【CVPR2025】即插即用SCSA 用连续 + 稀疏双机制,让计算范式被改写!直接涨点起飞!
本文提出了一种即插即用的语义连续-稀疏注意力机制(SCSA),用于解决现有基于注意力的任意风格迁移方法(Attn-AST)在处理同语义内容与风格图像时出现的语义区域风格不一致、相邻区域不连续及纹理缺失问题。SCSA通过双注意力模块协同工作:语义连续注意力(SCA)确保同语义区域的整体风格一致性,语义稀疏注意力(SSA)捕捉具体纹理细节。该方法无需重新训练即可集成到CNN、Transformer和扩
1. 【前言】
基于注意力机制的任意风格迁移方法(Attn-AST) 虽能生成高质量风格化图像,但在处理同语义内容与风格图像时,因未考虑局部区域与语义区域的关系,导致生成图对应语义区域风格不一致、相邻区域风格不连续且纹理缺失;为此,论文《SCSA: A Plug-and-Play Semantic Continuous-Sparse Attention for Arbitrary Semantic Style Transfer》提出即插即用的语义连续-稀疏注意力机制(SCSA),通过让查询点关注对应语义区域关键点,结合语义连续与稀疏注意力,首次以无训练方式将Attn-AST扩展至语义风格迁移,实验证明其能显著提升语义准确性、风格连续性和纹理丰富度,为数字艺术等领域提供了更优解决方案。![Comparisons of the Attn-AST approaches–CNN-based SANet, Transformer-based StyTR2,and Diffusion-based StyleID [9]–without and with our SCSA.](https://i-blog.csdnimg.cn/direct/6eb054c2133b4cc9b7cc240bbf7aa090.png)
2.【论文基本信息】

- 论文标题:SCSA: A Plug-and-Play Semantic Continuous-Sparse Attention for Arbitrary Semantic Style Transfer
- 论文链接:https://arxiv.org/abs/2503.04119
3.【创新点概述】

3.1 问题定位与机制创新
首次揭示了基于注意力的任意风格迁移方法(Attn-AST)在处理同语义内容与风格图像时表现不佳的根本原因,即未考虑局部区域与语义区域的关系。据此提出语义连续-稀疏注意力机制(SCSA),通过让查询点关注对应语义区域的关键点,同时解决风格不一致、区域不连续及纹理缺失问题。
3.2 模块设计与方法突破
- 双注意力模块协同:结合语义连续注意力(SCA)和语义稀疏注意力(SSA)。SCA通过语义地图特征确保同语义区域的整体风格一致性,SSA通过图像特征捕捉具体纹理细节,二者互补实现语义区域的精准风格迁移。
- 即插即用特性:无需重新训练即可集成到现有Attn-AST框架(如CNN、Transformer、扩散模型),扩展其为语义风格迁移工具,且实验证明能提升各类模型的语义准确性和纹理生动性。
4.【整体架构流程】
4.1 原始Attn-AST框架流程
- 特征编码:通过编码器EEE对内容图像IcI_cIc和风格图像IsI_sIs分别编码,得到内容特征FcF_cFc和风格特征FsF_sFs:
Fc=E(Ic),Fs=E(Is)F_c = E(I_c), \quad F_s = E(I_s)Fc=E(Ic),Fs=E(Is) - 特征转换:利用通用注意力(UA)模块TUAT_{UA}TUA对特征进行转换,生成风格化特征FcsF_{cs}Fcs:
Fcs=TUA(Fc,Fs)F_{cs} = T_{UA}(F_c, F_s)Fcs=TUA(Fc,Fs) - 图像生成:通过解码器DDD将风格化特征FcsF_{cs}Fcs解码为风格化图像IcsI_{cs}Ics:
Ics=D(Fcs)I_{cs} = D(F_{cs})Ics=D(Fcs)
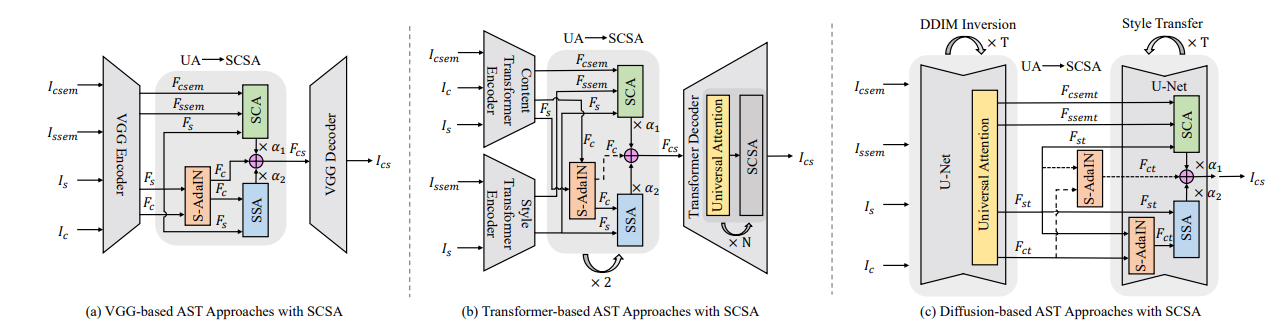
4.2 集成SCSA的Attn-AST流程
- 四元组特征编码:除内容和风格图像外,还对其语义地图IcsemI_{csem}Icsem和IssemI_{ssem}Issem编码,得到语义特征FcsemF_{csem}Fcsem和FssemF_{ssem}Fssem:
{Fc=E(Ic),Fs=E(Is)Fcsem=E(Icsem),Fssem=E(Issem)\begin{cases} F_c = E(I_c), \quad F_s = E(I_s) \\ F_{csem} = E(I_{csem}), \quad F_{ssem} = E(I_{ssem}) \end{cases}{Fc=E(Ic),Fs=E(Is)Fcsem=E(Icsem),Fssem=E(Issem) - 语义自适应实例归一化(S-AdaIN):对内容特征FcF_cFc进行归一化处理,消除原始风格干扰:
Fc=S-AdaIN(Fc,Fs)F_c = \text{S-AdaIN}(F_c, F_s)Fc=S-AdaIN(Fc,Fs) - 语义连续注意力(SCA):
- 以语义特征为输入,计算查询Q1Q_1Q1、键K1K_1K1和值V1V_1V1:
Q1=fq(F‾csem),K1=fk(F‾ssem),V1=fv(Fs)Q_1 = f_q(\overline{F}_{csem}), \quad K_1 = f_k(\overline{F}_{ssem}), \quad V_1 = f_v(F_s)Q1=fq(Fcsem),K1=fk(Fssem),V1=fv(Fs) - 生成初步注意力图A\mathcal{A}A并通过操作G1G_1G1过滤不同语义区域的关联:
A=Q1⊤⊗K1,A‾=G1(A)\mathcal{A} = Q_1^\top \otimes K_1, \quad \overline{\mathcal{A}} = G_1(\mathcal{A})A=Q1⊤⊗K1,A=G1(A) - 得到包含整体风格特征的FscaF_{sca}Fsca:
Fsca=fo(softmax(A‾)⊗V1)F_{sca} = f_o(\text{softmax}(\overline{\mathcal{A}}) \otimes V_1)Fsca=fo(softmax(A)⊗V1)
- 以语义特征为输入,计算查询Q1Q_1Q1、键K1K_1K1和值V1V_1V1:
- 语义稀疏注意力(SSA):
- 以归一化的内容特征和风格特征为输入,计算查询Q2Q_2Q2、键K2K_2K2和值V2V_2V2:
Q2=fq(F‾c),K2=fk(F‾s),V2=fv(Fs)Q_2 = f_q(\overline{F}_c), \quad K_2 = f_k(\overline{F}_s), \quad V_2 = f_v(F_s)Q2=fq(Fc),K2=fk(Fs),V2=fv(Fs) - 生成初始注意力图B\mathcal{B}B并通过操作G2G_2G2保留同语义区域中最相似的关键点注意力:
B=Q2⊤⊗K2,B‾=G2(B)\mathcal{B} = Q_2^\top \otimes K_2, \quad \overline{\mathcal{B}} = G_2(\mathcal{B})B=Q2⊤⊗K2,B=G2(B) - 得到包含具体纹理特征的FssaF_{ssa}Fssa:
Fssa=fo(softmax(B‾)⊗V2)F_{ssa} = f_o(\text{softmax}(\overline{\mathcal{B}}) \otimes V_2)Fssa=fo(softmax(B)⊗V2)
- 以归一化的内容特征和风格特征为输入,计算查询Q2Q_2Q2、键K2K_2K2和值V2V_2V2:
- 特征融合与图像生成:将FscaF_{sca}Fsca和FssaF_{ssa}Fssa按权重融合,结合原始内容特征生成最终风格化特征:
Fcs=α1×Fsca+α2×Fssa+Fc,Ics=D(Fcs)F_{cs} = \alpha_1 \times F_{sca} + \alpha_2 \times F_{ssa} + F_c, \quad I_{cs} = D(F_{cs})Fcs=α1×Fsca+α2×Fssa+Fc,Ics=D(Fcs)
其中α1\alpha_1α1和α2\alpha_2α2分别控制整体风格和纹理的权重。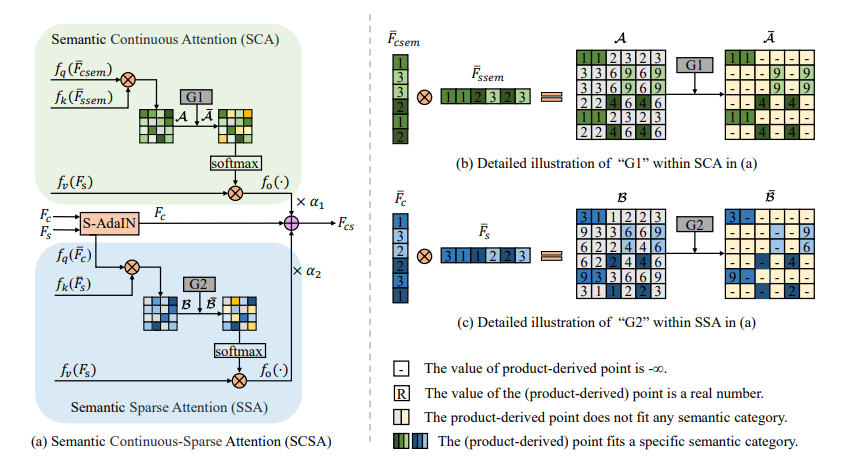
4.3 不同模型集成SCSA的差异
- CNN-based(如SANet):使用VGG-19编码器,SCSA替换UA模块,直接处理特征转换。
- Transformer-based(如StyTR2):采用双编码器(内容和风格Transformer),SCSA在特征融合模块中结合语义信息,并通过参数bbb平衡风格化与内容保留。
- Diffusion-based(如StyleID):在U-Net的DDIM反演过程中引入SCSA,仅在最大时间步TTT应用S-AdaIN,结合时间步参数t1,t2t_1, t_2t1,t2调整语义风格与内容保留。
5.【实验结果】
5.1 定性实验结果
-
语义风格一致性提升:相较于传统Attn-AST方法(如SANet、StyTR2、StyleID),集成SCSA后生成的图像在对应语义区域的风格一致性显著提高。例如,在布料颜色、背景纹理等区域,SCSA能确保生成图像的语义区域风格与风格图像一致,避免了传统方法中相邻区域风格不连续的问题。
-
纹理细节增强:SCSA通过语义稀疏注意力(SSA)捕捉风格图像中的具体纹理特征,使生成图像的纹理更生动。如在砖块、树木等结构中,SCSA生成的图像纹理细节更接近风格图像,而传统方法常因加权平均导致纹理模糊。
-
与SOTA方法对比:与STROTSS、MAST等语义风格迁移方法相比,SCSA在内容保留和语义准确性上更优。例如,在河流、马匹等场景中,SCSA生成的图像既保持了内容结构,又准确传递了语义风格,而部分SOTA方法可能引入风格图像的内容元素或导致语义偏差。

5.2 定量实验结果
- 语义风格损失(SSL):SCSA显著降低了SSL值,表明其在语义区域的风格匹配更精准。例如,SANet+SCSA的SSL值比原始SANet降低约0.08,且在所有Attn-AST方法中表现最优,甚至超过部分SOTA方法。
- Fréchet Inception Distance(FID):SCSA提升了整体风格保真度,其中StyTR2+SCSA的FID值最低(12.3963),较原始StyTR2降低约1.2,说明生成图像与风格图像的视觉风格更接近。
- 内容特征结构距离(CFSD):在CNN和Transformer基模型中,SCSA的CFSD值最低,表明内容保留能力强。例如,StyTR2+SCSA的CFSD为0.0705,优于多数SOTA方法,仅在扩散模型中因语义风格调整导致CFSD略有上升,但仍在可接受范围。
- 用户研究:40名参与者中,超70%的投票认为SCSA生成的图像更符合语义风格需求,显著优于传统Attn-AST方法及SOTA语义迁移方法,验证了其主观效果优势。

5.3 消融实验结果
- SCA与SSA的互补性:单独使用SCA会导致纹理缺失(SSL和FID分别上升0.01-0.1),单独使用SSA则引发颜色偏差,两者结合时性能最佳,证明了模块间的互补作用。
- S-AdaIN的必要性:移除S-AdaIN后,图像全局风格转移不准确,纹理细节减少(如StyleID+SCSA的SSL上升至1.7538),表明S-AdaIN对消除原始风格干扰、提升语义对齐至关重要。
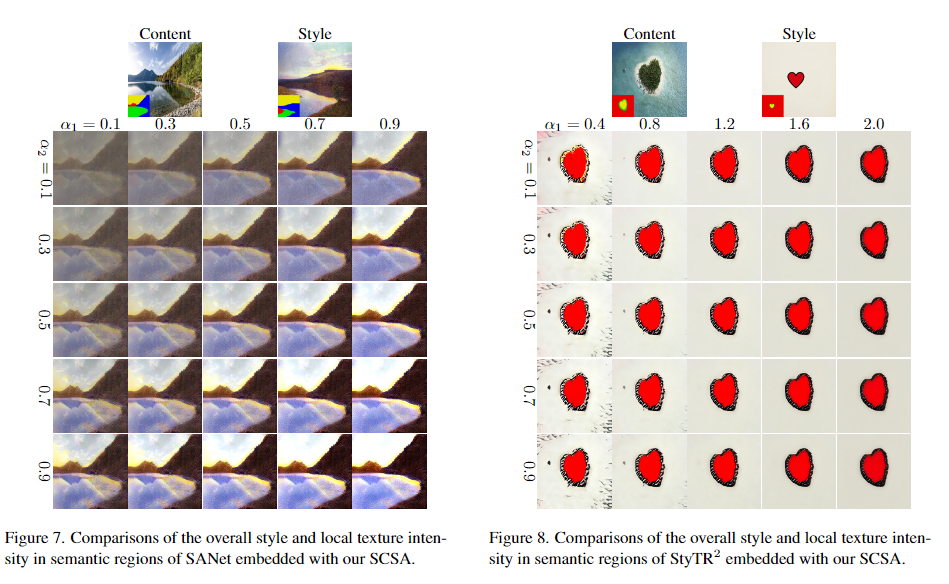
- 参数影响:调整α1\alpha_{1}α1(整体风格权重)和α2\alpha_{2}α2(纹理权重)可动态平衡风格强度,如α1=0.7\alpha_{1}=0.7α1=0.7,α2=0.3\alpha_{2}=0.3α2=0.3时,SANet+SCSA的纹理清晰度与风格一致性达到最佳平衡。

6.【论文总结展望】
总结
论文指出基于注意力的任意风格迁移方法(Attn-AST) 在处理同语义内容与风格图像时,因未考虑局部区域与语义区域的关系,导致生成图像存在语义区域风格不一致、相邻区域不连续及纹理缺失等问题。为此提出即插即用的语义连续-稀疏注意力机制(SCSA),通过语义连续注意力(SCA) 确保同语义区域整体风格一致性,结合语义稀疏注意力(SSA) 捕捉具体纹理细节,无需重新训练即可集成到CNN、Transformer和扩散模型等Attn-AST框架中。实验表明,SCSA能显著提升语义风格迁移的准确性和纹理生动性,在定性、定量及用户研究中均优于传统方法和现有SOTA语义迁移技术。
展望
未来研究可聚焦于优化SCSA的计算效率,减少其对模型处理时间和内存的额外消耗,以推动实际应用。此外,可探索将SCSA扩展至视频语义风格迁移领域,或与多模态模型结合,实现更复杂的语义风格控制。同时,考虑引入动态参数调整机制,进一步提升SCSA在不同场景下的泛化能力,使其在保持内容保留的同时,更精准地适应多样化的语义风格需求。
7.【附录 / 扩展资源】
- 论文链接:https://arxiv.org/abs/2503.04119
- 代码链接:https://github.com/scn-00/SCSA
- 微信交流群:838795243
- 更多模块解析请关注原文及后续更新!
环境要求
- Python 3.8
- Pytorch 2.4.1
快速开始
- 克隆代码仓库:
git clone https://github.com/scn-00/SCSA
cd SCSA
python sem.py
SANet + SCSA 操作指南
- 进入目标文件夹:
cd SANet+SCSA
-
准备SANet预训练模型:
从SANet获取相同的预训练模型,解压后放置于models/路径下。 -
单组图像测试:
- 使用SANet测试:
python SANet.py --content ../sem_data/29/29.jpg --style ../sem_data/29/29_paint.jpg- 使用SANet + SCSA测试(需额外提供语义地图):
python SCSA.py --content ../sem_data/29/29.jpg --style ../sem_data/29/29_paint.jpg --content_sem ../sem_data/29/29_sem.png --style_sem ../sem_data/29/29_paint_sem.png --sem_map_64 ../sem_precomputed_feats/29/29_29_paint_map_64.pt --sem_map_32 ../sem_precomputed_feats/29/29_29_paint_map_32.pt -
批量图像测试:
python run.py
StyTr² + SCSA 操作指南
- 进入目标文件夹:
cd StyTr2+SCSA
-
准备StyTr²预训练模型:
从StyTr²获取相同的预训练模型,解压后放置于experiments/路径下。 -
单组图像测试:
- 使用StyTr²测试:
python StyTr2.py --content ../sem_data/31/31_paint.jpg --style ../sem_data/31/31.jpg- 使用StyTr² + SCSA测试(需额外提供语义地图):
python SCSA.py --content ../sem_data/31/31_paint.jpg --style ../sem_data/31/31.jpg --content_sem ../sem_data/31/31_paint_sem.png --style_sem ../sem_data/31/31_sem.png --sem_map_64 ../sem_precomputed_feats/31/31_paint_31_map_64.pt --sem_map_32 ../sem_precomputed_feats/31/31_paint_31_map_32.pt -
批量图像测试:
python run.py
StyleID + SCSA 操作指南
- 进入目标文件夹:
cd StyleID+SCSA
-
准备StyleID预训练模型:
从StyleID获取相同的预训练模型,解压后放置于models/路径下。 -
单组图像测试:
- 使用StyleID测试:
cd StyleID python StyleID.py --cnt ../sem_data/1/1.jpg --sty ../sem_data/1/1_paint.jpg- 使用StyleID + SCSA测试(需返回上级目录并提供语义地图):
cd StyleID+SCSA python run.py --cnt ../../sem_data/1/1.jpg --sty ../../sem_data/1/1_paint.jpg --cnt_sem ../../sem_data/1/1_sem.png --sty_sem ../../sem_data/1/1_paint_sem.png --sem_map_32 ../../sem_precomputed_feats/1/1_1_paint_map_32.pt --sem_map_64 ../../sem_precomputed_feats/1/1_1_paint_map_64.pt -
批量图像测试:
python run.py

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 29
29 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)