【CVPR025】即插即用-DFormerv2 首创几何自注意力,三大数据集碾压 SOTA,涨点起飞!
本文提出DFormerv2模型,通过几何自注意力机制将深度数据作为几何先验直接引入RGBD语义分割任务。该方法创新性地融合深度和空间几何信息,构建高效编码器,在NYU DepthV2、SUNRGBD和Deliver三大数据集上实现性能突破。实验表明,DFormerv2-L以95.5M参数取得58.4% mIoU,计算量较SOTA方法降低50%以上,展现出优异的性能与效率平衡。该研究为RGBD语义分
1. 【前言】
在计算机视觉领域,语义分割旨在为图像中每个像素分配预定义类别标签,然而仅基于RGB数据的方法在复杂场景(如杂乱室内环境或低光条件)中性能显著下降。随着3D模块化传感器的发展,深度数据因包含场景3D几何信息,被广泛用于提升RGB-D语义分割的鲁棒性与准确性。当前主流方法多采用双编码器架构分别处理RGB和深度数据并进行特征融合,但这类方法忽视了两种模态的固有差异,且存在计算成本高、输入不一致导致表示分布偏移等问题。基于此,本篇论文《DFormerv2: Geometry Self-Attention for RGBD Semantic Segmentation》提出DFormerv2,其核心动机是将深度图直接作为几何先验而非通过神经网络编码,通过几何自注意力机制建模图像块间的几何和空间关系,以更高效地融合RGB和深度信息,在减少计算量的同时提升分割性能,为RGBD语义分割领域提供了新的研究思路与方法。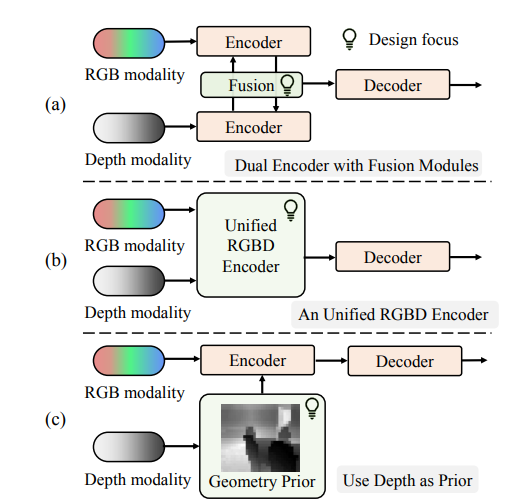
2.【论文基本信息】

- 论文标题:DFormerv2: Geometry Self-Attention for RGBD Semantic Segmentation
- 论文链接:https://arxiv.org/pdf/2504.04701
3.【创新点概述】
3.1 首次将深度信息与空间信息结合作为几何先验引入神经网络
不同于传统方法通过神经网络编码深度信息,本研究首次提出将深度图直接作为几何先验,通过提取深度中的几何线索及图像块间的空间距离,形成几何先验以指导自注意力机制中的权重分配,为RGBD特征表示学习提供了全新思路。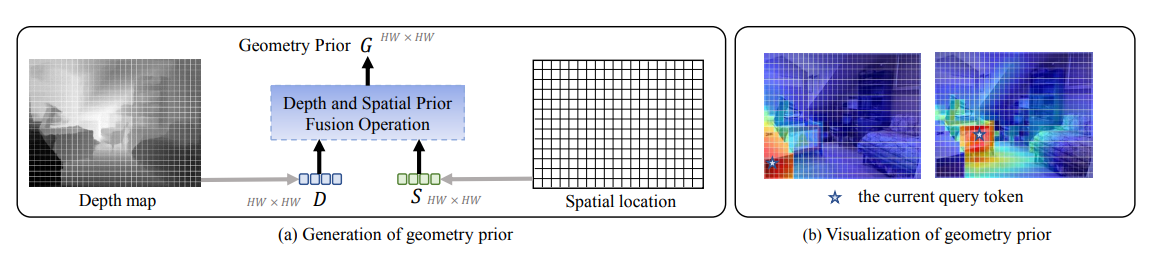
3.2 提出几何自注意力机制(GSA)构建高效RGBD编码器
设计Geometry Self-Attention(GSA),将几何先验融入自注意力计算,通过衰减机制增强近邻区域的注意力权重,抑制无关区域,有效建模对象内和对象间的几何关系。同时采用轴分解操作降低计算复杂度,使模型在参数和计算量上更高效。
3.3 在三大RGBD语义分割数据集上实现性能与效率的双重突破
DFormerv2在NYU DepthV2、SUNRGBD和Deliver数据集上均刷新SOTA,例如DFormerv2-L在NYU DepthV2上以95.5M参数和124.1G Flops实现58.4% mIoU,较同类方法计算成本降低一半以上,展现出最佳的分割性能与计算效率平衡。
4.【整体架构流程】
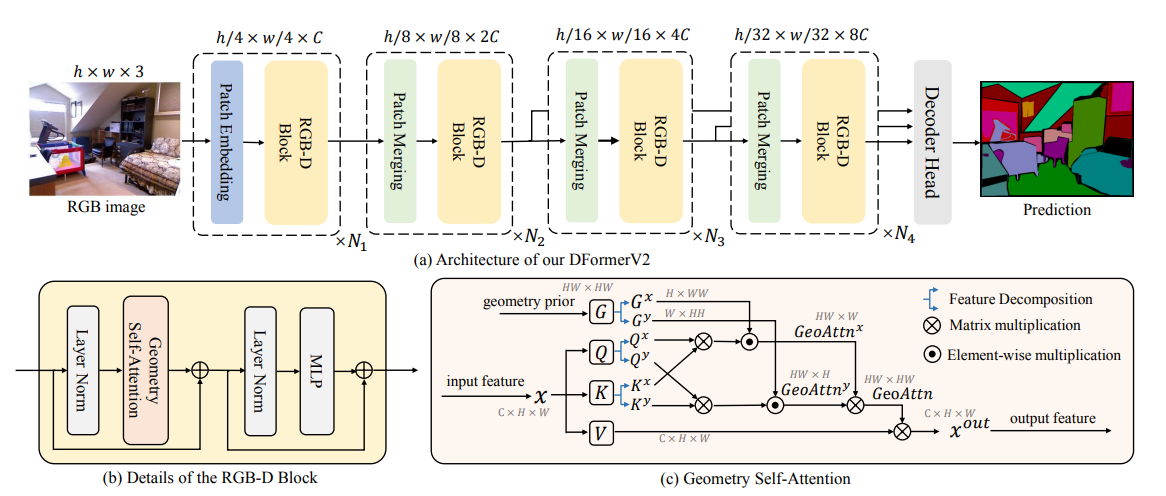
4.1 编码器架构
DFormerv2采用编码器-解码器框架,编码器包含四个阶段,各阶段通过几何自注意力块(Geometry Self-Attention Block)生成多尺度特征:
- 输入处理:RGB图像经stem层(两层3×3卷积,步长2)提取初始特征,深度图通过平均池化生成各尺度几何先验,无需神经网络编码。
- 特征提取阶段:前三个阶段对几何自注意力进行轴分解(沿水平和垂直方向),降低计算复杂度;第四阶段不分解,保留全局几何关系。
- 多尺度特征:四阶段输出特征分辨率依次为输入的1/4、1/8、1/16、1/32,通道数随阶段递增。
4.2 几何自注意力(GSA)机制
- 几何先验生成:
- 深度距离矩阵 D i j , i ′ j ′ = ∣ z i j − z i ′ j ′ ∣ D_{ij,i'j'} = |z_{ij} - z_{i'j'}| Dij,i′j′=∣zij−zi′j′∣,其中 z i j z_{ij} zij为深度块平均深度。
- 空间距离矩阵 S i j , i ′ j ′ = ∣ i − i ′ ∣ + ∣ j − j ′ ∣ S_{ij,i'j'} = |i-i'| + |j-j'| Sij,i′j′=∣i−i′∣+∣j−j′∣,采用曼哈顿距离。
- 融合 D D D和 S S S生成几何先验矩阵 G G G,建模全局3D几何关系。
- 注意力计算:
GeoAttn ( Q , K , V , G ) = ( Softmax ( Q K T ) ⊙ β G ) V \text{GeoAttn}(Q, K, V, G) = (\text{Softmax}(QK^T) \odot \beta^G)V GeoAttn(Q,K,V,G)=(Softmax(QKT)⊙βG)V
其中 β ∈ ( 0 , 1 ) \beta \in (0, 1) β∈(0,1) 为衰减率, β G \beta^G βG 通过元素级乘法将几何先验嵌入注意力图, 增强近邻区域权重。 - 轴分解优化:将自注意力分解为水平和垂直方向计算,降低高分辨率特征的计算复杂度:
G e o A t t n y = ( S o f t m a x ( Q y ( K y ) T ) ⊙ β G y ) G e o A t t n x = ( S o f t m a x ( Q x ( K x ) T ) ⊙ β G x ) G e o A t t n = G e o A t t n y ( G e o A t t n x V ) T \mathrm{GeoAttn}^{y}=\left(\mathrm{Softmax}(Q^{y}(K^{y})^{T})\odot\beta^{G^{y}}\right)\\\mathrm{GeoAttn}^{x}=\left(\mathrm{Softmax}(Q^{x}(K^{x})^{T})\odot\beta^{G^{x}}\right)\\\mathrm{GeoAttn}=\mathrm{GeoAttn}^{y}(\mathrm{GeoAttn}^{x}V)^{T} GeoAttny=(Softmax(Qy(Ky)T)⊙βGy)GeoAttnx=(Softmax(Qx(Kx)T)⊙βGx)GeoAttn=GeoAttny(GeoAttnxV)T
其中 G x 、 G y G^x、G^y Gx、Gy分别为水平和垂直方向的几何先验矩阵。
4.3 解码器与模型变体
- 解码器设计:轻量级解码器接收编码器后三阶段特征,输出语义分割结果。
- 模型变体:基于几何自注意力块配置,设计DFormerv2-S、DFormerv2-B、DFormerv2-L三种尺度,参数规模与性能逐步提升。
4.4 训练与推理流程
- 预训练:在ImageNet-1K上进行RGB-D预训练,采用AdamW优化器,学习率 1 × 1 0 − 3 1 \times 10^{-3} 1×10−3,训练300轮。
- 微调:在NYU DepthV2、SUNRGBD、Deliver数据集上微调,使用交叉熵损失,输入尺寸分别为480×640、480×480、1024×1024,采用多尺度翻转推理。
5.【实验结果】
5.1 主要数据集性能对比
-
NYU DepthV2数据集:
- DFormerv2-L实现58.4% mIoU,参数95.5M,计算量124.1G Flops,超越GeminiFusion-B5(57.7% mIoU,256.1G Flops),计算成本减少超一半。
- DFormerv2-B以53.9M参数、67.2G Flops达到57.7% mIoU,性能与GeminiFusion-B5相当,但计算量仅为其26%。
-
SUNRGBD数据集:
- DFormerv2-L实现53.3% mIoU,参数和计算量分别为95.5M和160.5G Flops,优于GeminiFusion-B5的53.3% mIoU(332.4G Flops)。
- DFormerv2-B以52.8% mIoU、86.9G Flops,超越DFormer-L的52.5% mIoU(84.5G Flops)。

-
Deliver数据集:
- DFormerv2-L以67.1% mIoU、114.5G Flops刷新SOTA,较GeminiFusion-B5(66.9% mIoU,218.4G Flops)性能提升0.2%,计算量降低47%。
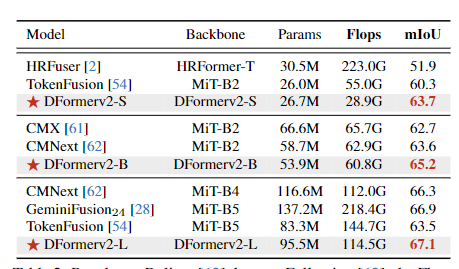
- DFormerv2-L以67.1% mIoU、114.5G Flops刷新SOTA,较GeminiFusion-B5(66.9% mIoU,218.4G Flops)性能提升0.2%,计算量降低47%。
5.2 计算效率与模型规模分析
-
参数与计算量对比:
- 在相同性能下,DFormerv2参数和Flops显著低于同类方法。例如,DFormerv2-B(57.7% mIoU)参数仅为GeminiFusion-B5的39.3%,计算量为26.2%。
- 小模型DFormerv2-S(26.7M参数)在NYU DepthV2实现56.0% mIoU,优于DFormer-Small(18.7M参数,53.6% mIoU)。

-
推理延迟:
5.3 消融实验结果
-
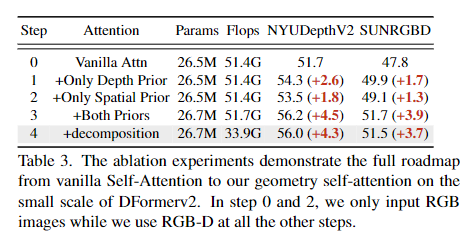
几何先验有效性:
- 仅深度先验使NYU DepthV2 mIoU提升2.6%,仅空间先验提升1.8%,融合两者提升4.5%。
- 轴分解操作在保持性能的同时,将计算量从51.7G降至33.9G。
-
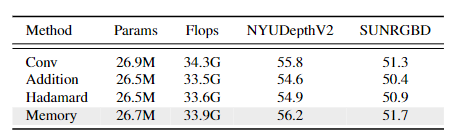
融合操作与衰减率:
-
记忆权重融合(Memory)较卷积(Conv)、加法(Addition)等操作,使NYU DepthV2 mIoU提升1.4%。
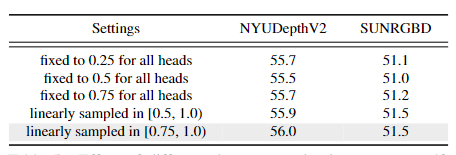
-
衰减率β在[0.75, 1.0)区间线性采样时,模型性能最优(56.0% mIoU)。

-
5.4 可视化与模态分析
-
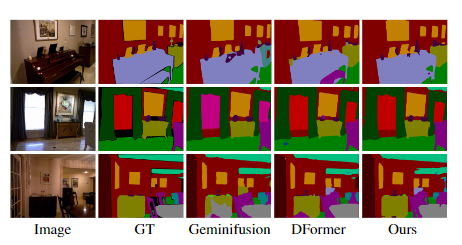
几何先验可视化:
- 几何先验可准确捕捉物体间空间关系(如椅子在桌子下方),帮助模型区分语义对象。
- 引入先验后,特征图对物体细节(如边缘、轮廓)的捕捉能力显著提升。

-
RGB与深度模态贡献:
- 深度模态主要提升分割精度(MAE从0.054降至0.048),对分类精度提升有限(Top-1 Acc从83.1%升至83.4%)。

6.【论文总结展望】
总结
DFormerv2通过将深度图直接作为几何先验引入自注意力机制,构建了几何自注意力(GSA),实现了RGBD语义分割中深度信息的高效利用。该方法无需神经网络显式编码深度,而是通过融合深度与空间距离生成几何先验矩阵,指导注意力权重分配,同时采用轴分解优化计算复杂度。实验表明,DFormerv2在NYU DepthV2、SUNRGBD和Deliver数据集上刷新SOTA,例如以95.5M参数实现58.4% mIoU,较同类方法计算成本降低超一半,首次实现了深度几何先验与视觉特征的深度耦合。
展望
未来可探索动态几何先验生成,如结合场景理解动态调整深度与空间距离的融合权重,或引入时序信息拓展至视频RGBD任务。此外,可尝试将几何先验机制迁移至3D目标检测、SLAM等跨模态任务,探索其在更复杂场景中的泛化能力。同时,进一步优化模型架构以适配边缘设备,推动RGBD技术在实时交互系统中的应用落地。
7.【附录 / 扩展资源】
- 论文链接:https://arxiv.org/pdf/2504.04701
- 代码链接:https://github.com/VCIP-RGBD/DFormer
- 更多模块解析请关注后续更新!

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 16
16 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

{kind=link}
所有评论(0)