ViLLA模型的隐动作空间:从LAPA到UniVLA
之前我们提到的要构建一种中间表征,这种基于Latent Action的就是一种很好的方法。总结来讲的话就是Encoder部分获取输入当前帧和未来帧得到输入两帧之间的动作表征;Decoder通过这个动作表征以及的输入来预测。通过这样一种自监督范式,我们可以发现这种 Latent Action Model 得益于VQ-VAE中间的 codebook 具有很强的信息瓶颈,所以他可以很好地学到两帧之间的
智元机器人在9.19日正式开源了通用机器人ViLLA模型GO-1。什么是ViLLA?它和VLA的区别是什么?本文旨在探究和思考VLA模型发展中,潜在动作空间加入并演化的过程
智元AgiBot-World的Github链接:OpenDriveLab/AgiBot-World: [IROS 2025 Award Finalist] The Large-scale Manipulation Platform for Scalable and Intelligent Embodied Systems
ViLLA (Vision-Language-Latent-Action)模型
动机(Motivation)
在ViLLA模型的概念提出之前,例如OpenVLA、Pi-0或者是RT-2这些VLA模型,都是在Low-Level action space 上进行大规模预训练,这样的训练要求的就是必须要有机器人真实的动作标签,这样就存在两方面问题:
一是像这样的机器人Low-Level数据的数量依然不够多。下图是机器人数据量与AI大模型的数据量的对比图,可以看到,相较于在互联网搜集大量数据的大语言模型,采集到的高质量机器人数据可谓是少之又少。
第二方面是不同的embodiment动作空间可迁移性很差。
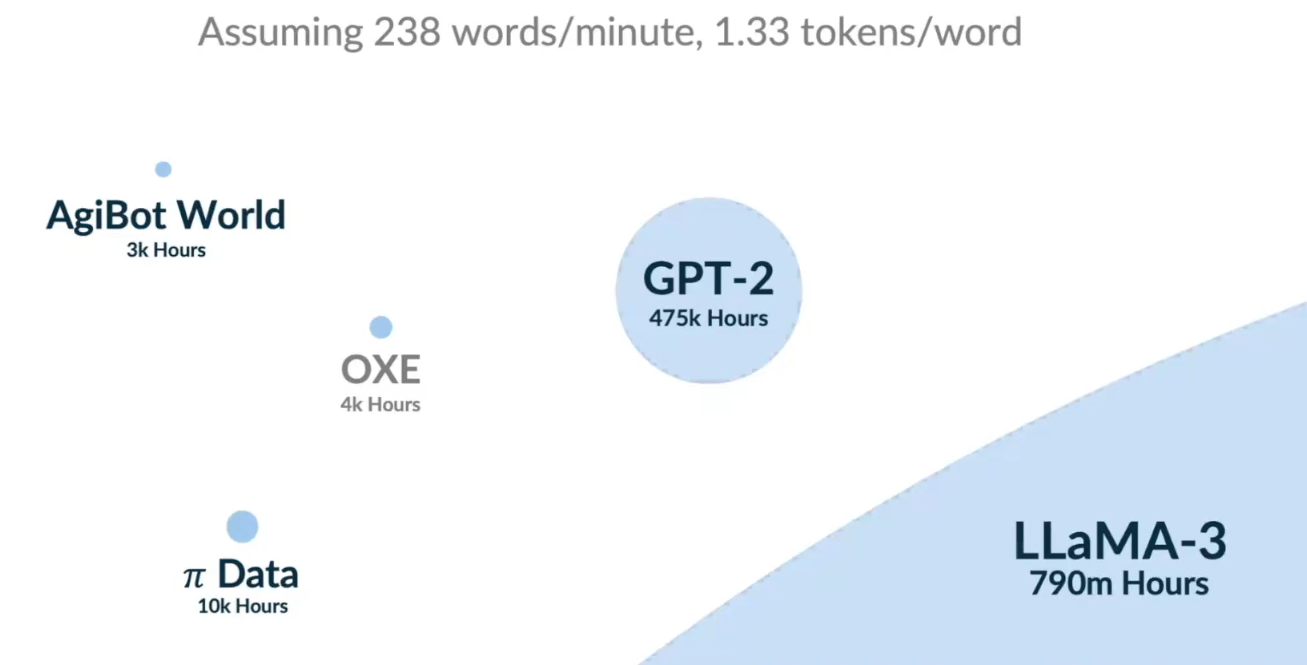
那么我们的朴素想法就是找到某种高于Low-Level级别的空间表征,使模型能在这个空间里做规划和学习,最好是能够利用到互联网上的海量数据(包括人类操作的数据)。隐式动作空间的想法应运而生。
模型架构
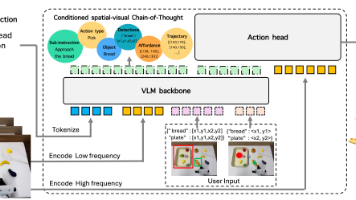
ViLLA引入潜在动作 token(latent action tokens)作为中间表征,通过显式学习“状态变化意图”,从而弥合视觉-语言输入与机器人动作执行之间的鸿沟。其整体架构由 VLM(多模态大模型) + MoE(混合专家体系)构成(不同于VLA的VLM+AE的架构),其中各组件职能明确并协同训练:
-
VLM(VIsion-Language-Model视觉-语言模型)
VLM借助海量互联网图文数据获得通用场景感知和语言理解能力 -
MoE(混合专家 Mixture of Experts)模块
-
Latent Planner(潜在动作规划器)
潜在动作规划器是ViLLA区别于VLA的主要模块,也是模型泛化性增强的主要创新点。其借助大量跨本体和人类操作视频数据获得通用的动作理解能力 -
Action Expert(动作执行专家)
借助百万真机数据获得精细的动作执行能力
-
整个体系通过“视觉-语言理解 → 潜在意图规划 → 精细控制执行”三层结构实现强泛化与高精度执行能力。
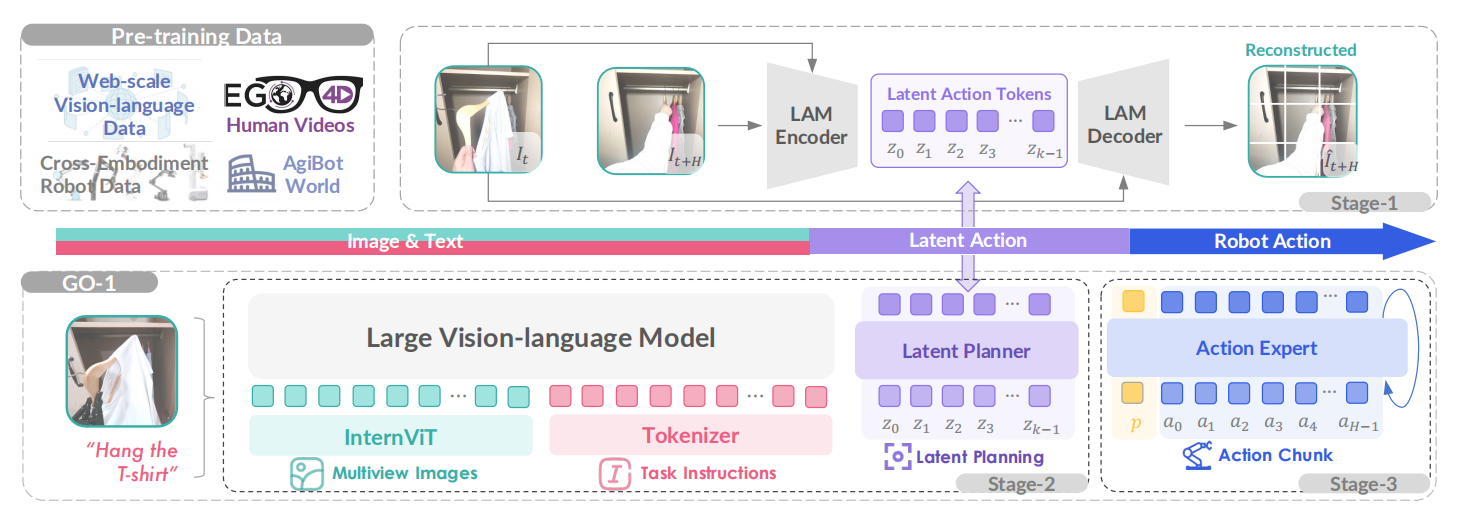
以智元GO1-为例,ViLLA模型GO-1在训练阶段分为三个阶段:
- 第一阶段,通过在互联网规模的异构数据上训练编码器-解码器潜在动作模型(LAM),将连续图像映射到潜在动作空间
- 第二阶段中,这些潜在动作作为潜在规划器的伪标签,既支持与具身无关的长期规划,又能充分发挥预训练VLM的泛化能力
- 第三阶段,我们引入动作专家模块,并与潜在规划器协同训练,从而支持灵巧操作的学习
理解ViLLA模型,让我们先从对 Latent Action 的探索开始......
LAPA:来自视频的隐式动作预训练
LAPA这篇论文在24年10月被提出,其提及到的无需真实机器人动作标签即可对机器人基础模型进行无监督预训练的方法在AgiBot World论文中被多次引用。
[2410.11758] Latent Action Pretraining from Videos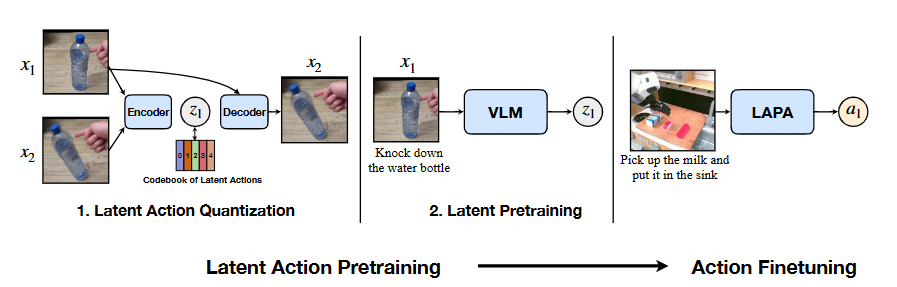
这种完全无监督训练的特点主要体现在以下两个阶段:
- 潜在动作量化(Latent Action Quantization):在这个阶段,模型利用VQ-VAE目标以完全无监督的方式学习离散的潜在动作。这意味着在学习这些动作时,不需要任何预先定义的人工标签或机器人动作信息。模型是根据原始图像帧之间的潜在变化来自动发现和量化动作的。
- 潜在动作预训练(Latent Pretraining):在这个阶段,视觉-语言模型(VLM)被训练来预测在第一阶段学习到的潜在动作。这本质上是在进行行为克隆,但同样不需要真实的机器人动作标签。VLM从视频观察和任务描述中学习如何预测这些无监督发现的潜在动作。
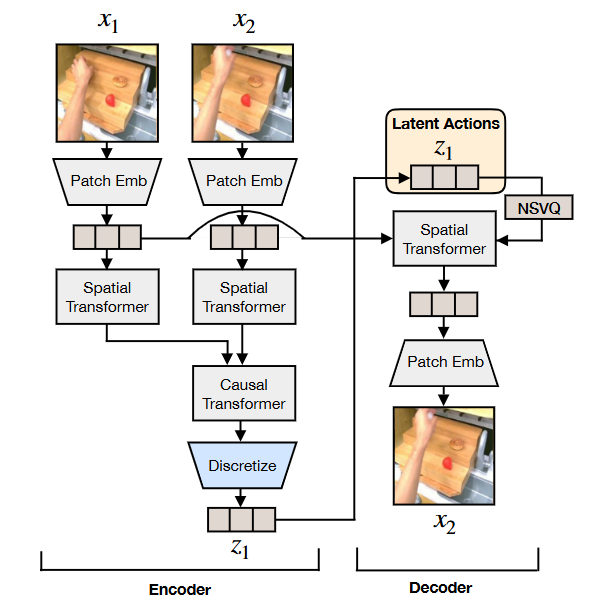
具体训练过程见上图:
这个潜在动作量化模型是基于C-ViViT模型架构,并借鉴了GENIE模型的潜在动作思想。其核心目的是以无监督的方式从视频帧中学习离散的潜在动作。整个过程可以分为编码、量化和解码三个主要部分。
编码过程
在编码阶段,模型会处理连续的两帧图像:当前帧 和未来帧
。
- 补丁嵌入(Patch Embedding):首先,
和
会分别通过补丁嵌入层,得到它们的特征表示
和
。这个过程将原始图像分解成一系列的补丁,并将每个补丁转换为一个向量表示。
- 空间Transformer(Spatial Transformer):接下来,
- 因果Transformer(Causal Transformer):为了捕获时间信息,从空间Transformer输出的两个表示会传递给一个因果Transformer。因果Transformer(带有因果位置编码)负责处理序列数据中的时间依赖性,生成连续的嵌入
和
。
- 计算动作“Delta”:然后,通过计算
=
- CNN网络:在获得
量化过程
量化是将连续的动作表示 转换为离散的潜在动作
的关键步骤。
- VQ-VAE目标:模型采用VQ-VAE(Vector Quantized Variational AutoEncoder)目标。VQ-VAE的核心思想是从一个嵌入空间中检索与连续嵌入
- 查找最近的嵌入:通过以下公式(1),模型从码本
中找到与
。码本的大小是一个超参数。
- NSVQ技术:在量化之后,模型会应用NSVQ(Noise Substitution in Vector Quantization)技术,用于解码之前的处理。NSVQ旨在解决VQ-VAE中常见的梯度崩溃问题,通过将向量量化误差替换为原始误差与标准化噪声向量的乘积来避免表示崩溃,并利用码本替换技术来最大化码本利用率。通过公式(2)进行噪声替换:
其中是一个标准正态分布的噪声向量。
解码过程
解码阶段的目标是利用潜在动作 和当前帧
重建未来帧
。
- 重构未来帧:解码器
接收一个经过修改的潜在动作
(经过NSVQ处理)和当前帧
:
这里,表示对
- 解码器结构:与编码器不同,解码器
- 训练目标:模型的训练目标是最小化原始未来帧
总结
之前我们提到的要构建一种中间表征,这种基于Latent Action的就是一种很好的方法。总结来讲的话就是Encoder部分获取输入当前帧 和未来帧
得到输入两帧之间的动作表征;Decoder通过这个动作表征以及
的输入来预测
。
通过这样一种自监督范式,我们可以发现这种 Latent Action Model 得益于VQ-VAE中间的 codebook 具有很强的信息瓶颈,所以他可以很好地学到两帧之间的 dynamics。这是因为VQ-VAE的机制使得编码器在分析完两帧图像后,不能随心所欲地创造一个动作指令。它必须从这本“动作词典”里挑选一个最合适的“单词”(或几个单词的组合)来描述这个动作,编码器想传递给解码器的所有关于“变化”的信息,都必须被压缩成词典里的这几个单词,这带来了巨大的好处。
对于 Decoder 部分,它的输入之一是当前帧 。这意味着它已经知道了场景里所有物体的样子、颜色、纹理等静态信息。所以我们不需要像训练一个image tokenizer,将 tockenize 的这个 latent action 表征去 encode 很多纹理信息,因为纹理已经在
中给出。因此,当它接收到来自编码器的“动作指令”
时,这个指令完全不需要包含物体的纹理信息。如果指令里包含了“这是一个红色的杯子”,那就是一种浪费,因为解码器看着
就已经知道了。这样,
这个“动作指令”会演变成只包含最核心的变化信息,也就是“从 A 位置移动到 B 位置”这样的动态信息 。
但是,我们学到的这种 naïve latent action 会不可避免地学到一些与任务不相关(task-irrelevant)的动态,比如新物体的出现,人类的介入以及 non-ego agents 的运动。这样我们可以关注到 UniVLA 的内容。
UniVLA: 构建通用可扩展的机器人动作空间
[2505.06111] UniVLA: Learning to Act Anywhere with Task-centric Latent Actions
UniVLA的提出解决了我们上述的 task-irrelevant 的问题,其宗旨是构建一种“任务中心”的离散潜在动作空间
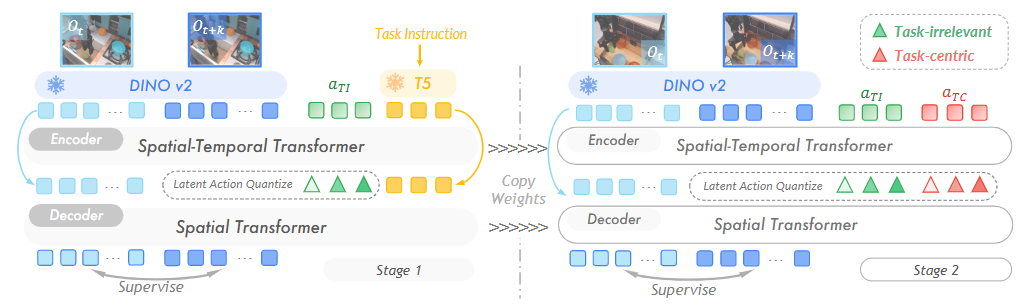
其提出的两阶段训练框架如图所示:
UniVLA 的两阶段训练围绕“潜在动作”建模展开,目标是把与任务无关的视觉变化和与任务相关的自我运动解耦出来。具体做法是:用成对视频帧在 DINOv2 特征空间里做逆/正向动力学建模,配合 VQ-VAE 将动作压缩成离散码本,并用语言指令作为条件来“疏导”语义信息。
训练阶段一:语言条件冻结“任务无关”的潜在码本
我们之前提到,在 naïve latent action 的训练中,给到解码器第一帧的输入,就会迫使码本不去学习到动作无关的 texture 信息。

在UniVLA训练的第一阶段里,模型接收两帧观察图像和一语言指令 ,编码出一组潜在动作
并量化到码本,解码器用
预测未来特征
。关键在于把语言指令
明确送到解码器,让高层语义由解码器直接承担;同时 VQ 瓶颈限制了
的容量,于是它更倾向去编码那些“可预测但与任务无关”的环境变化,例如相机抖动、路人/旁观者移动、光照与贴图变化等。这一步得到的是“与任务无关”的潜在动作码本与参数。
训练阶段二:生成任务中心的潜在动作表示

第二阶段在拷贝第一阶段权重的基础上,引入一套全新的潜在动作 与码本,保持上一阶段学到的 “任务无关” 码本冻结不动,编码器同时产出
和
,解码器用
来重建
,优化的还是
。因为与任务无关的那部分已经被冻结,想要进一步降低预测误差,新的码本只能去吸收“残差”——也就是与指令一致的自我运动、被操纵物体的受控位姿变化、朝向目标的轨迹等。这种“残差化”学习配合指令条件,迫使
聚焦任务关键动态,从而成为任务中心(task‑centric)的潜在动作表示。
之所以能获得稳定的 task‑centric 能力,还依赖三个设计细节的配合:其一,相比直接在像素级别上的学习,在 DINOv2 的空间下做 Supervision(即不仅在 Encoder 部分用DINOv2做编码,同时需要预测的目标也是一个 DINOv2 的 feature 而不是 raw pixel)利用了 DINOv2 的丰富语义和object-centric。在 DINOv2 的对象与空间感知特征上做预测,天然抑制了纹理、光照等低层噪声;其二,固定约一秒的帧间隔 把跨数据集的时间尺度统一为“动作块”,让潜在动作对不同具身与视角更一致;其三,VQ 的离散瓶颈既压缩信息、提高信噪比,也让后续把潜在动作作为“动作词元”接到策略模型里变得直接可用。综合这些机制,第二阶段学到的
就成为跨具身、跨视角且以任务为中心的动作中间层。
“通用策略”预训练
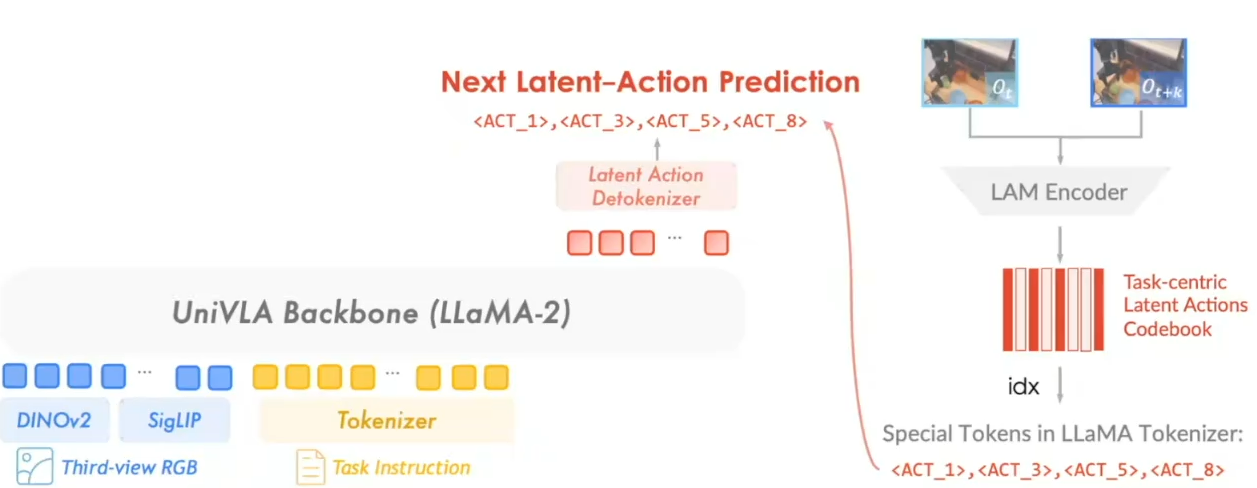
完成潜在动作学习之后,进入“通用策略”预训练。这里把每个时间步的动作看作长度为 的离散令牌序列,把
的每个码本条目声明为一个新的特殊词元 <ACT_i> 并加入到大语言模型词表。
-
遍历视频数据并生成伪标签:
- 对于数据集中的每一个视频序列:
- 将视频帧分割成一系列连续的帧对
。
- 对于每一个帧对,将其输入到已训练的潜空间动作模型的编码器中。
- 编码器会提取出对应的潜在动作表示,并通过量化器将其转换为离散的码字索引。
- 将这些码字索引序列记录下来,作为该视频片段对应的“潜空间动作序列”。
- 将视频帧分割成一系列连续的帧对
- 对于数据集中的每一个视频序列:
-
映射到特殊 Token:
- 这些离散的码字索引(例如 0, 1, ..., C-1)随后会被映射成 LLM 词汇表中的特殊 Token(例如
<ACT_1>,<ACT_2>, ...,<ACT_C>)。
- 这些离散的码字索引(例如 0, 1, ..., C-1)随后会被映射成 LLM 词汇表中的特殊 Token(例如
视觉前端由 SigLIP 与 DINOv2 融合,映射后与文本指令一起喂给基座 VLM Prismatic‑7B。训练任务是“下一潜在动作预测”:给出当前观测 、任务指令
和已有的潜在动作前缀
,自回归地预测下一 token,最小化交叉熵:
因为动空间被压缩成少量 ACT 词元,策略收敛明显加快;文中用 20k 步、批量 1024,在 32 张 A100 上约 30 小时(合 960 A100‑h)即可完成大规模预训练。这一阶段不需要任何真实动作标注,所有监督都来自前述潜在动作打标器对海量跨域视频的自动离散标注。
这套范式的关键点有三个。其一,用 DINO 特征而不是像素来做“世界模型式”的一步预测,直接降低噪声与域间差异。其二,两阶段、两码本、只冻结任务无关码本的设计,让“语义相关的自体/目标运动”与“语义无关的背景/相机扰动”在学习动力学上被显式分流。其三,把离散潜在动作映射为小词表的 ACT 令牌,自然适配自回归 VLM 的训练范式与推理接口,为后续跨载体的快速适配与动作块(约一秒)解码奠定统一时间尺度。通过这样的预训练,策略学到的是“在统一潜在动作空间里计划下一步”的能力,后续只需在下游机器人上训练一个轻量解码头,把潜在动作块还原为具体控制信号即可。
后训练:跨机器人形态的知识迁移
预训练好的通用策略模型(Generalist Policy)本身并不直接输出机器人能执行的命令(比如具体的关节角度或电机速度)。它输出的是一系列抽象的、表示“意图”的潜空间动作令牌(Latent Action Tokens),例如 <ACT_5>, <ACT_12>, <ACT_92>, ...。
后训练的核心任务就是将这些抽象的“意图”翻译成特定机器人能够理解和执行的物理动作。这个翻译官就是动作解码器(Action Decoder)。
这个过程具体如下:
1、输入:
通用策略的输出:由主模型预测出的潜空间动作令牌序列。
当前视觉观察:来自特定机器人摄像头(比如第三人称视角RGB图像)的视觉嵌入(Visual Embeddings)。
2、解码机制:
论文中提到,动作解码器是一个轻量级的模块。它使用多头注意力机制(Multi-head Attention)来融合视觉信息和潜空间动作信息。
可以理解为:模型首先将当前的视觉画面(比如桌子上有一个苹果)浓缩成一个特征(Visual Embed)。然后,这个视觉特征会作为一个查询(Query),去“询问”潜空间动作(Action Embed):“根据我当前看到的画面,你这个‘抓取’的意图具体应该怎么实现?”
通过这种方式,解码器能够动态地、根据当前环境的上下文,来精细化解释抽象动作的含义。
3、输出:
解码器最终输出特定机器人动作空间中的一个具体指令。例如,对于一个七自由度的机械臂,输出可能是一个包含7个维度关节角度变化的向量。论文中提到,由于一个潜空间动作代表了大约1秒内的动态,所以解码器可以一次性输出一个动作块(action chunks),从而实现更平滑、更高频率的控制。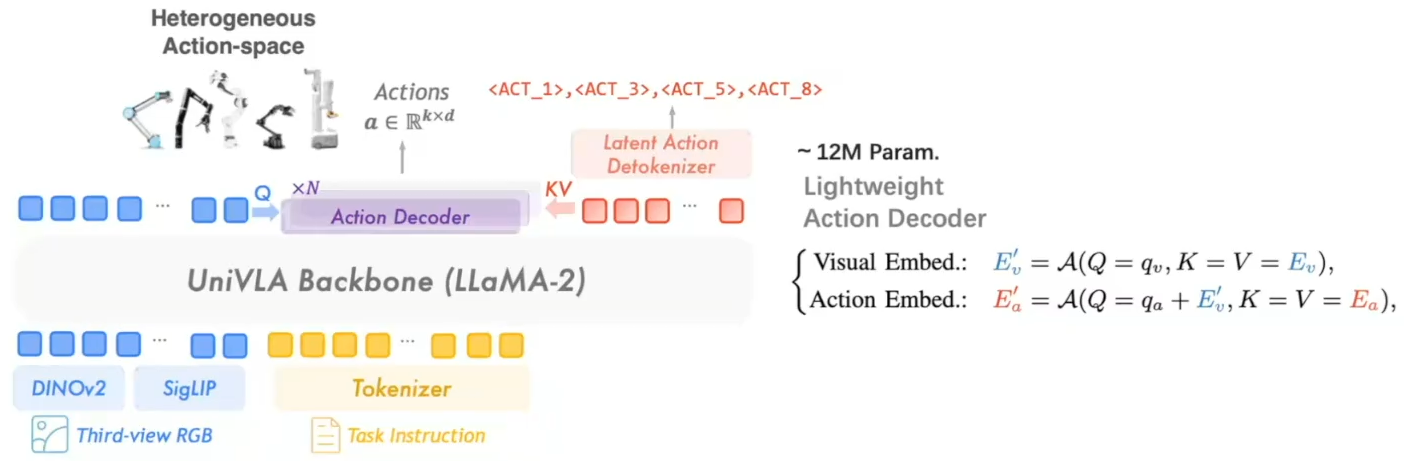
训练步骤
训练过程是端到端 (end-to-end) 的,这意味着虽然我们主要关注解码器,但整个模型会作为一个整体参与运算,并根据一个组合的损失函数进行优化。以下是单次训练迭代的详细步骤:
第一步:数据前向传播 (Forward Pass)
- 模型接收一条训练数据(当前视觉观察
和任务指令
)。
- 通用策略模型进行推理,预测出它认为下一步应该执行的潜空间动作令牌 (latent action token)
。
- 同时,动作解码器接收两个输入:
- 通用策略模型内部产生的视觉特征嵌入。
- 通用策略模型预测出的潜空间动作嵌入。
- Visual Embed. (视觉嵌入):
- Action Embed. (动作嵌入):
- 动作解码器将这两个信息融合,并输出一个具体的物理动作 (physical action)
。
第二步:计算损失函数 (Calculate Loss)
这是最关键的一步。模型需要知道自己做得好不好,这通过计算两个部分的“误差”来实现:
-
策略规划损失 (Policy Loss - Next-Latent-Action Prediction Loss):
- 比较通用策略模型预测的潜空间动作
之间的差异。
- 在训练时,我们会用预训练好的潜空间动作编码器 (Latent Action Encoder) 将数据集中的真实状态转换(
- 这个损失函数的目标是确保通用模型的规划能力依然准确。
- 比较通用策略模型预测的潜空间动作
-
动作执行损失 (Decoder Loss - Physical Action L1 Loss):
- 比较动作解码器输出的物理动作
之间的差异。
- 论文中使用 L1损失,它衡量了预测动作和真实动作之间的绝对差值。
- 这个损失函数的目标是教会解码器如何正确地“翻译”模型的意图。
- 比较动作解码器输出的物理动作
第三步:反向传播与参数更新 (Backward Pass & Update)
- 将上述两个损失相加,得到总损失。
- 通过反向传播算法计算梯度。
- 关键点:在更新参数时,我们只更新那些被设置为“可训练”的参数。这主要包括:
- 动作解码器的所有参数。
- 通用策略模型中通过 LoRA (Low-Rank Adaptation) 注入的少量可训练参数。
- 模型的绝大部分(超过98%)的参数保持不变。
结语
ViLLA模型作为具身VLA领域的一大方向,是非常值得关注的。潜空间动作模型具有较好的可解释性,其中的解码器本质上可以看作一个简单的世界模型,预测给定动作下的未来观测。这为未来结合更复杂的规划和世界模型(如规划树、模型预测控制等)提供了基础。但依然存在动作细粒度、码本大小、复杂动作等挑战。尽管存在这些挑战,ViLLA 仍然是 VLA 领域一个重要的里程碑,它提供了一个可扩展、高效且通用的框架,为构建能够在任何地方学习和行动的机器人铺平了道路。
参考

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 13
13 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)