROUP BY user_id, email;
执行逻辑分析:
- SELECT 子句 :提取关键字段,使用
MAX(created_at)获取最新记录时间。 - INTO stg_clean_users :创建新表,字段类型自动继承源列。
- GROUP BY :实现基于用户ID和邮箱的去重,消除重复注册记录。
⚠️ 注意:MySQL 不支持
SELECT ... INTO外部表(除INTO OUTFILE),需拆分为两步操作。
该方法的优点在于无需预先定义表结构,适合快速原型开发。但缺点也明显:无法精确控制字段约束(如NOT NULL、PK)、字符集或存储引擎,不利于后期集成。
5.2.2 INSERT INTO … SELECT模式的安全迁移
为了实现更高可控性的数据迁移,推荐采用先建表、后填充的分离式方案:
-- 第一步:显式创建目标中间表
CREATE TABLE stg_clean_users (
user_id BIGINT PRIMARY KEY,
email VARCHAR(255) NOT NULL,
last_seen TIMESTAMP,
source_system VARCHAR(50),
INDEX idx_email (email)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
-- 第二步:安全插入去重数据
INSERT INTO stg_clean_users (user_id, email, last_seen, source_system)
SELECT
user_id,
email,
MAX(created_at),
'CRM_IMPORT'
FROM raw_user_data
WHERE status = 'active'
GROUP BY user_id, email
ON DUPLICATE KEY UPDATE
last_seen = GREATEST(stg_clean_users.last_seen, VALUES(last_seen)),
source_system = 'CRM_IMPORT';
代码逻辑逐行解读:
- CREATE TABLE 部分明确定义了主键、索引、编码等属性,增强数据一致性。
- INSERT INTO … SELECT 实现增量加载,配合
WHERE条件过滤无效状态。 - GROUP BY 确保每用户-邮箱组合唯一。
- ON DUPLICATE KEY UPDATE 处理潜在冲突(如已有记录),实现“合并更新”而非报错中断。
此模式广泛应用于OLAP系统的每日同步任务中,具备良好的容错性与扩展性。
5.2.3 表结构一致性校验与字段映射检查
在长期维护过程中,源表结构可能发生变更(如新增字段、修改类型),若中间表未同步更新,将引发数据丢失或转换错误。为此,应建立结构比对机制。
| 校验项 | 检查方法 | 工具/语句 |
|---|---|---|
| 字段数量是否一致 | 查询INFORMATION_SCHEMA.COLUMNS | SELECT COUNT(*) FROM ... WHERE table_name IN ('src', 'tgt') |
| 数据类型兼容性 | 比较data_type、character_maximum_length | 自定义脚本对比 |
| 是否存在缺失映射字段 | LEFT JOIN 元数据表 | SELECT src_col FROM src_meta LEFT JOIN map_table... |
| 默认值与约束匹配 | 检查is_nullable、column_default | SQL元数据查询 |
例如,在PostgreSQL中可通过以下查询检测字段差异:
SELECT
column_name,
data_type,
is_nullable
FROM information_schema.columns
WHERE table_name = 'raw_user_data'
EXCEPT
SELECT
column_name,
data_type,
is_nullable
FROM information_schema.columns
WHERE table_name = 'stg_clean_users';
返回结果即为源表中有而目标表缺失或不一致的字段,可用于触发告警或自动调整DDL。
5.3 应用场景:批量数据清洗任务自动化
在实际生产环境中,去重并非孤立操作,而是嵌入在整个数据管道中的标准环节。借助临时表与中间表的协同机制,可构建全自动化的批量清洗系统,显著降低人工干预成本。
5.3.1 定期执行去重脚本更新汇总表
设想某电商平台需每日凌晨生成一份“去重活跃用户”快照,供BI团队分析趋势。流程如下:
-- daily_dedup_user_snapshot.sql
BEGIN;
-- 步骤1:创建临时表存放去重结果
CREATE TEMPORARY TABLE tmp_active_users AS
SELECT DISTINCT user_id, device_id, ip_address
FROM user_event_log
WHERE event_date = CURRENT_DATE - INTERVAL '1 day';
-- 步骤2:合并至每日快照表
INSERT INTO dws_user_daily_snapshot (user_id, device_id, ip_address, snapshot_date)
SELECT user_id, device_id, ip_address, CURRENT_DATE - INTERVAL '1 day'
FROM tmp_active_users
ON CONFLICT (user_id, snapshot_date) DO NOTHING;
-- 步骤3:记录影响行数
INSERT INTO etl_monitor_log(job_name, affected_rows, run_time)
VALUES ('daily_user_dedup', (SELECT COUNT(*) FROM tmp_active_users), NOW());
COMMIT;
流程说明:
- 使用事务包裹整个流程,确保原子性。
ON CONFLICT ... DO NOTHING防止重复插入。- 日志表记录每次执行的影响行数,便于监控异常波动。
5.3.2 搭配调度工具实现无人值守运行
上述脚本可通过定时任务调度器(如cron、Airflow、Quartz)自动触发:
# Linux crontab 示例:每天00:15执行
15 0 * * * /usr/bin/psql -U analytics -d marketing_db -f /scripts/daily_dedup_user_snapshot.sql >> /var/log/etl.log 2>&1
在Airflow DAG中则可定义依赖关系与重试策略:
from airflow import DAG
from airflow.operators.bash import BashOperator
from datetime import datetime, timedelta
dag = DAG(
'daily_user_dedup',
default_args={'retries': 3},
schedule_interval='15 0 * * *',
start_date=datetime(2024, 1, 1)
)
run_dedup = BashOperator(
task_id='execute_dedup_script',
bash_command='psql -U analytics -d marketing_db -f /scripts/daily_dedup_user_snapshot.sql',
dag=dag
)
5.3.3 监控日志记录每次去重影响行数
为及时发现数据异常(如某天突然出现百万级去重记录),应建立监控指标体系:
-- 查询最近7天去重影响趋势
SELECT
snapshot_date,
COUNT(*) AS unique_users,
LAG(COUNT(*)) OVER (ORDER BY snapshot_date) AS prev_day_count,
ROUND(100.0 * (COUNT(*) - LAG(COUNT(*)) OVER ()) / LAG(COUNT(*)) OVER (), 2) AS growth_rate_pct
FROM dws_user_daily_snapshot
WHERE snapshot_date >= CURRENT_DATE - INTERVAL '7 days'
GROUP BY snapshot_date
ORDER BY snapshot_date;
该查询输出可用于绘制趋势图,一旦增长率超过阈值(如±50%),即可触发企业微信/钉钉告警。
综上所述,临时表与中间表的组合运用,构成了现代数据清洗基础设施的核心组件。通过精细化的生命周期管理、结构校验与自动化调度,不仅能高效完成去重任务,更能支撑起稳健可靠的企业级数据服务体系。
6. 自连接删除重复记录(保留主键最小行)
在企业级数据库维护过程中,数据冗余问题不仅影响存储效率,更可能引发业务逻辑错误。尤其是在没有严格唯一约束的历史表中,因系统异常、网络重试或人为误操作导致的重复插入屡见不鲜。面对这类场景,仅通过查询去重已无法满足需求,必须对物理数据进行清理。本章聚焦于一种高效且可控的物理去重技术—— 使用自连接方式删除重复记录,并保留每组重复数据中主键最小的一条 。该方法适用于不具备窗口函数支持的老版本数据库系统(如MySQL 5.7以下),同时具备良好的可读性和执行透明性。
相较于 ROW_NUMBER() 等高级语法,自连接方案更加底层,但其优势在于兼容性强、逻辑清晰,尤其适合需要精细控制删除条件的复杂环境。我们将从理论模型出发,深入剖析其运行机制,逐步构建完整的实现流程,并结合真实订单系统的清洗案例,展示如何安全、精准地完成大规模重复数据清除任务。
6.1 自连接去重的逻辑模型与适用条件
自连接(Self-Join)是指一张表与其自身进行JOIN操作的技术手段。在去重场景中,我们利用这一特性将同一张表中的重复记录相互匹配,再根据预设规则(如主键大小)决定哪些行应被保留,哪些应被删除。这种方法的核心思想是: 找出所有“非最优”的重复副本并予以剔除 。
6.1.1 基于相同关键字段进行表内连接
要识别重复数据,首先需明确定义“什么是重复”。通常,这由业务语义决定。例如,在订单系统中,“用户ID + 订单金额 + 创建时间”三者一致即可视为重复提交;而在用户信息表中,则可能是“手机号 + 身份证号”组合构成唯一标识。
假设存在如下订单表结构:
CREATE TABLE orders (
id INT AUTO_INCREMENT PRIMARY KEY,
user_id INT NOT NULL,
amount DECIMAL(10,2),
created_at DATETIME,
status VARCHAR(20)
);
若发现部分用户因前端双击导致生成了完全相同的订单(即 user_id , amount , created_at 均相同),则可通过以下自连接语句定位这些重复项:
SELECT a.id, a.user_id, a.amount, a.created_at
FROM orders a
JOIN orders b
ON a.user_id = b.user_id
AND a.amount = b.amount
AND a.created_at = b.created_at
AND a.id > b.id;
上述查询返回的是所有“非首次”出现的重复记录( a.id > b.id ),意味着只要存在一个ID更小的同类记录,当前记录就属于冗余数据。
| 字段 | 含义 |
|---|---|
a |
主表别名,表示待评估是否删除的记录 |
b |
自连接表别名,用于寻找“更早”的重复记录 |
ON 条件 |
定义“重复”的判断标准(关键字段相等) |
a.id > b.id |
确保只选中非最小ID的重复行 |
该逻辑的本质是一种 偏序关系筛选 :对于任意两行具有相同业务字段的记录,仅允许ID最小者存活。
flowchart TD
A[原始表 orders] --> B{是否存在另一行<br/>user_id=amount=created_at<br/>且id更小?}
B -- 是 --> C[标记为可删除]
B -- 否 --> D[保留为唯一记录]
C --> E[执行 DELETE 操作]
D --> F[保留在结果集中]
逻辑分析说明 :
- 自连接的关键在于设置合理的连接条件,既要保证能匹配到重复行,又要避免全表笛卡尔积带来的性能灾难。
- 使用
a.id > b.id而非a.id != b.id可防止重复配对(如 ID=3 和 ID=5 匹配两次),提高效率并避免误删。- 此方法要求表中存在单调递增的主键(如自增ID),否则无法有效确定“最早”记录。
6.1.2 利用主键或时间戳确定保留优先级
在实际应用中,除了主键ID外,还可以借助其他字段作为保留依据。常见策略包括:
| 保留策略 | 判断依据 | SQL 实现方式 |
|---|---|---|
| 最小主键 | id 最小者保留 |
a.id > b.id |
| 最早创建 | created_at 最早者保留 |
a.created_at > b.created_at 或配合 TIMESTAMPDIFF |
| 状态最优 | 如 status='completed' 优先保留 |
使用 CASE WHEN 排序权重 |
| 综合评分 | 多字段加权排序 | 需引入窗口函数或子查询辅助 |
当无法依赖主键时(如UUID主键无序),可改用时间戳字段作为排序基准。示例如下:
DELETE a FROM orders a
USING orders a
JOIN orders b
ON a.user_id = b.user_id
AND a.amount = b.amount
AND a.created_at = b.created_at
AND a.created_at > b.created_at;
注意:某些数据库(如PostgreSQL)不支持
DELETE ... USING语法,需改写为标准DELETE FROM ... WHERE EXISTS形式。
此外,若多个字段共同构成唯一性标准,建议建立复合索引以提升连接性能:
CREATE INDEX idx_orders_dup ON orders(user_id, amount, created_at);
该索引可显著加速JOIN过程中的等值匹配,减少全表扫描开销。
6.1.3 DELETE + JOIN语句的兼容性说明
不同数据库对 DELETE 结合 JOIN 的支持程度存在差异,这是实施自连接删除前必须考虑的问题。
| 数据库 | 支持 DELETE JOIN | 语法形式 |
|---|---|---|
| MySQL | ✅ 支持 | DELETE a FROM table a JOIN table b ON ... |
| PostgreSQL | ❌ 不直接支持 | 需用 USING 或 EXISTS 替代 |
| SQL Server | ✅ 支持 | DELETE a FROM table a INNER JOIN table b ON ... |
| Oracle | ❌ 不支持 | 必须使用子查询或MERGE |
以MySQL为例,正确的删除语法如下:
DELETE a FROM orders a
JOIN orders b
ON a.user_id = b.user_id
AND a.amount = b.amount
AND a.created_at = b.created_at
AND a.id > b.id;
而在PostgreSQL中,等效写法为:
DELETE FROM orders a
USING orders b
WHERE a.user_id = b.user_id
AND a.amount = b.amount
AND a.created_at = b.created_at
AND a.id > b.id;
参数说明与执行逻辑解读 :
USING子句相当于隐式JOIN,允许引用另一份表实例。- 所有条件置于
WHERE中,逻辑与MySQL一致。- 此写法虽略显繁琐,但在跨平台脚本中更具通用性。
为确保脚本可移植性,推荐封装成通用模板:
-- 通用自连接删除模板(适用于多数RDBMS)
DELETE FROM target_table alias_a
WHERE EXISTS (
SELECT 1 FROM target_table alias_b
WHERE alias_b.col1 = alias_a.col1
AND alias_b.col2 = alias_a.col2
-- ... 其他关键字段
AND alias_b.pk < alias_a.pk -- 保留最小主键
);
此方式虽然性能略低于 JOIN ,但兼容性最佳,且易于理解与调试。
6.2 具体实现步骤详解
要成功执行基于自连接的去重删除,必须遵循严谨的操作流程,确保数据安全与事务一致性。以下是标准化的五步实现路径。
6.2.1 构造连接条件匹配重复对
第一步是准确识别出哪些记录属于“重复组”。这一步不应立即删除,而应先通过 SELECT 验证匹配效果。
继续以上述 orders 表为例,构造如下查询:
-- 查看即将被删除的重复记录
SELECT
a.id AS delete_id,
a.user_id,
a.amount,
a.created_at,
b.id AS keep_id
FROM orders a
JOIN orders b
ON a.user_id = b.user_id
AND a.amount = b.amount
AND a.created_at = b.created_at
AND a.id > b.id
ORDER BY a.user_id, a.created_at;
输出示例:
| delete_id | user_id | amount | created_at | keep_id |
|---|---|---|---|---|
| 4 | 101 | 99.99 | 2024-03-15 10:00:00 | 2 |
| 7 | 102 | 50.00 | 2024-03-16 11:30:00 | 5 |
逻辑分析 :
- 每一行代表一个将被删除的冗余记录。
keep_id表示同组中ID更小、将被保留的原始记录。- 若结果过多,可用
LIMIT 10控制预览数量。
建议在此阶段导出结果供审核,防止误删关键数据。
6.2.2 设定删除规则仅保留最小ID记录
确认匹配逻辑正确后,方可执行删除。完整SQL如下:
START TRANSACTION;
DELETE a FROM orders a
USING orders b
WHERE a.user_id = b.user_id
AND a.amount = b.amount
AND a.created_at = b.created_at
AND a.id > b.id;
-- 查看影响行数
SELECT ROW_COUNT() AS affected_rows;
-- COMMIT; -- 确认无误后再提交
代码逐行解释 :
START TRANSACTION;:开启事务,确保可回滚。DELETE a FROM ... USING ...:PostgreSQL风格删除,移除满足条件的a表记录。- 连接条件确保只有“重复且ID较大”的记录被选中。
ROW_COUNT()返回本次删除影响的行数,用于监控。- 注释掉的
COMMIT提醒操作者手动确认后再提交。
若使用MySQL,语法稍有不同:
START TRANSACTION;
DELETE a FROM orders a
JOIN orders b
ON a.user_id = b.user_id
AND a.amount = b.amount
AND a.created_at = b.created_at
AND a.id > b.id;
SELECT ROW_COUNT();
-- COMMIT;
两种写法功能等价,均能高效完成去重。
6.2.3 使用事务确保删除操作可回滚
生产环境中任何数据修改都必须在事务保护下进行。以下是推荐的完整操作流程:
-- 1. 开启事务
BEGIN;
-- 2. 备份原表(可选但强烈建议)
CREATE TABLE orders_backup_20240405 AS SELECT * FROM orders;
-- 3. 执行删除
DELETE a FROM orders a
JOIN orders b
ON a.user_id = b.user_id
AND a.amount = b.amount
AND a.created_at = b.created_at
AND a.id > b.id;
-- 4. 检查影响行数
SELECT COUNT(*) AS remaining_count FROM orders;
-- 5. 核对数据完整性(如外键依赖)
SELECT COUNT(*) FROM order_items oi
LEFT JOIN orders o ON oi.order_id = o.id
WHERE o.id IS NULL; -- 应返回0
-- 6. 确认无误后提交
COMMIT;
-- 或发现异常则 ROLLBACK;
| 步骤 | 目的 |
|---|---|
| 备份表 | 防止误删后无法恢复 |
| 事务包裹 | 提供原子性保障 |
| 删除后校验 | 确保未破坏关联数据 |
| 外键检查 | 避免孤儿记录产生 |
扩展建议 :
- 可将备份表命名加入时间戳,便于追踪历史状态。
- 对于大表操作,建议分批删除(每次1000行),避免长事务锁表。
graph LR
A[开始事务] --> B[创建备份表]
B --> C[执行DELETE自连接]
C --> D[检查影响行数]
D --> E{数据是否正常?}
E -- 是 --> F[COMMIT提交]
E -- 否 --> G[ROLLBACK回滚]
该流程体现了数据库运维的最佳实践: 变更前备份、变更中监控、变更后验证 。
6.3 实战案例:清除订单系统中的双提交记录
某电商平台近期收到用户投诉:“同一笔订单被扣款两次”。经排查,系前端防抖机制失效所致,大量用户在短时间内触发了重复下单请求,造成财务损失和客户信任危机。现需紧急清洗数据库,消除此类重复订单。
6.3.1 分析重复订单特征(相同金额、时间、用户)
通过对日志和数据库抽样分析,发现重复订单具有以下共性:
user_id相同amount完全一致created_at时间差 ≤ 1秒status均为 ‘pending’- 主键
id连续或接近
据此定义重复标准:
-- 查找疑似双提交记录
SELECT
user_id,
amount,
MIN(created_at) AS first_time,
MAX(created_at) AS last_time,
COUNT(*) AS dup_count
FROM orders
WHERE status = 'pending'
GROUP BY user_id, amount, DATE(created_at), HOUR(created_at), MINUTE(created_at)
HAVING COUNT(*) > 1
AND TIMESTAMPDIFF(SECOND, MIN(created_at), MAX(created_at)) <= 1;
此查询按分钟粒度分组,并限制时间差不超过1秒,有效过滤正常高频下单行为。
6.3.2 编写DELETE语句精准移除冗余条目
基于上述分析,编写最终删除语句:
-- 开启事务
BEGIN;
-- 创建快照备份
CREATE TABLE orders_pre_clean_20240405 AS SELECT * FROM orders;
-- 执行去重删除
DELETE a FROM orders a
JOIN orders b
ON a.user_id = b.user_id
AND a.amount = b.amount
AND a.status = 'pending'
AND TIMESTAMPDIFF(SECOND, b.created_at, a.created_at) BETWEEN 0 AND 1
AND a.id > b.id;
-- 输出统计信息
SELECT
'Deleted duplicate orders' AS message,
ROW_COUNT() AS count;
-- 提交事务
COMMIT;
参数说明 :
TIMESTAMPDIFF(SECOND, ...)精确控制时间间隔。BETWEEN 0 AND 1确保方向正确(a晚于b)。a.id > b.id保证只删后一条。
执行后验证剩余数据:
-- 检查是否仍有重复
SELECT user_id, amount, COUNT(*)
FROM orders
WHERE status = 'pending'
GROUP BY user_id, amount, created_at
HAVING COUNT(*) > 1;
-- 期望返回空集
6.3.3 验证前后数据完整性与外键依赖关系
最后一步是确保删除未破坏系统一致性。重点检查:
- 外键引用完整性
-- 检查order_items是否指向已删除订单
SELECT COUNT(*) FROM order_items oi
LEFT JOIN orders o ON oi.order_id = o.id
WHERE o.id IS NULL;
- 财务总额对比
-- 清理前总额(含重复)
SELECT SUM(amount) FROM orders_pre_clean_20240405 WHERE status = 'pending';
-- 清理后总额
SELECT SUM(amount) FROM orders WHERE status = 'pending';
- 用户维度统计变化
-- 每个用户的订单数分布变化
SELECT
user_id,
COUNT(*) AS order_count
FROM orders
GROUP BY user_id
HAVING COUNT(*) > 5
ORDER BY order_count DESC;
通过以上多维度验证,确认去重操作既达到了清理目标,又未引入新的数据问题。
| 指标 | 清理前 | 清理后 | 变化率 |
|---|---|---|---|
| 总订单数 | 1,050,231 | 1,048,765 | -0.14% |
| 重复用户数 | 1,842 | 0 | -100% |
| 平均每单处理时间 | 12.4ms | 11.8ms | ↓4.8% |
结果显示,去重成功消除了全部重复订单,轻微减少了总数据量,同时提升了后续查询性能。
综上所述,自连接删除是一种成熟、可靠且高度可控的物理去重手段,特别适用于缺乏现代SQL特性的旧系统。只要设计好匹配逻辑、善用事务保护,并辅以充分验证,即可安全应对各类重复数据挑战。
7. ROW_NUMBER()窗口函数标记并删除重复行
7.1 窗口函数基本语法与分区机制
ROW_NUMBER() 是 SQL 标准中定义的窗口函数之一,能够在结果集的每个分组内为行分配一个唯一的递增整数。其核心优势在于可以在不破坏原始数据结构的前提下,精确控制“保留哪一行”这一业务逻辑。
7.1.1 ROW_NUMBER() OVER(PARTITION BY ORDER BY)结构解析
该函数的标准语法如下:
ROW_NUMBER() OVER (
PARTITION BY column1, column2, ...
ORDER BY sort_column [ASC | DESC]
)
PARTITION BY:定义去重的粒度,即按照哪些字段判断“重复”。例如,在客户信息表中,若以姓名、电话、地址作为判断依据,则这三者组合相同的记录被视为一组。ORDER BY:在每一组内部进行排序,决定哪条记录被保留(通常是排序靠前的第一条)。
示例 :假设我们有一个客户表
customers,包含以下字段:
| id | name | phone | address | created_time |
|---|---|---|---|---|
| 1 | 张三 | 13800138000 | 北京市朝阳区xxx路1号 | 2023-01-01 10:00 |
| 2 | 张三 | 13800138000 | 北京市朝阳区xxx路1号 | 2023-01-02 11:30 |
| 3 | 李四 | 13900139000 | 上海市浦东新区yyy街 | 2023-02-01 09:15 |
| 4 | 张三 | 13800138000 | 北京市朝阳区xxx路1号 | 2023-01-01 08:45 |
执行以下查询可为每组重复数据编号:
SELECT
*,
ROW_NUMBER() OVER (
PARTITION BY name, phone, address
ORDER BY created_time ASC
) AS rn
FROM customers;
输出结果:
| id | name | phone | address | created_time | rn |
|---|---|---|---|---|---|
| 4 | 张三 | 13800138000 | 北京市朝阳区xxx路1号 | 2023-01-01 08:45 | 1 |
| 1 | 张三 | 13800138000 | 北京市朝阳区xxx路1号 | 2023-01-01 10:00 | 2 |
| 2 | 张三 | 13800138000 | 北京市朝阳区xxx路1号 | 2023-01-02 11:30 | 3 |
| 3 | 李四 | 13900139000 | 上海市浦东新区yyy街 | 2023-02-01 09:15 | 1 |
其中 rn = 1 的记录是按时间最早的一条,将被保留。
7.1.2 分区字段选择对去重粒度的影响
分区字段的选择直接决定了“什么是重复”的语义标准。常见策略包括:
| 场景 | 推荐分区字段 | 说明 |
|---|---|---|
| 客户主数据清洗 | name, phone, id_card | 多维度匹配防止误删 |
| 用户行为日志 | user_id, event_type, timestamp (±1s) | 允许微小时间误差去重 |
| 订单系统 | order_no, amount, user_id | 防止双提交导致重复 |
| 设备上报数据 | device_id, metric_name, collect_time | 时间戳需参与判断 |
错误的分区可能导致过度去重或遗漏真实重复项。建议结合业务规则和数据分析先验知识确定字段组合。
7.1.3 排序字段设定决定保留哪一行
排序字段用于控制每组中优先保留的记录。典型选择包括:
created_time ASC:保留最早录入的数据(适用于历史归档)updated_time DESC:保留最新更新的数据(适用于主数据同步)id ASC:保留主键最小的记录(通用做法,简单稳定)
⚠️ 注意:如果
ORDER BY字段存在 NULL 值,应明确处理方式(如用COALESCE(updated_time, '1970-01-01')补默认值),避免排序不确定性。
7.2 基于编号筛选唯一记录的方法
一旦通过 ROW_NUMBER() 生成行号,即可利用该编号过滤出唯一记录。
7.2.1 在子查询中生成行号并过滤rn > 1
最基础的方式是在外层查询中排除 rn > 1 的行:
SELECT *
FROM (
SELECT
*,
ROW_NUMBER() OVER (
PARTITION BY name, phone, address
ORDER BY created_time ASC
) AS rn
FROM customers
) t
WHERE rn = 1;
此查询返回所有非重复的“代表记录”,可用于构建干净视图或插入新表。
7.2.2 结合CTE构建安全删除语句
为了从原表中删除重复行,推荐使用 CTE 提高可读性和事务安全性:
WITH DuplicateCTE AS (
SELECT
id,
ROW_NUMBER() OVER (
PARTITION BY name, phone, address
ORDER BY created_time ASC
) AS rn
FROM customers
)
DELETE FROM customers
WHERE id IN (
SELECT id FROM DuplicateCTE WHERE rn > 1
);
✅ 使用 CTE 可预先查看待删数据:
sql SELECT * FROM DuplicateCTE WHERE rn > 1; -- 先预览再删除
同时建议包裹在事务中执行:
BEGIN TRANSACTION;
-- 预览删除影响
WITH DuplicateCTE AS (
SELECT id, rn FROM (
SELECT
id,
ROW_NUMBER() OVER (PARTITION BY name, phone, address ORDER BY created_time)
AS rn
FROM customers
) t
)
SELECT COUNT(*) AS rows_to_delete FROM DuplicateCTE WHERE rn > 1;
-- 执行删除
WITH DuplicateCTE AS (
SELECT
id,
ROW_NUMBER() OVER (PARTITION BY name, phone, address ORDER BY created_time) AS rn
FROM customers
)
DELETE FROM customers
WHERE id IN (SELECT id FROM DuplicateCTE WHERE rn > 1);
-- COMMIT; -- 确认无误后再提交
-- ROLLBACK; -- 出错时回滚
7.2.3 使用MERGE语句实现原子化更新
对于需要同步多个系统的场景,可采用 MERGE 实现“查删插”一体化操作:
MERGE INTO clean_customers AS target
USING (
SELECT *
FROM (
SELECT *,
ROW_NUMBER() OVER (PARTITION BY name, phone, address ORDER BY id) AS rn
FROM raw_customers
) t
WHERE rn = 1
) AS source
ON target.phone = source.phone
WHEN MATCHED THEN
UPDATE SET
name = source.name,
address = source.address,
updated_time = GETDATE()
WHEN NOT MATCHED THEN
INSERT (id, name, phone, address, created_time)
VALUES (source.id, source.name, source.phone, source.address, source.created_time);
该方式具备幂等性,适合 ETL 流程中的增量合并。
7.3 综合案例:客户信息表全字段去重清洗
7.3.1 定义“完全重复”标准(姓名、电话、地址一致)
在某银行客户管理系统中,发现因多渠道录入导致大量重复客户档案。经分析,确认以下去重规则:
- 判定条件:
name,phone,address三者完全相同视为重复 - 保留策略:优先保留
created_time最早的记录 - 安全要求:删除前备份原始数据,并记录影响行数
7.3.2 使用ROW_NUMBER()标记所有重复实例
首先创建归档表保存原始副本:
SELECT *, GETDATE() AS archive_time
INTO customers_archive_20250405
FROM customers;
然后执行标记与删除:
-- 查看将要删除的记录
WITH Dups AS (
SELECT
id, name, phone, address, created_time,
ROW_NUMBER() OVER (
PARTITION BY name, phone, address
ORDER BY created_time ASC
) AS rn
FROM customers
)
SELECT *
FROM Dups
WHERE rn > 1
ORDER BY name, phone;
确认后执行删除:
WITH Dups AS (
SELECT
id,
ROW_NUMBER() OVER (
PARTITION BY name, phone, address
ORDER BY created_time ASC
) AS rn
FROM customers
)
DELETE FROM customers
WHERE id IN (SELECT id FROM Dups WHERE rn > 1);
7.3.3 最终生成无重复干净数据集并归档原始副本
验证去重效果:
-- 检查是否仍有重复
SELECT
name, phone, address,
COUNT(*) AS cnt
FROM customers
GROUP BY name, phone, address
HAVING COUNT(*) > 1;
若无返回结果,则表示去重成功。最后建立唯一索引防止未来重复:
ALTER TABLE customers
ADD CONSTRAINT uk_customer_unique
UNIQUE (name, phone, address);
同时可通过流程图展示整体去重流程:
flowchart TD
A[原始客户表] --> B{是否存在重复?}
B -->|否| C[无需处理]
B -->|是| D[创建归档表备份]
D --> E[使用ROW_NUMBER标记重复行]
E --> F[构造CTE筛选rn > 1]
F --> G[执行DELETE删除冗余]
G --> H[添加唯一约束防再生]
H --> I[输出干净数据集]
此外,统计去重前后对比数据如下表所示:
| 指标 | 去重前 | 去重后 | 变化量 |
|---|---|---|---|
| 总记录数 | 102456 | 87321 | -15135 |
| 平均每客户重复次数 | 1.18 | 1.00 | -0.18 |
| 存储空间占用(MB) | 420 | 358 | -62 |
| 查询响应时间(ms) | 340 | 190 | -150 |
| 唯一手机号占比 | 92.3% | 100% | +7.7% |
| 索引碎片率 | 38% | 8% | -30% |
| 外键引用完整性检查 | 通过 | 通过 | — |
| 日均新增重复率 | 0.6% | 0.05% | -0.55% |
| 数据质量评分 | 76 | 94 | +18 |
整个过程体现了 ROW_NUMBER() 在复杂去重任务中的灵活性与可靠性,尤其适用于缺乏自然主键但需语义级去重的场景。
简介:在SQL中,去除重复数据是数据清洗的关键步骤,直接影响数据的准确性和唯一性。本文介绍了多种SQL去重方法,包括DISTINCT关键字、GROUP BY配合聚合函数、CTE或临时表、自连接、ROW_NUMBER()窗口函数、唯一索引以及集合操作等,适用于不同数据库环境和业务场景。通过这些技术,用户可灵活实现查询去重与物理删除重复记录,提升数据质量。实际操作前建议备份数据,防止误删。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 28
28 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)