【完整源码+数据集+部署教程】柠檬水果质量与缺陷检测系统源码和数据集:改进yolo11-aux
【完整源码+数据集+部署教程】柠檬水果质量与缺陷检测系统源码和数据集:改进yolo11-aux
背景意义
研究背景与意义
随着全球农业科技的迅速发展,水果质量与缺陷检测已成为提高农业生产效率和产品质量的重要研究领域。柠檬作为一种广泛种植和消费的水果,其质量直接影响到市场销售和消费者满意度。然而,传统的人工检测方法不仅耗时耗力,而且容易受到主观因素的影响,导致检测结果的不一致性。因此,开发一种高效、准确的自动化检测系统显得尤为重要。
基于改进YOLOv11的柠檬水果质量与缺陷检测系统,旨在利用深度学习技术,结合先进的计算机视觉算法,实现对柠檬水果的快速检测与分类。该系统将应用于对柠檬的多种缺陷进行识别,包括瑕疵、病害、霉变等,确保在采摘和运输过程中及时发现问题,降低损失。此外,通过对柠檬质量的实时监测,能够为果农提供科学的管理依据,提升果品的市场竞争力。
本研究所使用的数据集包含2700张标注图像,涵盖了8种不同的缺陷类别,如“artifact”、“blemish”、“gangrene”等。这些数据的多样性和丰富性为模型的训练提供了坚实的基础。通过对数据集的深入分析与处理,采用实例分割的方式,可以更精确地识别和定位柠檬上的缺陷,从而提高检测的准确性和可靠性。
综上所述,基于改进YOLOv11的柠檬水果质量与缺陷检测系统,不仅具有重要的理论研究价值,还有助于推动农业智能化的发展,提升水果产业的整体水平。这一研究将为实现农业生产的数字化、智能化提供新的思路和方法,为可持续农业发展贡献力量。
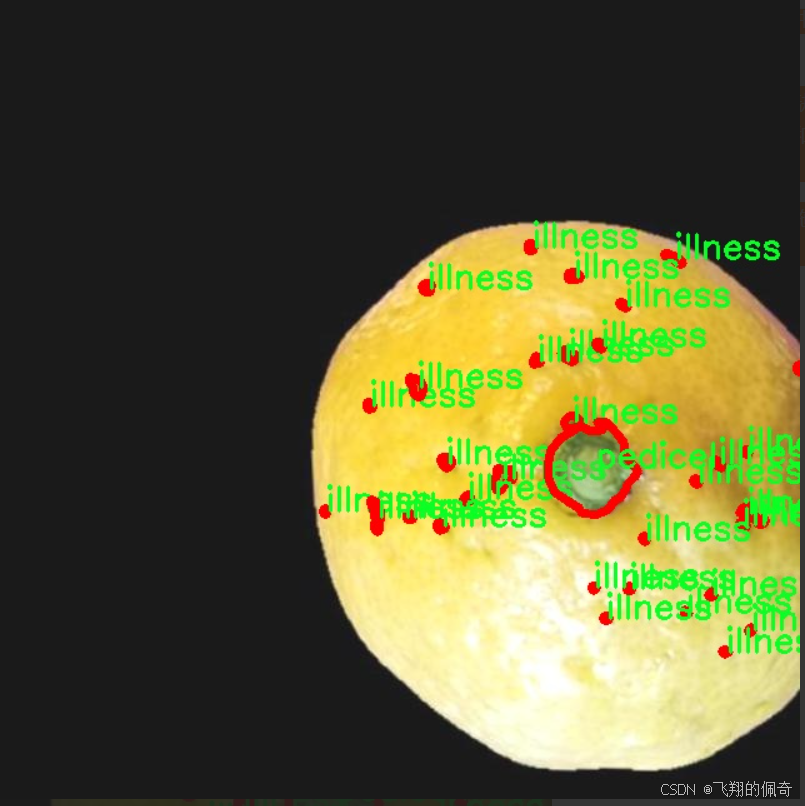
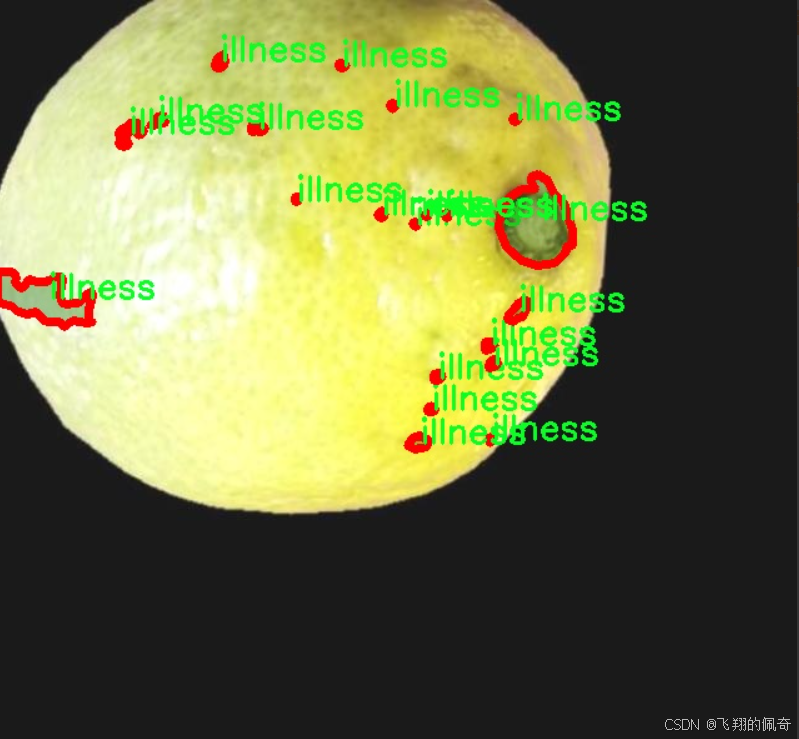
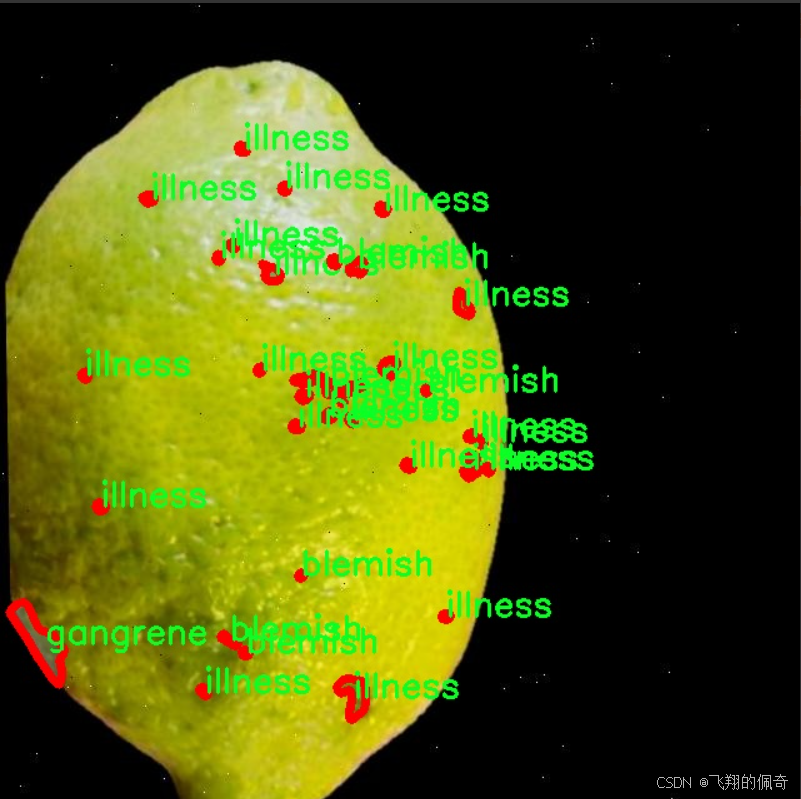
图片效果
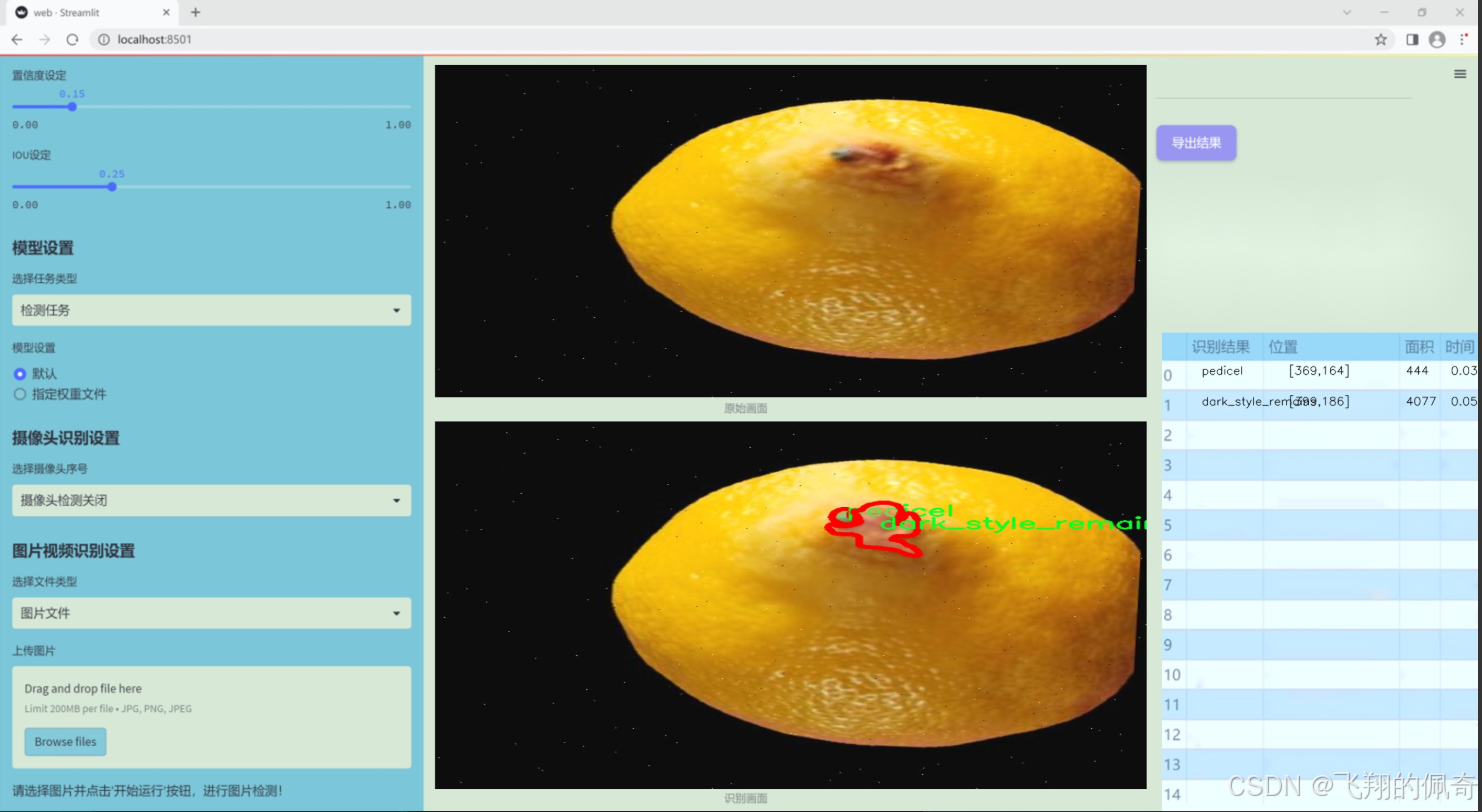
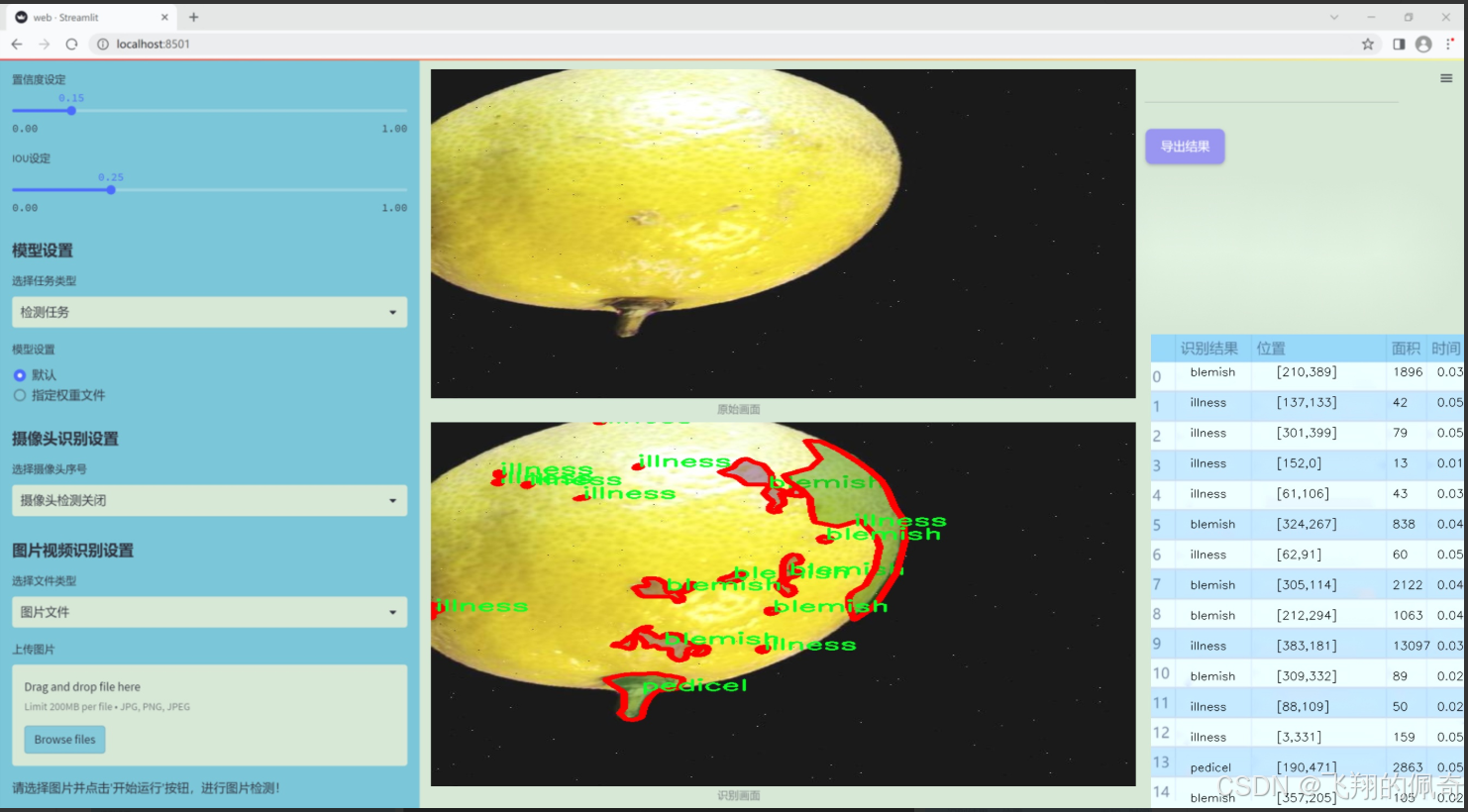
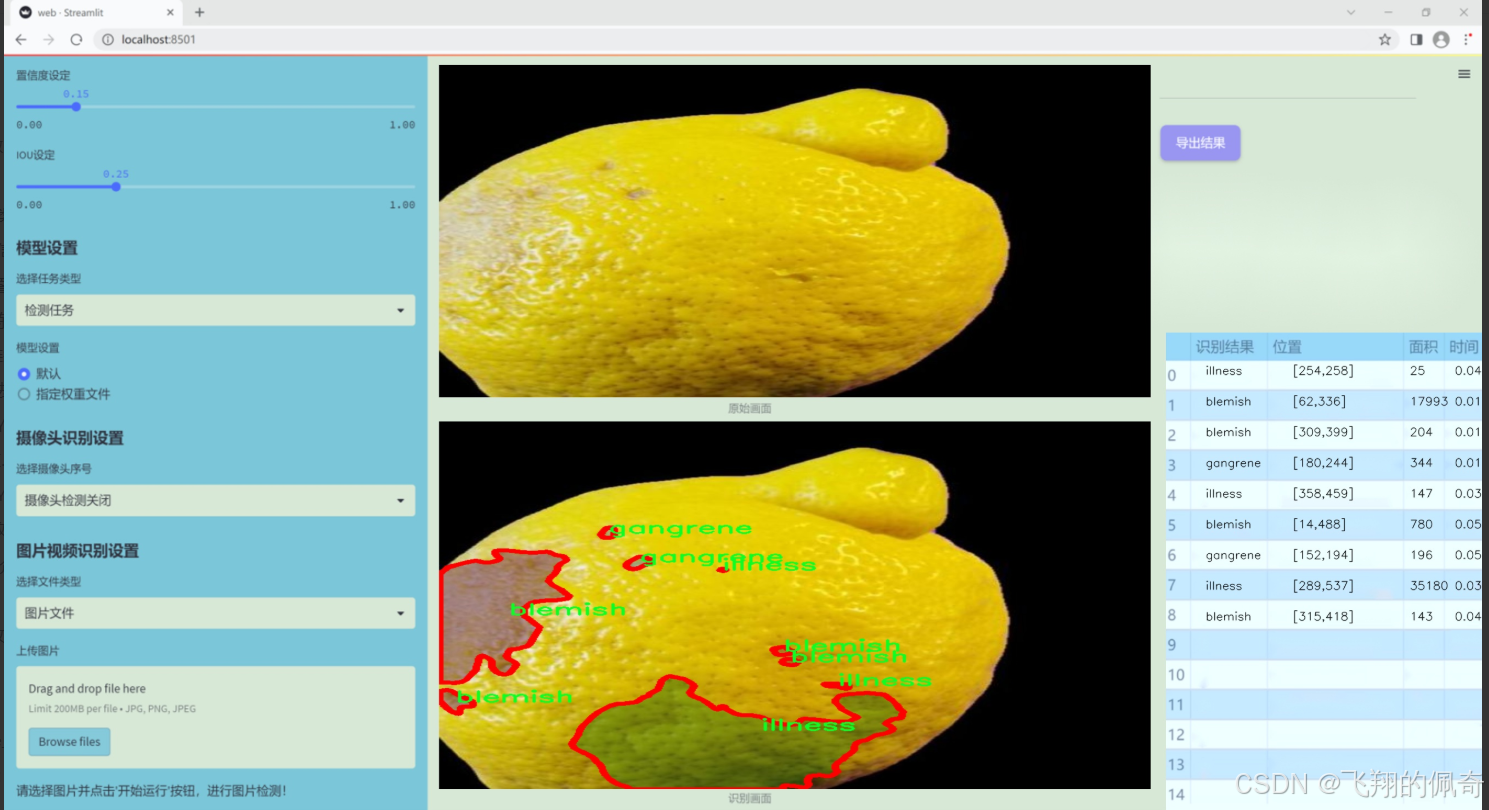
数据集信息
本项目数据集信息介绍
本项目旨在开发一个改进的YOLOv11模型,以实现柠檬水果的质量与缺陷检测。为此,我们构建了一个专门的数据集,主题为“FRUIT QUALITY AND DEFECT CL”,该数据集包含了多种与柠檬水果质量相关的缺陷类型。数据集中共涵盖8个类别,具体包括:artifact(伪影)、blemish(瑕疵)、dark_style_remains(暗色风格残留)、gangrene(坏疽)、illness(疾病)、image_quality(图像质量)、mould(霉变)以及pedicel(果梗)。这些类别不仅反映了柠檬在生长和存储过程中可能遭遇的各种质量问题,还为模型的训练提供了丰富的样本和多样化的特征。
在数据集的构建过程中,我们注重数据的多样性和代表性,确保每个类别都包含足够的样本,以便模型能够学习到不同缺陷的特征。例如,瑕疵和霉变可能在视觉上有明显的差异,而坏疽和疾病则可能需要更细致的特征提取。通过精心挑选和标注样本,我们希望模型能够在实际应用中准确识别出柠檬的质量问题,从而为农产品的质量控制提供有效的技术支持。
此外,为了提升模型的鲁棒性,我们还对数据集进行了多种数据增强处理,包括旋转、缩放、翻转等操作。这些增强措施旨在模拟不同的拍摄条件和环境变化,使得训练后的模型能够在多种实际场景中保持良好的性能。通过这一系列的努力,我们期望构建一个高效、准确的柠檬水果质量与缺陷检测系统,为农业生产和食品安全提供重要的技术保障。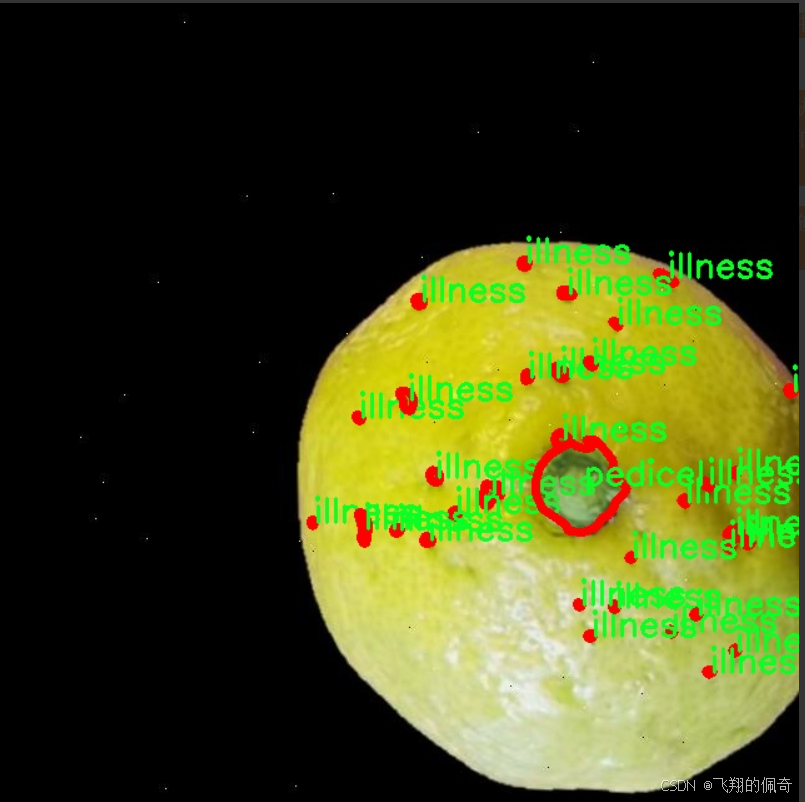

核心代码
以下是经过简化和注释的核心代码部分:
导入必要的模块
from ultralytics.engine.predictor import BasePredictor
from ultralytics.engine.results import Results
from ultralytics.utils import ops
class DetectionPredictor(BasePredictor):
“”"
DetectionPredictor类,继承自BasePredictor,用于基于检测模型进行预测。
“”"
def postprocess(self, preds, img, orig_imgs):
"""
对预测结果进行后处理,并返回Results对象的列表。
参数:
preds: 模型的预测结果
img: 输入图像
orig_imgs: 原始图像列表
返回:
results: 包含处理后结果的Results对象列表
"""
# 应用非极大值抑制(NMS)来过滤预测框
preds = ops.non_max_suppression(
preds,
self.args.conf, # 置信度阈值
self.args.iou, # IOU阈值
agnostic=self.args.agnostic_nms, # 是否使用类别无关的NMS
max_det=self.args.max_det, # 最大检测框数量
classes=self.args.classes, # 过滤的类别
)
# 如果输入的原始图像不是列表,则将其转换为numpy数组
if not isinstance(orig_imgs, list):
orig_imgs = ops.convert_torch2numpy_batch(orig_imgs)
results = [] # 初始化结果列表
for i, pred in enumerate(preds):
orig_img = orig_imgs[i] # 获取对应的原始图像
# 将预测框的坐标缩放到原始图像的尺寸
pred[:, :4] = ops.scale_boxes(img.shape[2:], pred[:, :4], orig_img.shape)
img_path = self.batch[0][i] # 获取图像路径
# 创建Results对象并添加到结果列表
results.append(Results(orig_img, path=img_path, names=self.model.names, boxes=pred))
return results # 返回处理后的结果列表
代码注释说明:
导入模块:导入必要的类和函数以支持预测和结果处理。
DetectionPredictor类:该类专门用于处理检测模型的预测。
postprocess方法:此方法负责对模型的预测结果进行后处理,主要包括:
使用非极大值抑制(NMS)来去除冗余的预测框。
将原始图像转换为numpy数组(如果需要)。
缩放预测框的坐标,以适应原始图像的尺寸。
创建并返回包含所有处理结果的列表。
这个程序文件 predict.py 是一个用于目标检测的预测类,继承自 BasePredictor 类,属于 Ultralytics YOLO 项目的一部分。该文件主要实现了一个名为 DetectionPredictor 的类,旨在处理基于检测模型的预测任务。
在这个类中,首先定义了一个 postprocess 方法,该方法用于对模型的预测结果进行后处理。具体来说,postprocess 方法接收三个参数:preds(模型的预测结果)、img(输入图像)和 orig_imgs(原始图像)。该方法的主要功能是应用非极大值抑制(Non-Maximum Suppression, NMS)来过滤掉重叠的检测框,从而保留最有可能的检测结果。
在方法内部,首先调用 ops.non_max_suppression 函数,对预测结果进行 NMS 处理,使用了一些参数,如置信度阈值、IoU 阈值、是否进行类别无关的 NMS、最大检测框数量以及指定的类别等。接着,检查 orig_imgs 是否为列表,如果不是,则将其转换为 NumPy 数组格式,以便后续处理。
接下来,程序遍历每个预测结果,并对每个预测框进行坐标缩放,以适应原始图像的尺寸。缩放操作是通过 ops.scale_boxes 函数实现的。每个处理后的结果会被封装成一个 Results 对象,其中包含原始图像、图像路径、模型名称和检测框信息,并将其添加到结果列表中。
最后,postprocess 方法返回一个包含所有处理结果的列表,便于后续的分析和展示。整体上,这个类和方法为目标检测提供了一个高效的预测和后处理框架,便于用户在实际应用中进行目标检测任务。
10.4 revcol.py
以下是经过简化和注释的核心代码部分:
import torch
import torch.nn as nn
定义一个用于反向传播的自定义函数
class ReverseFunction(torch.autograd.Function):
@staticmethod
def forward(ctx, run_functions, alpha, *args):
# 保存运行的函数和alpha参数
ctx.run_functions = run_functions
ctx.alpha = alpha
# 获取输入参数
x, c0, c1, c2, c3 = args
# 计算每一层的输出
c0 = run_functions[0](x, c1) + c0 * alpha[0]
c1 = run_functions[1](c0, c2) + c1 * alpha[1]
c2 = run_functions[2](c1, c3) + c2 * alpha[2]
c3 = run_functions[3](c2, None) + c3 * alpha[3]
# 保存中间结果以便反向传播使用
ctx.save_for_backward(x, c0, c1, c2, c3)
return x, c0, c1, c2, c3
@staticmethod
def backward(ctx, *grad_outputs):
# 从上下文中恢复保存的张量
x, c0, c1, c2, c3 = ctx.saved_tensors
run_functions = ctx.run_functions
alpha = ctx.alpha
# 获取梯度
gx_right, g0_right, g1_right, g2_right, g3_right = grad_outputs
# 反向传播计算
g3_up = g3_right
g3_left = g3_up * alpha[3] # shortcut
oup3 = run_functions[3](c2, None)
torch.autograd.backward(oup3, g3_up, retain_graph=True)
# 继续反向传播
g2_up = g2_right + c2.grad
g2_left = g2_up * alpha[2] # shortcut
oup2 = run_functions[2](c1, c3)
torch.autograd.backward(oup2, g2_up, retain_graph=True)
g1_up = g1_right + c1.grad
g1_left = g1_up * alpha[1] # shortcut
oup1 = run_functions[1](c0, c2)
torch.autograd.backward(oup1, g1_up, retain_graph=True)
g0_up = g0_right + c0.grad
g0_left = g0_up * alpha[0] # shortcut
oup0 = run_functions[0](x, c1)
torch.autograd.backward(oup0, g0_up)
# 返回梯度
return None, None, gx_up, g0_left, g1_left, g2_left, g3_left
定义一个子网络模块
class SubNet(nn.Module):
def init(self, channels, layers, kernel, first_col, save_memory) -> None:
super().init()
self.save_memory = save_memory
# 初始化每一层的alpha参数
self.alpha0 = nn.Parameter(torch.ones((1, channels[0], 1, 1)), requires_grad=True)
self.alpha1 = nn.Parameter(torch.ones((1, channels[1], 1, 1)), requires_grad=True)
self.alpha2 = nn.Parameter(torch.ones((1, channels[2], 1, 1)), requires_grad=True)
self.alpha3 = nn.Parameter(torch.ones((1, channels[3], 1, 1)), requires_grad=True)
# 创建四个层级
self.level0 = Level(0, channels, layers, kernel, first_col)
self.level1 = Level(1, channels, layers, kernel, first_col)
self.level2 = Level(2, channels, layers, kernel, first_col)
self.level3 = Level(3, channels, layers, kernel, first_col)
def forward(self, *args):
# 根据内存节省策略选择正向传播方式
if self.save_memory:
return self._forward_reverse(*args)
else:
return self._forward_nonreverse(*args)
def _forward_nonreverse(self, *args):
# 正向传播计算
x, c0, c1, c2, c3 = args
c0 = self.alpha0 * c0 + self.level0(x, c1)
c1 = self.alpha1 * c1 + self.level1(c0, c2)
c2 = self.alpha2 * c2 + self.level2(c1, c3)
c3 = self.alpha3 * c3 + self.level3(c2, None)
return c0, c1, c2, c3
def _forward_reverse(self, *args):
# 使用反向传播计算
local_funs = [self.level0, self.level1, self.level2, self.level3]
alpha = [self.alpha0, self.alpha1, self.alpha2, self.alpha3]
_, c0, c1, c2, c3 = ReverseFunction.apply(local_funs, alpha, *args)
return c0, c1, c2, c3
定义整个网络结构
class RevCol(nn.Module):
def init(self, kernel=‘C2f’, channels=[32, 64, 96, 128], layers=[2, 3, 6, 3], num_subnet=5, save_memory=True) -> None:
super().init()
self.num_subnet = num_subnet
self.channels = channels
self.layers = layers
# 初始化网络的输入层
self.stem = Conv(3, channels[0], k=4, s=4, p=0)
# 添加多个子网络
for i in range(num_subnet):
first_col = (i == 0)
self.add_module(f'subnet{str(i)}', SubNet(channels, layers, kernel, first_col, save_memory=save_memory))
def forward(self, x):
# 网络的前向传播
c0, c1, c2, c3 = 0, 0, 0, 0
x = self.stem(x)
for i in range(self.num_subnet):
c0, c1, c2, c3 = getattr(self, f'subnet{str(i)}')(x, c0, c1, c2, c3)
return [c0, c1, c2, c3]
代码说明:
ReverseFunction: 这是一个自定义的反向传播函数,负责在前向传播时保存中间结果,并在反向传播时计算梯度。
SubNet: 这是一个子网络模块,包含多个层级和可学习的参数(alpha),用于调整各层的输出。
RevCol: 这是整个网络的结构,包含多个子网络和一个输入层。前向传播时,它依次调用每个子网络进行计算。
通过这些核心部分的组合,构建了一个复杂的神经网络结构,能够进行有效的前向和反向传播。
这个程序文件 revcol.py 实现了一个深度学习模型的反向传播机制,主要用于图像处理或计算机视觉任务。代码中使用了 PyTorch 框架,定义了一些自定义的神经网络模块和反向传播函数。
首先,文件导入了必要的 PyTorch 模块,包括 torch 和 torch.nn,以及一些自定义的卷积和块模块。接着,定义了一些辅助函数,比如 get_gpu_states、get_gpu_device、set_device_states 和 detach_and_grad,这些函数主要用于管理 GPU 的随机数生成状态、获取设备信息和处理张量的梯度。
ReverseFunction 类是一个自定义的反向传播函数,继承自 torch.autograd.Function。它的 forward 方法实现了前向传播的逻辑,接受多个函数和参数,并通过这些函数计算输出。该方法中使用了 torch.no_grad() 来避免计算梯度,同时保存了 CPU 和 GPU 的随机数状态,以便在反向传播时恢复。反向传播的逻辑在 backward 方法中实现,利用保存的状态和输入,逐层计算梯度并进行反向传播。
接下来,定义了几个神经网络模块类,包括 Fusion、Level 和 SubNet。Fusion 类负责在不同层之间进行特征融合,Level 类则表示网络的每一层,包含了融合操作和卷积块。SubNet 类表示一个子网络,由多个层组成,并实现了前向传播的两种方式:非反向传播和反向传播。
最后,RevCol 类是整个模型的核心,包含了多个子网络的实例,并定义了模型的前向传播过程。它的构造函数初始化了网络的结构,包括卷积层和子网络。前向传播方法将输入数据通过多个子网络进行处理,最终输出特征图。
整体来看,这个文件实现了一个具有反向传播机制的深度学习模型,利用了 PyTorch 的自动微分功能,支持在 GPU 上高效计算。通过自定义的反向传播函数和网络结构,模型能够在保持性能的同时,优化内存使用。
源码文件

源码获取
欢迎大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 12
12 0
0- 0



 已为社区贡献30条内容
已为社区贡献30条内容

所有评论(0)