使用Prometheus+grafana打造高逼格监控平台_基于prometheus+grafana开发大数据平台
由于grafana的界面配置都是页面点击,需要截图标注,如果截太多图就文章太冗长了,这里就不进一步说明了,相关配置参考通过上面的安装配置发现,其实整个监控的流程还缺少了报警的环节,如果不能及时通报异常情况再好看也白搭。报警解压规则配置groups:rules:


如果你觉得不错可以继续看下去,上面主要是kvm宿主机, ceph集群, 物理机监控,以及ping, 最后一张的监控图没有展开是为了让你可以瞥一眼所能监控的指标条目。
Prometheus架构图在这里插入图片描述
参考:https://prometheus.io/docs/introduction/overview/
如果你对Prometheus没有接触过,也许会看不懂上面说什么,但是没关系,如果你看完之后,在回过头来瞧瞧,也许就了解这个架构了,也会对Prometheus有一个更深的认识。
这里简单说一下Prometheus的各个部分。
Prometheus Server: Prometheus服务端,由于存储及收集数据,提供相关api对外查询用。
Exporter: 类似传统意义上的被监控端的agent,有区别的是,它不会主动推送监控数据到server端,而是等待server端定时来手机数据,即所谓的主动监控。
Pushagateway: 用于网络不可直达而居于exporter与server端的中转站。
Alertmanager: 报警组件,将报警的功能单独剥离出来放在alertmanager。
Web UI: Prometheus的web接口,可用于简单可视化,及语句执行或者服务状态监控。
安装
由于Prometheus是go语言写的,所以不需要编译,安装的过程非常简单,仅需要解压然后运行。
Prometheus官方下载地址:https://prometheus.io/download/
注:为了演示方便,这里node_exporter, Prometheus server, grafana都安装再同一台机器,系统环境Ubuntu14.04
安装Prometheus server
解压
tar xf prometheus-2.0.0-rc.2.linux-amd64.tar.gz
运行
cd prometheus-2.0.0-rc.2.linux-amd64
./prometheus --config.file=prometheus.yml
然后我们可以访问 http://<服务器IP地址>:9090,验证Prometheus是否已安装成功,web显示应该如下
通过点击下拉栏选取指标,点击”Excute” 我们能够看到Prometheus的性能指标。
点击”status”可以查看相关状态。
但是光安装Prometheus server意义不大,下面我们再安装node_exporter以及grafana
node_exporter安装
解压
tar xf node_exporter-0.15.0.linux-amd64.tar.gz
运行
cd node_exporter-0.15.0.linux-amd64
./node_exporter
验证node_exporter是否安装成功
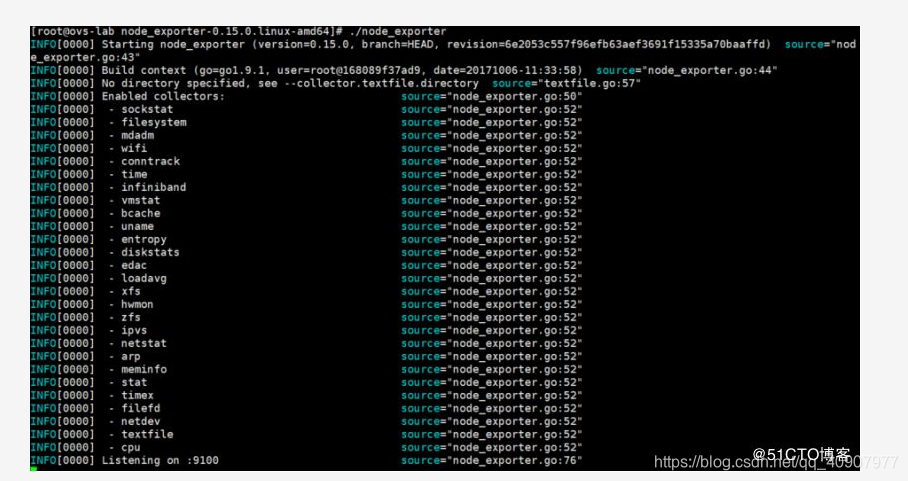
curl 127.0.0.1:9100
curl 127.0.0.1:9100/metrics
返回一大堆性能指标。
grafana安装
下载deb安装
wget https://s3-us-west-2.amazonaws.com/grafana-releases/release/grafana_4.5.2_amd64.deb
dpkg -i grafana_4.5.2_amd64.deb
安装依赖
sudo apt-get install -y adduser libfontconfig
启动grafana
sudo service grafana-server start
加入自启动
sudo update-rc.d grafana-server defaults
注:其他系统安装参考:http://docs.grafana.org/installation/
启动grafana并查看状态
systemctl daemon-reload
systemctl start grafana-serversystemctl status grafana-server
访问grafana, http://<服务器IP>:3000
默认用户名密码:admin/admin
为grafana添加Prometheus数据源
至此所有安装已完成
但是还存在以下问题
一:Prometheus server并没有配置被监控端的IP地址,即没有取指定的机器取数据
二:启动的方式太不人性化了,没有启动脚本。
三:grafana没有可用的dashboard用于展示
这些问题我们放在下面的配置,可视化段落处理。
配置
关闭之前之间运行的node_exporter及prometheus
增加一个被监控端配置项
创建目录/etc/prometheus/
mkdir /etc/prometheus/
创建配置文件
vi /etc/prometheus/prometheus.yml
修改如下(在有配置文件基础上增加红色区域)
my global configglobal:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
scrape_timeout is set to the global default (10s).
Attach these labels to any time series or alerts when communicating with
external systems (federation, remote storage, Alertmanager).
external_labels:
monitor: ‘codelab-monitor’# Load rules once and periodically evaluate them according to the global ‘evaluation_interval’.rule_files: # - “first.rules”
- “second.rules”# A scrape configuration containing exactly one endpoint to scrape:# Here it’s Prometheus itself.scrape_configs: # The job name is added as a label job=<job_name> to any timeseries scraped from this config.
- job_name: ‘prometheus’
metrics_path defaults to ‘/metrics’
scheme defaults to ‘http’.
static_configs:
- targets: [‘localhost:9090’]
注意:缩进是必须的
添加启动脚本
下载地址:https://github.com/youerning/blog/tree/master/prometheus
cp node-exporter.service /etc/init.d/node-exporter
cp prometheus.service /etc/init.d/prometheus
chmod +x /etc/init.d/node-exporter
chmod +x /etc/init.d/prometheus
将上面的可执行二进制文件移到/usr/local/bin
cp prometheus-2.0.0-rc.2.linux-amd64/prometheus /usr/local/bin/prometheus
mv node_exporter-0.15.0.linux-amd64/node_exporter /usr/local/bin/node_exporter
然后启动Prometheus,node-exporter
创建工作目录(Prometheus的数据会存在这,启动脚本里面我写的是/data)
mkdir /data
service prometheus startservice node-exporter start
在Prometheus的web页面能看到被监控端
然后grafana导入dashboard
下载地址:https://grafana.com/dashboards/1860
注:https://grafana.com/dashboards还有很多的dashboard可以下载
按照以下步骤导入
点击import以后grafana就会多一个dashboard
至此一个系统层面性能指标监控已经全部完成。
可视化自定义
由于grafana的界面配置都是页面点击,需要截图标注,如果截太多图就文章太冗长了,这里就不进一步说明了,相关配置参考
http://docs.grafana.org/features/panels/
通过上面的安装配置发现,其实整个监控的流程还缺少了报警的环节,如果不能及时通报异常情况再好看也白搭。
报警
解压
tar xf alertmanager-0.11.0.linux-amd64.tar.gz
规则配置
cat /etc/prometheus/alert.rules
groups:
name: uptime
rules:
Alert for any instance that is unreachable for >1 minutes.
- alert: InstanceDown
expr: up == 0
for: 1m
labels:
severity: page
annotations:
summary: “Instance {{ $labels.instance }} down”
description: “{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 5 minutes.”
prometheus.yml增加以下内容
rule_files:
- “/etc/prometheus/alert.rules”
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数软件测试工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年软件测试全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上软件测试开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加V获取:vip1024b (备注软件测试)
一个人可以走的很快,但一群人才能走的更远。不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎扫码加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
的进阶课程,基本涵盖了95%以上软件测试开发知识点,真正体系化!**
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加V获取:vip1024b (备注软件测试)
[外链图片转存中…(img-HzLFBcu4-1712938498129)]
一个人可以走的很快,但一群人才能走的更远。不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎扫码加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 24
24 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)