VISTA:分层操作策略的规模化世界模型
26年2月来自西安交大、北京智源、清华、新加坡国立和中科院自动化所的论文“Scaling World Model for Hierarchical Manipulation Policies”。视觉-语言-动作(VLA)模型在通用机器人操作方面展现出巨大潜力,但在分布外(OOD)场景下,尤其是在真实机器人数据有限的情况下,其泛化能力仍然较弱。为了解决泛化瓶颈问题,引入一个分层视觉-语言-动作框架V
26年2月来自西安交大、北京智源、清华、新加坡国立和中科院自动化所的论文“Scaling World Model for Hierarchical Manipulation Policies”。
视觉-语言-动作(VLA)模型在通用机器人操作方面展现出巨大潜力,但在分布外(OOD)场景下,尤其是在真实机器人数据有限的情况下,其泛化能力仍然较弱。为了解决泛化瓶颈问题,引入一个分层视觉-语言-动作框架VISTA,该框架利用大规模预训练世界模型的泛化能力,实现了鲁棒且可泛化的视觉子目标任务分解(VISTA)。我们的分层框架VISTA由一个作为高层规划器的世界模型和一个作为底层执行器的VLA组成。高层世界模型首先将操作任务分解为包含目标图像的子任务序列,而底层策略则根据文本和视觉指导生成动作序列。与原始的文本目标描述相比,这些合成的目标图像为底层策略提供视觉和物理上的细节,使其能够泛化到未见过的物体和新的场景。在大规模分布外场景中验证视觉目标合成和提出的分层VLA策略,结果表明,在世界模型生成的指导下,相同结构的VLA在新场景中的性能提升14%至69%。
如图所示分层VISTA: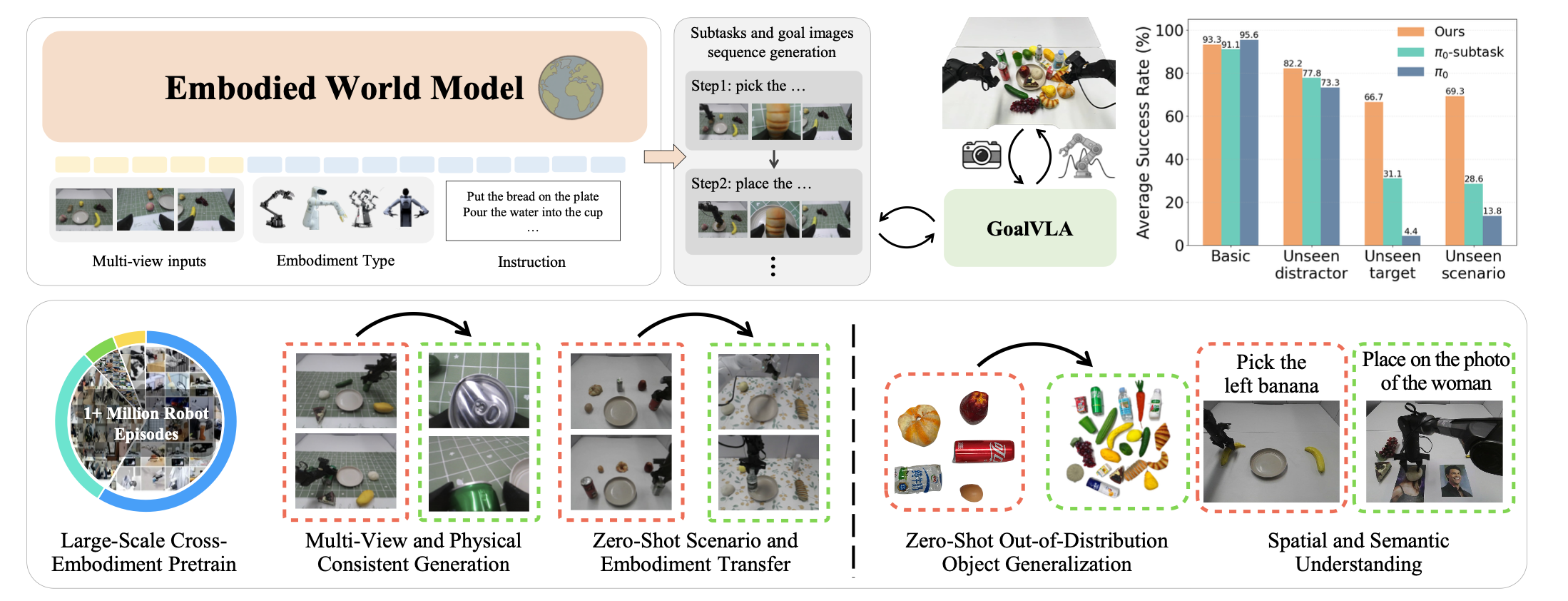
如图所示VISTA 概述。该框架包含两个基本模块:左图是VISTA 作为高级规划器。它将视觉目标和文本子任务视为一个统一的多模态序列,并根据全局指令和初始观察结果,自回归地生成交错的文本子任务和视觉目标。右图是GoalVLA 作为底层控制器。它以实时观察结果和生成的子目标作为输入,预测可执行的动作块。执行过程采用分层管理,子任务切换器在当前阶段完成后切换到下一阶段。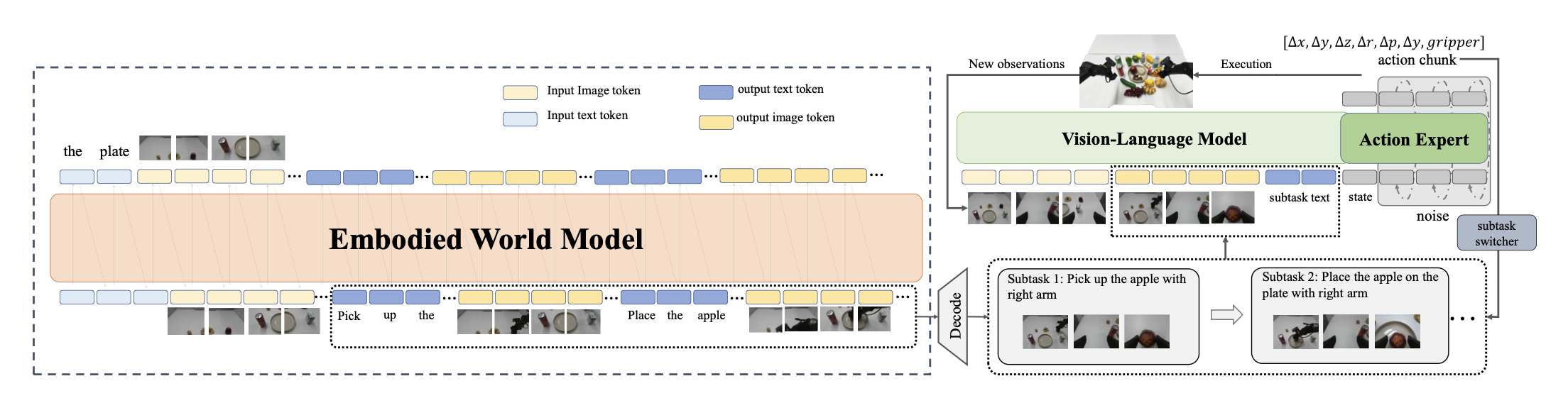
世界模型规划器
为了实现高层次的规划,引入具身世界模型(记为 W),该模型将全局指令 L 分解为可执行的里程碑(l_i,g_i)。通过将视觉目标和文本子任务视为统一的多模态序列,W 可以根据生成的历史记录自回归地预测任务的下一阶段。
a) 模型构建:采用统一的离散表示,将视觉和语言映射到共享词汇表 V 中。用 IBQ token化器 [38] 处理图像,使用 Qwen3 token化器 [1] 处理文本,两者统称为分词函数 φ。按固定顺序展平的多视图图像和文本被转换为离散的token序列 S。
这使得全局上下文 (I_0, L) 和交错里程碑 (l_i, g_i) 统一为 Transformer 的单一同质输入。基于统一的序列公式,该模型通过标准自回归建模进行训练,以学习任务序列的联合分布。优化序列 S 上的交叉熵损失 L,最大化给定前一个上下文的下一个token似然性。
让θ_W 表示模型参数。训练采用教师强制和因果注意掩码,确保第 k 步的预测仅取决于历史token u_<k。
b)子任务规划:在推理过程中,生成过程通过迭代采样以自回归方式进行,从而预测里程碑序列。从初始上下文 (φ(I_0), φ(L)) 开始,模型使用束搜索依次预测后续子任务和目标图像的token。具体来说,维护一个包含 B 个候选序列的集合(其中 B 为束宽)。在每个步骤 j,给定当前的token历史记录 S_<j = (u_1, …, u_j−1),计算输出 logits,并用最有可能的 B 个后续tokens扩展每个候选序列。候选序列 S 的联合概率计算为其组成tokens的条件概率的乘积。
采样过程重复进行,直至为所有候选序列生成终止token。然后,选择总体概率最高的序列,并使用逆token化器 φ−1 在像素级别重建目标图像 g_i。这种方法能够生成基于初始输入的全局一致里程碑序列,从而有效降低贪婪解码中可能出现的次优token-级决策风险。在开源的 EMU3.5 [16] 检查点上进行持续训练,该检查点使用包含导航和操作的交错文本图像数据进行训练,共训练 2000 步。
目标-条件的视觉-语言-动作 (VLA)模型 GoalVLA
利用世界模型的规划能力,训练一个目标图像引导的视觉-语言-动作 (VLA) 策略 π_θ,作为用于细粒度操作的底层控制器。
a) 模型构建:在阶段 i 的每个时间步 t,策略以当前观测值 I_t、子任务指令 l_i 和对应的目标图像 g_i 作为输入,预测一个驱动机器人向里程碑移动的动作块 a。为了有效地融合视觉信息,在将输入馈入到模型主干之前,将当前观测值tokens与目标图像tokens连接起来,从而扩展输入表示。
借鉴 π0 [6] 的架构,用流匹配目标来训练策略,以生成连续的动作轨迹。定义噪声样本 z ∼ N (0, I) 与真实动作块 a 之间的线性插值 x_τ = (1 − τ)z + τ_a,其中 τ ∈ [0, 1] 表示流时间。策略预测在 (l_i , I_t , g_i ) 条件下对应的速度场 v_τ = a−z。目标是最小化期望均方误差。
b) 子任务-觉察的动作填充:动作块可能跨越子任务边界(即包含属于阶段 i+1 的步骤)。为了防止策略在没有更新目标的情况下过早执行下一阶段,对每个真实数据块中当前里程碑完成后的部分进行零填充,从而显式地教会策略在目标 g_i 满足后停止执行。
c) 随机目标图像偏移:世界模型预测的目标图像可能相对于真实的子任务终止时间提前/延迟几帧,这可能会导致阶段边界附近的执行不稳定。为了使 GoalVLA 对这种错位具有鲁棒性,在子任务 i 和 i+1 的边界周围定义一个时间重叠窗口。对于此窗口内的训练样本,随机使用 g_i 或 g_i+1 作为目标条件;当使用 g_i+1 时,还会将样本重新标记为阶段 i+1,以避免零填充。对于阶段 i 的其余样本,从终端重叠窗口中随机采样 g_i,而不是使用固定的目标帧。这种简单的增强方法使策略能够应对边界噪声,并促进平滑的阶段过渡。
数据集整理
a) 数据集来源:用来自 Open-X-Embodiment [36]、AgiBot World Beta [9] 和自己的 Mobile Aloha 数据集 [21] 这些大规模具身操作数据来训练世界模型。尽管语料库包含超过 100 万条轨迹,但标注仅包含全局指令和图像-动作对,缺少中间里程碑(l_i,g_i)。因此,引入一个自动轨迹分解流程。
b) 自动里程碑标注:该流程分为三个步骤。首先,用 Qwen3 [46] 对指令动词进行聚类,构建一个包含 50 个原子技能(例如,拾取、推动)的库。其次,利用Ramer-Douglas-Peucker (RDP)算法[17]分析运动轨迹和机械臂状态转换,通过物理状态变化检测候选里程碑边界。最后,Qwen2.5-VL 72B算法[2]合并具有相同技能的相邻片段,并生成自然语言子任务描述l_i。
该过程将120万条轨迹转换为交错的子任务和目标图像序列,涵盖14种支持多视角的实现方式,总计152亿个tokens(如图所示)。对于AgiBot,进一步将抽象任务类型细化为更细粒度的指令。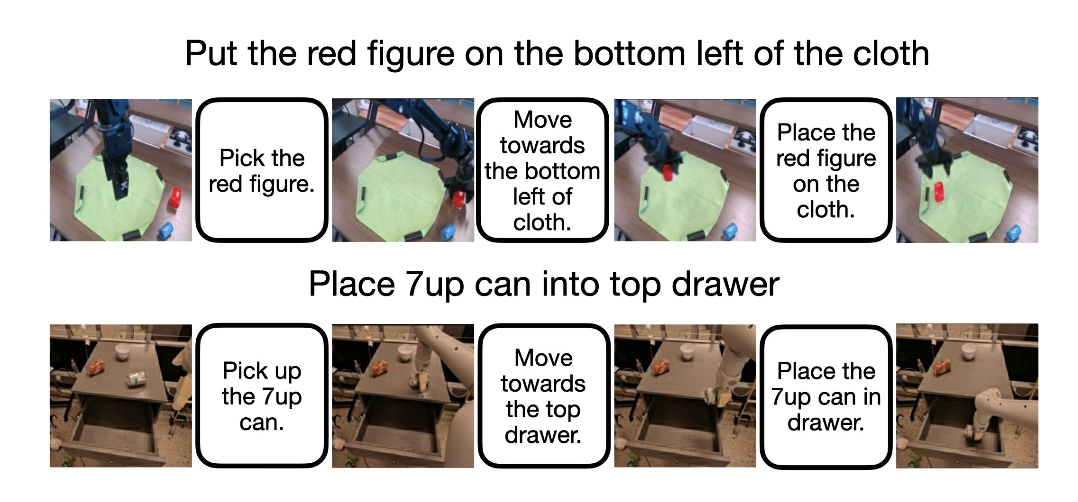
c) X-到-图像预训练数据:用由 SEED-Data-Edit [22]、Weather-Stream [53]、ShareGPT-4o-Image [11] 等构建的 150 亿个tokens的X-到-图像数据集来共同训练世界模型。
实现细节
世界模型规划器
a) 模型架构和token化:构建的世界模型总共包含 341 亿个参数,其中 312 亿个参数位于 Transformer 层,29 亿个参数位于嵌入层。token化方面,采用包含 282,926 个tokens的统一词汇表。视觉部分,用 EMU3.5 [16] 中预训练的 IBQ-token化器,其词汇量为 131,072,并将每个 16 × 16 的图像块量化为离散的tokens。具体来说,在设置中,输入图像被调整为 512 × 512 的分辨率,因此每张图像生成 1024 个视觉tokens。语言部分,用词汇量为 151,854 的 Qwen3 token化器 [1]。
b) 序列格式化:将最大序列长度设置为 16,384,每个序列都使用交错的文本和视觉tokens进行格式化。对于监督学习,仅提供指令和初始观测值,模型需要自回归地预测整个交错序列。由于一个序列最多包含 16 张图像,随机选取目标图像时间戳前后 1 秒内的时间戳进行采样,并让模型预测后续步骤。因此,序列可以从任意子任务阶段开始,并持续生成子任务和目标图像序列,直到任务完成或达到提示中要求的阶段数。这种滑动窗口式的操作不仅增加了数据集的大小和多样性,而且实现了无限闭环生成。
c) 模型训练:在训练设置中,用 Megatron-LM [39] 训练世界模型,张量并行大小设置为 8,上下文并行大小设置为 1。全局批大小为 512,学习率为 1 × 10⁻⁵。在开源的 EMU3.5 [16] 检查点上进行 2000 步的持续训练。用 128 个 Nvidia H100 GPU 对 VISTA 进行为期 2 天的后训练,采用余弦学习率调度器和线性预热。
目标条件化的 VLA- GoalVLA
a) 模型架构:采用类似于 π0 [5] 的 MoE 架构,以 PaliGemma-3B [3] 为骨干网络,并同时构建一个 0.3B 规模的动作专家模型。采用分块因果掩码,其中 VLM 模块关注自身特征,本体感觉模块(与动作模块共享权重)关注自身特征以及 VLM 模块的特征,动作模块关注所有模块;每个模块内部都是完全双向的。在每个推理步骤中,模型以六张图像作为输入,包括三张当前观测图像和三张目标图像,这些图像通过 SigLIP [52] 编码成tokens。模型还以当前子任务提示和代表机械臂末端执行器 6D 位姿的本体感觉信号作为输入。随后,执行一个 10 步的流匹配解码过程,生成一个长度为 30 步的动作块。
b) 两阶段训练设置:为 GoalVLA 采用两阶段训练范式。在第一阶段,用来自 AgiBot-Beta 数据集 [9] 的 20 万条轨迹样本,并使用标注的子任务文本和目标图像作为附加条件。该阶段包含 10 万个训练步骤,全局批大小为 512,初始学习率为 5 × 10⁻⁵。在第二阶段,用 737 条自行收集的机器人轨迹对 GoalVLA 进行微调。将全局批大小设置为 128,学习率为 2 × 10⁻⁵,训练模型 10 个 epoch(约 2 万步)。
c) 推理细节:在实际机器人部署和测试阶段,为了减轻运动误差的影响,并使模型能够更精细地调整机器人,仅执行模型推断出的动作块中 30 个步骤中的 10 个步骤。采用闭环绝对末端执行器 (EE) 位姿控制来操作机械臂。由于模型输出的是 Δ EE 位姿,基于当前读取的本体感受信号计算绝对 EE 位姿。为了获得更平滑的控制,选择第 5 步和第 10 步的绝对 EE 位姿作为执行目标路径点。
利用提出的自动分割和标注框架,将120万条轨迹分割成交错的子任务和目标图像格式,支持10种不同的实现方式和多视角生成。对于Agibot World Beta数据集,进一步利用Qwen2.5-VL 72B [2] 将抽象的任务类型细化为详细的指令,并将原始技能描述分割成更细粒度的子任务。
作为一种基本的单步生成任务,X2I生成通常涉及由文本和任意数量图像组成的任意多模态交错输入,要求模型输出单个图像作为响应。这给模型的关键能力提出很高的要求,尤其是在多模态指令跟踪、保持主体/背景一致性、遵循世界知识和规则以及控制图像风格和纹理方面。掌握这些极具挑战性的 X2I 能力将有助于模型稳健地演进到更通用的任意-到-任意 (X2X) 生成范式,从而使其发展成为一个更复杂、更强大的世界模型。为此,构建一个大规模的 X2I 数据集(包含 152 亿个 token)用于训练,以克服现有开源数据在多样性、质量和规模方面的局限性。该内部 X2I 数据集还整合多个开源数据集的部分内容,包括 SEED-Data-Edit [22]、WeatherStream [53]、PromptFix [51]、OmniGen-X2I [45]、ShareGPT-4o-Image [11]、ImgEdit [50]、OmniGen2-X2I2 [43]、MultiRef [12] 和 GPT-IMAGE-EDIT-1.5M [42]。为了提高空间理解和多视图一致性,进一步使用 mast3r [30] 去标注从同一场景拍摄的多张图像的相对位置,并构建相机视图编辑数据集。
真实世界任务和设置
对于训练数据集,收集 2 小时的抓取放置任务数据,任务包含五个物体:鸡蛋、可乐罐、苹果、牛奶桶和羊角面包。选择具有显著影响和出色性能的 π0 模型作为基线模型。为了进一步说明子任务指令的影响,修改 π0 的训练范式,将数据集中的原始指令替换为子任务,并将此变型称为 π0-subtask。
如图所示,在域内场景和域外场景 (OOD) 上评估这些方法。对于域内场景,除了基本设置外,还将干扰物和目标物替换为未见过的物体。在域内场景的每种设置下,共有 5 个任务 × 3 种场景设置(布局和未见过物体的组合)= 15 个场景。对于 OOD 场景,引入 21 个具有不同语义类型的新物体,并针对每个场景抽取 5 个物体作为样本,其中一个被选为目标物体,其余四个被选为干扰物体。因此,共有 21 个目标物体 × 3 种场景设置(桌布和布局的组合)= 63 个场景。对于每个场景,对模型进行 3 次评估并计算平均指标,因此每个策略共进行 78 个场景(15 个领域内场景 + 63 个 OOD 场景)× 每个场景 3 次部署 = 234 次部署。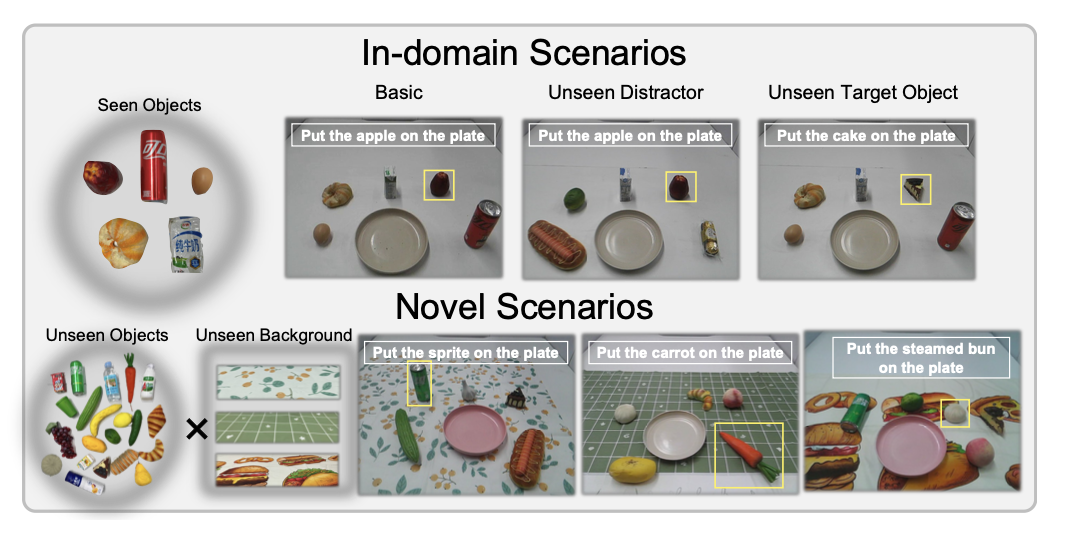

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 13
13 0
0- 0



 已为社区贡献211条内容
已为社区贡献211条内容

所有评论(0)