基于RAG的法律条文智能助手-方案与数据
评分原理:使用 BGE-reranker 等交叉编码器计算 query-doc 交互。特点:计算代价高,分数范围可能为任意实数(需 sigmoid 处理)评分原理:基于 BGE-samll 等双编码器模型的余弦相似度。实现 RAG 与 Lora 微调结合的模型优化方案。支持条款精准引用(如 “《劳动法》第 36 条”)处理复杂查询(如劳动纠纷中的多条款关联分析)重点:RAG 在动态更新和可解释性上
基于 RAG 的法律条文智能助手 - 方案与数据
项目目标
掌握法律智能问答系统的需求分析与 RAG 技术选型逻辑
学会法律条文数据爬取、清洗与结构化处理
实现 RAG 与 Lora 微调结合的模型优化方案
项目内容与重点
需求设计
每月更新最新法律条文
支持条款精准引用(如 “《劳动法》第 36 条”)
处理复杂查询(如劳动纠纷中的多条款关联分析)
技术选型:RAG vs 微调
重点:RAG 在动态更新和可解释性上的优势
| 对比维度 | RAG 方案 | 微调方案 |
| 数据更新频率 | 支持动态更新知识库 | 需重新标注数据并训练模型 |
| 内容准确性 | 直接引用原文,避免生成失真(避免模型幻觉问题) | 依赖标注数据的质量,易产生偏差 |
| 知识覆盖范围 | 适合大模型知识体系(可扩展至任意规模的领域知识,不受模型参数限制) | 模型的知识完全来自训练数据,需海量标注数据 |
| 可解释性 | 支持条款溯源,符合法律严谨性 | 黑盒模型,解释性差(无法追踪生成内容的依据) |
核心实现流程
# 流程图
用户提问 → 问题解析 → RAG检索 → 生成答案 → 引用溯源
# 关键模块
1. RAG检索层
使用微调后的通用大模型(如劳动法领域适配模型)
知识库构建:结构化法律条文(JSON格式)
2. 数据更新模块
定时爬取政府官网最新法规
自动化解析条款(正则匹配 第[一二三四...]条 )
重点:RAG与领域微调的结合策略。
数据收集与整理

import json
import re # python中用于正则表达式操作的标准库模块
import requests
from bs4 import BeautifulSoup # BeautifulSoup 是一个用于解析HTML和XML文档的Python库
def fetch_and_parse(url):
# 请求网页
response = requests.get(url)
# 设置网页编码格式
response.encoding = 'utf-8'
# 解析网页内容
soup = BeautifulSoup(response.text, 'html.parser')
# 提取正文内容
content = soup.find_all('p')
# 初始化存储数据
data = []
# 提取文本并格式化
for para in content:
text = para.get_text(strip=True) # 获取文本并除去空格
if text: # 只处理非空文本
# 根据需求格式化内容
data.append(text)
data_str = '\n'.join(data) # 将容器类型中的多个元素通过指定字符拼接成一个字符串
# print(data_str)
return data_str
def extract_law_articles(data_str):
# 使用正则表达式,匹配每个条款号及其内容
pattern = re.compile(r'第([一二三四五六七八九十零百]+)条.*?(?=\n第|$)', re.DOTALL)
# 初始化字典来存储条款号和内容
lawarticles = {}
# 搜索所有匹配项
for match in pattern.finditer(data_str):
articlenumber = match.group(1) # group():在re模块中,用于提取匹配结果中捕获组的内容
articlecontent = match.group(0).replace('第' + articlenumber + '条', '').strip()
lawarticles[f"中华人民共和国劳动法 第{articlenumber}条"] = articlecontent
# 转换字典为JSON字符串
jsonstr = json.dumps(lawarticles, ensure_ascii=False, indent=4)
return jsonstr
if __name__ == '__main__':
# 请求页面
url = "https://www.gov.cn/banshi/2005-05/25/content_905.htm"
data_str = fetch_and_parse(url)
json_str = extract_law_articles(data_str)
print(json_str)
中华人民共和国劳动法

import json
import re
import requests
from bs4 import BeautifulSoup
def fetch_and_parse(url):
# 请求网页
response = requests.get(url)
# 设置网页编码格式
response.encoding = 'utf-8'
# 解析网页内容
soup = BeautifulSoup(response.text, 'html.parser')
# 提取正文内容
content = soup.find_all('p')
# 初始化存储数据
data = []
for p in content:
text = p.get_text().strip()
# text = p.get_text(strip=True)
if text:
for line in text.split('\n'):
data.append(line.strip())
data_str = '\n'.join(data)
return data_str
def extract_law_articles(data_str):
# 使用正则表达式,匹配每个条款号及其内容
pattern = re.compile(r'第([一二三四五六七八九十零百]+)条.*?(?=\n第|$)', re.DOTALL)
# 初始化字典来存储条款号和内容
lawarticles = {}
# 搜索所有匹配项
for match in pattern.finditer(data_str):
articlenumber = match.group(1) # group():在re模块中,用于提取匹配结果中捕获组的内容
articlecontent = match.group(0).replace('第' + articlenumber + '条', '').strip()
lawarticles[f"中华人民共和国劳动合同法 第{articlenumber}条"] = articlecontent
# 转换字典为JSON字符串
jsonstr = json.dumps(lawarticles, ensure_ascii=False, indent=4)
return jsonstr
if __name__ == '__main__':
url = "https://www.gov.cn/ziliao/flfg/2007-06/29/content_669394.htm"
data_str = fetch_and_parse(url)
json_str = extract_law_articles(data_str)
print(json_str)
中华人民国和过劳动合同
Lora 微调优化
微调场景
适用情况:
小众领域(如劳动仲裁)需提升问答专业性
需结合RAG知识库的问答对进行增强训练
微调步骤
1. 准备少量高质量问答数据(示例):
2. 使用Lora轻量化微调大模型,提升领域理解能力
重点:小样本微调与RAG的协同优化
基于 RAG 的法律条文智能助手 - 实现与部署
优化策略对比
| 优化维度 | 优化前 | 优化后 |
| 检索范围 | 固定 Top3 | 初筛 Top10 + 精排 Top3 |
| 排序方式 | 余弦相似度 | 语义重排序列模型 |
| 提示词设计 | 简单模板 | 强化约束的额多条件模板 |
基础代码

import json
import chromadb
import time
from pathlib import Path # Python 中用于面向对象处理文件系统路径的类,提供跨平台支持(自动处理不同操作系统的路径分隔符)
from typing import List,Dict # 用于类型注释,表示函数返回的类型
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.core import Settings,VectorStoreIndex,StorageContext
# VectorStoreIndex(向量存储索引):将文档转换为向量并存储在向量数据库中(文档自动分块和向量化)
# StorageContext(存储上下文):管理索引的存储后端,包括向量存储、文档存储和索引存储
# Settings(全局设置):LlamaIndex 的全局配置中心,统一管理各种组件的默认设置
from llama_index.core.schema import TextNode
from llama_index.llms.huggingface import HuggingFaceLLM
from llama_index.vector_stores.chroma import ChromaVectorStore # ChroaVectorStore用于将向量索引存储在Chroma数据库并进行高效相似性搜索的能力
from llama_index.core import PromptTemplate
QA_TEMPLATE = (
"<|im_start|>system\n"
"你是一个专业的法律助手,请严格根据以下法律条文回答问题:\n"
"相关法律条文:\n{context_str}\n<|im_end|>\n"
"<|im_start|>user\n{query_str}<|im_end|>\n"
"<|im_start|>assistant\n"
)
response_template = PromptTemplate(QA_TEMPLATE)
# =================== 配置区 ====================
class Config:
EMBED_MODEL_PATH = r"E:\ai_model_data\model\embedding_model\sungw111\text2vec-base-chinese-sentence"
LLM_MODEL_PATH = r"E:\ai_model_data\model\Qwen\Qwen2___5-0___5B-Instruct"
DATA_DIR = r"D:\PycharmProjects\rag_laber_law\data"
VECTOR_DB_DIR = r"D:\PycharmProjects\rag_laber_law\chroma_db"
PERSIST_DIR = r"D:\PycharmProjects\rag_laber_law\storage"
COLLECTION_NAME = "chinese_labor_laws"
TOP_K = 10 # 扩大初始检索数量
配置

# ================== 初始化模型并验证 ==================
def init_models():
# 初始化Embedding模型
embed_model = HuggingFaceEmbedding(
model_name = Config.EMBED_MODEL_PATH,
# encode_kwargs = { # 自定义编码过程中的参数
# 'normalize_embeddings': True , # 是否对生成的向量进行归一化
# 'device': 'cuda' if hasattr(Settings, 'device') else 'cpu'
# }
)
Settings.embed_model = embed_model
# 初始化LLM模型
llm = HuggingFaceLLM(
model_name = Config.LLM_MODEL_PATH,
tokenizer_name = Config.LLM_MODEL_PATH,
model_kwargs = {"trust_remote_code": True},
tokenizer_kwargs = {"trust_remote_code": True},
generate_kwargs = {"temperature": 0.3}
)
Settings.llm = llm
# 验证模型
test_embedding = embed_model.get_text_embedding("测试文本")
print(f"Embedding维度验证:{len(test_embedding)}")
return embed_model,llm
init_models

# ================== 数据处理 ==================
def load_and_validate_json_files(data_dir: str) -> List[Dict]:
"""加载并验证JSON法律文件"""
json_files = list(Path(data_dir).glob("*.json")) # glob支持通配符匹配,返回生成器
assert json_files,f"未找到JSON文件于{data_dir}" # assert 是一个用于调试的关键字,用于在代码中设置检查点,验证某个条件是否为 True。如果条件为 False,则会触发 AssertionError 异常
all_data = []
for json_file in json_files:
with open(json_file,'r',encoding='utf-8') as f:
try:
data = json.load(f)
print(data)
# 验证数据结构
if not isinstance(data,list): # isinstance用于检查一个对象是否属于指定的类型或类型元组中的某一个类型
raise ValueError(f"文件 {json_file.name} 根元素应为列表") # raise用于主动引发异常的关键字
for item in data:
if not isinstance(item,dict):
raise ValueError(f"文件 {json_file.name} 包含非字典元素")
for k,v in item.items():
if not isinstance(v,str):
raise ValueError(f"文件 {json_file.name} 中键 '{k}' 的值不是字符串")
all_data.extend(
{
"content": item,
"metadata": {"source": json_file.name}
} for item in data
)
except Exception as e:
raise RuntimeError(f"加载文件 {json_file} 失败: {str(e)}")
print(f"成功加载 {len(all_data)} 个法律文件条目")
return all_data
load_and_validate_json_files

# ====================== 创建节点 =====================
def create_nodes(raw_data: List[Dict]) -> List[TextNode]:
# 添加id稳定性保障
nodes = []
for entry in raw_data:
law_dict = entry["content"]
source_file = entry["metadata"]["source"]
for full_title, content in law_dict.items():
# 生成稳定id(避免重复)
node_id = f"{source_file}::{full_title}"
parts = full_title.split(" ",1)
law_name = parts[0] if len(parts) > 0 else "未知法律"
article = parts[1] if len(parts) > 1 else "未知条款"
node = TextNode(
text = content,
id = node_id,
metadata = {
"law_name": law_name,
"article": article,
"full_title": full_title,
"source_file": source_file,
"content_type": "legal_article"
}
)
nodes.append(node)
print(f"生成 {len(nodes)} 个文本节点(ID示例:{nodes[0].id_})")
return nodes
create_nodes

# ================== 向量存储 ==================
def init_vector_store(nodes: List[TextNode]) -> VectorStoreIndex:
chroma_client = chromadb.PersistentClient(path=Config.VECTOR_DB_DIR)
chroma_collection = chroma_client.get_or_create_collection(
name = Config.COLLECTION_NAME,
metadata = {"hnsw:space": "cosine"}, # 指定余弦相似度计算
)
# 确保存储上下文正确初始化
storage_context = StorageContext.from_defaults(
vector_store=ChromaVectorStore(chroma_collection=chroma_collection)
)
# 判断是否需要新建索引
if chroma_collection.count() == 0 and nodes is not None:
print(f"创建新索引({len(nodes)}个节点)...")
# 显式将节点添加到存储上下文
storage_context.docstore.add_documents(nodes)
index = VectorStoreIndex(
nodes,
storage_context=storage_context,
show_progress=True
)
# 双重持久化保障
storage_context.persist(persist_dir=Config.PERSIST_DIR)
index.storage_context.persist(persist_dir=Config.PERSIST_DIR) # <-- 新增
else:
print("加载已有索引...")
storage_context = StorageContext.from_defaults(
persist_dir=Config.PERSIST_DIR,
vector_store=ChromaVectorStore(chroma_collection=chroma_collection)
)
index = VectorStoreIndex.from_vector_store(
storage_context.vector_store,
storage_context=storage_context,
embed_model=Settings.embed_model
)
# 安全验证
print("\n存储验证结果:")
doc_count = len(storage_context.docstore.docs)
print(f"DocStore记录数:{doc_count}")
if doc_count > 0:
sample_key = next(iter(storage_context.docstore.docs.keys()))
print(f"示例节点ID:{sample_key}")
else:
print("警告:文档存储为空,请检查节点添加逻辑!")
return index
init_vector_store

# ================== 主程序 ==================
def main():
embed_model,llm = init_models()
# 仅当需要更新数据时执行
if not Path(Config.VECTOR_DB_DIR).exists():
print("\n初始化数据...")
raw_data = load_and_validate_json_files(Config.DATA_DIR)
nodes = create_nodes(raw_data)
else:
nodes = None # 已有数据时不加载
print("\n初始化向量存储...")
start_time = time.time()
index = init_vector_store(nodes)
print(f"索引加载耗时:{time.time() - start_time:.2f}s")
# 创建查询引擎
query_engine = index.as_query_engine(
similarity_top_k = Config.TOP_K,
text_qa_template = response_template,
verbose = True
)
# 示例查询
while True:
question = input("\n请输入劳动法相关问题(输入q退出): ")
if question.lower() == 'q':
break
# 执行查询
response = query_engine.query(question)
# 显示结果
print(f"\n智能助手回答:\n{response.response}")
print("\n支持依据:")
for idx, node in enumerate(response.source_nodes, 1):
meta = node.metadata
print(f"\n[{idx}] {meta['full_title']}")
print(f" 来源文件:{meta['source_file']}")
print(f" 法律名称:{meta['law_name']}")
print(f" 条款内容:{node.text[:100]}...")
print(f" 相关度得分:{node.score:.4f}")
if __name__ == "__main__":
main()
main
本地持久化存储转码
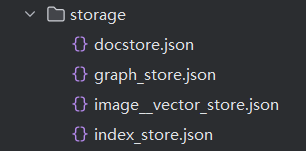

import json
def load_and_print_json(file_path):
# 读取JSON文件
with open(file_path, 'r', encoding='utf-8') as file:
data = json.load(file)
# print(data)
# # 遍历数据并打印中文内容
# for key, value in data['docstore/data'].items():
# # 获取中文标题
# full_title = value['__data__']['metadata']['full_title']
# # 获取文本内容
# text = value['__data__']['text']
# print(f"标题:{full_title}")
# print(f"内容:{text}\n")
# 将JSON数据格式化并打印
formatted_json = json.dumps(data, ensure_ascii=False, indent=4)
print(formatted_json)
# 使用函数
file_path = r'D:\PycharmProjects\rag_laber_law\storage\docstore.json'
load_and_print_json(file_path)
read_json

"docstore/data": {
"6bce5145-5233-4ef9-ba73-46af7e4a278d": {
"__data__": {
"id_": "6bce5145-5233-4ef9-ba73-46af7e4a278d",
"embedding": null,
"metadata": {
"law_name": "中华人民共和国劳动法",
"article": "第一条",
"full_title": "中华人民共和国劳动法 第一条",
"source_file": "file.json",
"content_type": "legal_article"
},
"excluded_embed_metadata_keys": [],
"excluded_llm_metadata_keys": [],
"relationships": {},
"metadata_template": "{key}: {value}",
"metadata_separator": "\n",
"text": "为了保护劳动者的合法权益,调整劳动关系,建立和维护适应社会主义市场经济的劳动制度,促进经济发展和社会进步,根据宪法,制定本法。",
"mimetype": "text/plain",
"start_char_idx": null,
"end_char_idx": null,
"metadata_seperator": "\n",
"text_template": "{metadata_str}\n\n{content}",
"class_name": "TextNode"
},
"__type__": "1"
},
节点展示
重排序优化实践
技术原理
两阶段检索机制显著提升召回精度:
初筛阶段:使用向量检索获取候选集
精排阶段:通过专用重排序模型计算语义相关性
# 创建检索器和响应合成器(将查询引擎修改为创建检索器和响应合成器)
retriever = index.as_retriever( # 检索器:从索引中检索与用户查询最相关的文档片段
similarity_top_k=Config.TOP_K # 控制召回数量 )
response_synthesizer = get_response_synthesizer( # 响应合成器:基于检索器返回的节点(一般会将节点进行重排序)和用户的问题,使大模型生成最终答案
text_qa_template=response_template, # 自定义响应模板
verbose=True # 显示详细生成过程 )
# 1. 初始检索
initial_nodes = retriever.retrieve(question)
for node in initial_nodes:
node.node.metadata['initial_score'] = node.score # 保存初始分数到元数据
# 2. 重排序
reranked_nodes = reranker.postprocess_nodes(initial_nodes,query_str=question)
# 3. 合成答案
response = response_synthesizer.synthesize(question,nodes=reranked_nodes)
初始检索与重排序评分机制差异
初始检索(向量相似度)
评分原理:基于 BGE-samll 等双编码器模型的余弦相似度
特定:快速计算,分数范围通常为 0-1
示例计算:
查询向量 = [0.2, 0.5, ..., 0.7] # 维度768
文档向量 = [0.3, 0.6, ..., 0.6]
相似度 = cosine_similarity(查询向量, 文档向量) # 0.9276
重排序(交叉编码器)
评分原理:使用 BGE-reranker 等交叉编码器计算 query-doc 交互
特点:计算代价高,分数范围可能为任意实数(需 sigmoid 处理)
示例计算:
model_input = "[CLS]劳动合同解除通知期[SEP]劳动合同期满终止条款[SEP]"
logits = model(model_input) # 输出原始分数如1.2
score = 1 / (1 + exp(-logits)) # 转换为0.3520
重排序优化后代码

import json
import chromadb
import time
from pathlib import Path # Python 中用于面向对象处理文件系统路径的类,提供跨平台支持(自动处理不同操作系统的路径分隔符)
from typing import List,Dict # 用于类型注释,表示函数返回的类型
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.core import Settings, VectorStoreIndex, StorageContext, get_response_synthesizer
# VectorStoreIndex(向量存储索引):将文档转换为向量并存储在向量数据库中(文档自动分块和向量化)
# StorageContext(存储上下文):管理索引的存储后端,包括向量存储、文档存储和索引存储
# Settings(全局设置):LlamaIndex 的全局配置中心,统一管理各种组件的默认设置
from llama_index.core.schema import TextNode
from llama_index.llms.huggingface import HuggingFaceLLM
from llama_index.vector_stores.chroma import ChromaVectorStore # ChroaVectorStore用于将向量索引存储在Chroma数据库并进行高效相似性搜索的能力
from llama_index.core import PromptTemplate
from llama_index.core.postprocessor import SentenceTransformerRerank # 新增重排序组件
QA_TEMPLATE = (
"<|im_start|>system\n"
"您是中国劳动法领域专业助手,必须严格遵循以下规则:\n"
"1.仅使用提供的法律条文回答问题\n"
"2.若问题与劳动法无关或超出知识库范围,明确告知无法回答\n"
"3.引用条文时标注出处\n\n"
"可用法律条文(共{context_count}条):\n{context_str}\n<|im_end|>\n"
"<|im_start|>user\n问题:{query_str}<|im_end|>\n"
"<|im_start|>assistant\n"
)
response_template = PromptTemplate(QA_TEMPLATE)
# =================== 配置区 ====================
class Config:
EMBED_MODEL_PATH = r"E:\ai_model_data\model\embedding_model\sungw111\text2vec-base-chinese-sentence"
LLM_MODEL_PATH = r"E:\ai_model_data\model\Qwen\Qwen2___5-0___5B-Instruct"
RERANK_MODEL_PATH = r"E:\ai_model_data\model\ReRanker\BAAI\bge-reranker-large" # 新增重排序模型路径
DATA_DIR = r"D:\PycharmProjects\rag_laber_law\data"
VECTOR_DB_DIR = r"D:\PycharmProjects\rag_laber_law\chroma_db"
PERSIST_DIR = r"D:\PycharmProjects\rag_laber_law\storage"
COLLECTION_NAME = "chinese_labor_laws"
TOP_K = 10 # 扩大初始检索数量
RERANK_TOP_K = 3 # 重排序后保留数量
配置

# ================== 初始化模型并验证 ==================
def init_models():
# 初始化Embedding模型
embed_model = HuggingFaceEmbedding(
model_name = Config.EMBED_MODEL_PATH,
# encode_kwargs = { # 自定义编码过程中的参数
# 'normalize_embeddings': True , # 是否对生成的向量进行归一化
# 'device': 'cuda' if hasattr(Settings, 'device') else 'cpu'
# }
)
Settings.embed_model = embed_model
# 初始化LLM模型
llm = HuggingFaceLLM(
model_name = Config.LLM_MODEL_PATH,
tokenizer_name = Config.LLM_MODEL_PATH,
model_kwargs = {"trust_remote_code": True},
tokenizer_kwargs = {"trust_remote_code": True},
generate_kwargs = {"temperature": 0.3}
)
Settings.llm = llm
# 初始化重排序模型(新增)
reranker = SentenceTransformerRerank(
model = Config.RERANK_MODEL_PATH,
top_n = Config.RERANK_TOP_K
)
# 验证模型
test_embedding = embed_model.get_text_embedding("测试文本")
print(f"Embedding维度验证:{len(test_embedding)}")
return embed_model,llm,reranker
init_models
# ================== 向量存储 ==================
def init_vector_store(nodes: List[TextNode]) -> VectorStoreIndex:
chroma_client = chromadb.PersistentClient(path=Config.VECTOR_DB_DIR)
chroma_collection = chroma_client.get_or_create_collection(
name = Config.COLLECTION_NAME,
metadata = {"hnsw:space": "cosine"}, # 指定余弦相似度计算
)
# 确保存储上下文正确初始化
storage_context = StorageContext.from_defaults(
vector_store=ChromaVectorStore(chroma_collection=chroma_collection)
)
# 判断是否需要新建索引
if chroma_collection.count() == 0 and nodes is not None:
print(f"创建新索引({len(nodes)}个节点)...")
# 显式将节点添加到存储上下文
storage_context.docstore.add_documents(nodes)
index = VectorStoreIndex(
nodes,
storage_context=storage_context,
show_progress=True
)
# 双重持久化保障
storage_context.persist(persist_dir=Config.PERSIST_DIR)
index.storage_context.persist(persist_dir=Config.PERSIST_DIR) # <-- 新增
else:
print("加载已有索引...")
storage_context = StorageContext.from_defaults(
persist_dir=Config.PERSIST_DIR,
vector_store=ChromaVectorStore(chroma_collection=chroma_collection)
)
index = VectorStoreIndex.from_vector_store(
storage_context.vector_store,
storage_context=storage_context,
embed_model=Settings.embed_model
)
# 安全验证
print("\n存储验证结果:")
doc_count = len(storage_context.docstore.docs)
print(f"DocStore记录数:{doc_count}")
if doc_count > 0:
sample_key = next(iter(storage_context.docstore.docs.keys()))
print(f"示例节点ID:{sample_key}")
else:
print("警告:文档存储为空,请检查节点添加逻辑!")
return index
init_vector_store

#新增过滤函数
def is_legal_question(text: str) -> bool:
"""判断问题是否属于法律咨询"""
legal_keywords = ["劳动法", "合同", "工资", "工伤", "解除", "赔偿"]
return any(keyword in text for keyword in legal_keywords)
# ================== 主程序 ==================
def main():
embed_model,llm,reranker = init_models()
# 仅当需要更新数据时执行
if not Path(Config.VECTOR_DB_DIR).exists():
print("\n初始化数据...")
# raw_data = load_and_validate_json_files(Config.DATA_DIR)
# nodes = create_nodes(raw_data)
else:
nodes = None # 已有数据时不加载
print("\n初始化向量存储...")
start_time = time.time()
index = init_vector_store(nodes)
print(f"索引加载耗时:{time.time() - start_time:.2f}s")
# # 创建查询引擎
# query_engine = index.as_query_engine(
# similarity_top_k = Config.TOP_K,
# text_qa_template = response_template,
# verbose = True
# )
# 创建检索器和响应合成器(将查询引擎修改为创建检索器和响应合成器)
retriever = index.as_retriever( # 检索器:从索引中检索与用户查询最相关的文档片段
similarity_top_k=Config.TOP_K # 控制召回数量
)
response_synthesizer = get_response_synthesizer( # 响应合成器:基于检索器返回的节点(一般会将节点进行重排序)和用户的问题,使大模型生成最终答案
text_qa_template=response_template, # 自定义响应模板
verbose=True # 显示详细生成过程
)
# 示例查询
while True:
question = input("\n请输入劳动法相关问题(输入q退出): ")
if question.lower() == 'q':
break
# 添加问答类型判断(关键修改)
# if not is_legal_question(question): # 新增判断函数
# print("\n您好!我是劳动法咨询助手,专注解答《劳动法》《劳动合同法》等相关问题。")
# continue
# 执行检索-重排序-回答流程(新增重排序相关步骤)
start_time = time.time()
# 1. 初始检索
initial_nodes = retriever.retrieve(question)
retrieval_time = time.time() - start_time
for node in initial_nodes:
node.node.metadata['initial_score'] = node.score # 保存初始分数到元数据
# 2. 重排序
reranked_nodes = reranker.postprocess_nodes(
initial_nodes,
query_str=question
)
rerank_time = time.time() - start_time - retrieval_time
# ★★★★★ 添加过滤逻辑在此处 ★★★★★
MIN_RERANK_SCORE = 0.4 # 设置阈值
# 执行过滤
filtered_nodes = [
node for node in reranked_nodes
if node.score > MIN_RERANK_SCORE
]
# 一般对模型的回复做限制就从filtered_nodes的返回值下手
# print("原始分数样例:", [node.score for node in reranked_nodes[:3]])
# print("重排序过滤后的结果:", filtered_nodes)
# 空结果处理
if not filtered_nodes:
print("你的问题未匹配到相关资料!")
continue
# 3. 合成答案
response = response_synthesizer.synthesize(
question,
nodes=reranked_nodes
)
synthesis_time = time.time() - start_time - retrieval_time - rerank_time
# 显示结果(修改显示逻辑)
print(f"\n智能助手回答:\n{response.response}")
print("\n支持依据:")
for idx, node in enumerate(reranked_nodes, 1):
# 兼容新版API的分数获取方式
initial_score = node.metadata.get('initial_score', node.score) # 获取初始分数
rerank_score = node.score # 重排序后的分数
meta = node.node.metadata
print(f"\n[{idx}] {meta['full_title']}")
print(f" 来源文件:{meta['source_file']}")
print(f" 法律名称:{meta['law_name']}")
print(f" 初始相关度:{node.node.metadata['initial_score']:.4f}")
print(f" 重排序得分:{node.score:.4f}")
print(f" 条款内容:{node.node.text[:100]}...")
print(f"\n[性能分析] 检索: {retrieval_time:.2f}s | 重排序: {rerank_time:.2f}s | 合成: {synthesis_time:.2f}s")
if __name__ == "__main__":
main()
main
vLLM 高性能推理集成
HuggingFace 引擎运行大模型较慢
部署配置
# 启动vLLM服务
python -m vllm.entrypoints.openai.api_server \
--model DeepSeek-R1-Distill-Qwen-1___5B \
--port 8000 \
--tensor-parallel-size 2 # GPU并行数
# -m vllm.entrypoints.openai.api_server 调用vLLM的OpenAI兼容API服务模块
# --port 8000 指定服务监听的端口号(默认8000)
系统集成
from llama_index.llms.openai_like import OpenAILikeLLM
class VLLMConfig:
API_BASE = "http://localhost:8000/v1"
MODEL_NAME = "DeepSeek-R1-Distill-Qwen-1___5B"
TIMEOUT = 60
def init_vllm_llm():
return OpenAILikeLLM(
model=VLLMConfig.MODEL_NAME,
api_base=VLLMConfig.API_BASE,
temperature=0.3,
max_tokens=1024,
additional_kwargs={"stop": ["<|im_end|>"]}
)
# 替换原有LLM组件
Settings.llm = init_vllm_llm()
性能对比
| 指标 | HuggingFace 推理 | vLLM 加速 | 提升幅度 |
| 生成速度(tokens/s) | 45 | 320 | 7.1x |
| 显存占用(7B 模型) | 8.2GB | 5.1GB | -38% |
| 长文本响应延迟 | 12.4s | 3.8s | 3.26x |
Streamlit 可视化系统
界面组件设计

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)