深度学习模型部署(七)TensorRT工作流and入门demo
探讨了TensorRT的工作流,并给出了一个demo
·
TensorRT工作流程
官方给出的步骤: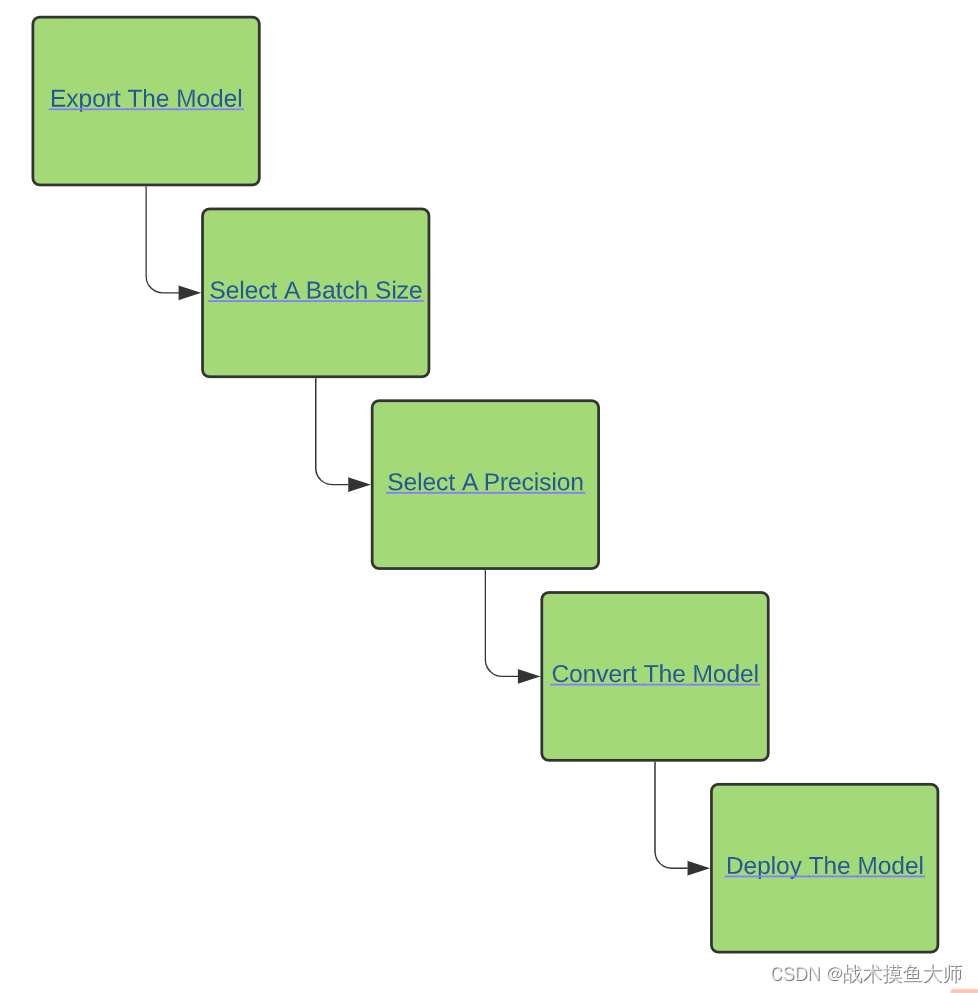
总结下来可以分为两大部分:
- 模型生成:将onnx经过一系列优化,生成tensorrt的engine模型
- 选择batchsize,选择精度precision,模型转换
- 创建logger
- 创建builder,用于构建模型
- 创建builder_config,配置内存池大小之类的
- 创建network,选择batch支持模式,分为显式和隐式两种,不过隐式batch在TensorRT10以后被弃用了
- 解析onnx模型文件生成engine,可以使用官方提供的onnxparser,也可以对着模型一层一层自己手搓
- 模型推理:使用python或者C++进行推理
- 构建runtime,运行时环境
- 构建模型,加载engine模型
- 构建上下文context,每个engine可以对应多个context,以实现多个推理任务复用一个engine
- 设定输入输出,根据输入输出名字绑定输入输出缓存区
- 进行推理
入门Demo
生成engine
生成trt模型:
trtexec --onnx=yolov5s.onnx --saveEngine=yolov5s.trt
# trtexec是TensorRT自带的工具,如果运行显示is no command,把TensorRT安装路径下的bin文件夹加入到path中然后source一下就行了。
然后就坐等输出模型,我们可以根据log信息看一下tensorRT都干了什么:
=== Model Options ===
=== Build Options ===
Precision: FP32
=== System Options ===
=== Inference Options ===
=== Reporting Options ===
# 这几部分是一些选项设置,不用看,目前只需要看精度这一项
=== Device Information ===
# 设备信息
[TRT] CUDA lazy loading is not enabled.
# 这里提到了CUDA lazy loading,这个是CUDA11.8新增的延时加载功能。
# 初始化时不加载kernel,只有用相应的kernel才会加载,是CUDA层面的特性。
# 这个特性会导致第一次推理比较慢,因为第一次推理要加载用到的kernel函数
# 我们后面会先更几篇番外初步速成一下cuda,后面用到cuda的地方会很多
Start parsing network model.
[03/11/2024-22:37:43] [I] [TRT] ----------------------------------------------------------------
[03/11/2024-22:37:43] [I] [TRT] Input filename: yolov5s.onnx
[03/11/2024-22:37:43] [I] [TRT] ONNX IR version: 0.0.8
[03/11/2024-22:37:43] [I] [TRT] Opset version: 17
[03/11/2024-22:37:43] [I] [TRT] Producer name: pytorch
[03/11/2024-22:37:43] [I] [TRT] Producer version: 2.2.1
[03/11/2024-22:37:43] [I] [TRT] Domain:
[03/11/2024-22:37:43] [I] [TRT] Model version: 0
[03/11/2024-22:37:43] [I] [TRT] Doc string:
[03/11/2024-22:37:43] [I] [TRT] ----------------------------------------------------------------
# 解析模型
[TRT] onnx2trt_utils.cpp:374: Your ONNX model has been generated with INT64 weights, while TensorRT does not natively support INT64. Attempting to cast down to INT32.
# 提醒我们的模型时INT64的,会被压缩到INT32
[TRT] Graph optimization time: 0.021841 seconds.
# 进行图优化
[TRT] [GraphReduction] The approximate region cut reduction algorithm is called.
# 进行图简化/图规约
Using random values for input images
[03/11/2024-22:39:14] [I] Input binding for images with dimensions 1x3x640x640 is created.
[03/11/2024-22:39:14] [I] Output binding for output0 with dimensions 1x25200x85 is created.
[03/11/2024-22:39:14] [I] Starting inference
# 会进行一次推理,tracing数据流过的算子以及时间
也可以使用C++生成模型:
先写一个logger
enum class LoggLevel{
kINTERNAL_ERROR = 0,
//! An application error has occurred.
kERROR = 1,
//! An application error has been discovered, but TensorRT has recovered or fallen back to a default.
kWARNING = 2,
//! Informational messages with instructional information.
kINFO = 3,
//! Verbose messages with debugging information.
kVERBOSE = 4,
};
class Logger : public nvinfer1::ILogger {
public:
Logger(LoggLevel severity) : __severity(severity){};
void log(Severity severity, const char* msg) noexcept override {
// suppress info-level messages
if((int)severity < (int)__severity){
std::cout << msg << std::endl;
}
}
private:
LoggLevel __severity;
};
再写具体的生成engine
#include <NvInfer.h>
#include <cuda.h>
#include <cuda_runtime_api.h>
#include <NvOnnxParser.h>
#include <iostream>
#include <fstream>
#include "trt_helper.hpp"
nvinfer1::IHostMemory* build_engine(std::string onnx_path) {
Logger logger(LoggLevel::kINFO);
auto builder = nvinfer1::createInferBuilder(logger); //创建builder
uint32_t flag = 1U << static_cast<uint32_t>(
nvinfer1::NetworkDefinitionCreationFlag::kEXPLICIT_BATCH);
auto network = builder->createNetworkV2(flag); //创建network
//创建onnx parser,用于解析onnx模型架构
auto parser = nvonnxparser::createParser(*network, logger);
parser->parseFromFile(onnx_path.c_str(), static_cast<int>(nvinfer1::ILogger::Severity::kWARNING));
for(int32_t i=0;i<parser->getNbErrors();++i){
std::cout << parser->getError(i)->desc() << std::endl;
}
//创建config,用于定义一系列生成engine相关的设置,例如最大显存占用,浮点精度等
auto config = builder->createBuilderConfig();
size_t free, total;
cuMemGetInfo(&free,&total);
std::cout << "GPU Memory total[MB]:" << (total>>20) << "free[MB] :" << (free >> 20) << std::endl;
config->setMemoryPoolLimit(nvinfer1::MemoryPoolType::kWORKSPACE, free >> 1);
nvinfer1::IHostMemory* serial_model = builder->buildSerializedNetwork(*network, *config);
//保存engine文件
onnx_path.erase(onnx_path.size()-4);
std::ofstream file_ptr(onnx_path+"engine",std::ios::binary);
if (!file_ptr) {
std::cerr << "could not open plan output file" << std::endl;
return nullptr;
}
file_ptr.write(reinterpret_cast<const char*>(serial_model->data()),serial_model->size());
std::cout << "Engine save successfuly,path:" << onnx_path << "engine" << std::endl;
// 输出模型基本信息
std::cout << "Engine size: " << serial_model->size() << std::endl;
std::cout << "Engine input name: " << network->getInput(0)->getName() << std::endl;
auto dims = network->getInput(0)->getDimensions();
std::cout << "Engine input size: " << dims.nbDims << std::endl;
for(int32_t i=0;i<dims.nbDims;++i){
std::cout << dims.d[i] << " ";
}
std::cout << std::endl;
std::cout << "Engine output name: " << network->getOutput(0)->getName() << std::endl;
std::cout << "Engine output size: " << network->getOutput(0)->getDimensions().d[1] << std::endl;
delete parser;
delete serial_model;
delete config;
delete network;
delete builder;
// 返回序列化模型
return serial_model;
}
部署
得到模型后开始进行部署:
可以使用python,也可以使用C++。
python版
import tensorrt as trt
import numpy as np
import pycuda.driver as cuda
import pycuda.autoinit
N_CLASSES = 80 # yolov5 class label number
BATCH_SIZE=1
PRECISION= np.float32
dummy_input_batch = np.zeros((BATCH_SIZE,3,640,640),dtype=PRECISION)
f = open("yolov5s.trt", "rb")
runtime = trt.Runtime(trt.Logger(trt.Logger.WARNING))
engine = runtime.deserialize_cuda_engine(f.read())
context = engine.create_execution_context()
output = np.empty(N_CLASSES, dtype = PRECISION) # Need to set both input and output precisions to FP16 to fully enable FP16
d_input = cuda.mem_alloc(1 * dummy_input_batch.nbytes)
d_output = cuda.mem_alloc(1 * output.nbytes)
bindings = [int(d_input), int(d_output)]
stream = cuda.Stream()
def predict(batch): # result gets copied into output
# Transfer input data to device
cuda.memcpy_htod_async(d_input, batch, stream)
# Execute model
context.execute_async_v2(bindings, stream.handle, None)
# Transfer predictions back
cuda.memcpy_dtoh_async(output, d_output, stream)
# Syncronize threads
stream.synchronize()
return output
pred = predict(dummy_input_batch)
print(pred.shape)
C++版:
#include <NvInfer.h>
#include <cuda.h>
#include <cuda_runtime_api.h>
#include <NvInferRuntime.h>
#include <NvOnnxParser.h>
#include <iostream>
#include <numeric>
#include "trt_helper.hpp"
#include "build_engine.hpp"
int main() {
Logger logger(LoggLevel::kINFO);
nvinfer1::IHostMemory* serial_model=nullptr;
std::ifstream file("../yolov5s.engine", std::ios::binary);
if(!file){
serial_model = build_engine("../yolov5s.onnx");
}
char* trtModelStream = NULL; // 定义一个字符指针,用于读取engine文件数据
int size = 0; // 存储二进制文件字符的数量
if (file.good()) {
file.seekg(0, file.end); //将文件指针移动到文件末尾
size = file.tellg(); //获取当前文件指针的位置,即文件的大小
file.seekg(0, file.beg); //文件指针移回文件开始处
trtModelStream = new char[size]; //分配足够的内存储存文件内容
assert(trtModelStream); //检查内存是否分配成功
file.read(trtModelStream, size); //读取文件信息,并存储在trtModelStream
file.close(); //关闭文件
}
auto runtime = nvinfer1::createInferRuntime(logger);
std::cout << "runtime create successfully" <<std::endl;
auto engine_rt = runtime->deserializeCudaEngine(trtModelStream, size);
std::cout<< "deserialize engine successfully"<<std::endl;
auto context = engine_rt->createExecutionContext();
// 配置输入输出对应的buffer,理论上这里应该搞一个字典或者map,每个输入输出的name对应一个buffer指针
// demo嘛,粗糙点也无所谓
int num=engine_rt->getNbIOTensors();
std::cout <<"nums:"<<num<<std::endl;
std::vector<void*> buffers(num);
for(int i=0;i<num;++i){
auto name = engine_rt->getIOTensorName(i);
// 查询维度信息,各维度相乘,得到该tensor的数据量
auto dims = engine_rt->getTensorShape(name);
size_t size = std::accumulate(dims.d,dims.d+dims.nbDims,1,std::multiplies<int>());
//这里理论上应该根据tensor的数据类型所占内存大小,乘以数据数量,再进行分配,demo就直接默认float了
cudaMalloc(&buffers[i],size*sizeof(float));
std::cout << "malloc size:" << size <<std::endl;
}
void* inputBuffer = buffers[0];
void* outputBuffer = buffers[1];
// 这里的输入也是要求可以通过tensor名称查询对应buffer地址,
// 不过直接这么输入好像也没报错,那就不管他了,后续报错再改
context->executeV2(buffers.data());
// Clean up
for (void* buffer : buffers) {
cudaFree(buffer);
}
delete serial_model;
delete context;
delete engine_rt;
delete runtime;
return 0;
}
今天blog的主题是跑通tensorRT的整个流程,yolov5的后处理比较麻烦,这不是今天blog的主题,所以没有写,后面有空补上。
如果感觉有帮助,点赞收藏+关注!thanks!

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 16
16 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)