论文笔记-Onboard dynamic-object detection and tracking for autonomous robot navigation with RGB-D camera
本文提出一种基于RGB-D相机的轻量级三维动态障碍物检测与跟踪方法(DODT),专为资源受限的机器人设计。系统采用三种计算效率高的非学习型检测器(U-depth、DBSCAN、YOLO-MAD)进行集成检测,通过特征匹配和IOU验证实现鲁棒识别,并引入可选学习模块增强性能。跟踪模块提出基于特征向量的匹配方法和恒加速度卡尔曼滤波,通过融合位置、尺寸和点云统计特征,有效解决目标混淆问题,在保证实时性的
阅读笔记-1
“Onboard dynamic-object detection and tracking for autonomous robot navigation with RGB-D camera” )
文章目录
粗略阅读
传感器:RGB-D 相机(获取彩色与深度)
现状:动驾驶领域已经有大量研究探索三维目标检测问题,但这些方法普遍依赖高密度点云数据(来自体积大、功耗高的 LiDAR传感器),并且其学习型数据处理算法计算开销极大,
创新:提出一种基于 RGB-D相机的轻量级三维动态障碍物检测与跟踪方法(DODT),专为低功耗、计算资源受限的机器人设计。将多个计算量小但精度低的检测器组合起来,实现实时且高精度的障碍物检测;提出了一种基于特征的关联与跟踪方法,利用点云的统计特征来防止匹配错误,系统还包含一个可选的、辅助性的学习型检测模块YOLO/PointNet,用于增强障碍物的检测距离和动态目标识别能力
检测模块
包含非学习型部分与学习型部分。
-
非学习部分:利用深度图像和两个非学习检测器来进行通用障碍物检测。
-
学习部分:使用对齐的 RGB-D 图像进行直接动态障碍物检测,并与非学习部分结果融合
三种低精度但高效率的检测器:

U-depth 检测器
-
U-depth 图生成:
将深度图像按列计算深度直方图形成 “U-depth 图”。
直观上可以理解为相机视角的“俯视图(top-down view)”。 -
线条分组(Line Grouping):
在 U-depth 图上分组线条以获得障碍物在图像平面的宽度 w i w_i wi 和厚度 t i t_i ti。 -
深度连续性检测(Depth Continuity Search):
在原始深度图上检查深度连续性,以获取障碍物的高度 h i h_i hi。 -
三维重建:
将 2D 检测框投影到三维相机坐标系,再通过坐标变换得到世界坐标系下障碍物的位置与尺寸。
DBSCAN 检测器:或许可以用到
功能概述:
基于点云的聚类算法。
-
使用深度图生成点云;
-
应用体素滤波(voxel filter)去除噪声;
-
使用 DBSCAN 聚类提取每个障碍物的点云;
-
为每个簇生成轴对齐边界框。
YOLO-MAD 检测器
功能概述:
用于识别障碍物类型与远距离动态障碍检测。
基于轻量级 YOLOFastestDet(CPU级实时),扩展到 3D。
流程:
-
在 RGB 图像中检测 2D 边界框;
-
在对应的深度图区域提取深度信息;
-
通过 MAD(Median Absolute Deviation,中位绝对偏差) 计算障碍物厚度,剔除异常深度值;
-
将深度范围内的点三角化得到 3D 包围框。
公式核心:
M A D = m e d i a n ( ∣ d i − d ~ ∣ ) MAD = median(|d_i - \tilde{d}|) MAD=median(∣di−d~∣),
S M A D = { d i ∣ d ~ − n ⋅ M A D ≤ d i ≤ d ~ + n ⋅ M A D } S_{MAD} = \{d_i | \tilde{d} - n·MAD ≤ d_i ≤ \tilde{d} + n·MAD\} SMAD={di∣d~−n⋅MAD≤di≤d~+n⋅MAD}。
理解:
MAD 方法相当于鲁棒的深度滤波,避免背景和噪声影响。
由于仍较耗算力,YOLO-MAD 是可选辅助模块。
集成检测
结合三种检测结果以提升鲁棒性与精度,消除单一传感器的噪声误差。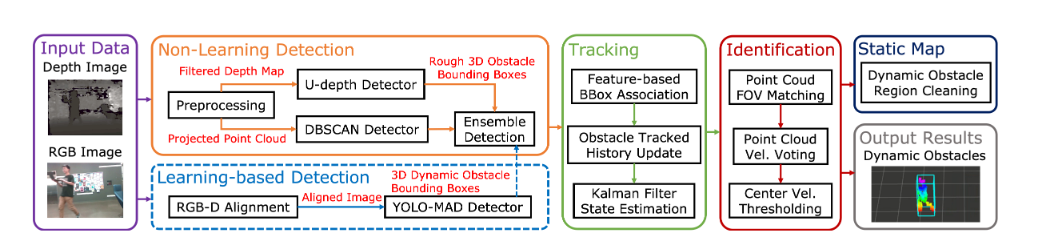
问题1:使用深度图获得的点云存在误差吧
-
距离越远、表面越光滑或透明,误差越大
-
深度像素 ( u , v ) (u,v) (u,v) 转换为点云 ( x , y , z ) (x,y,z) (x,y,z) 时需用到内参矩阵 K K K
问题2:集成检测没看懂
-
三个检测器都会输出3D框 -
IOU 都超过一定阈值(例如0.5)→ 才认为它们确实检测到的是同一个障碍物
for 每个bd1 in Bd1: 找出 Bd2 中与之 IOU 最大的框 bmatch1 再反查:在 Bd1 中找 bmatch1 的 IOU 最大框 bmatch2 若 bmatch2 == bd1 且 IOU > 阈值: fuse(bd1, bmatch1) -
位置 (center):取平均+尺寸 (width, height, depth):取最大(保守做法,宁大勿漏)
跟踪模块
- 使用经过优化的三维边界框(3D bounding boxes)及历史数据来估计障碍物状态(位置、速度、加速度等)
通过障碍物特征向量匹配不同时间帧的障碍物:使用形状、尺寸、点云统计量,因此不易混淆“人和墙”这类误匹配
f e a t ( O i ) = [ p o s ( i ) , d i m ( i ) , l e n ( i ) , s t d ( i ) ] feat(O_i) = [pos(i), dim(i), len(i), std(i)] feat(Oi)=[pos(i),dim(i),len(i),std(i)]
并计算相似度:
s i m ( O i , O j ) = e − ∣ ∣ f e a t ( O i ) − f e a t ( O j ) ∣ ∣ 2 / 2 sim(O_i, O_j) = e^{-||feat(O_i) - feat(O_j)||^2/2} sim(Oi,Oj)=e−∣∣feat(Oi)−feat(Oj)∣∣2/2
若相似度大于阈值,则认为是同一障碍物。
此外,使用预测位置代替旧位置以提高匹配稳定性
问题3:中心距离匹配会误把“人”匹配到“墙”,为什么
-
中心距离匹配只看两个框中心点的欧氏距离
假设上一帧的人在点A,下一帧他走到点B,而B离墙中心C更近:
→ 中心距离法会误认为“墙”是“人”的延续。
问题4,下面分别是什么
f e a t ( O i ) = [ p o s ( i ) , d i m ( i ) , l e n ( i ) , s t d ( i ) ] feat(O_i) = [pos(i), dim(i), len(i), std(i)] feat(Oi)=[pos(i),dim(i),len(i),std(i)]
每个分量含义如下👇:
-
pos(i):障碍物中心位置 ( x , y , z ) (x, y, z) (x,y,z)
-
dim(i):障碍物三维尺寸(宽、高、深)
-
len(i):点云中点的数量(反映大小或密度)
-
std(i):点云的标准差(反映形状复杂度或散布)
即:它综合考虑位置 + 尺寸 + 点云特性。
问题5:下面为什么这么设计
s i m ( O i , O j ) = e − ∥ f e a t ( O i ) − f e a t ( O j ) ∥ 2 / 2 sim(O_i, O_j) = e^{-\|feat(O_i) - feat(O_j)\|^2 / 2} sim(Oi,Oj)=e−∥feat(Oi)−feat(Oj)∥2/2
-
越相似 ⇒ 差距越小 ⇒ 指数项接近 1;
-
越不同 ⇒ 差距越大 ⇒ 指数项趋近 0。
-
墙与人的位置可能相近,但尺寸、std 差距巨大;因此 sim 值很低,不会被错误匹配
恒加速度卡尔曼滤波(Constant-Acceleration Kalman Filter)
状态向量:包含位置、速度、加速度
X = [ x , y , x ˙ , y ˙ , x ¨ , y ¨ ] T X = [x, y, \dot{x}, \dot{y}, \ddot{x}, \ddot{y}]^T X=[x,y,x˙,y˙,x¨,y¨]T
状态方程:
X t ∣ t − 1 = A X t − 1 + Q X_{t|t-1} = A X_{t-1} + Q Xt∣t−1=AXt−1+Q
测量方程:
Z t = H X t + R Z_t = H X_t + R Zt=HXt+R
与传统的恒速度模型不同,此模型允许速度变化(更准确),计算量仍可接受。
问题6:恒加速度卡尔曼滤波是干啥用的
1️⃣ 状态定义–目标的状态向量:位置 §、速度 (v)、加速度 (a) 三个分量
2️⃣ 状态转移模型(假设加速度恒定)–离散时间步长 Δt 进行状态更新:
-
x t + 1 = F x t + w t x_{t+1} = F x_t + w_t xt+1=Fxt+wt
论文里面
其中 w t w_t wt 是过程噪声, F F F 是状态转移矩阵:
F = [ 1 0 Δ t 0 0.5 Δ t 2 0 0 1 0 Δ t 0 0.5 Δ t 2 0 0 1 0 Δ t 0 0 0 0 1 0 Δ t 0 0 0 0 1 0 0 0 0 0 0 1 ] F = \begin{bmatrix} 1 & 0 & Δt & 0 & 0.5Δt^2 & 0 \\ 0 & 1 & 0 & Δt & 0 & 0.5Δt^2 \\ 0 & 0 & 1 & 0 & Δt & 0 \\ 0 & 0 & 0 & 1 & 0 & Δt \\ 0 & 0 & 0 & 0 & 1 & 0 \\ 0 & 0 & 0 & 0 & 0 & 1 \end{bmatrix} F= 100000010000Δt010000Δt01000.5Δt20Δt01000.5Δt20Δt01
这样目标的位置和速度会根据恒定加速度模型进行预测
3️⃣ 观测模型
-
检测器只能观测到目标的位置(中心点坐标):
z t = H x t + v t z_t = H x_t + v_t zt=Hxt+vt
其中大部分情况 H = [ 1 0 0 0 0 0 0 1 0 0 0 0 ] H = \begin{bmatrix} 1 & 0 & 0 & 0 & 0 & 0 \\ 0 & 1 & 0 & 0 & 0 & 0 \end{bmatrix} H=[100100000000],
v t v_t vt 是观测噪声。
4️⃣ 预测 + 校正(标准卡尔曼步骤)
预测阶段
x ^ t ∣ t − 1 = F x ^ t − 1 \hat{x}_{t|t-1} = F \hat{x}_{t-1} x^t∣t−1=Fx^t−1
P t ∣ t − 1 = F P t − 1 F T + Q P_{t|t-1} = F P_{t-1} F^T + Q Pt∣t−1=FPt−1FT+Q
更新阶段
计算卡尔曼增益 K_t
K t = P t ∣ t − 1 H T ( H P t ∣ t − 1 H T + R ) − 1 K_t = P_{t|t-1} H^T (H P_{t|t-1} H^T + R)^{-1} Kt=Pt∣t−1HT(HPt∣t−1HT+R)−1
含义:
-
K 决定“信测量多少、信预测多少”;
-
P 大 / R 小 → K 大(信测量多);
-
P 小 / R 大 → K 小(信预测多)。:
用测量更新状态
x ^ t = x ^ t ∣ t − 1 + K t ( z t − H x ^ t ∣ t − 1 ) \hat{x}_t = \hat{x}_{t|t-1} + K_t (z_t - H\hat{x}_{t|t-1}) x^t=x^t∣t−1+Kt(zt−Hx^t∣t−1)
含义:
-
括号里 ( z t − H x ^ t ∣ t − 1 ) (z_t - H\hat{x}_{t|t-1}) (zt−Hx^t∣t−1):叫残差(innovation),表示“测量与预测的差”;
-
K t K_t Kt:调节信任度;
-
x t x^t xt:校正后的最优估计。
更新协方差
-
P t = ( I − K t H ) P t ∣ t − 1 P_t = (I - K_t H) P_{t|t-1} Pt=(I−KtH)Pt∣t−1
论文实际使用:
1️⃣ 状态定义
X = [ x , y , x ˙ , y ˙ , x ¨ , y ¨ ] T X = [x, y, \dot{x}, \dot{y}, \ddot{x}, \ddot{y}]^T X=[x,y,x˙,y˙,x¨,y¨]T
也就是障碍物在全局坐标下的:
2️⃣ 状态转移模型
状态转移方程(预测模型)
X t ∣ t − 1 = A X t − 1 + B u t − 1 + Q X_{t|t-1} = A X_{t-1} + B u_{t-1} + Q Xt∣t−1=AXt−1+But−1+Q
其中:
-
u = 0 u = 0 u=0:没有控制输入
-
Q Q Q:过程噪声协方差矩阵,代表模型的不确定性
-
A A A:状态转移矩阵,由“恒加速度”模型推导而来
-
状态转移矩阵 A
A = [ 1 0 δ t 0 1 2 δ t 2 0 0 1 0 δ t 0 1 2 δ t 2 0 0 1 0 δ t 0 0 0 0 1 0 δ t 0 0 0 0 1 0 0 0 0 0 0 1 ] A = \begin{bmatrix} 1 & 0 & \delta t & 0 & \frac{1}{2}\delta t^2 & 0 \\ 0 & 1 & 0 & \delta t & 0 & \frac{1}{2}\delta t^2 \\ 0 & 0 & 1 & 0 & \delta t & 0 \\ 0 & 0 & 0 & 1 & 0 & \delta t \\ 0 & 0 & 0 & 0 & 1 & 0 \\ 0 & 0 & 0 & 0 & 0 & 1 \end{bmatrix} A= 100000010000δt010000δt010021δt20δt010021δt20δt01
这是根据“匀加速度运动方程”推导的:
x t = x t − 1 + v t − 1 δ t + 1 2 a t − 1 δ t 2 x_t = x_{t-1} + v_{t-1}\delta t + \frac{1}{2}a_{t-1}\delta t^2 xt=xt−1+vt−1δt+21at−1δt2
v t = v t − 1 + a t − 1 δ t v_t = v_{t-1} + a_{t-1}\delta t vt=vt−1+at−1δt
a t = a t − 1 a_t = a_{t-1} at=at−1
3️⃣ 观测模型
测量向量 Z t Z_t Zt 定义为:
Z t = H X t + R Z_t = H X_t + R Zt=HXt+R
其中:
-
H = I H = I H=I:单位矩阵
意味着我们能直接观测到全部状态分量(位置、速度、加速度)。
实际上,这里的速度和加速度是由点云检测到的障碍物位置序列计算出来的。 -
速度、加速度的测量计算
V t = P t − P t − 1 δ t , A t = V t − V t − 1 δ t V_t = \frac{P_t - P_{t-1}}{\delta t}, \quad A_t = \frac{V_t - V_{t-1}}{\delta t} Vt=δtPt−Pt−1,At=δtVt−Vt−1
为了让观测更平滑,论文提到:会使用多个时间差 δ t \delta t δt 的数据平均后求 V t V_t Vt、 A t A_t At。
4️⃣ 预测 + 校正(标准卡尔曼步骤)
同上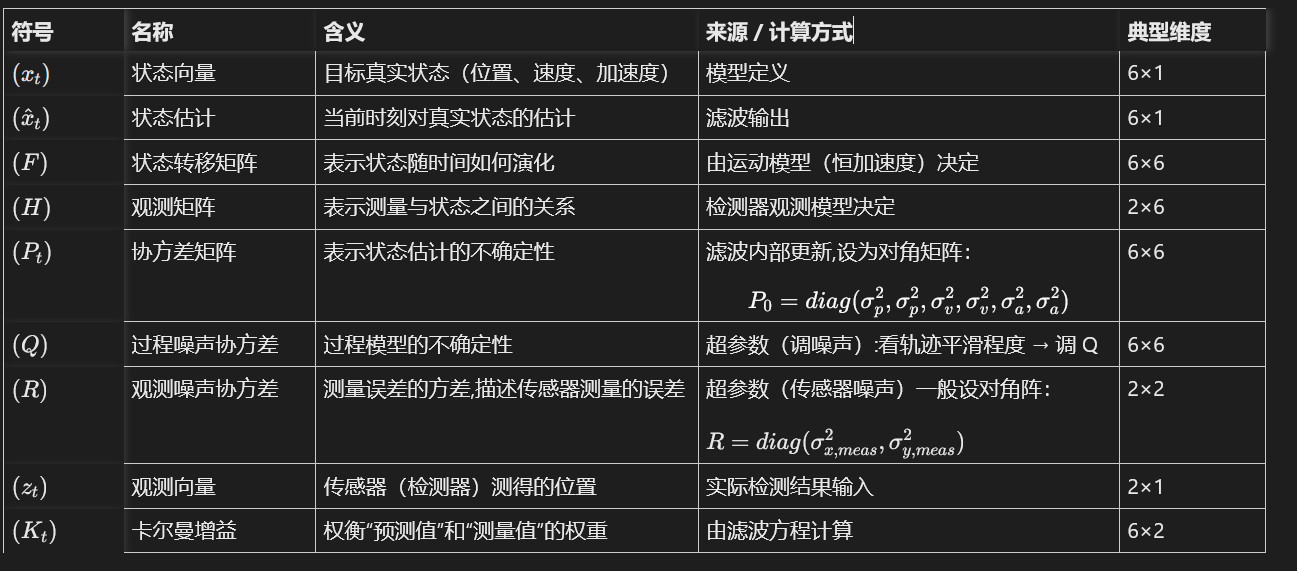
识别模块
- 根据状态变化与跟踪历史,将障碍物分类为静态(Static)或动态(Dynamic)
识别过程分两步:
-
速度阈值判定:
若障碍物中心速度 V c e n t e r < T v e l V_{center} < T_{vel} Vcenter<Tvel,判为静态。 -
点云投票法(Voting):
对障碍物点云中的每个点计算对应时刻的速度 V i v o t e V_i^{vote} Vivote:-
若 V i v o t e > T v o t e V_i^{vote} > T_{vote} Vivote>Tvote,该点投票为“动态”;
-
若动态点比例 N v o t e / N v a l i d > T r a t i o N_{vote}/N_{valid} > T_{ratio} Nvote/Nvalid>Tratio,则障碍物判为“动态”。
-
剔除无效点条件:
-
速度方向偏差过大(>90°);
-
在上一帧视野外(FOV外)的新点。
若启用 YOLO-MAD,其分类结果直接覆盖此识别。
问题7:什么是点云投票法
基本思路:
-
对每个障碍物的点云,记录当前帧 t n t_n tn 与过去某帧 t n − k t_{n-k} tn−k 的对应点;
-
每个点计算它的运动速度 V i v o t e V_i^{vote} Vivote;
-
如果这个速度大于某个阈值 T v o t e T_{vote} Tvote,该点就“投票”为动态;
-
若:
N v o t e N v a l i d > T r a t i o \frac{N_{vote}}{N_{valid}} > T_{ratio} NvalidNvote>Tratio
→ 认为整个障碍物是动态的。
问题8:部分遮挡时如何过滤新出现的点防止错误识别动态是什么意思
场景:
机器人逐渐靠近一个半遮挡的障碍物(例如桌子后面露出一角)。
-
在前一帧 t₁,只看到“红色点”;
-
到后一帧 t₂,机器人移动后能看到完整物体;
-
中心点会“跳动”(因为更多点出现);
→ 系统误以为这个物体动了。
解决方法:
过滤“新出现的点”:
-
判断在 t₁ 时,这些点是否在视野内(FOV)可见;
-
若之前根本没看到(被遮挡),那这些点不是运动引起的,而是视角变化带来的“假运动”;
-
因此在投票中剔除这些点。
📊 论文图示讲解(Figures)

总结
以上就是今天要讲的内容,本文仅仅简单介绍了论文

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 29
29 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)