10分钟零代码!用n8n+飞书打造24小时智能客服机器人,大模型入门到精通,收藏这篇就足够了!
还在为重复回答客户问题而头疼?想要一个不知疲倦的数字员工?今天教你用两个免费工具——n8n和飞书,零代码搭建专属智能客服!
还在为重复回答客户问题而头疼?想要一个不知疲倦的数字员工?今天教你用两个免费工具——n8n和飞书,零代码搭建专属智能客服!
无论你是创业老板还是运营小白,这篇教程都能让你轻松上手,彻底告别重复劳动!
准备工作:3样东西搞定
开始前,我们需要准备:
-
- n8n账号:免费的自动化神器,可以让不同软件"对话"
-
- 飞书管理员账号:用来创建机器人
-
- 知识库文档:机器人的"大脑",比如常见问题解答
准备好了?开始"造"机器人!
第一步:创建飞书"数字员工"
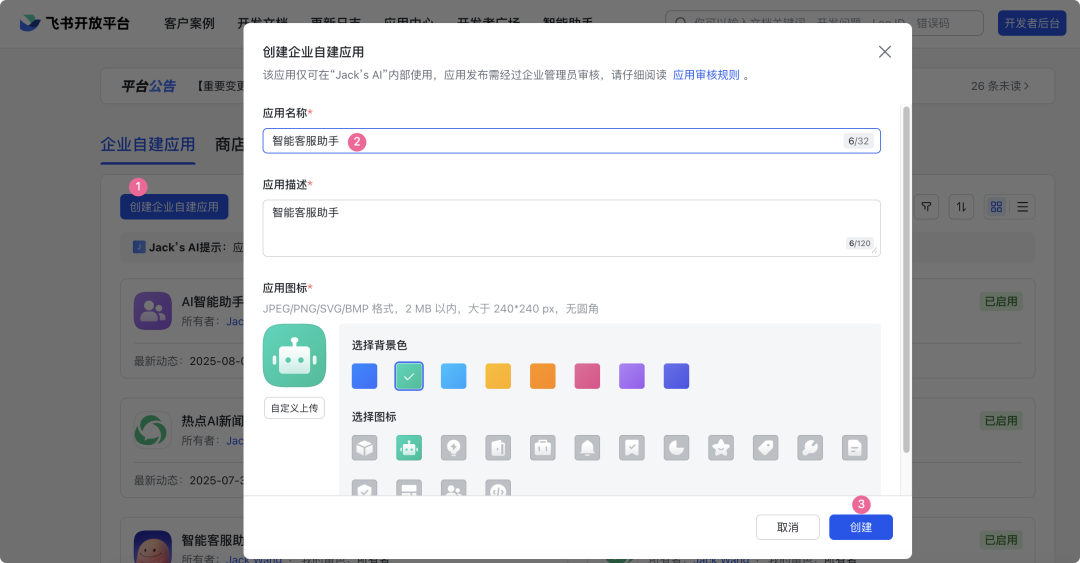
1. 创建飞书应用
- • 登录飞书开放平台
- • 选择"创建应用" → “企业自建应用”
- • 填写应用名称(如"智能客服助手")
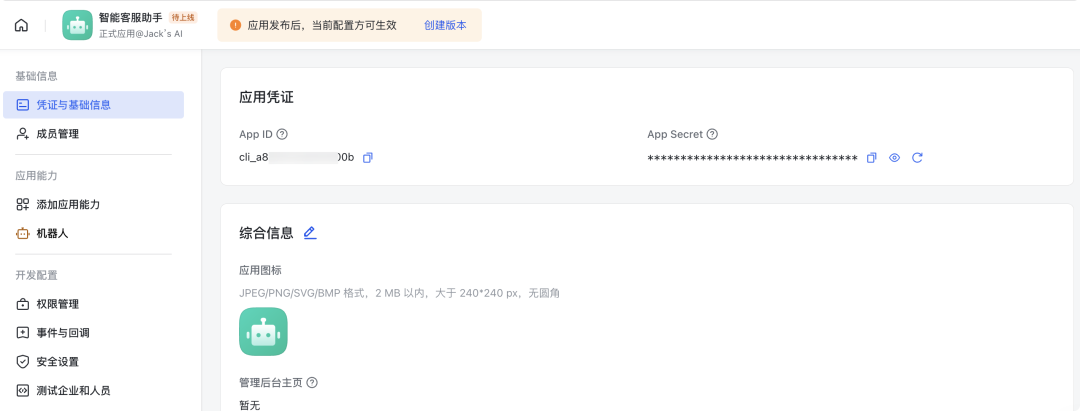
2. 获取关键信息
在"凭证与基础信息"页面,记下:
- • App ID
- • App Secret
这两个是连接n8n的"钥匙",务必保存好!
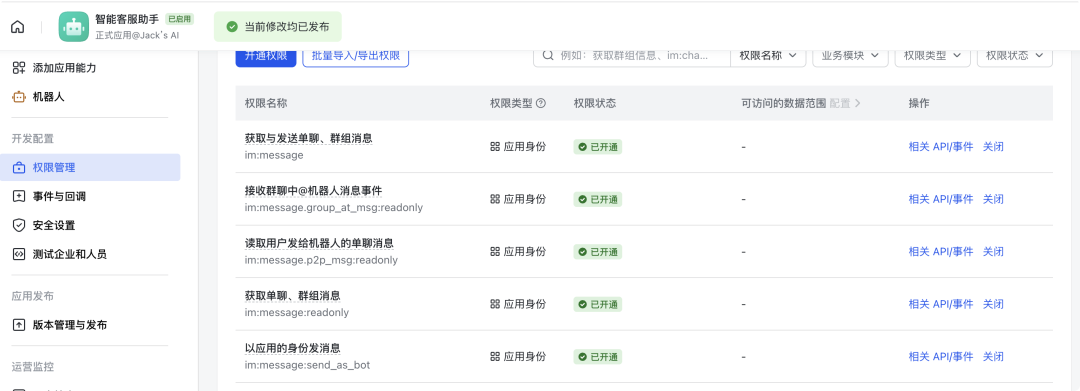
3. 开通机器人权限
在"应用功能" → "机器人"中启用,然后在"权限管理"开通:
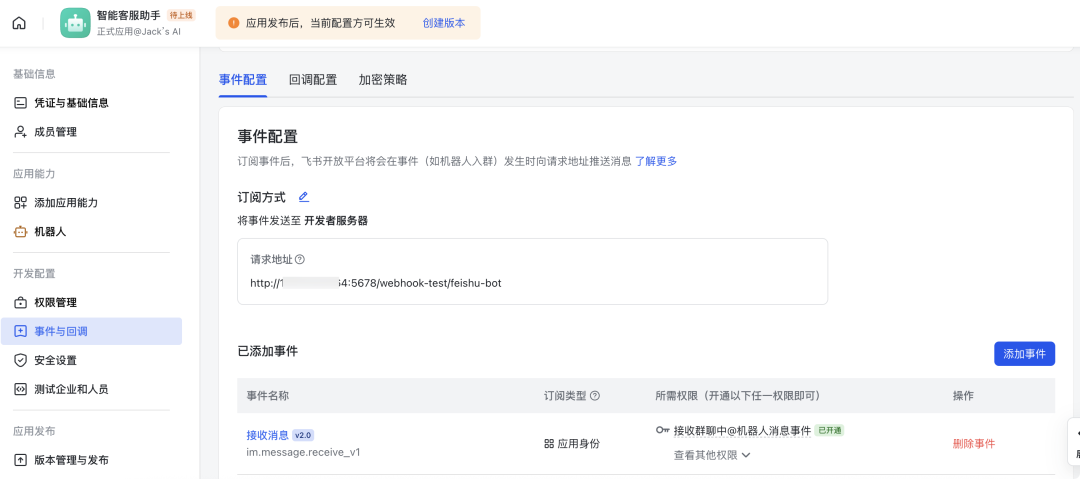
4. 配置事件订阅
在"事件订阅"页面,先留着"请求地址配置"空白,等下一步生成URL后再填。
第二步:搭建n8n智能大脑
登录n8n,开始搭建核心流程:接收消息 → 智能处理 → 回复消息
1. 添加Webhook节点(接收飞书消息)
步骤1:创建Webhook节点
- • 在n8n工作流编辑器中,点击左侧的"+"按钮
- • 在节点搜索框中输入"webhook"
- • 选择"Webhook"节点并添加到画布
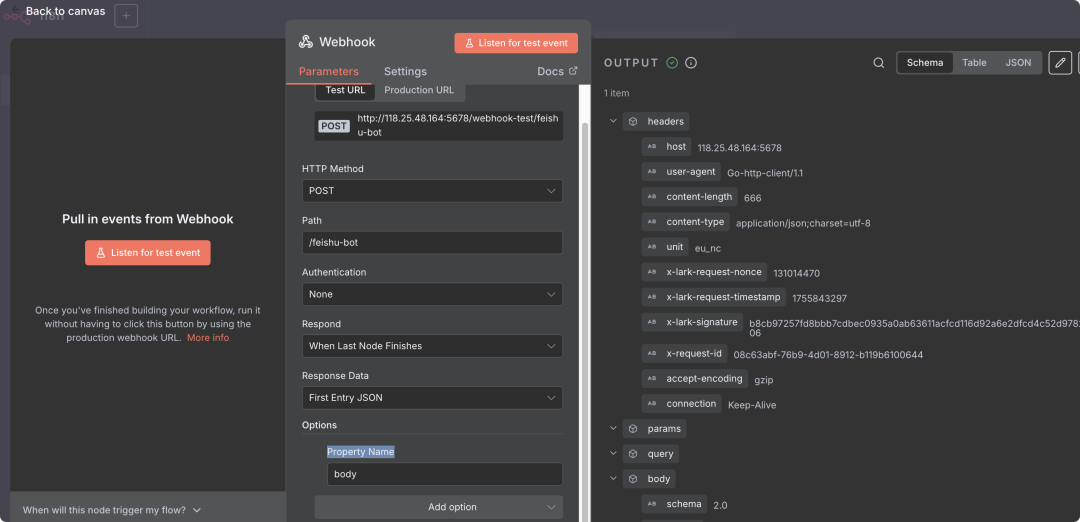
步骤2:配置Webhook节点
- • 双击Webhook节点进入配置界面
- • HTTP Method: 选择"POST"(飞书事件推送使用POST方法)
- • Path: 保持默认或自定义路径(如:
/feishu-bot) - • Authentication: 选择"None"(飞书验证通过Challenge机制)
- • Response Mode: 选择"When Last Node Finishes"
- • Response Data: 选择"First Entry JSON"
- • Property Name: 输入"body"
步骤3:获取Webhook URL
- • 配置完成后,点击"Test step"或"Listen for test event"
- • 复制生成的Test URL(格式如:
https://yourdomain.com/webhook-test/uuid) - • 确保URL显示为外网可访问地址(非localhost)
步骤4:在飞书后台配置
- • 登录飞书开放平台,进入你的应用
- • 找到"事件订阅" → “请求地址配置”
- • 将复制的URL粘贴到"请求URL"字段
- • 点击"保存"按钮
步骤5:验证连接
-
• 确保工作流已保存并激活
-
• 在n8n中确保Webhook节点处于"Listen for test event"状态
-
• 飞书会自动发送Challenge验证请求
-
• 验证成功后,飞书后台会显示"验证成功"状态
网络访问配置:
- • 本地开发:使用ngrok等内网穿透工具:
ngrok http 5678 - • 云端部署:配置N8N_HOST环境变量为实际域名或IP地址
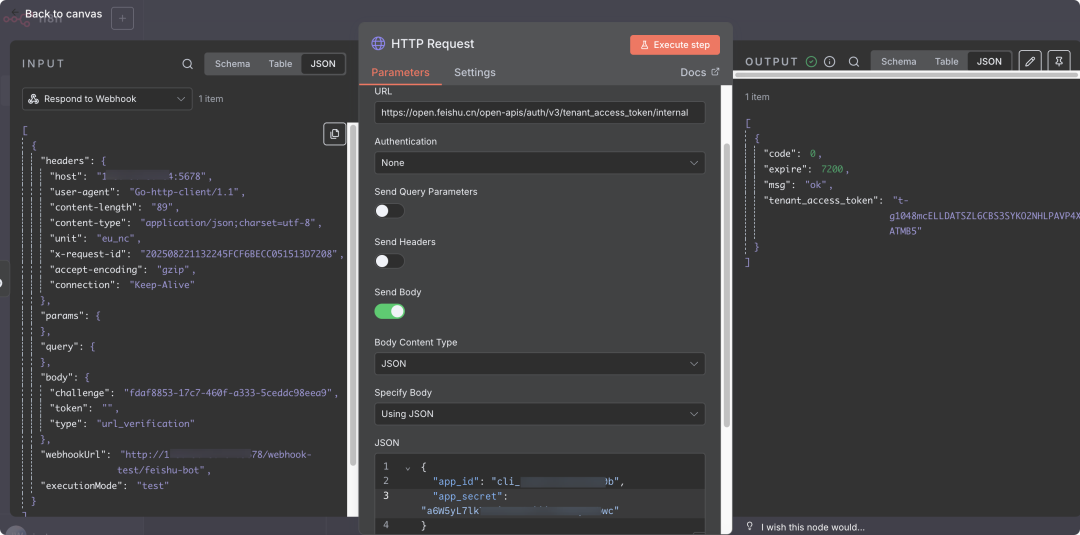
2. 添加Token获取节点
添加HTTP Request节点:
- • 点击"+"添加
HTTP Request节点,连接到Webhook节点 - • Method: POST
- • URL:
https://open.feishu.cn/open-apis/auth/v3/tenant_access_token/internal - • Body: JSON格式
{
"app_id"
:
"你的APP_ID"
,
"app_secret"
:
"你的APP_SECRET"
}
注意:替换为真实的APP_ID和APP_SECRET,Token有效期2小时。
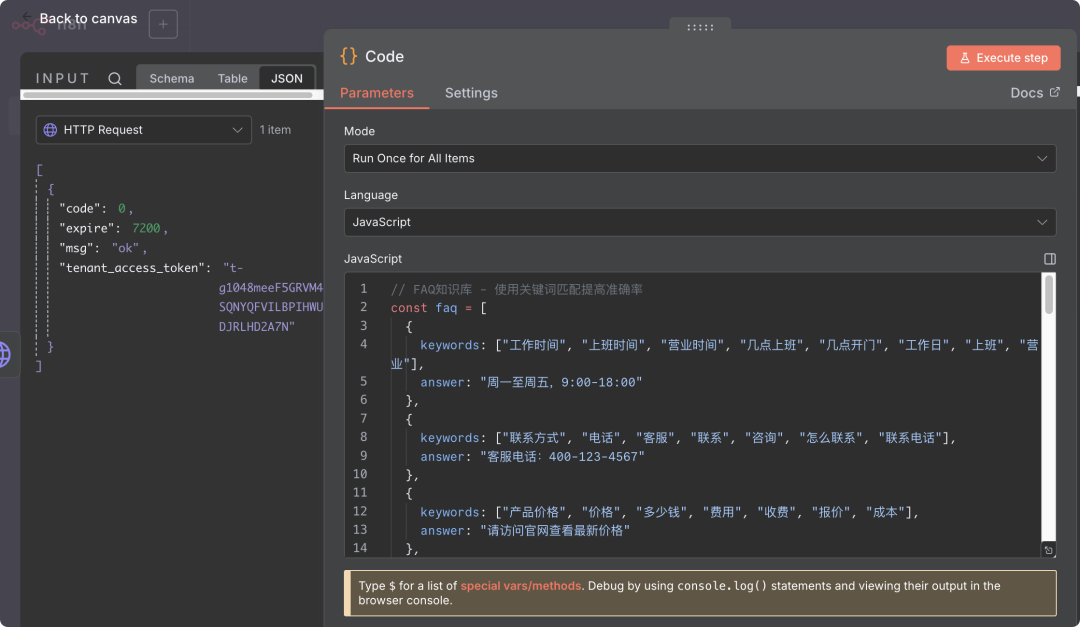
3. 添加智能问答节点
添加Code节点:
- • 点击"+"添加
Code节点,连接到Token获取节点 - • 重要配置:将Mode设置为
Run Once for All Items(对所有项目运行一次) - • 输入以下JavaScript代码:
// FAQ知识库 - 使用关键词匹配提高准确率
const
faq = [
{
keywords
: [
"工作时间"
,
"上班时间"
,
"营业时间"
,
"几点上班"
,
"几点开门"
,
"工作日"
,
"上班"
,
"营业"
],
answer
:
"周一至周五,9:00-18:00"
},
{
keywords
: [
"联系方式"
,
"电话"
,
"客服"
,
"联系"
,
"咨询"
,
"怎么联系"
,
"联系电话"
],
answer
:
"客服电话:400-123-4567"
},
{
keywords
: [
"产品价格"
,
"价格"
,
"多少钱"
,
"费用"
,
"收费"
,
"报价"
,
"成本"
],
answer
:
"请访问官网查看最新价格"
},
{
keywords
: [
"技术支持"
,
"技术"
,
"支持"
,
"帮助"
,
"问题"
,
"故障"
,
"bug"
,
"技术问题"
],
answer
:
"请发送邮件至 tech@company.com"
},
{
keywords
: [
"退换货"
,
"退货"
,
"换货"
,
"退款"
,
"返回"
,
"不满意"
,
"退"
,
"换"
],
answer
:
"支持7天无理由退换货,详情请查看用户协议"
}
];
// 获取输入数据 - 明确数据来源
// 从Token节点获取access_token
const
tokenData = $input.
first
().
json
;
// 从Webhook节点获取原始消息数据
const
webhookData = $(
'Webhook'
).
first
().
json
.
body
;
// 调试信息:打印数据来源和结构
console
.
log
(
'Token节点数据:'
,
JSON
.
stringify
(tokenData,
null
,
2
));
console
.
log
(
'Webhook原始数据:'
,
JSON
.
stringify
(webhookData,
null
,
2
));
console
.
log
(
'事件数据:'
,
JSON
.
stringify
(webhookData.
event
,
null
,
2
));
// 提取用户问题并匹配回答
// 注意:content可能是JSON字符串,需要先解析
let
userQuestion =
""
;
try
{
const
content = webhookData.
event
?.
message
?.
content
;
if
(
typeof
content ===
'string'
) {
// 如果content是字符串,尝试解析JSON
const
parsedContent =
JSON
.
parse
(content);
userQuestion = parsedContent?.
text
?.
trim
() ||
""
;
}
else
if
(content?.
text
) {
// 如果content已经是对象,直接访问text
userQuestion = content.
text
.
trim
() ||
""
;
}
}
catch
(error) {
console
.
log
(
'解析content时出错:'
, error);
userQuestion =
""
;
}
let
reply =
"抱歉,暂时无法回答您的问题,正在为您转接人工客服"
;
// 提取chat_id,尝试多种可能的路径
const
chatId = webhookData.
event
?.
message
?.
chat_id
||
webhookData.
event
?.
message
?.
message
?.
chat_id
||
webhookData.
event
?.
chat_id
;
console
.
log
(
'提取的chat_id:'
, chatId);
console
.
log
(
'用户问题:'
, userQuestion);
// 遍历FAQ数组,使用关键词匹配
for
(
const
faqItem
of
faq) {
// 检查用户问题是否包含任何关键词
const
matched = faqItem.
keywords
.
some
(
keyword
=>
userQuestion.
toLowerCase
().
includes
(keyword.
toLowerCase
())
);
if
(matched) {
reply = faqItem.
answer
;
console
.
log
(
`匹配到FAQ:
${faqItem.keywords[
0
]}
, 回复:
${reply}
`
);
break
;
}
}
// 验证必要参数
if
(!chatId) {
console
.
error
(
'错误: 无法获取chat_id'
);
throw
new
Error
(
'无法获取chat_id,请检查飞书webhook数据结构'
);
}
if
(!tokenData.
tenant_access_token
) {
console
.
error
(
'错误: 无法获取access_token'
);
throw
new
Error
(
'无法获取access_token,请检查Token获取节点'
);
}
// 返回处理结果
const
result = {
reply
: reply,
chatId
: chatId,
token
: tokenData.
tenant_access_token
};
console
.
log
(
'返回结果:'
,
JSON
.
stringify
(result,
null
,
2
));
return
result;
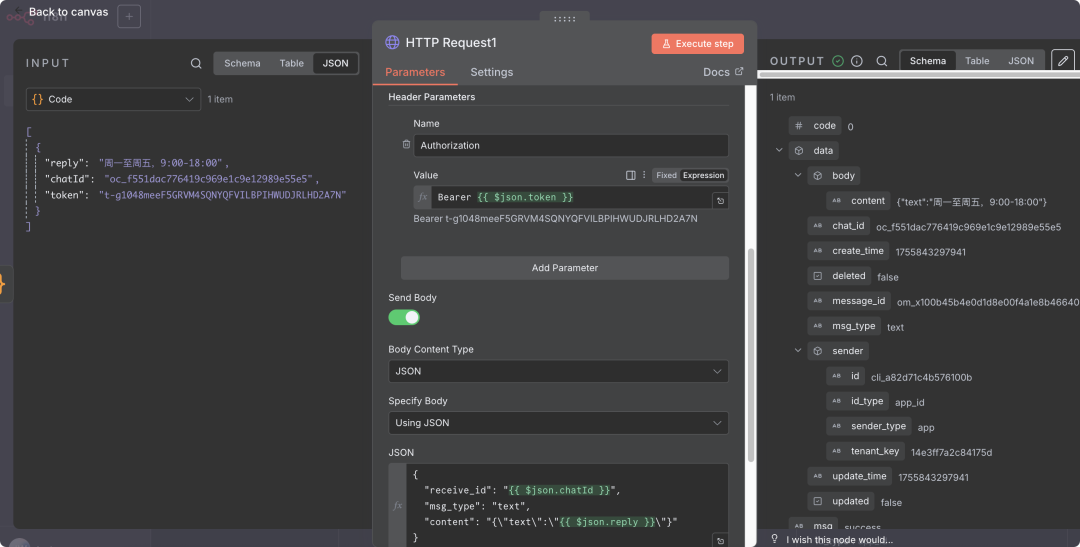
4. 添加回复节点
添加HTTP Request节点:
- • 点击"+"添加第二个
HTTP Request节点,连接到Code节点 - • Method: POST
- • URL:
https://open.feishu.cn/open-apis/im/v1/messages?receive_id_type=chat_id - • Authentication: Header Auth
- • Name:
Authorization - • Value:
Bearer {{ $json.token }}
- • Body: JSON格式
{
"receive_id"
:
"{{ $json.chatId }}"
,
"msg_type"
:
"text"
,
"content"
:
"{\"text\":\"{{ $json.reply }}\"}"
}
重要提示:
- • 如果遇到"invalid receive_id"错误,说明chatId为空,请检查Code节点的调试输出
- • 确保飞书webhook包含完整的消息事件数据
- • content字段需要双重JSON编码
第三步:上线测试
-
- 保存激活:点击"Save"并激活工作流
-
- 发布应用:在飞书后台"应用发布"创建新版本
-
- 开始对话:在飞书中@机器人提问测试

成功!你的智能客服已经上线了!
FAQ 常见问题
Q: 机器人不回复怎么办?
A: 检查n8n工作流是否激活,飞书权限是否开通完整。
Q: 如何让机器人更智能?
A: 将Code节点替换为调用ChatGPT或其他AI模型的API。
Q: 能处理图片消息吗?
A: 可以,需要在飞书权限中开通相应的多媒体消息权限。
Q: 免费版有限制吗?
A: n8n免费版每月有5000次执行限制,一般小团队够用。
总结
通过n8n和飞书的完美结合,我们零代码实现了智能客服的基础功能。这只是起点,你还可以:
- • 接入AI大模型:让回答更智能
- • 连接数据库:查询订单、用户信息
- • 创建工单系统:无法解决的问题自动转人工
自动化的世界充满无限可能,希望这个教程能为你打开新世界的大门!
我们该怎样系统的去转行学习大模型 ?
很多想入行大模型的人苦于现在网上的大模型老课程老教材,学也不是不学也不是,基于此我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近100余次后,终于把整个AI大模型的学习门槛,降到了最低!
在这个版本当中:
第一您不需要具备任何算法和数学的基础第二不要求准备高配置的电脑第三不必懂Python等任何编程语言
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型教程已经给大家整理并打包分享出来, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、大模型经典书籍(免费分享)
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套大模型报告(免费分享)
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)
三、大模型系列视频教程(免费分享)

四、2025最新大模型学习路线(免费分享)
我们把学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:我们会去了解大模型的基础知识,以及大模型在各个行业的应用和分析;学习理解大模型的
核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段是我们的AI大模型RAG应用开发工程,我们会去学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,我们会去学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造我们自己的Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,我们会更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调;并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以微信扫描下方二维码,免费领取

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 3
3 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)