获取全国行政区划数据
开始认为在网站上可以直接下载到区划编码的json格式数据。但是找到了能够查询的国家民政局网站,提供了截至到5月份最新的数据。背景:自定义表单要做级联组件。需要配置远程接口获取区划数据。,进入网站后点击菜单栏民政数据就可以看到。
·
-
背景:自定义表单要做级联组件。需要配置远程接口获取区划数据。数据需要准备。
-
开始认为在网站上可以直接下载到区划编码的json格式数据。但是没有找到。很失望。但是找到了能够查询的国家民政局网站,提供了截至到5月份最新的数据。中华人民共和国民政部,进入网站后点击菜单栏民政数据就可以看到。行政区划连接。
-
行政区划查看

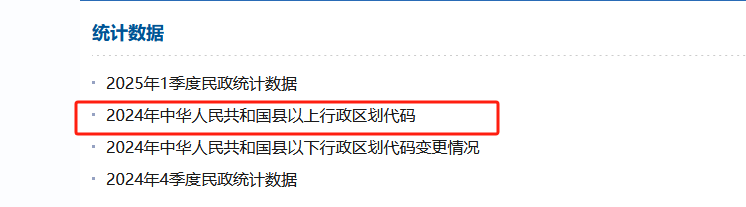
- 但是连接打开后直接给出的市html页面。需要自己分析。
- 无耐请教大模型。开始还算顺利,告知提取省市级别的行政区划数据,但是区县级别的就不干了,硕鼠数据2000+条不能整理,直接给出了python脚本让自己爬取解析。
- 解析用的python代码
import os
import requests
from bs4 import BeautifulSoup
# 方法一:禁用代理
session = requests.Session()
session.trust_env = False # 禁用环境变量中的代理配置
try:
response = session.get('https://www.mca.gov.cn/mzsj/xzqh/2025/202401xzqh.html')
response.encoding = response.apparent_encoding
response.raise_for_status()
# print(response.text)
soup = BeautifulSoup(response.text, 'html.parser')
# print(soup.select('tr'))
# 示例:查找所有可能包含区县信息的表格行
districts = []
for tr in soup.select('tr'):
tds = tr.select('td.xl7121822, td.xl7021822')
# print(f" {len(tds)} ")
if len(tds) >= 2:
code = tds[0].text.strip()
name = tds[1].text.strip()
print(f" {name} {code}")
# 判断是否为区县级别(假设代码长度为6且第3-4位非00)
if len(code) == 6 and code[2:4] != '00' and code[4:6] != '00':
# 提取父级代码(前4位+00)
parent_id = code[:4] + '00'
districts.append((code, name, parent_id))
#print(districts)
# 生成SQL语句
sql_statements = []
for code, name, parent_id in districts:
sql = f"SELECT '{code}', '{name}', '{parent_id}' UNION ALL"
sql_statements.append(sql)
if sql_statements:
sql_statements[-1] = sql_statements[-1].rstrip(' UNION ALL') # 最后一条语句去掉UNION ALL
# 保存到文件
with open('districts.sql', 'w', encoding='utf-8') as f:
f.write('\n'.join(sql_statements))
print(f"成功生成 {len(sql_statements)} 条记录到 districts.sql")
except requests.exceptions.RequestException as e:
print(f"请求出错: {e}")
except Exception as e:
print(f"其他错误: {e}")
- 目前准备了3各表分别存储省市县的区划数据。其他的两个标结构基本相同

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 2
2 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)