CALIPSO数据处理:(一)数据批量下载
calipso数据批量下载
·
1、数据下载链接:https://search.earthdata.nasa.gov/
2、搜索框输入关键词CALIPSO VFM(或其它)
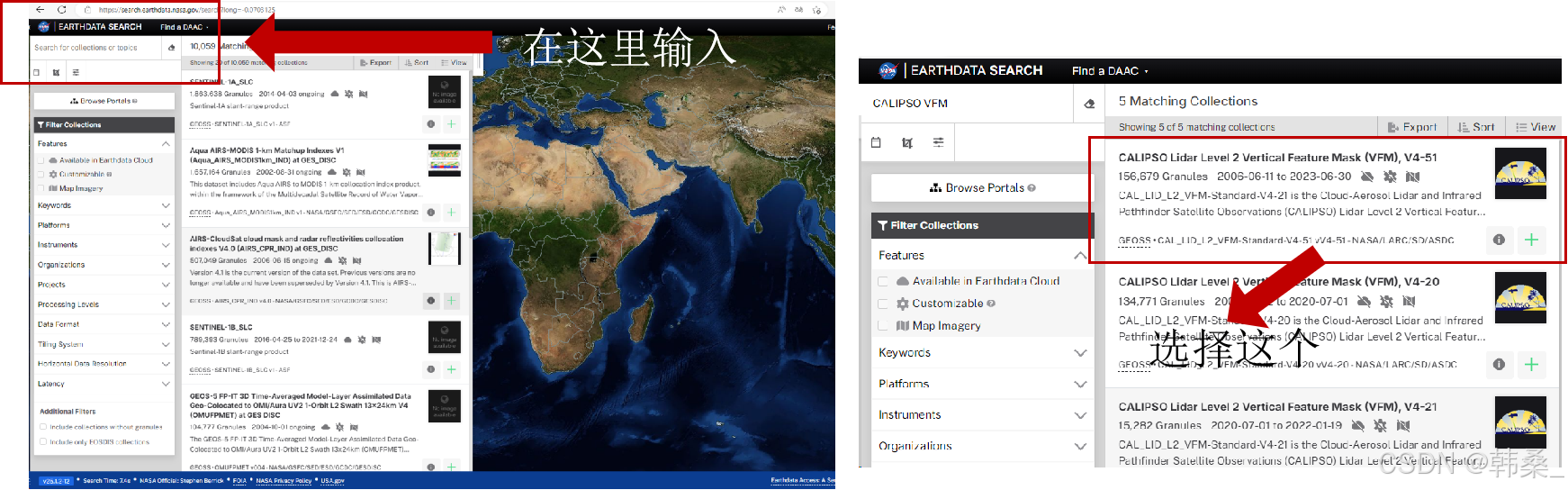
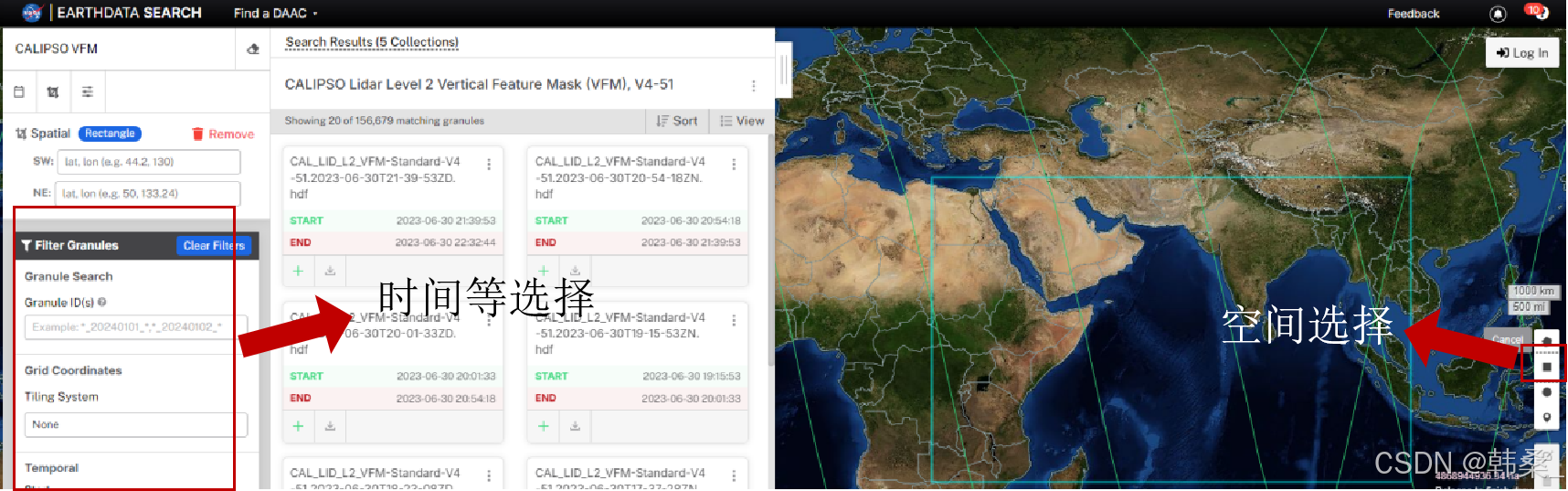
3、选择时间、空间范围
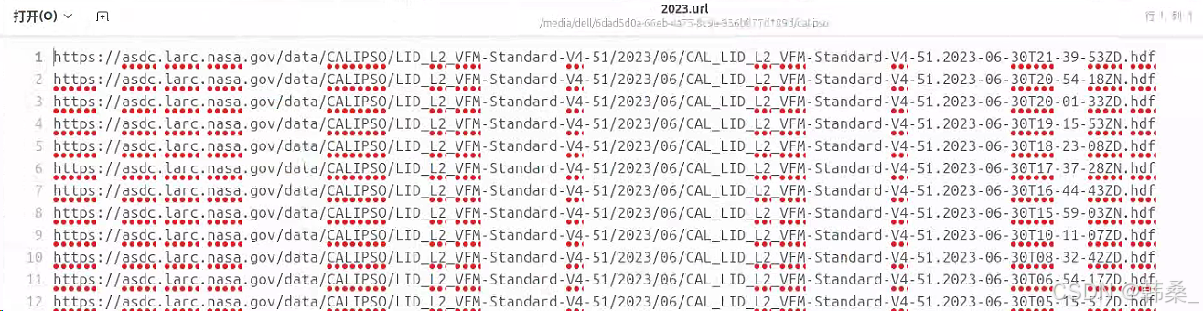
4、点击下载后得到一个包含全部文件的下载路径,重命名为2023.url(或其它)
5、批量下载代码如下,注意:下载速度比较慢
import os
import requests
from http.cookiejar import MozillaCookieJar
from time import sleep
#自己注册的认证信息
USERNAME = " " #这里输入账号
PASSWORD = " " #这里输入密码
# 存储路径需要修改
URL_FILE_PATH = "./2023.url"
SAVE_DIR = "./saved"
CHUNK_SIZE = 1024 * 1024
session = requests.Session()
session.auth = (USERNAME, PASSWORD)
session.headers.update({
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"
})
with open(URL_FILE_PATH, "r") as f:
urls = [line.strip() for line in f.readlines()]
os.makedirs(SAVE_DIR, exist_ok=True)
for url in urls:
file_name = os.path.basename(url)
save_path = os.path.join(SAVE_DIR, file_name)
if os.path.exists(save_path): continue
for attempt in range(5):
try:
with session.get(url, allow_redirects=True, timeout=60) as first_response:
first_response.raise_for_status()
real_download_url = first_response.url
with session.get(real_download_url, stream=True, timeout=60) as response:
response.raise_for_status()
content_type = response.headers.get("Content-Type", "")
if "text/html" in content_type.lower():
raise ValueError(" Server returned HTML instead of data file. Authentication failed!")
total_size = int(response.headers.get("Content-Length", 0))
with open(save_path, "wb") as file:
downloaded_size = 0
for chunk in response.iter_content(chunk_size=CHUNK_SIZE):
if chunk:
file.write(chunk)
downloaded_size += len(chunk)
if total_size > 0 and downloaded_size < total_size:
os.remove(save_path)
sleep(5)
continue
break
except (requests.exceptions.RequestException, ValueError) as e:
sleep(10)
else:
print(f" Failed to download {file_name} after multiple attempts.")

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 2
2 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)