AVX和AMX的计算逻辑
AVX向量级并行计算的逻辑:512位寄存器可以存32个BF16数据,两个BF16数相乘最大范围需要32位表示,为保持精度,每个结果需要用32位存储,512位寄存器只能保存16个BF32数据,每个数据的诞生是并行计算得到的,并行度为16,每个数据=相邻的两对BF16相乘的和。
AVX


AVX向量级并行计算的逻辑:512位寄存器可以存32个BF16数据,两个BF16数相乘最大范围需要32位表示,为保持精度,每个结果需要用32位存储,512位寄存器只能保存16个BF32数据,每个数据的诞生是并行计算得到的,并行度为16,每个数据=相邻的两对BF16相乘的和
AMX
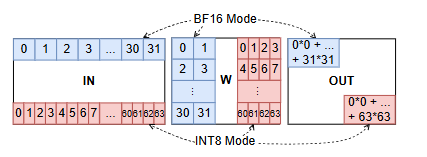

AMX矩阵级并行计算的逻辑:每一个tile是16行*512位的二维寄存器。
对于BF16格式,存储16*32个数据,由于权重也要存在tile中,从矩阵计算的角度而言,权重矩阵应该是32*16的,但是tile只有16行,所以权重矩阵变成(16*2)*16,代表着两列16替代了逻辑上的32列。结果为16*16个数,所以每个数最多只有32位的存储空间,而从矩阵计算的角度而言,需要32对BF16数据对应相乘并累加,数值范围需要16+16+5=37位才能无损表示,所以只能用BF32格式存储(即使有精度损失)。并行的是:结果矩阵的每个元素是并行产生的,并行度为16*16
对于INT8格式,存储16*64个数据,权重矩阵变成(16*4)*16,,结果为16*16,那么每个结果最多有32位可以存储,从矩阵计算角度而言,结果需要8+8+6=22位可以无损表示,所以INT32可以满足无损表示。并行的是:结果矩阵的每个元素是并行产生的,并行度为16*16

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)