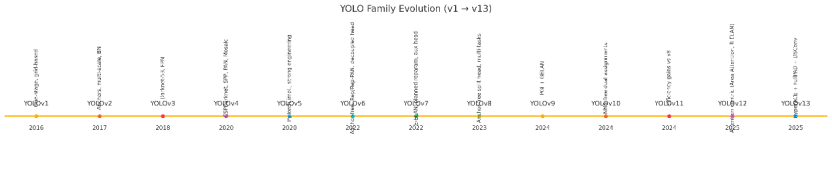
从 YOLOv1 到 YOLOv13:十年进化,一文读懂目标检测的「速度与激情」
YOLO系列目标检测算法发展综述 YOLO系列从2015年至今已迭代至v13版本,始终追求速度与精度的平衡。核心创新包括:v1首创单阶段端到端检测;v2引入锚框和多尺度训练;v3采用深度残差网络和三尺度输出;v4系统整合工程优化技巧;v5完善PyTorch生态链;v6-v8逐步实现Anchor-Free和多功能统一;v9改进梯度信息流;v10消除NMS后处理;最新版本开始融合注意力机制和超图建模。
本文部分图片源自网络,仅用于学术分享,如有侵权,请联系删除。
一、导读
在计算机视觉(Computer Vision)领域,目标检测(Object Detection)一直是最为基础且至关重要的研究方向之一。随着深度学习的兴起与硬件性能的不断提高,目标检测算法在过去十年间取得了长足的进步,从早期的 R-CNN 系列到 SSD、RetinaNet,再到YOLO(You Only Look Once)系列,每一次技术迭代都在速度与精度之间寻找新的平衡点。
如今,YOLO 系列已走过了近十年的发展历程,从最初的 YOLOv1(2015)到当下最新的 YOLOv13,每一个版本都体现了学术界与工业界在网络结构、训练策略、特征融合、损失函数设计等方面的不断探索与突破。
YOLO 系列的核心思路在于将目标检测看作是一个单阶段(One-Stage)的回归问题:它将输入图像划分为若干网格(Grid),并在每个网格中直接回归边界框(Bounding Box)与类别置信度,从而实现了高效的目标检测。
这种端到端、一次性完成检测与分类的思路,极大地提升了检测速度,同时在后续版本中,通过引入更加成熟的特征提取网络与多尺度预测策略,也逐步提升了检测精度。YOLO系列在无人驾驶、视频监控、机器人视觉等对实时性要求高的应用场景中得到了广泛采用。
1. YOLO 系列的初衷与背景
1.1 背景回顾
在 YOLO 系列出现之前,目标检测主要依赖双阶段(Two-Stage)检测器,如 R-CNN(2013)、Fast R-CNN(2015)、Faster R-CNN(2015) 等。这些方法通常先生成候选区域(Region Proposals),再对候选区域进行分类与回归,流程较为复杂,且推理速度相对较慢。虽然 R-CNN 系列在精度上表现出色,但难以满足实时检测场景(如无人驾驶、实时监控)对速度的严苛需求。
YOLO(You Only Look Once)的提出正是为了解决这一问题:通过将检测过程简化为一次网络前向传播,在特征图中直接预测各网格单元内的目标边界框及其类别,减少了重复计算与复杂的候选区域生成过程,从而实现了显著的速度提升。
1.2 YOLO 的核心思路
YOLO 的主要思想可以概括为:
-
将输入图像划分为 S×SS \times SS×S 的网格(例如 7×7);
-
每个网格预测若干个边界框(Bounding Box)及其对应的置信度与类别概率;
-
通过对输出的边界框进行非极大值抑制(NMS)等后处理操作,得到最终的检测结果。
这一方法大大简化了检测流程,使得网络可以端到端地学习从输入图像到检测结果的映射,同时也利用了全局信息来进行目标定位与分类。
2. YOLOv1(2015):端到端目标检测的开端
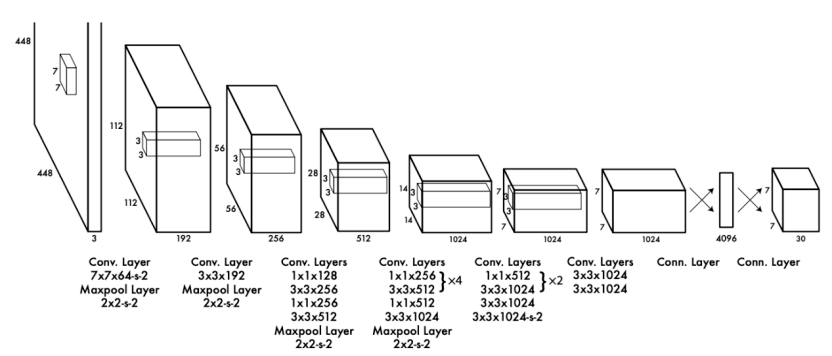
2.1 发表与背景YOLOv1 由 Joseph Redmon 等提出,论文《You Only Look Once: Unified, Real‑Time Object Detection》首次把检测表述为单阶段端到端回归,以整图为输入一次性预测类别与框,显著简化流程。
arXiv+1 2.2 网络结构使用类似 GoogLeNet 的卷积主干(24/28 层版本),混合 1×1 与 3×3 卷积;输出张量大小为 S×S×(B×5+C)(如 7×7×(2×5+20)),网格内回归多个框与类别概率。arXiv 2.3 核心创新点(相对两阶段)统一检测为单次前向、整图级全局感知、推理极快。
arXiv 2.4 局限与不足小目标/密集场景召回与定位偏弱;每格固定框数限制表达,Recall 相对较低。Semantic Scholar 2.5 性能与影响VOC2007 上mAP≈63.4%,以实时速度引发单阶段检测潮流,为后续 YOLOv2/3 奠定范式。CV Foundation
3. YOLOv2 / YOLO9000(2016):锚框与多尺度
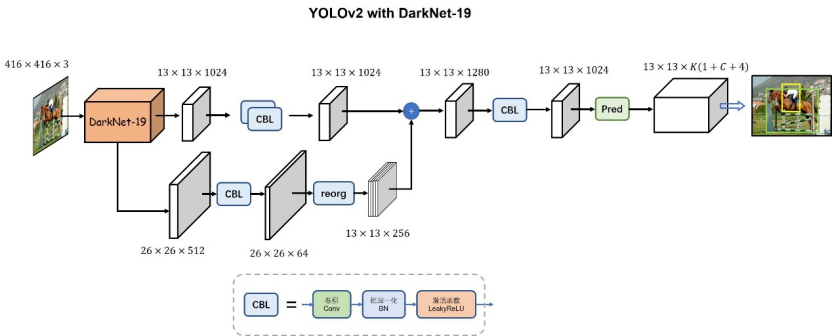
3.1 发表与背景相对 v1,YOLOv2/YOLO9000 系统性升级:引入Anchors、BatchNorm、多尺度训练,并提出分类+检测联合训练(YOLO9000),可检测 9000+ 类。arXiv+1 3.2 网络结构采用 Darknet‑19主干;多尺度在训练中动态更换输入大小;Anchor‑based 预测提升召回与定位。
ar5iv 3.3 核心创新点(相对 v1)锚框机制 + 多尺度训练显著提升精度与稳定性;联合训练拓展可检测类目。arXiv 3.4 局限与不足锚框/先验超参较多、匹配与后处理复杂度上升。 3.5 性能与影响在 VOC/COCO 上实现更高 mAP 与 67FPS 级实时性能,成为随后方法的主流基线。arXiv
4. YOLOv3(2018):更深主干与三尺度输出
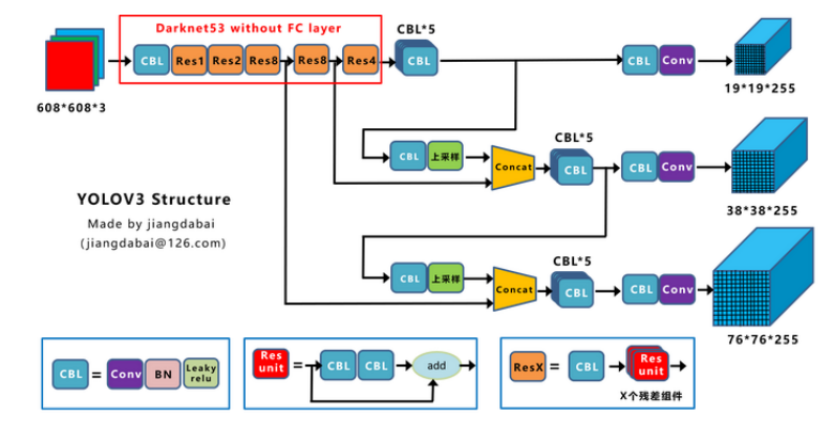
4.1 发表与背景相对 v2,引入更强的 Darknet‑53与多尺度特征金字塔(FPN 风格),均衡速度与精度。arXiv+1 4.2 网络结构Darknet‑53(残差堆叠)+ 三层尺度预测头,强化小/中/大目标覆盖。
ar5iv 4.3 核心创新点(相对 v2)更深残差主干 + 三尺度检测,显著改善小目标与总体 mAP。arXiv 4.4 局限与不足依旧 Anchor‑based,后处理/匹配开销与阈值敏感仍在。 4.5 性能与影响成为多年工程与研究公共基线,稳健易复现。arXiv
5. YOLOv4(2020):CSP 与工程化“组合拳”
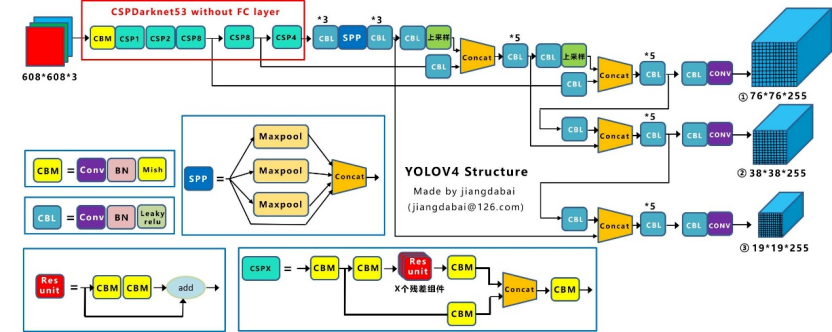
5.1 发表与背景相对 v3,YOLOv4 将BoF/BoS系列技巧系统化:CSPDarknet53、SPP、PAN、Mosaic、CIoU 等,强调可复现与可训练。arXiv+1 5.2 网络结构CSPDarknet53 主干 + SPP + PAN 颈部,配合强数据增强与损失设计。
arXiv 5.3 核心创新点(相对 v3)在标准硬件上即可训练出高精度+高速度模型,工程落地友好。arXiv 5.4 局限与不足训练/增强策略较多,调参门槛略高。 5.5 性能与影响在 COCO 上刷新速度‑精度折中,成为工业侧广用范式。arXiv
6. YOLOv5(2020,Ultralytics):PyTorch 工程范式
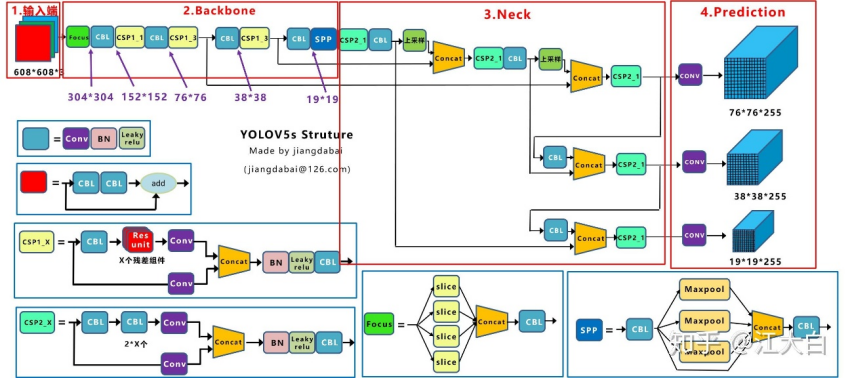
6.1 发表与背景相对 v4,全面拥抱 PyTorch 与工具链:训练/验证/导出(ONNX/TensorRT/CoreML)一体化,事实标准实现。Ultralytics Docs+1 6.2 网络结构CSP 派生的 C3/Focus等组件 + PAN;后续 v5u引入Anchor‑Free Split Head,与 v8 接轨。
Ultralytics Docs+1 6.3 核心创新点(相对 v4)工程体验与部署生态显著提升,降低端到端落地成本。Ultralytics Docs 6.4 局限与不足无正式论文;早期默认仍以 Anchor‑based 为主。 6.5 性能与影响成为“上手快、交付快”的首选实现,影响深远。Ultralytics Docs
7. YOLOv6(2022,美团):Anchor‑Free + 解耦头
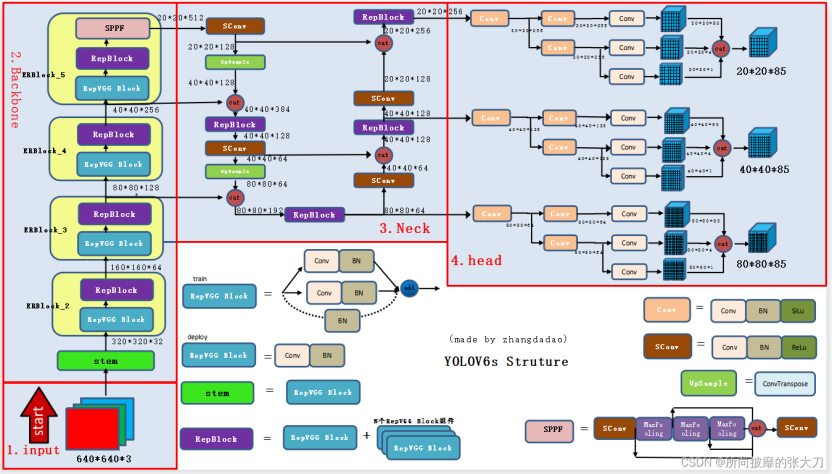
7.1 发表与背景相对 v5,面向工业落地,采用 Anchor‑Free、EfficientRep主干、Rep‑PAN颈部和解耦头,并提出 TAL标签分配。arXiv 7.2 网络结构RepVGG/CSPStackRep 主干 + Rep‑PAN + 高效解耦头;量化/蒸馏/裁剪友好。
arXiv+1 7.3 核心创新点(相对 v5)端侧吞吐/延迟更优,部署友好度大幅提升。arXiv 7.4 局限与不足训练细节较多;与 Ultralytics 生态兼容度需适配。 7.5 性能与影响在多硬件上实现稳定的低延迟高吞吐。MDPI
8. YOLOv7(2022/2023):E‑ELAN 与深监督
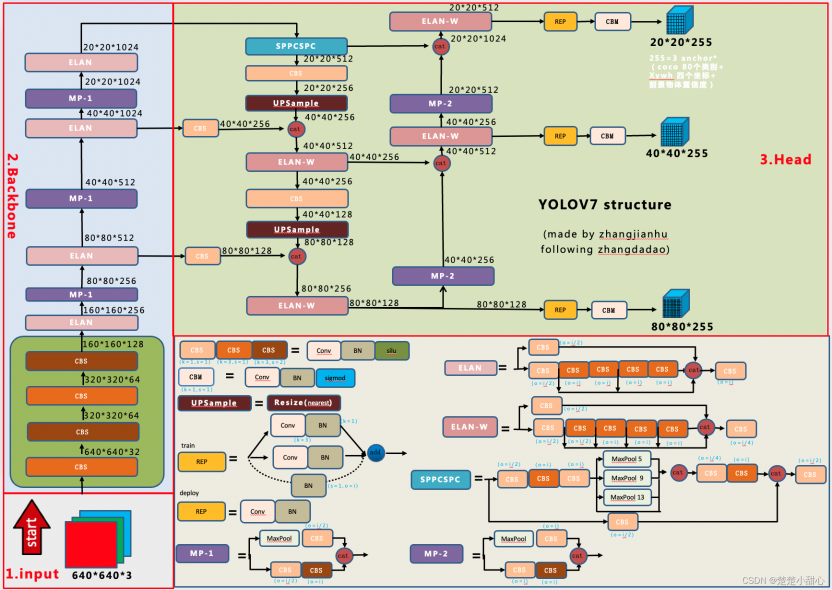
8.1 发表与背景相对 v6,引入 E‑ELAN、计划式重参数化与Auxiliary Head 深监督,训练策略系统化升级。arXiv+1 8.2 网络结构E‑ELAN 主干/颈部设计,保持梯度路径稳定;多尺度复合缩放。
CVF Open Access 8.3 核心创新点(相对 v6)训练可学“免费项”(bag‑of‑freebies)更可训,推理开销不增也提精度。arXiv 8.4 局限与不足工程生态不如 Ultralytics 系列一体。 8.5 性能与影响在 30FPS+ 实时段刷新精度纪录,成为强力实战方案。ResearchGate
9. YOLOv8(2023,Ultralytics):统一 Anchor‑Free 多任务
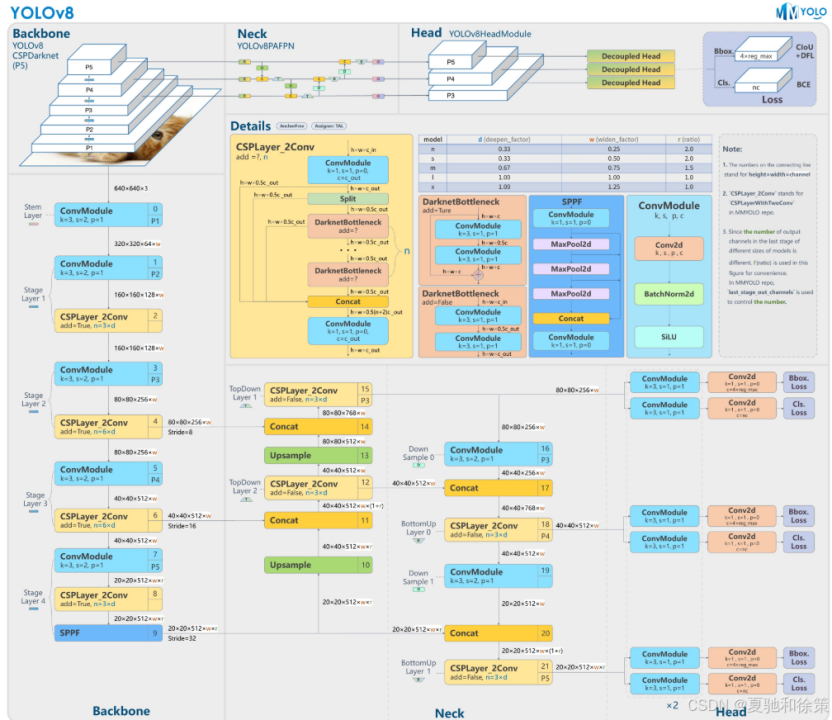
9.1 发表与背景相对 v7,Ultralytics 采用Anchor‑Free 分离头并统一到检测/分割/姿态/分类/OBB多任务,工程体验进一步提升。Ultralytics Docs+1 9.2 网络结构改进的 CSP/C2f 主干 + PAN 颈部 + Anchor‑Free Head;默认训练/导出简化。
Ultralytics Docs 9.3 核心创新点(相对 v7)生态与任务覆盖显著增强,默认表现更佳。Ultralytics Docs 9.4 局限与不足极端拥挤场景仍依赖后处理与阈值调优。 9.5 性能与影响成为通用业务的默认优选,便于端云全栈部署。Ultralytics Docs
10. YOLOv9(2024):PGI + GELAN 缓解信息瓶颈
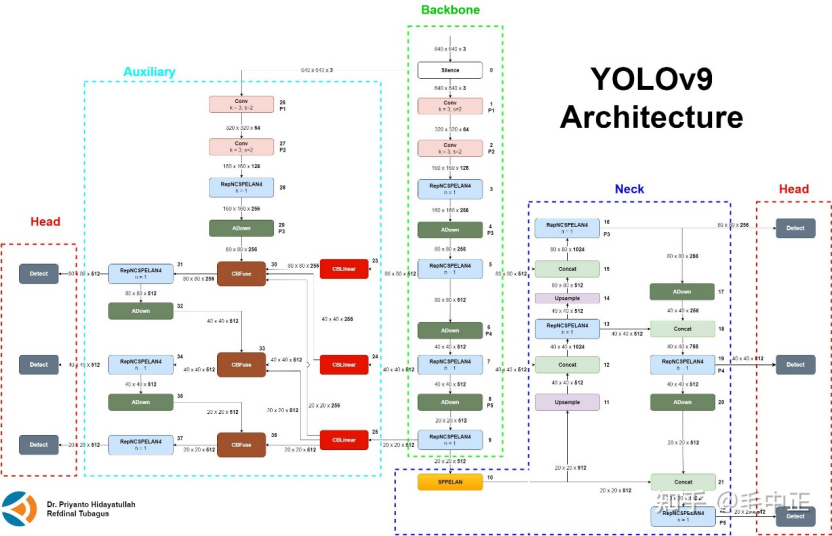
10.1 发表与背景相对 v8,引入 PGI(可编程梯度信息)与 GELAN主干,面向从轻量到大型的统一收益。arXiv+1 10.2 网络结构GELAN 规划梯度路径,配合 PGI 辅助分支优化梯度信号与信息保真。
ECVA 10.3 核心创新点(相对 v8)缓解“信息瓶颈”,从零训练与小模型更稳。arXiv 10.4 局限与不足训练配置更复杂;与部分工具链的适配需注意。 10.5 性能与影响在 COCO 上提供更优的精度‑参数/算力折中。ECVA
11. YOLOv10(2024,THU‑MIG):端到端 NMS‑free
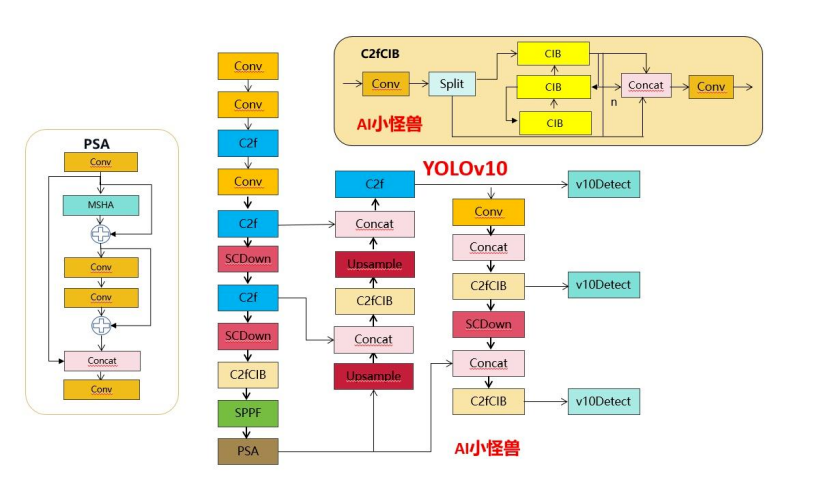
11.1 发表与背景相对 v9,提出一致的双分配,实现端到端 NMS‑free;并以效率‑精度协同设计重构各部件。arXiv+1 11.2 网络结构双分配训练 + 统一度量,配合更高效的主干/颈部/头部组合;整体延迟降低。
arXiv 11.3 核心创新点(相对 v9)消除 NMS 后处理与阈值敏感,拥挤重叠目标更稳。arXiv 11.4 局限与不足需要端到端链路完整适配与评估。 11.5 性能与影响各尺寸上刷新效率‑精度边界,便于上线。arXiv
12. YOLOv11(2024,Ultralytics):更高 mAP、更少参数
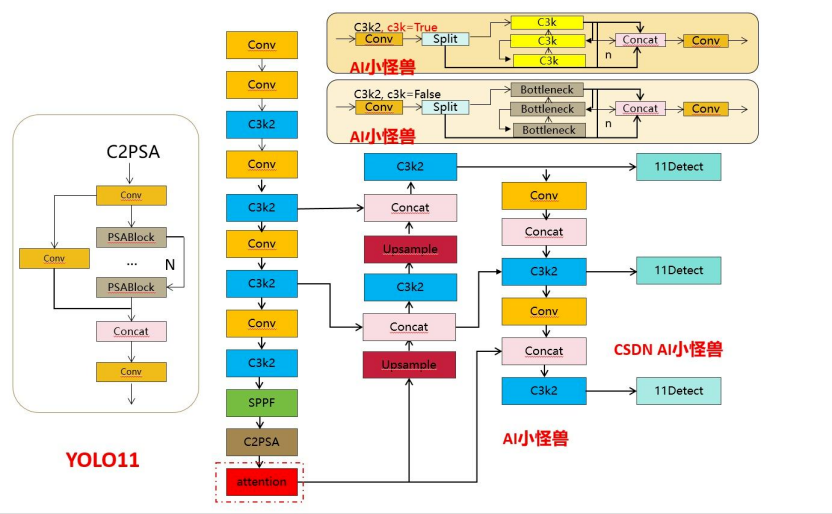
12.1 发表与背景相对 v10,Ultralytics 路线继续优化结构与训练配方:在相近规模下以更少参数取得更高 mAP,并延续 v8 的多任务与完善工具链。Ultralytics Docs+1 12.2 网络结构改进主干/颈部与训练流水线,提供 n/s/m/l/x 多尺度模型与多任务权重。
Ultralytics Docs 12.3 核心创新点(相对 v10)工程默认与生态完善,迁移/部署更轻松。Ultralytics Docs 12.4 局限与不足官方细节以文档为主,论文化阐述较少。 12.5 性能与影响在 CPU/边缘侧也体现更优参数‑速度优势,适合新项目默认选型。Ultralytics Docs
13. YOLOv12(2025):注意力中心的 YOLO
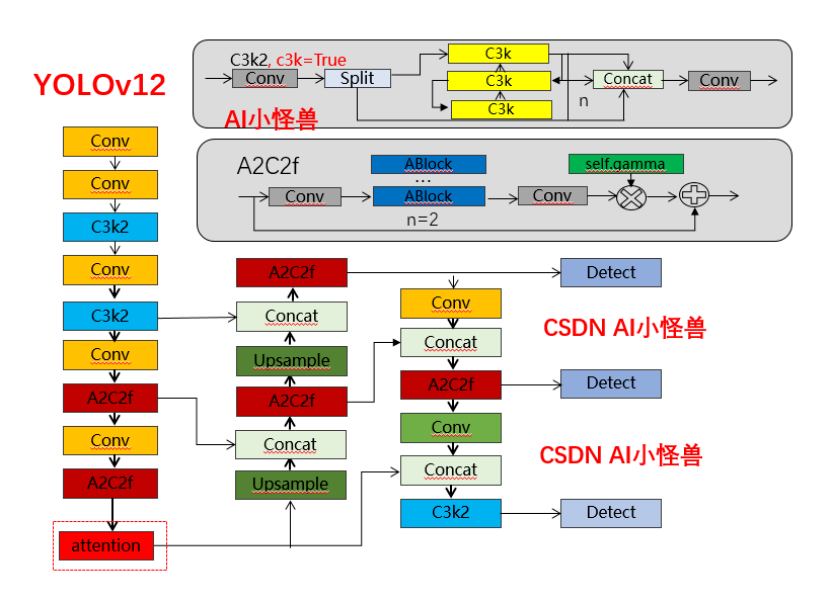
13.1 发表与背景相对 v11,引入Area Attention(A²)*与*R‑ELAN等,让注意力在接近 CNN 速度下发挥更强全局建模能力。arXiv+1 13.2 网络结构A² 进行区域化自注意与高效计算,R‑ELAN 优化信息流;报告中亦提到基于 FlashAttention 的实现思路。
arXiv 13.3 核心创新点(相对 v11)在复杂/长程依赖场景中以几乎不增延迟**的方式提升精度与稳健性。arXiv 13.4 局限与不足注意力算子对硬件与软件栈有一定要求。13.5 性能与影响在多数据集上取得更优 mAP‑Latency 平衡,扩展 YOLO 的应用边界。PyImageSearch
14. YOLOv13(2025):超图相关与全流程分发
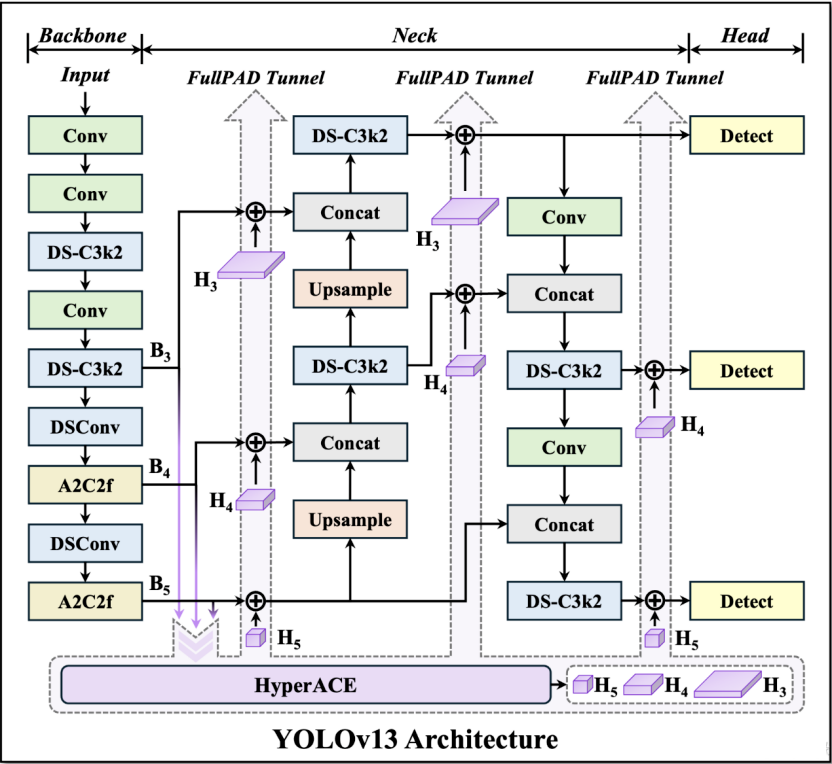
14.1 发表与背景相对 v12,YOLOv13 提出 HyperACE 超图相关增强与 FullPAD 全流程聚合‑分发,把点对点相关建模升级为多对多高阶,并以 DS‑Conv维持轻量高效。arXiv+1 14.2 网络结构基于超图的全局跨位置/跨尺度相关建模;FullPAD 将增强特征贯穿全管线;用深度可分离/大核替代以降参。
arXiv 14.3 核心创新点(相对 v12)在拥挤/遮挡/多目标交互场景下显著增强多实体关系刻画,保持实时性。arXiv 14.4 局限与不足超图/大核的实现与推理优化需要更细的工程适配。 14.5 性能与影响COCO 等基准上以更少参数与 FLOPs 获得 SOTA 级表现;代码与 Demo 已开源。GitHub
四、总结与思考
YOLO 系列在过去的近十年间,不断演进,从 YOLOv1 到 YOLOv13,经历了如下关键变化:
-
从单纯的回归到 Anchor 机制
-
YOLOv1 仅使用简单的网格回归,而 YOLOv2 引入了 Anchor Boxes,极大提高了对多尺度目标的适应性。
-
从浅层网络到深层残差网络
-
从最初的 Darknet-19 到 Darknet-53、CSPDarknet53,以及后来的融合 Transformer,网络深度和结构的不断演进使 YOLO 在特征提取能力上显著增强。
-
多尺度与注意力融合
-
YOLOv3 开始的多尺度预测、YOLOv4 中的大量 Bag of Freebies 与 Bag of Specials、后续 YOLOv9 ~ YOLOv12 对注意力模块的探索,使得网络对小目标、复杂背景等场景更具鲁棒性。
-
工业化与易用性
-
YOLOv5、YOLOv6、YOLOv7、YOLOv8 等版本在工程化上下了大功夫,使得开发者可快速上手并在实际项目中部署。
-
高精度与实时性并重
-
YOLO 始终强调在高 FPS(Frames Per Second)的基础上不断追求更高精度,并在后续版本中进一步缩小与双阶段检测器的精度差距。
未来展望:
-
随着 Transformer 在视觉领域的深入,YOLO 也将更多地借鉴 ViT、Swin Transformer 等思路,引入全局注意力与局部卷积相结合的特征提取方式。
-
半监督、弱监督等学习方式可能被更多地整合到 YOLO 中,以减少对大规模标注数据的依赖。
-
边缘计算与移动端部署需求的增长,会促使 YOLO 系列在轻量化、量化、剪枝等方面进一步优化。
-
在多模态(图文、视频、3D 点云)融合下,YOLO 系列可能扩展到更丰富的场景,如图文检测、视频时序检测、点云检测等。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 42
42 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)