2025热门技术深度剖析!机器学习驱动的催化剂设计打破传统方案!
专题将系统引导学者深入理解电催化、热催化、光催化的核心原理,同时全面剖析机器学习、深度学习及图深度学习在催化领域的应用背景与适用范畴。
机器学习与催化剂设计的结合源于传统实验和计算方法的局限性。传统催化剂开发依赖试错法或密度泛函理论(DFT)计算,耗时且成本高昂。随着数据科学的发展,催化剂领域积累了大量实验和模拟数据,为机器学习提供了训练基础。
催化剂的性能优化涉及多变量(如活性位点、电子结构、载体效应等),机器学习能够高效挖掘高维数据中的隐藏规律,加速从“经验驱动”到“数据驱动”的范式转变。
技术优势
高效筛选与预测
机器学习模型可快速预测催化剂的活性、选择性和稳定性,显著减少实验或计算筛选的工作量。例如,通过描述符(如吸附能、d-band中心)训练模型,预测新型合金或单原子催化剂的性能。
复杂关系建模
催化机制常涉及非线性和多尺度问题(如反应动力学与表面结构的关联)。机器学习方法(如神经网络、随机森林)能够捕捉这类复杂关系,辅助理解构效关系。
逆向设计
生成模型(如VAE、GAN)或优化算法(如贝叶斯优化)可逆向生成满足特定性能的催化剂结构,突破传统试错法的设计瓶颈。
多目标优化
同时优化多个性能指标(如转化率、成本、耐久性),机器学习能平衡不同目标间的权衡,提供帕累托最优解。
跨尺度整合
结合第一性原理计算、分子动力学和宏观实验数据,机器学习桥接微观与宏观尺度的信息,实现更全面的设计策略。
催化科学正经历机器学习(ML)驱动的变革。传统“试错法”研发周期长、成本高,而ML通过数据挖掘与模型预测,开创了高效精准的催化剂设计新范式。
ML的应用贯穿催化全链条:材料发现上,其整合实验与计算数据(如电子结构、表面活性),快速筛选高性能候选材料,图神经网络已设计出高效析氧催化剂,推动绿氢规模化;机理解析中,ML融合原位表征与模拟数据,智能识别反应路径关键节点,如在CO₂还原中加速过渡态搜索;性能优化上,ML构建跨尺度“结构-功能”模型,实现稳定性与经济性平衡,如强化学习设计多孔催化剂,协同提升传质与活性位点密度。
专题目标:
- 专题将系统引导学者深入理解电催化、热催化、光催化的核心原理,同时全面剖析机器学习、深度学习及图深度学习在催化领域的应用背景与适用范畴。通过 Python 语言基础与机器学习算法的专项学习,学者不仅能够清晰梳理机器学习从萌芽到蓬勃发展的历史脉络,洞悉其在信息时代于不同领域的多样化表现形式,更将通过实践操作,切实掌握将机器学习技术应用于科学研究的关键技能,为催化领域的前沿探索奠定坚实基础。
- 课程助力学者精准把握传统机器学习算法与深度学习算法的本质差异,熟练掌握 sklearn、torch 等主流第三方库的核心功能与应用技巧。通过系统学习与实践,学者将能够灵活运用树模型、深度神经网络、卷积神经网络、循环神经网络等算法模型,深度融入科学研究场景。同时,借助机器学习的可解释性分析方法,深入挖掘数据背后的科学规律,精准阐释催化反应机制,实现数据驱动与理论解析的深度融合,为科学研究提供创新分析视角与可靠技术支撑。
- 通过培养学者将机器学习应用在催化领域的研究思维,加速研究范式转变。将机器学习与第一性原理或者实验结合,以实现快速发现催化材料。这种结合能够充分发挥不同方法的优势,机器学习强大的数据处理和模式识别能力,可挖掘催化过程中的隐藏规律,第一性原理则能从量子力学层面揭示催化反应的本质,实验数据为模型提供真实可靠的验证基础。同时,引导学者运用迁移学习等技术,将在某一催化体系中训练得到的模型,快速应用到相似体系,实现知识的高效复用。此外,借助机器学习的可解释性研究,还能帮助学员深入理解催化反应机制,为进一步优化催化材料性能、设计新型催化体系提供理论支撑,推动催化领域朝着智能化、精准化方向迈进。
- 图拓扑结构和图神经网络在催化领域有着广泛的应用。由于催化过程中存在大量繁杂的中间体,这为图拓扑结构的构建提供了丰富的数据来源,从而更有利于发现新的催化路径。将晶体结构从欧式空间转化为非欧空间的图结构,相较于传统描述符,能够更有效地捕捉晶体结构与目标属性之间的映射关系。通过培养学者跨学科、跨领域、跨范式的科学思维,有望为新材料发现开辟新的研究范式。
机器学习催化剂设计专题主讲老师来自全国重点大学、国家“985工程”、“211工程”重点高校,长期从事机器学习辅助的催化剂设计与预测研究,在机器学习深度学习辅助的催化剂设计研究领域深耕多年,具有丰富的经验和扎实的基础。在多个国际高水平期刊上发表 SCI检索论文30余篇。他的授课方式深入浅出,能够将复杂的理论知识和计算方法讲解得清晰易懂!
专题内容:
第一天:
第一天上午
理论内容:
1.机器学习概述
2.材料与化学中的常见机器学习方法
3.应用前沿
实操内容:
1.Python基础:变量和数据类型,列表,字典,if语句,循环,函数
2.Python科学数据处理:NumPy,Pandas,Matplotlib
案例一:随着AI For Science时代的到来,机器学习以优异的速度迅速扩展到各个领域。本次培训详细讲解从下载到安装,再到环境配置全流程。无论是数据科学新手还是进阶学习者,都能借此掌握 Anaconda 操作要点,轻松搭建编程环境,为后续 Python 开发、数据分析等工作筑牢基础。
第一天下午
理论内容:
1.sklearn基础介绍
2.线性回归原理和正则化
实操内容:
1. 线性回归方法的实现与初步应用
2. L1和L2正则项的使用方法
3. 线性回归用于HER催化剂的筛选
4. 符号回归用于发现金属催化氧化载体中金属-载体相互作用
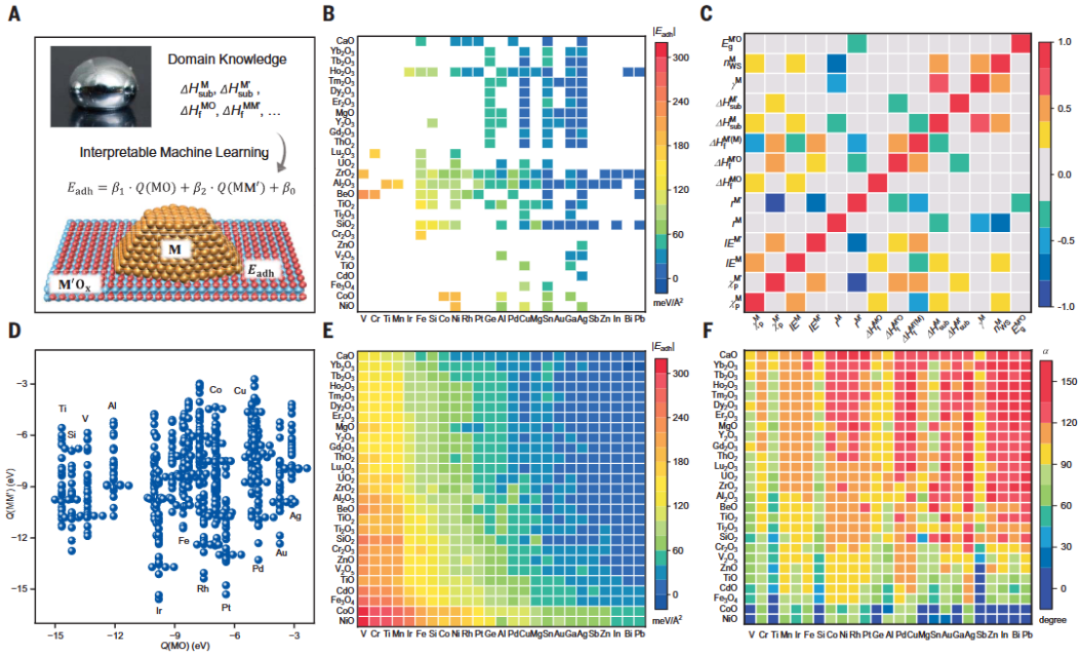
案例二:金属-载体相互作用是多相催化中最重要的支柱之一,但由于其复杂的界面,建立一个基本的理论一直具有挑战性。基于实验数据、可解释的机器学习、理论推导和第一性原理模拟,以建立了基于金属-金属和金属-氧相互作用的金属-氧化物相互作用的一般理论(符号回归)。
————————————————————————————————
第二天上午
理论内容:
1. 逻辑回归
1.1原理
1.2 使用方法
2. K近邻方法(KNN)
2.1 KNN分类原理
2.2 KNN分类应用
3. 神经网络方法的原理
3.1 神经网络原理
3.2神经网络分类
3.3神经网络回归
实操内容:
1.逻辑回归的实现与初步应用
2.KNN方法的实现与初步应用
3.神经网络实现
案例三:铜基合金催化剂因其良好的选择性和过电位低等特点,在二氧化碳还原反应(CO2RR)领域得到了广泛的应用。为了实现对CO2RR合金催化剂的高效探索,通过实施严格的特征选择过程,将特征空间的维数从13维降至5维,ML模型成功快速预测了CO2RR过程中关键中间体(HCOO、CO和COOH)的吸附能。
第二天下午
项目实操:
1.基于少特征模型的机器学习预测二氧化碳还原电催化剂
2.基于文本数据信息预测甲醇转化率
这两个实操项目同时穿插讲解如下内容
A1 机器学习材料与化学应用的典型步骤
A1.1 数据采集和清洗
A1.2 特征选择和模型选择
A1.3 模型训练和测试
A1.4 模型性能评估和优化
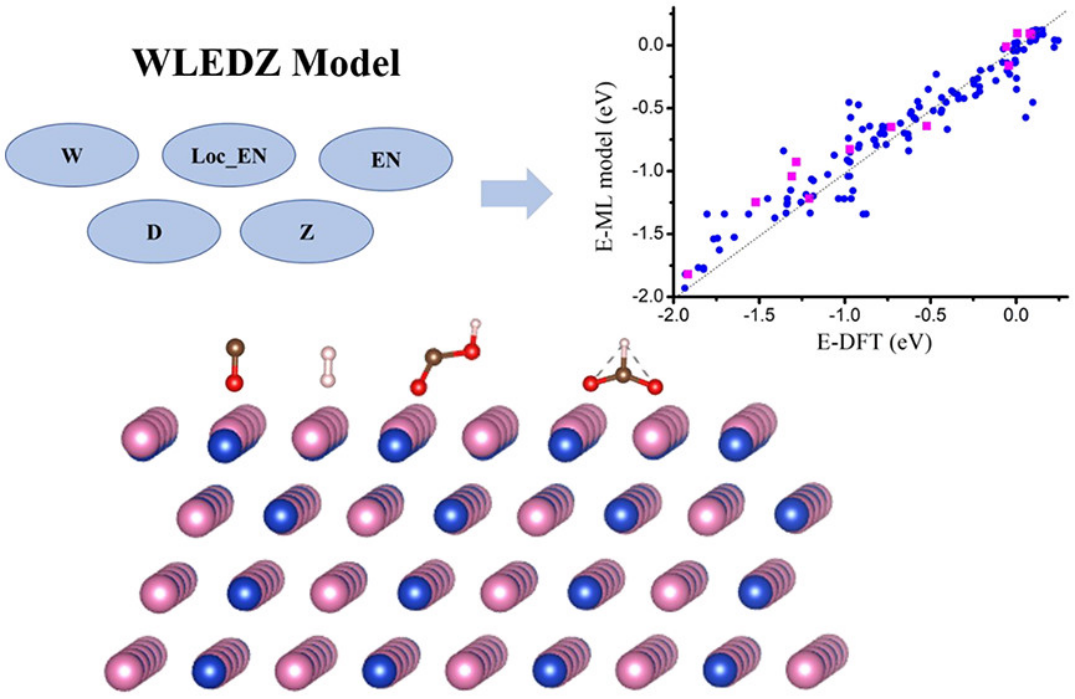
案例四:结构化材料合成路线对于化学家进行实验和现代应用(如机器学习材料设计)至关重要。近年来,化学文献呈指数级增长,人工提取已发表文献耗时耗力。本研究的重点是开发一种从化学文献中提取pd基催化剂合成路线的自动化方法。并利用合成路线的结构化数据来训练机器学习模型并预测甲烷转化率的性能。
————————————————————————————————
第三天上午
理论内容:
1.决策树
1.1决策树的原理
1.2决策树分类
2. 集成学习方法
2.1集成学习原理
2.2随机森林
2.3Bosting方法
3.朴素贝叶斯概率
3.1原理解析
3.2 模型应用
4. 支持向量机
4.1分类原理
4.2核函数
实操内容
1.决策树的实现和应用
2.随机森林的实现和应用
3.朴素贝叶斯的实现和应用
4.支持向量机的实现和应用
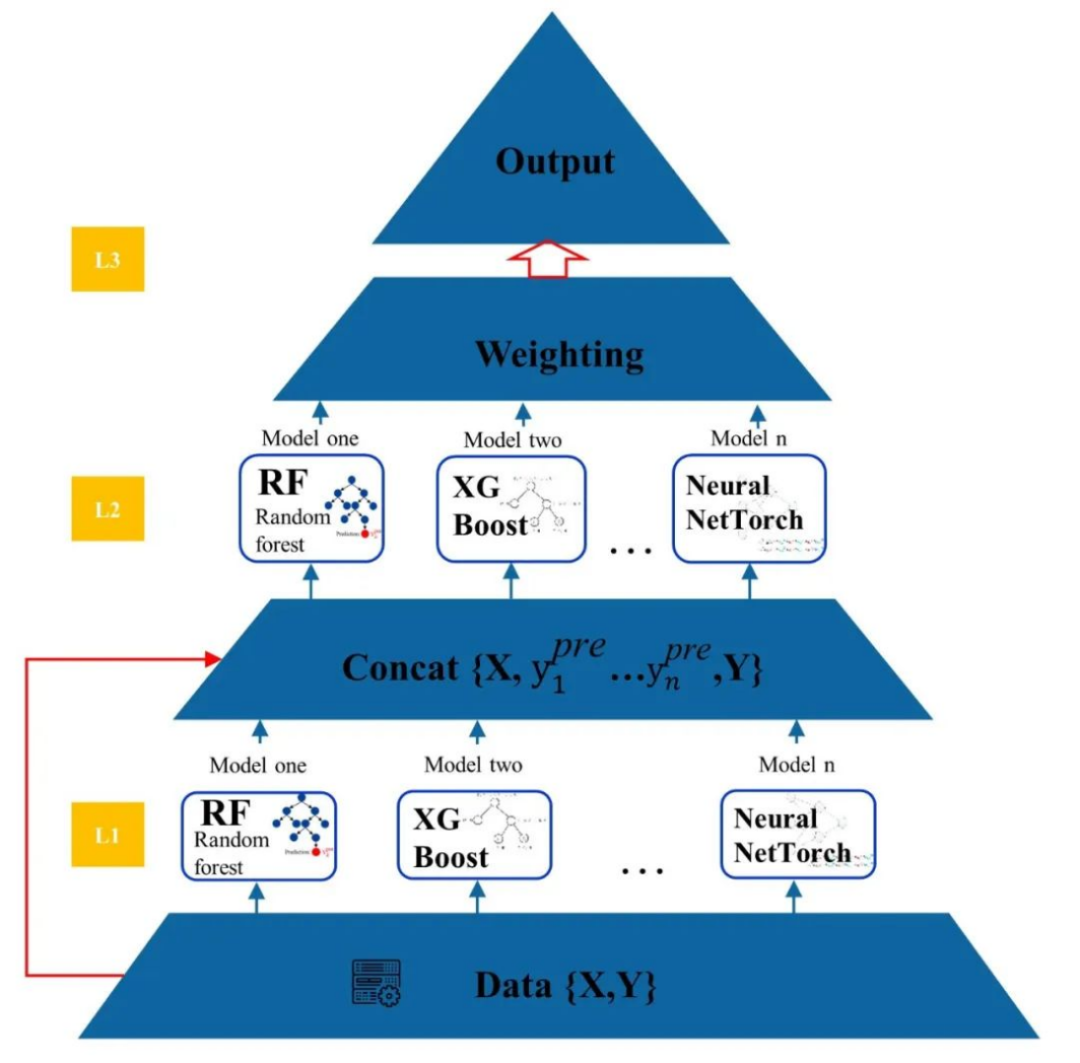
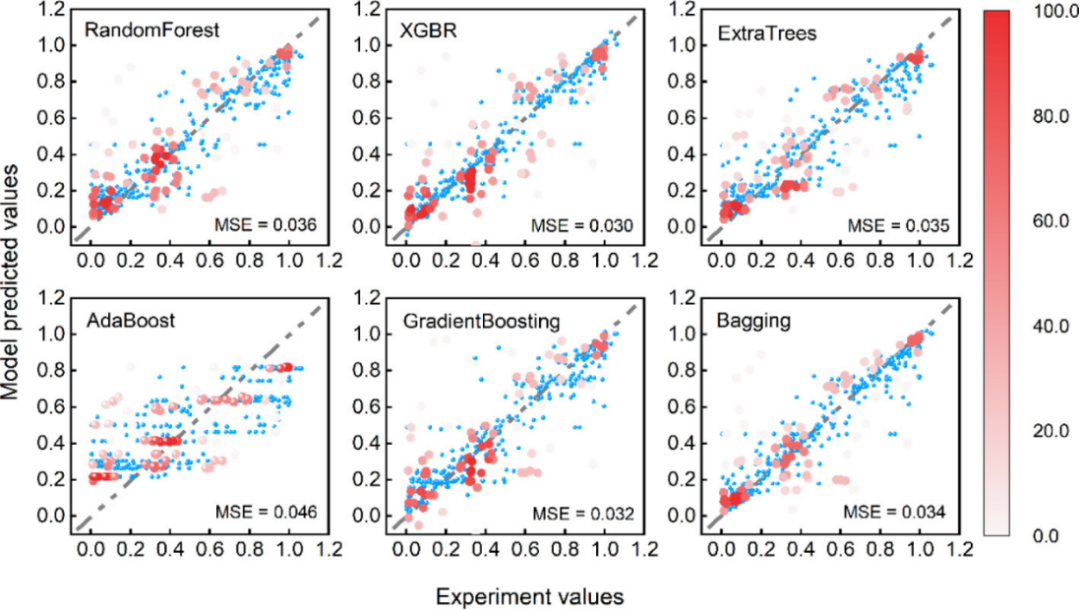
案例五:集成学习通过多层模型组合与融合,在提升模型性能方面极具优势。在数据挖掘中,面对海量且复杂的数据,单一模型往往难以全面捕捉数据特征。集成学习将弱学习器的性能结合,先由各基础模型从不同角度挖掘数据,再通过加权等方式融合结果,能更全面地剖析机器学习结果。
第三天下午
项目实操
1.机器学习加速设计ORR和OER双功能电催化剂
2.二元合金中双官能团氧电催化剂的有效机器学习模型设计
3.SHAP机器学习可解释性分析
这两个实操项目同时穿插讲解如下内容
A1 模型性能的评估方法
A1.1 交叉验证:评估估计器的性能
A1.2 分类性能评估
A1.3 回归性能评估
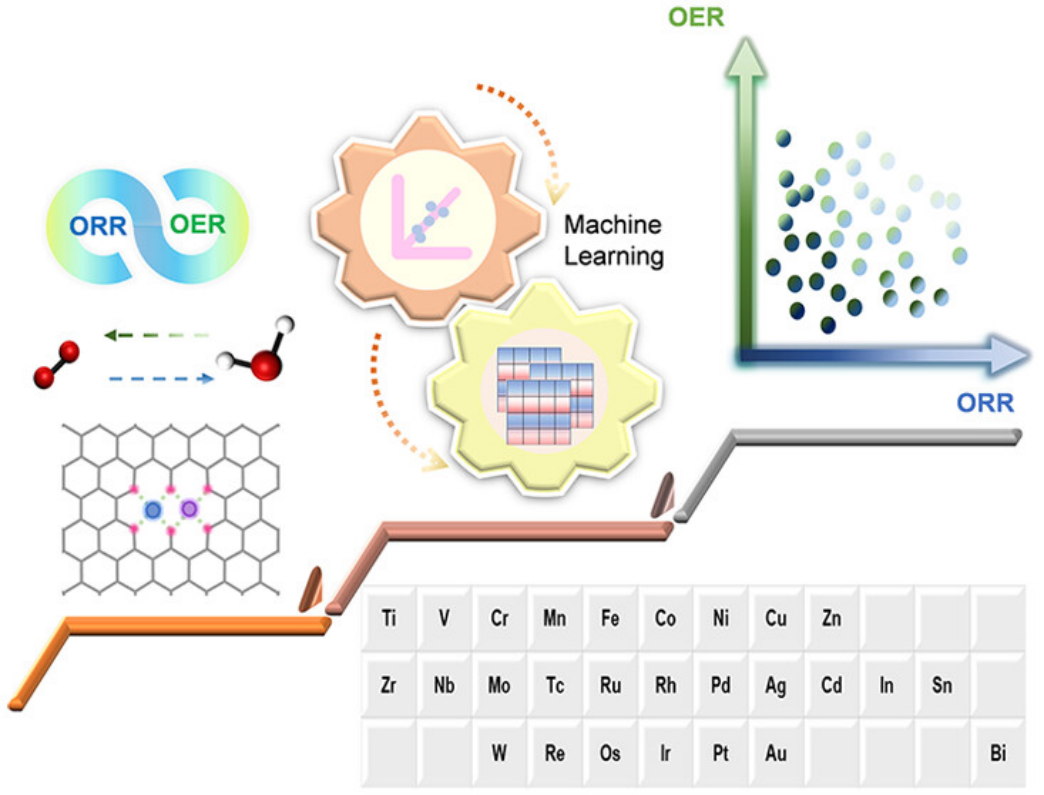
案例六:氧还原反应(ORR)和析氧反应(OER)是清洁能源转化的关键。近年来,双金属位催化剂(DMSCs)因其原子利用率高、稳定性强、催化性能好而受到广泛关注。本研究采用密度泛函理论(DFT)和机器学习(ML)相结合的先进方法,研究吸附物在数百种潜在催化剂上的吸附自由能,来筛选对ORR和OER具有高活性的催化剂。
————————————————————————————————
第四天上午
理论内容:
1. 无监督学习
2.1 什么是无监督学习
2.2 无监督算法——聚类
2.3 无监督算法——降维
2. 材料与化学数据的特征工程
2.1分子结构表示
2.2 独热编码
实操内容:
鸢尾花数据集用于聚类实现和应用
T-SNE实现和应用
PCA的实现和应用
层次聚类的实现和应用
K-means聚类的实现和应用
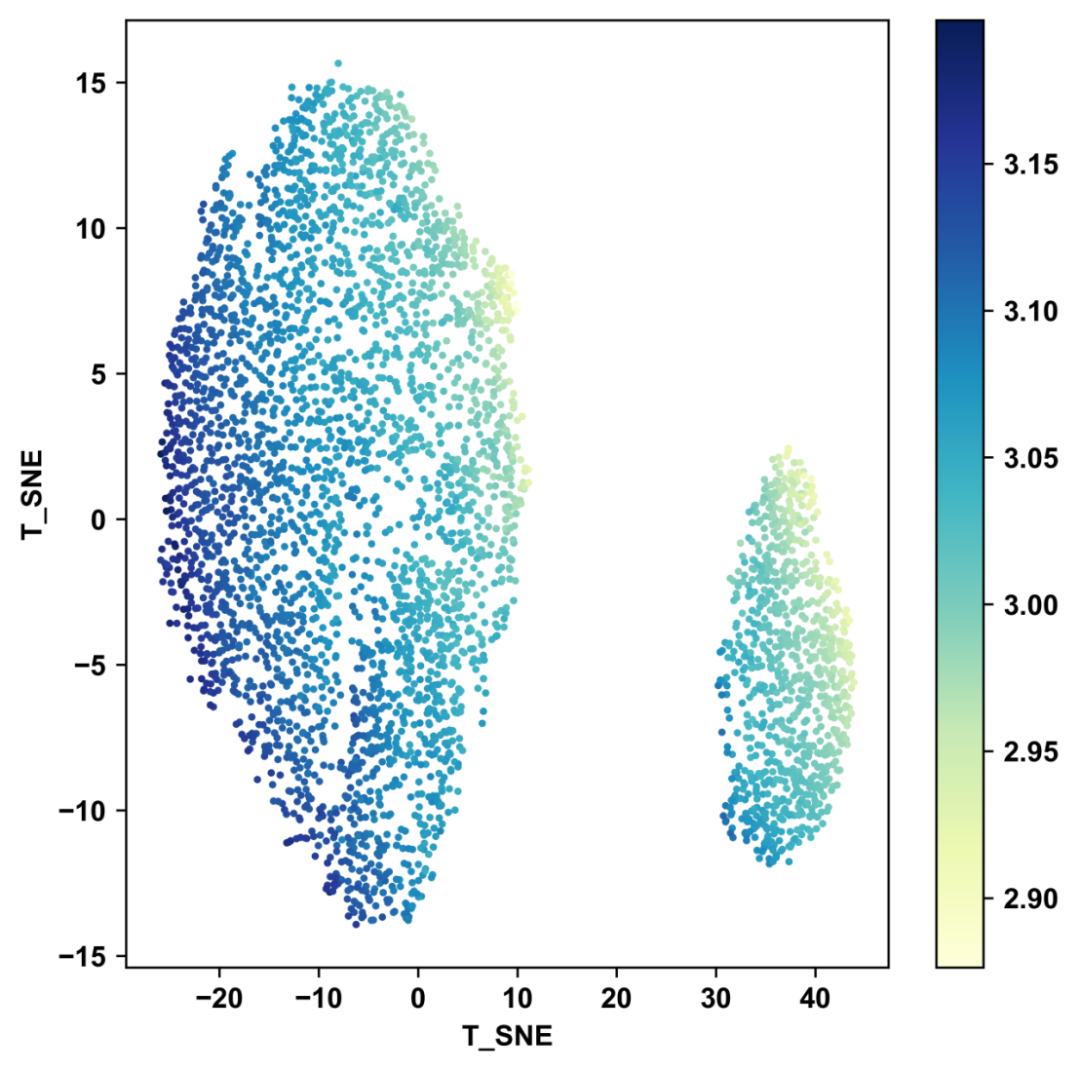
案例七:无监督学习是从无标签数据中挖掘模式与结构,t-SNE作为其重要降维工具,专注于保留高维数据点间局部结构。课程将深入讲解t-SNE核心原理,如通过概率分布衡量点间相似性,以优化KL散度实现降维,展示其在高维数据可视化中的强大作用。还会进行代码实操,涵盖数据加载、参数调优、降维及可视化等环节,让学员熟练掌握t-SNE在不同场景的应用,助力探索数据潜在结构与模式。
第四天下午
项目实操
理论内容:
1.深度学习理论基础
2.DNN、RNN、CNN、LSTM及Transformer基础框架介绍
实操内容
1. torch基础练习
2. 应用RNN、CNN、LSTM模型筛选光催化剂
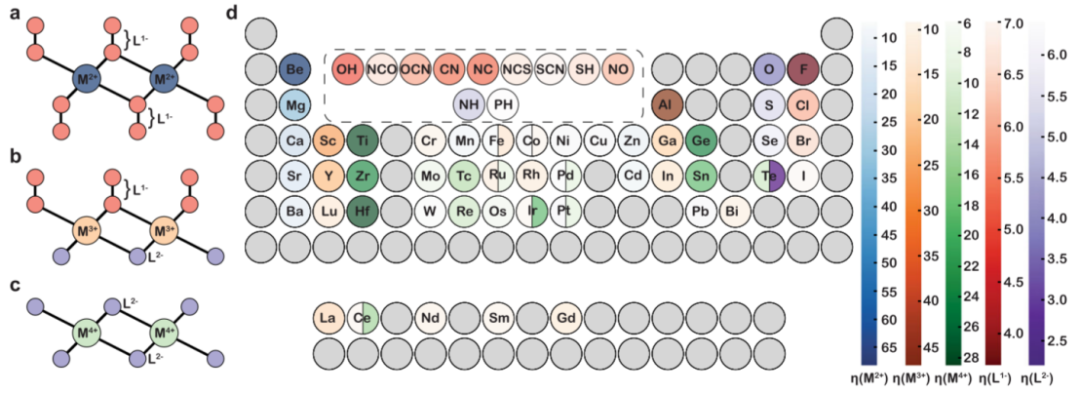
案例八:近年来,结合高通量(HT)和机器学习(ML)的策略以加速有前途的新材料的发现已经引起了人们的极大关注。因此,可以设计一种直观的方法,通过数据库并结合深度学习模型,并将它们与HT方法耦合,以寻找高效的2D水分解光催化剂。
————————————————————————————————
第五天上午
理论内容:
1.图深度学习理论基础
2.图深度学习应用实例OC20、OC22电催化剂开发挑战(ACS Catalysis)
实操内容:
1. 图结构构建及可视化
2. PyTorch Geometric基础介绍
案例九:近年来,在晶体性能预测领域,图神经网络(graph neural network,GNN)模型取得了长足的发展。GNN模型可以有效地从晶体结构中捕捉高维晶体特征,从而在性能预测中获得最佳性能。指导学员搭建图深度学习开发环境,以顺利构建图结构,并进行机器学习训练。
第五天下午
项目实操(约2.5-3小时)
1.图神经网络模型基本概述及CGCNN代码深度解读应用
2.基于图论构建反应网络用于NO电还原反应研究
3.Transformer辅助水氧化制备过氧化氢(WOR)及可解释分析
案例十:氮氧化物排放严重影响我们的环境和人类健康。光催化脱硝(deNOx)因其低成本、无污染而备受关注,但实际生产中产生的是不需要的亚硝酸盐和硝酸盐,而不是无害的氮气。揭示活性位点和光催化机理对改进工艺具有重要意义。本次课程以指导学员依据反应中间体,建立图反应网络结构以揭示反应机理。
专题特色及授课方式
线上进行时间和地点自由,建立专业课程群进行实时答疑解惑,理论+实操授课方式结合大量实战案例与项目演练,聚焦人工智能技术在催化领域、固态电解质和锂离子电池领域的最新研究进展,课前发送全部学习资料,课程提供全程答疑解惑;
完全贴合学员需求的课程体系设计,定期更新的前沿案例,由浅入深式讲解,课后提供无限次回放视频,免费赠送二次学习,发送全部案例资料,永不解散的课程群答疑,可以与相同领域内的老师同学互动交流问题,让求知的路上不再孤单!
增值服务
1、凡参加人员将获得本次课程学习资料及所有案例模型文件;
2、课程结束可获得本次所学专题全部回放视频;
3、课程会定期更新前沿内容,参加本次专题的学者可免费参加一次本单位后期举办的相同专题课程(任意一期)
私。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 31
31 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)