Langchain4j — 0基础使用Java代码构建自己的聊天机器人
🌟 本篇内容主要从0开始一步一步搭建自己的机器人! 🤖✨📚 文档来源:【小智医疗:Java大模型应用项目全流程实战,企业级Java项目LangChain4J项目,LangChain+向量数据库+RAG】🔥
🌟 本篇内容主要从0开始一步一步搭建自己的机器人! 🤖✨
📚 文档来源:
【小智医疗:Java大模型应用项目全流程实战,企业级Java项目LangChain4J项目,LangChain+向量数据库+RAG】🔥
👉 点击观看视频教程 🎥💾 技术栈亮点:
✅ MongoDB 🏗️ —— 持久化存储文档,数据管理更高效!
✅ Pinecone 🌲 —— 集成向量数据库,让AI检索更智能!🤖 @AiService
🧠 聊天记忆(Chat Memory)
✏️ 提示词(Prompt)
🔗 函数调用(Function Calling)
📚 检索增强生成(RAG)
📂 文档处理三剑客
- 文档加载器 📥 - 支持多种格式文件加载
- 文档解析器 🔍 - 精准提取文本内容
- 文档分割器 ✂️ - 智能切分长文本
🚀 一起动手,打造你的专属机器人吧! 💡👨💻
目录
一.什么是Langchain4j?
LangChain4j 是一个基于 Java 的轻量级开源库,旨在帮助开发者轻松集成大语言模型(LLM,如 OpenAI、Anthropic、阿里云 Qwen 等)到 Java 应用程序中。它借鉴了 Python 生态中流行的 LangChain 框架的设计理念,但专为 Java/Kotlin 开发者优化,提供更符合 Java 习惯的 API。
官网地址:LangChain4j | LangChain4j
主要功能:
-
与大型语言模型和向量数据库的便捷交互:通过统一的应用程序编程接口( API ),可以轻松访问所有主要的商业和开源大型语言模型以及向量数据库,使你能够构建聊天机器人、智能助手等应用。
-
专为 Java 打造:借助 Spring Boot 集成,能够将大模型集成到 ava 应用程序中。大型语言模型与 Java 之间实现了双向集成:你可以从 Java 中调用大型语言模型,同时也允许大型语言模型反过来调用你的 Java 代码
-
智能代理、工具、检索增强生成( RAG):为常见的大语言模型操作提供了广泛的工具,涵盖从底层的提示词模板创建、聊天记忆管理和输出解析,到智能代理和检索增强生成等高级模式。
二.使用Langchain4j实现与大模型对话:
1.创建SpringBoot项目:
首先引入依赖:
<properties>
<maven.compiler.source>17</maven.compiler.source>
<maven.compiler.target>17</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<spring-boot.version>3.2.6</spring-boot.version>
<knife4j.version>4.3.0</knife4j.version>
<langchain4j.version>1.0.0-beta3</langchain4j.version>
<mybatis-plus.version>3.5.11</mybatis-plus.version>
</properties>
<dependencies>
<!-- web应用程序核心依赖 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- 编写和运行测试用例 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<!-- 前后端分离中的后端接口测试工具 -->
<dependency>
<groupId>com.github.xiaoymin</groupId>
<artifactId>knife4j-openapi3-jakarta-spring-boot-starter</artifactId>
<version>${knife4j.version}</version>
</dependency>
<!-- Mysql Connector -->
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
</dependency>
<!--mybatis-plus 持久层-->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-spring-boot3-starter</artifactId>
<version>${mybatis-plus.version}</version>
</dependency>
</dependencies>
<dependencyManagement>
<dependencies>
<!--引入SpringBoot依赖管理清单-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-dependencies</artifactId>
<version>${spring-boot.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>之后导入 application.yml 配置文件:
spring:
datasource:
url: jdbc:mysql://localhost:3306/guiguxiaozhi?useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai&useSSL=false
username: root
password: 1234
driver-class-name: com.mysql.cj.jdbc.Driver
application:
name: AIModel
mybatis-plus:
configuration:
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
server:
port: 80802.接入大模型:
(1)LangChain4j 库结构:
- langchain4j-core 模块,它定义了核心抽象概念(如聊天语言模型和嵌入存储)及其 API。
- 主 langchain4j 模块,包含有用的工具,如文档加载器、聊天记忆实现,以及诸如人工智能服务等高层功能。
- 大量的 langchain4j-{集成} 模块,每个模块都将各种大语言模型提供商和嵌入存储集成到 LangChain4j 中。你可以独立使用 langchain4j-{集成} 模块。如需更多功能,只需导入主 langchain4j 依赖项即可。
添加Langchain4j依赖:
<properties>
<langchain4j.version>1.0.0-beta3</langchain4j.version>
</properties>
<dependencies>
<!-- 基于open-ai的langchain4j接口:ChatGPT、deepseek都是open-ai标准下的大模型 -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-open-ai</artifactId>
</dependency>
</dependencies>
<dependencyManagement>
<dependencies>
<!--引入langchain4j依赖管理清单-->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-bom</artifactId>
<version>${langchain4j.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>随后创建测试用例:
@SpringBootTest
public class LLMTest {
/**
* gpt-4o-mini语言模型接入测试
*/
@Test
public void testGPTDemo() {
//初始化模型
OpenAiChatModel model = OpenAiChatModel.builder()
//LangChain4j提供的代理服务器,该代理服务器会将演示密钥替换成真实密钥, 再将请求转发给OpenAI API
.baseUrl("http://langchain4j.dev/demo/openai/v1") //设置模型api地址(如果apiKey="demo",则可省略baseUrl的配置)
.apiKey("demo") //设置模型apiKey
.modelName("gpt-4o-mini") //设置模型名称
.build();
//向模型提问
String answer = model.chat("你好");
//输出结果
System.out.println(answer);
}
}(2)获取 API_KEY并接入大模型:
LangChain4j支持接入的大模型:https://docs.langchain4j.dev/integrations/language-models/
【1】获取Deepseek的API_KEY并使用:
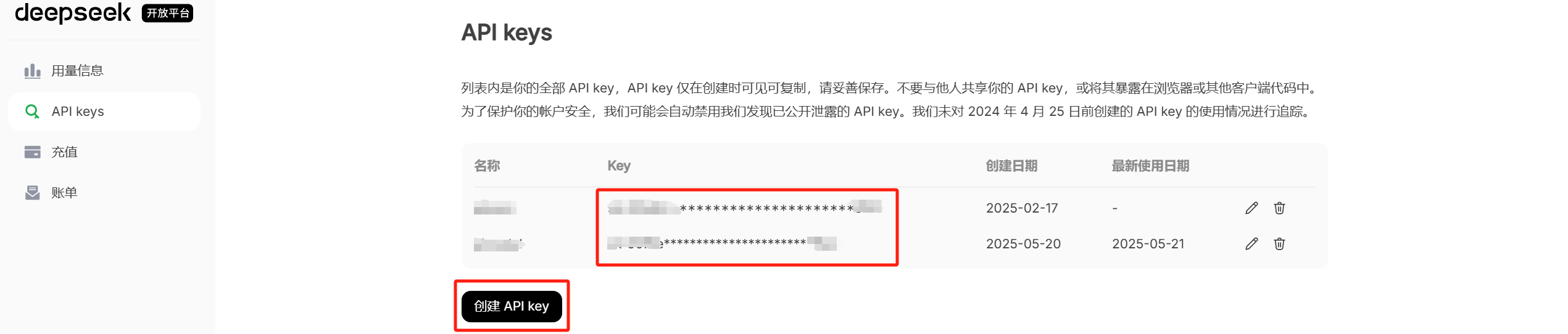
随后替换API_KEY。
为了更方便的使用,我们可以将所需的参数(如apiKey、modelName、baseUrl等)写到application.yml中:(这里是以Deepseek为例,可以将API_KEY保存在环境变量中)
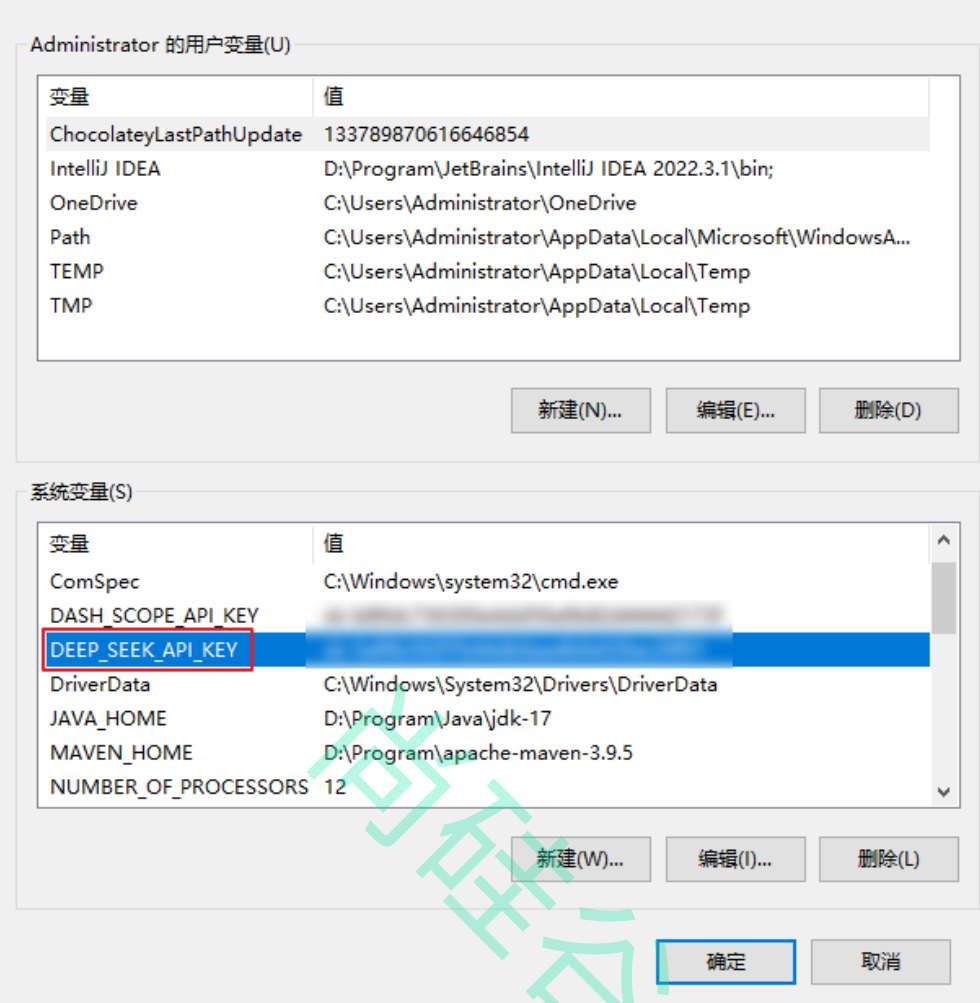
注意!!!配置完环境变量需要重启idea才能生效。
langchain4j:
open-ai:
chat-model:
model-name: deepseek-reasoner
log-requests: true
log-responses: true
base-url: https://api.deepseek.com
api-key: ************************ # 直接使用
# api-key: ${DEEP_SEEK_API_KEY} # 保存在环境变量
#启用日志debug级别
logging:
level:
root: debug测试用例:
/**
* 整合SpringBoot
*/
@Autowired
private OpenAiChatModel openAiChatModel;
@Test
public void testSpringBoot() {
//向模型提问
String answer = openAiChatModel.chat("你好");
//输出结果
System.out.println(answer);
}【2】ollama本地部署并使用:
Ollama 是一个本地部署大模型的工具。使用 Ollama 进行本地部署有以下多方面的原因:
①数据隐私与安全:对于金融、医疗、法律等涉及大量敏感数据的行业,数据安全至关重要。
②离线可用性:在网络不稳定或无法联网的环境中,本地部署的 Ollama 模型仍可正常运行。
③降低成本:云服务通常按使用量收费,长期使用下来费用较高。而 Ollama 本地部署,只需一次性投入硬件成本,对于需要频繁使用大语言模型且对成本敏感的用户或企业来说,能有效节约成本。
④部署流程简单:只需通过简单的命令 “ollama run < 模型名>”,就可以自动下载并运行所需的模型。
⑤灵活扩展与定制:可对模型微调,以适配垂直领域需求。
详细教程可见下面博客:Deepseek本地部署并搭建自己的知识库
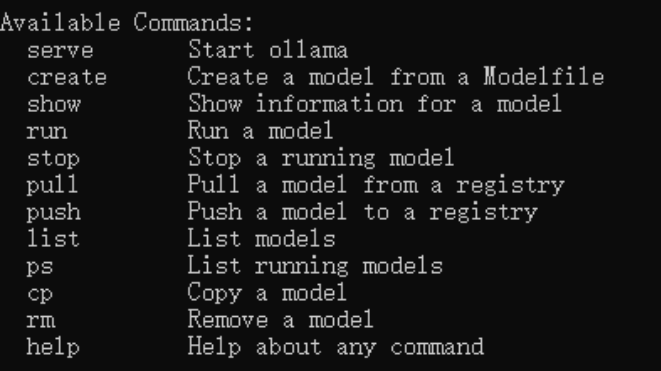
(3)执行命令: ollama run deepseek-r1:1.5 运行大模型。如果是第一次运行则会先下载大模型
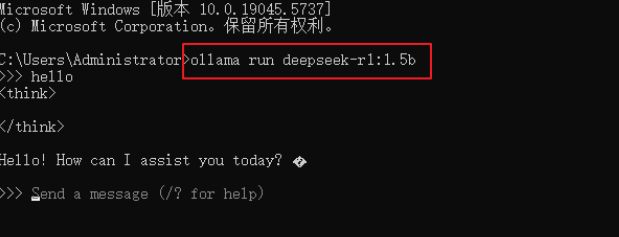
常用命令:
随后引入依赖:
<!-- 接入ollama -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-ollama-spring-boot-starter</artifactId>
</dependency>测试用例:
/**
* ollama接入
*/
@Autowired
private OllamaChatModel ollamaChatModel;
@Test
public void testOllama() {
//向模型提问
String answer = ollamaChatModel.chat("你好");
//输出结果
System.out.println(answer);
}【3】接入阿里百炼大模型:
在模型广场,我们可以看到各式各样的模型。
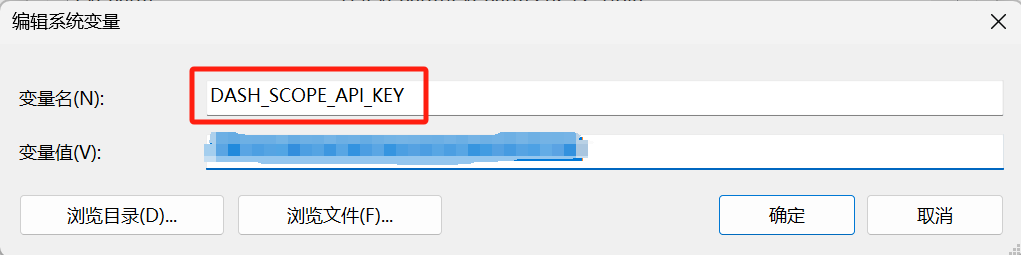
先申请一个API_KEY(不会可以去查看阿里详细教程):

随后同样将这个API_KEY保存在环境变量中:
随后引入阿里百炼依赖:
<dependencies>
<!-- 接入阿里云百炼平台 -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-community-dashscope-spring-boot-starter</artifactId>
</dependency>
</dependencies>
<dependencyManagement>
<dependencies>
<!--引入百炼依赖管理清单-->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-community-bom</artifactId>
<version>${langchain4j.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>随后我们配置阿里百炼大模型的参数:
langchain4j:
# 阿里百炼平台
community:
dashscope:
chat-model:
api-key: {DASH_SCOPE_API_KEY}
model-name: qwen-max随后测试QwenChat:
@Autowired
private QwenChatModel qwenChatModel;
@Test
public void testDashScopeQwen() {
//向模型提问
String answer = qwenChatModel.chat("你好");
//输出结果
System.out.println(answer);
}有关Langchain4j使用DashScope(Qwen)可访问下面地址:
https://docs.langchain4j.dev/integrations/language-models/dashscope/#plain-java
当然,我们也可以在阿里百炼上集成第三方大模型(如Deepseek):
langchain4j:
open-ai:
chat-model:
model-name: deepseek-v3
base-url: https://dashscope.aliyuncs.com/compatible-mode/v1
api-key: ${DASH_SCOPE_API_KEY}
# 温度系数:取值范围通常在 0 到 1 之间。值越高,模型的输出越随机、富有创造性;
# 值越低,输出越确定、保守。这里设置为 0.9,意味着模型会有一定的随机性,生成的回复可能会比较多样化。
temperature: 0.9三.AIService:
1.什么是AIService?
AIService(AI 服务)通常指封装了人工智能能力的 API 或 SDK,使开发者能够轻松集成 AI 功能(如自然语言处理、计算机视觉、语音识别等)到自己的应用程序中。
在 LangChain4j 等框架中,AIService 是一个高级抽象接口,用于简化 AI 模型的调用和管理。
它与Chain比较类似。
链的概念源自 Python 中的 LangChain。其理念是针对每个常见的用例都设置一条链,比如聊天机器人、
检索增强生成(RAG)等。链将多个底层组件组合起来,并协调它们之间的交互。链存在的主要问题是不
灵活,我们不进行深入的研究。在LangChain4j中我们使用AIService完成复杂操作,底层组件将由AIService进行组装。
2.创建AIService:
(1)引入依赖:
<!--langchain4j高级功能-->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-spring-boot-starter</artifactId>
</dependency>(2)创建接口:
package cn.eleven.com.aimodel.assistant;
public interface Assistant {
String chat(String userMessage);
}
(3)测试用例:
@SpringBootTest
public class AIServiceTest {
@Autowired
private QwenChatModel qwenChatModel;
@Test
public void testChat() {
//创建AIService
Assistant assistant = AiServices.create(Assistant.class, qwenChatModel);
//调用service的接口
String answer = assistant.chat("Hello");
System.out.println(answer);
}
}3.@AiService:
我们可以使用 @AiService 注解来简化 LangChain4j 的集成。
package cn.eleven.com.aimodel.assistant;
import dev.langchain4j.service.spring.AiService;
import static dev.langchain4j.service.spring.AiServiceWiringMode.EXPLICIT;
// 因为在配置文件中同时配置了多个大语言模型,所以需要在这里明确指定(EXPLICIT)模型的beanName(qwenChatModel)
@AiService(wiringMode = EXPLICIT, chatModel = "qwenChatModel")
public interface Assistant {
String chat(String userMessage);
}
测试用例中,我们可以直接注入Assistant对象:
@Autowired
private Assistant assistant;
@Test
public void testAssistant() {
String answer = assistant.chat("Hello");
System.out.println(answer);
}工作原理:
AiServices会组装Assistant接口以及其他组件,并使用反射机制创建一个实现Assistant接口的代理对象。
这个代理对象会处理输入和输出的所有转换工作。在这个例子中,chat方法的输入是一个字符串,但是大模型需要一个 UserMessage 对象。所以,代理对象将这个字符串转换为 UserMessage ,并调用聊天语言模型。chat方法的输出类型也是字符串,但是大模型返回的是 AiMessage 对象,代理对象会将其转换为字符串。
简单理解就是:代理对象的作用是输入转换和输出转换。
四.聊天记忆 —— Chat memory:
正常大模型是不具有记忆的,无法联想到上下文,我们可以使用下面例子测试是否有记忆:
@SpringBootTest
public class ChatMemoryTest {
@Autowired
private Assistant assistant;
@Test
public void testChatMemory() {
String answer1 = assistant.chat("我是环环");
System.out.println(answer1);
String answer2 = assistant.chat("我是谁");
System.out.println(answer2);
}
}在 AI 对话系统中,Chat Memory 用于存储和管理多轮对话的上下文,使 AI 能够记住之前的交互内容,从而实现更连贯的对话体验。LangChain4j 提供了多种内存管理方案,适用于不同场景。
使用AIService可以封装多轮对话的复杂性,使聊天记忆功能的实现变得简单:
@Test
public void testChatMemory3() {
// 创建chatMemory
MessageWindowChatMemory chatMemory = MessageWindowChatMemory.withMaxMessages(10);
// 创建AIService
Assistant assistant = AiServices
.builder(Assistant.class)
.chatLanguageModel(qwenChatModel)
.chatMemory(chatMemory)
.build();
// 调用service的接口
String answer1 = assistant.chat("我是环环");
System.out.println(answer1);
String answer2 = assistant.chat("我是谁");
System.out.println(answer2);
}使用@AiService注解实现:
当AIService由多个组件(大模型,聊天记忆等)组成的时候,我们就可以称他为智能体了。
package cn.eleven.com.aimodel.assistant;
import dev.langchain4j.service.spring.AiService;
import static dev.langchain4j.service.spring.AiServiceWiringMode.EXPLICIT;
@AiService(
wiringMode = EXPLICIT,
chatModel = "qwenChatModel",
chatMemory = "chatMemory"
)
public interface MemoryChatAssistant {
String chat(String message);
}随后配置chatMemory并使用@Bean注入Spring来管理:
package cn.eleven.com.aimodel.config;
import dev.langchain4j.memory.ChatMemory;
import dev.langchain4j.memory.chat.MessageWindowChatMemory;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class MemoryChatAssistantConfig {
@Bean
ChatMemory chatMemory() {
// 设置聊天记忆记录的message数量
return MessageWindowChatMemory.withMaxMessages(10);
}
}测试用例:
@Autowired
private MemoryChatAssistant memoryChatAssistant;
@Test
public void testChatMemory4() {
String answer1 = memoryChatAssistant.chat("我是环环");
System.out.println(answer1);
String answer2 = memoryChatAssistant.chat("我是谁");
System.out.println(answer2);
}隔离聊天记忆:
为了实现隔离聊天记忆,我们要使用ChatMemoryProvider。
ChatMemoryProvider 是 LangChain4j 中用于动态管理聊天记忆的核心接口,它负责为每个对话会话(session)创建独立的 ChatMemory 实例。
首先创建记忆隔离对话智能体:
package cn.eleven.com.aimodel.assistant;
import dev.langchain4j.service.MemoryId;
import dev.langchain4j.service.spring.AiService;
import static dev.langchain4j.service.spring.AiServiceWiringMode.EXPLICIT;
@AiService(
wiringMode = EXPLICIT,
chatMemory = "chatMemory",
chatMemoryProvider = "chatMemoryProvider" // 为每个对话会话(Conversation)提供独立的 ChatMemory
)
public interface SeparateChatAssistant {
/**
* 分离聊天记录
* @param memoryId 聊天id
* @param userMessage 用户消息
* @return
*/
String chat(@MemoryId int memoryId, @UserMessage @V("message") String userMessage);
}随后配置 ChatMemoryProvider 并将其注入到Spring中:
package cn.eleven.com.aimodel.config;
import cn.eleven.com.aimodel.store.MongoChatMemoryStore;
import dev.langchain4j.memory.chat.ChatMemoryProvider;
import dev.langchain4j.memory.chat.MessageWindowChatMemory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class SeparateChatAssistantConfig {
@Autowired
private MongoChatMemoryStore chatMemoryStore;
@Bean("chatMemoryProvider")
ChatMemoryProvider chatMemoryProvider() {
return memoryId -> MessageWindowChatMemory.builder()
.id(memoryId)
.maxMessages(10)
// .chatMemoryStore(new InMemoryChatMemoryStore()) // 加入则使用HashMap存储,不加则使用ArrayList存储
.chatMemoryStore(chatMemoryStore)
.build();
}
}测试案例:
@Autowired
private SeparateChatAssistant separateChatAssistant;
@Test
public void testChatMemory5() {
String answer1 = separateChatAssistant.chat(1,"我是环环");
System.out.println(answer1);
String answer2 = separateChatAssistant.chat(1,"我是谁");
System.out.println(answer2);
String answer3 = separateChatAssistant.chat(2,"我是谁");
System.out.println(answer3);
}默认情况下,聊天记忆存储在内存中。如果需要持久化存储,可以实现一个自定义的聊天记忆存储类,以便将聊天消息存储在你选择的任何持久化存储介质中。
持久化存储:
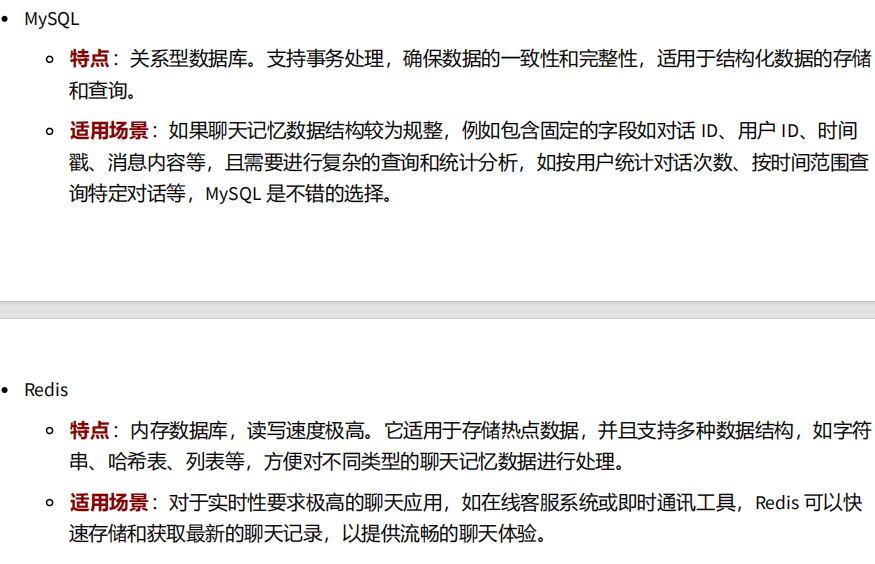

一般针对这样场景下(多样化信息、各种格式的聊天记录),我们一般使用MongoDB。

安装MongoDB:
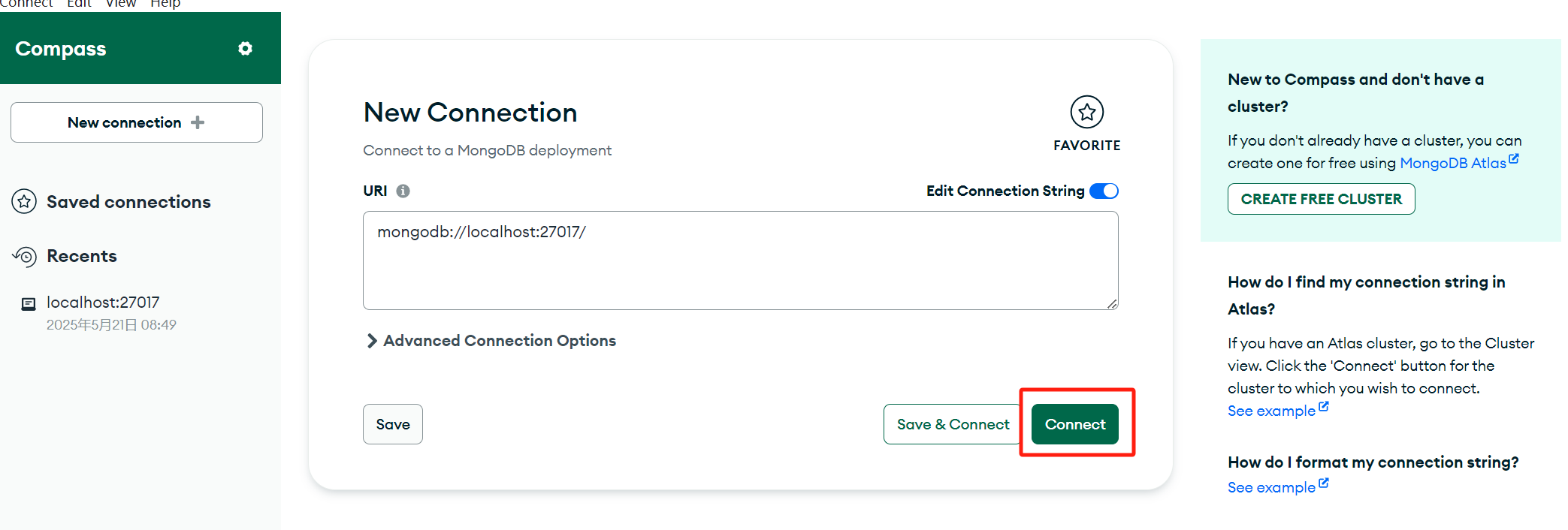
随后点击Connect连接,默认地址 localhost:27017:
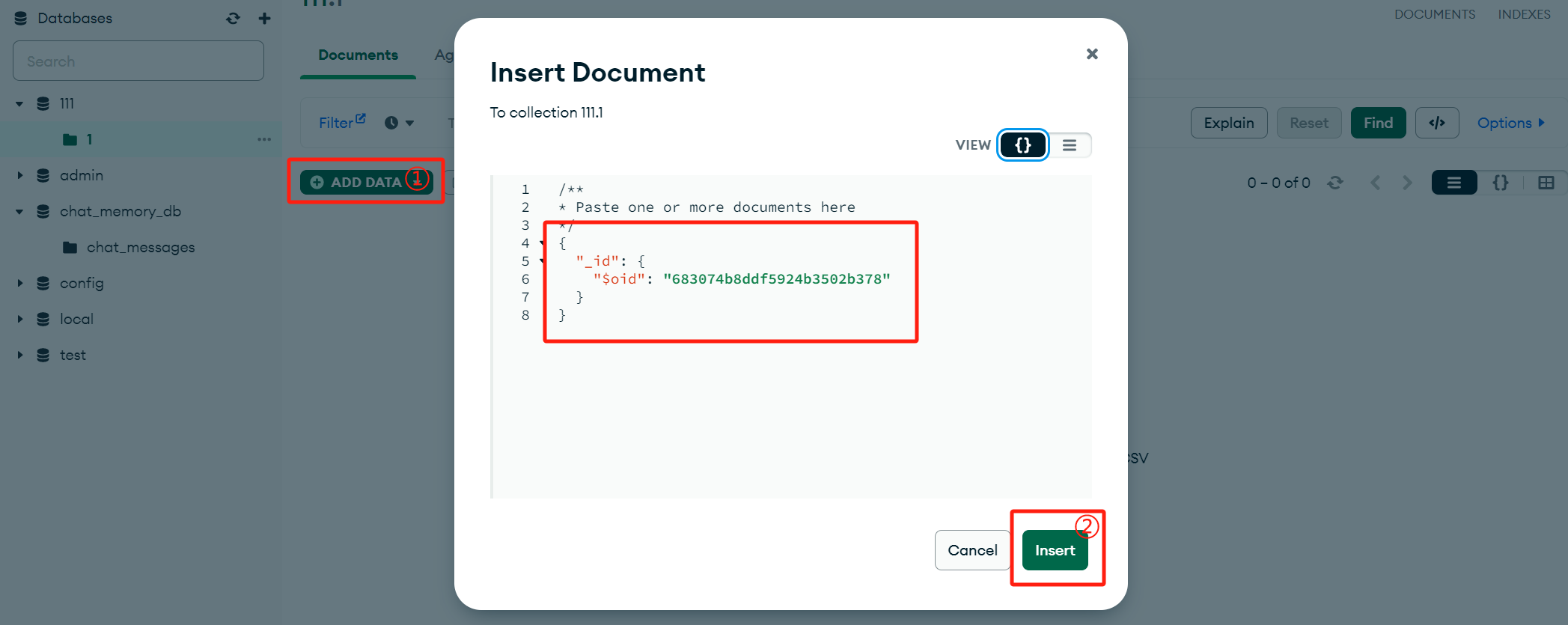
随后创建一个数据库111,并在1集合中存入一个文档:
引入依赖:
<!-- Spring Boot Starter Data MongoDB -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-mongodb</artifactId>
</dependency>随后在application.yml中引入配置:
spring:
data:
mongodb:
uri: mongodb://localhost:27017/chat_memory_db之后创建一个实体类来映射MongoDB中的文档:
package cn.eleven.com.aimodel.bean;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.bson.types.ObjectId;
import org.springframework.data.annotation.Id;
import org.springframework.data.mongodb.core.mapping.Document;
@Data
@AllArgsConstructor
@NoArgsConstructor
@Document("chat_messages") // 自动在数据库下创建集合chat_messages
public class ChatMessages {
// 唯一标识,映射到 MongoDB 文档的 _id 字段
@Id
private ObjectId messageId; // 为了让其自动生成id,使用ObjectId类型
private int memoryId; // 会话唯一标识,确保每个会话的记忆独立存储和检索
private String content; // 存储当前聊天记录列表的json字符串
}创建一个类实现ChatMemoryStore接口:
package cn.eleven.com.aimodel.store;
import cn.eleven.com.aimodel.bean.ChatMessages;
import dev.langchain4j.data.message.ChatMessage;
import dev.langchain4j.data.message.ChatMessageDeserializer;
import dev.langchain4j.data.message.ChatMessageSerializer;
import dev.langchain4j.store.memory.chat.ChatMemoryStore;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.mongodb.core.MongoTemplate;
import org.springframework.data.mongodb.core.query.Criteria;
import org.springframework.data.mongodb.core.query.Query;
import org.springframework.data.mongodb.core.query.Update;
import org.springframework.stereotype.Component;
import java.util.LinkedList;
import java.util.List;
@Component
public class MongoChatMemoryStore implements ChatMemoryStore {
@Autowired
private MongoTemplate mongoTemplate;
@Override
public List<ChatMessage> getMessages(Object memoryId) {
Criteria criteria = Criteria.where("memoryId").is(memoryId);
Query query = new Query(criteria);
ChatMessages chatMessages = mongoTemplate.findOne(query, ChatMessages.class);
if(chatMessages == null) return new LinkedList<>();
return ChatMessageDeserializer.messagesFromJson(chatMessages.getContent());
}
@Override
public void updateMessages(Object memoryId, List<ChatMessage> messages) {
Criteria criteria = Criteria.where("memoryId").is(memoryId);
Query query = new Query(criteria);
Update update = new Update();
update.set("content", ChatMessageSerializer.messagesToJson(messages)); // 将名为 content 的字段值设置新值
// 根据query条件能查询出文档,则修改文档;否则新增文档
mongoTemplate.upsert(query, update, ChatMessages.class);
}
@Override
public void deleteMessages(Object memoryId) {
Criteria criteria = Criteria.where("memoryId").is(memoryId);
Query query = new Query(criteria);
mongoTemplate.remove(query, ChatMessages.class);
}
}在SeparateChatAssistantConfig中,添加MongoChatMemoryStore对象的配置:
package cn.eleven.com.aimodel.config;
import cn.eleven.com.aimodel.store.MongoChatMemoryStore;
import dev.langchain4j.memory.chat.ChatMemoryProvider;
import dev.langchain4j.memory.chat.MessageWindowChatMemory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class SeparateChatAssistantConfig {
// 注入持久化对象
@Autowired
private MongoChatMemoryStore chatMemoryStore;
@Bean("chatMemoryProvider")
ChatMemoryProvider chatMemoryProvider() {
return memoryId -> MessageWindowChatMemory.builder()
.id(memoryId)
.maxMessages(10)
// .chatMemoryStore(new InMemoryChatMemoryStore()) // 加入则使用HashMap存储,不加则使用ArrayList存储
.chatMemoryStore(mongoChatMemoryStore) // 配置持久化对象
.build();
}
}
五.提示词 —— Prompt:
在 LangChain4j 中,@SystemMessage、@UserMessage、@MemoryId 和 @V 是用于控制 AI 对话流程的核心注解。
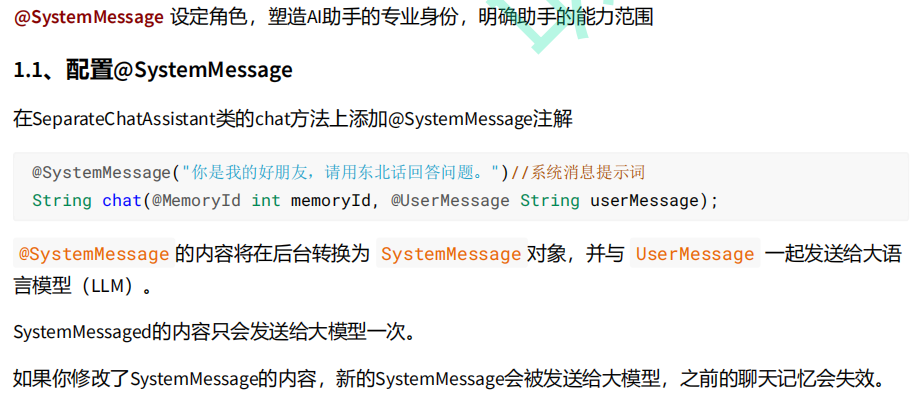

@SystemMessage 注解还可以从资源中加载提示模板:
@SystemMessage(fromResource = "my-prompt-template.txt") String chat(@MemoryId int memoryId, @UserMessage String userMessage);随后在my-prompt-template.txt中写入系统提示:
你是我的好朋友,请用东北话回答问题,回答问题的时候适当添加表情符号。 今天是 {{current_date}}。{{current_date}}表示当前日期。
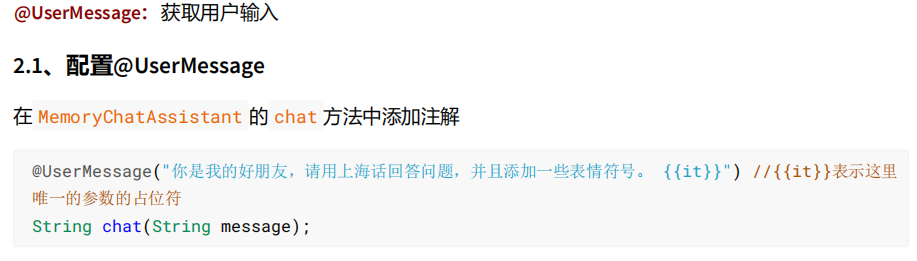

如果有两个或两个以上的参数,我们必须要用 @V 。
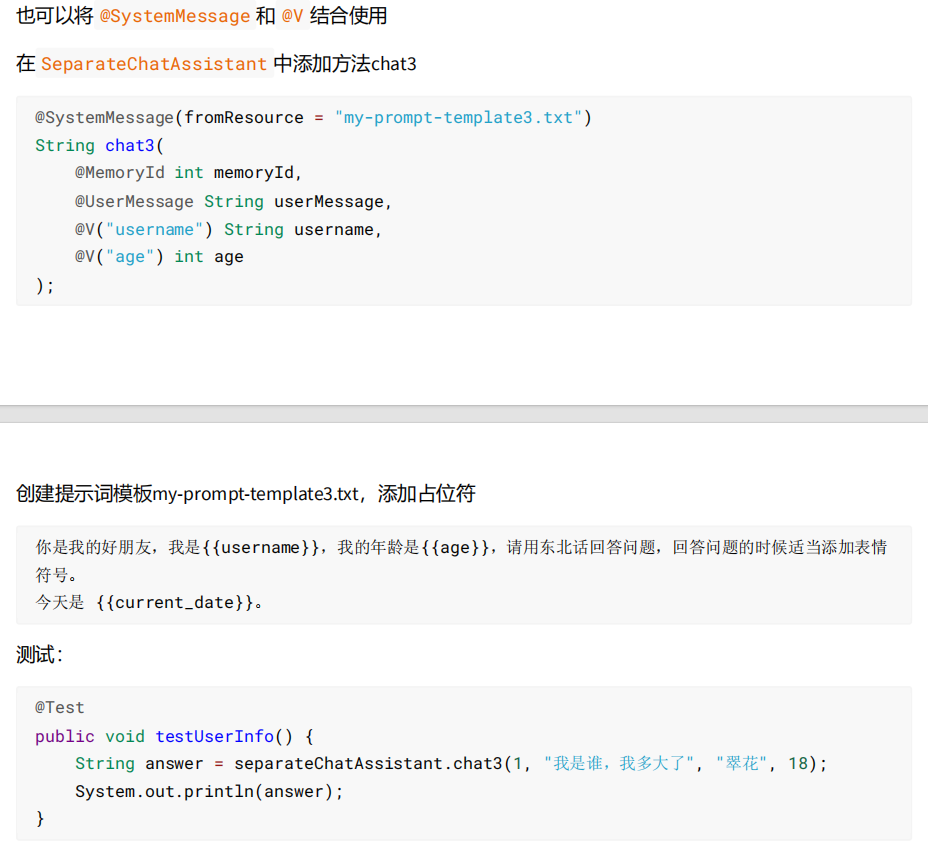
package cn.eleven.com.aimodel.assistant;
import dev.langchain4j.service.MemoryId;
import dev.langchain4j.service.SystemMessage;
import dev.langchain4j.service.UserMessage;
import dev.langchain4j.service.V;
import dev.langchain4j.service.spring.AiService;
import static dev.langchain4j.service.spring.AiServiceWiringMode.EXPLICIT;
@AiService(
wiringMode = EXPLICIT,
chatModel = "qwenChatModel",
// 在SeparateChatAssistantConfig内定义的
chatMemoryProvider = "chatMemoryProvider", // 为每个对话会话(Conversation)提供独立的 ChatMemory
)
public interface SeparateChatAssistant {
/**
* 分离聊天记录
* @param memoryId 聊天id
* @param userMessage 用户消息
* @return
*/
// @SystemMessage("回答问题的字数限制在50字以内,输出格式为 markdown") // 设置提示词
@SystemMessage(fromResource = "prompt-template.txt")
// @UserMessage("你是我的好朋友,请用上海话回答问题,并且添加一些表情符号。 {{it}}") // {{it}}表示这里唯一的参数的占位符,用来替换userMessage
@UserMessage("你是我的好朋友,请用上海话回答问题,并且添加一些表情符号。 {{message}}") // @V注解的使用
String chat(@MemoryId int memoryId, @UserMessage @V("message") String userMessage);
}六.函数调用 —— Function Calling:
Function Calling 函数调用 也叫 Tools 工具。
大语言模型本身并不擅长数学运算。如果应用场景中偶尔会涉及到数学计算,我们可以为他提供
一个 “数学工具”。当我们提出问题时,大语言模型会判断是否使用某个工具。
例如在tools内创建CalculatorTools:
package cn.eleven.com.aimodel.tools;
import dev.langchain4j.agent.tool.P;
import dev.langchain4j.agent.tool.Tool;
import dev.langchain4j.agent.tool.ToolMemoryId;
import dev.langchain4j.service.MemoryId;
import org.springframework.stereotype.Component;
@Component
public class CalculatorTools {
@Tool(name = "加法",value = "将两个数相加")
double sum(
@ToolMemoryId MemoryId memoryId, // 希望在 @Tool 方法中对不同用户进行区分,
@P(value="加数1") double a,
@P(value="加数2") double b
) {
System.out.println("调用加法运算");
return a + b;
}
@Tool(name = "平方根运算")
double squareRoot(double x) {
System.out.println("调用平方根运算");
return Math.sqrt(x);
}
}通过加入name、@P等修饰函数方法,帮助大语言模型更好的理解并正确调用。

随后在SeparateChatAssistant中添加tools属性配置:
package cn.eleven.com.aimodel.assistant;
import dev.langchain4j.service.MemoryId;
import dev.langchain4j.service.SystemMessage;
import dev.langchain4j.service.UserMessage;
import dev.langchain4j.service.V;
import dev.langchain4j.service.spring.AiService;
import static dev.langchain4j.service.spring.AiServiceWiringMode.EXPLICIT;
@AiService(
wiringMode = EXPLICIT,
chatModel = "qwenChatModel",
chatMemoryProvider = "chatMemoryProvider",
tools = "calculatorTools" // 配置tools工具
)
public interface SeparateChatAssistant {
/**
* 分离聊天记录
* @param memoryId 聊天id
* @param userMessage 用户消息
* @return
*/
@SystemMessage("回答问题的字数限制在50字以内,输出格式为 markdown") // 设置提示词
String chat(@MemoryId int memoryId, @UserMessage @V("message") String userMessage);
}测试案例:
@SpringBootTest
public class ToolsTest {
@Autowired
private SeparateChatAssistant separateChatAssistant;
@Test
public void testCalculatorTools() {
String answer = separateChatAssistant.chat(1, "1+2等于几,475695037565的平方根是多
少?");
//答案:3,689706.4865
System.out.println(answer);
}
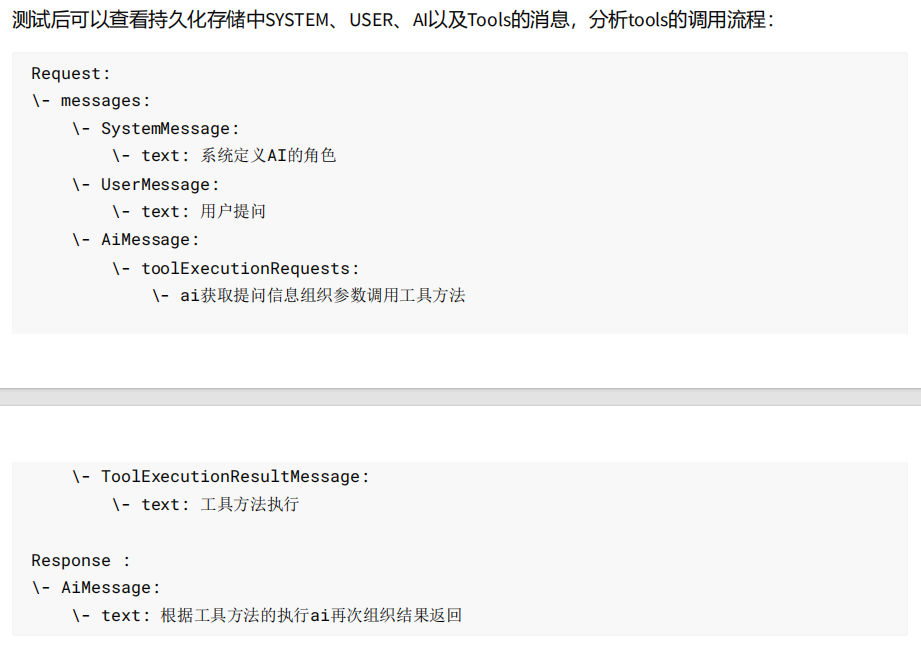
}
七.检索增强生成 —— RAG:


流程分析:
加载知识库文档 ==> 将文档中的文本分段 ==> 利用向量大模型将分段后的文本转换成向量 ==> 将向量存入向量数据库
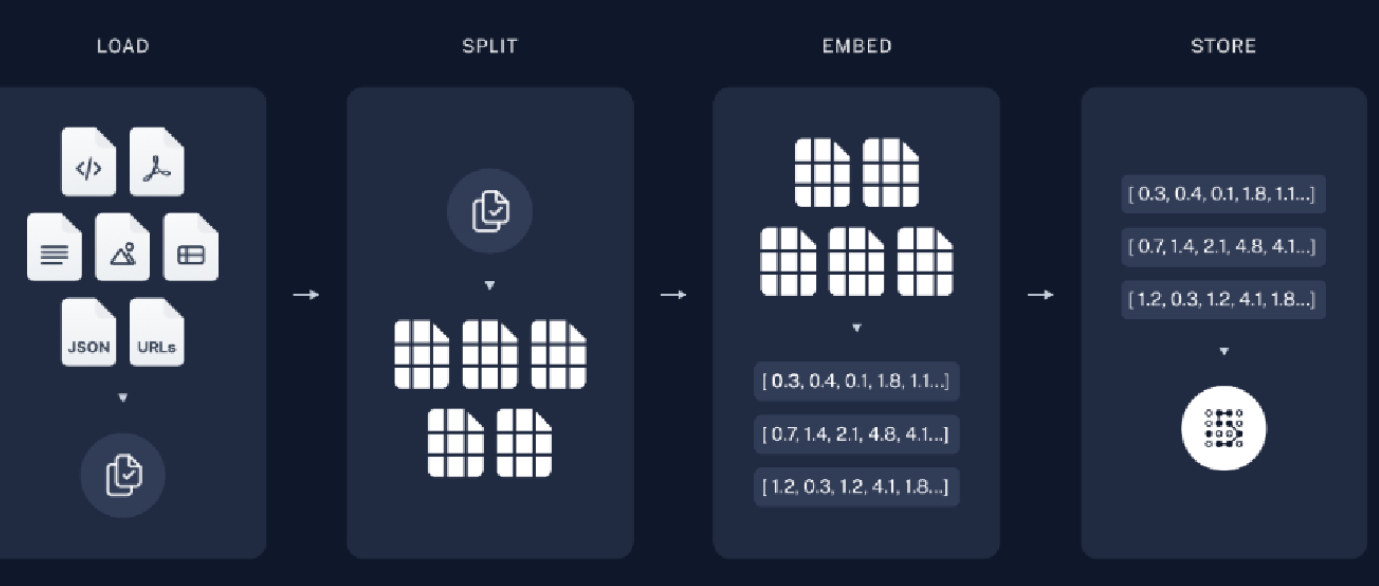
根据上图解析:
首先加载数据,可能是数据库内的、本地文本以及网上的资源等,然后将大文本进行切割(SPLIT)成小文本,之后将其向量化(Embedding)后存储到向量空间内。然后的内容如下图 ->
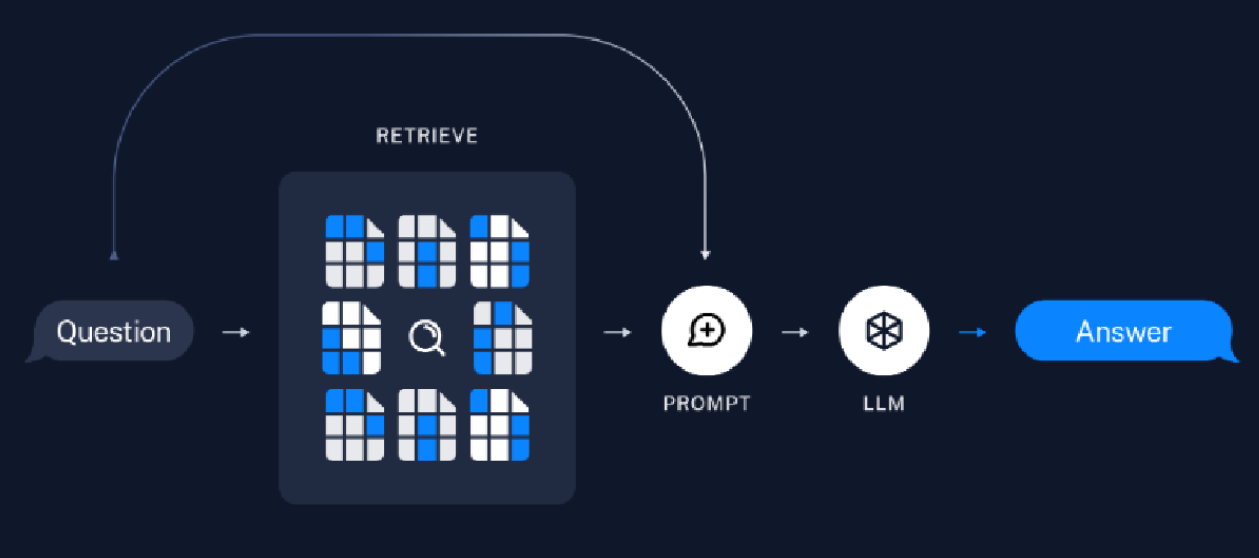
根据上图分析:
在上图,RETRIEVE就是根据上面的向量空间得到的检索器,我们的问题(Question)通过检索器检索出来后并结合提示词(PROMPT),交给LLM后在得出答案。
下面是模型检索流程:
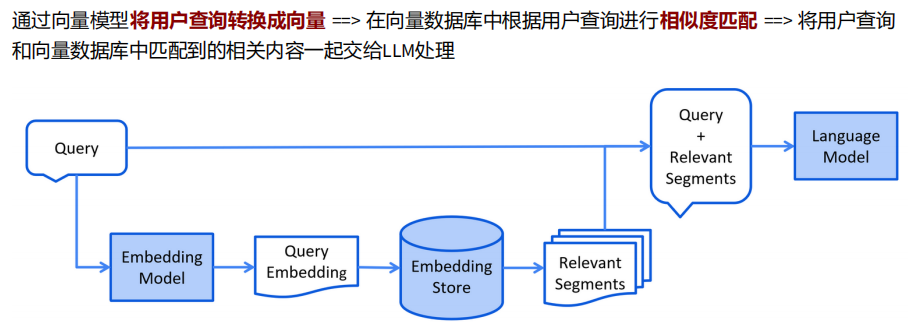
向量搜索Vector Search:
可以将向量理解为从空间中的一个点到另一个点的移动。我们可以看到一些二维空间中的向量:a是一个从 (100, 50) 到 (-50, -50) 的向量,b 是一个从 (0, 0) 到 (100, -50) 的向量。
很多时候,我们处理的向量是从原点 (0, 0) 开始的,比如b。这样我们可以省略向量起点部分,直接说 b 是向量 (100, -50)。那如何将向量的概念扩展到非数值实体上呢(例如文本)?
每个数值向量都有 x 和 y 坐标(或者在多维系统中是 x、y、z,...)。x、y、z... 是这个向量空间的轴,称为维度。对于我们想要表示为向量的一些非数值实体,我们首先需要决定这些维度,并为每个实体在每个维度上分配一个值。
例如,在一个交通工具数据集中,我们可以定义四个维度:“轮子数量”、“是否有发动机”、“是否可以在地上开动”和“最大乘客数”。然后我们可以将一些车辆表示为:

因此,我们的汽车Car向量将是 (4, yes, yes, 5),或者用数值表示为 (4, 1, 1, 5)(将 yes 设为 1,no 设为0)。
向量的每个维度代表数据的不同特性,维度越多对事务的描述越精确,我们可以使用“是否有翅膀”、“是否使用柴油”、“最高速度”、“平均重量”、“价格”等等更多的维度信息。
相似度Similarity
如果用户搜索 “轿车Car” ,你希望能够返回所有与 “汽车automobile” 和 “车辆vehicle” 等信息相关的结果。向量搜索就是实现这个目标的一种方法。
如何确定哪些是最相似的?
每个向量都有一个长度和方向。例如,在这个图中,p 和 a 指向相同的方向,但长度不同。p 和 b 正好指向相反的方向,但有相同的长度。然后还有c,长度比p短一点,方向不完全相同,但很接近。
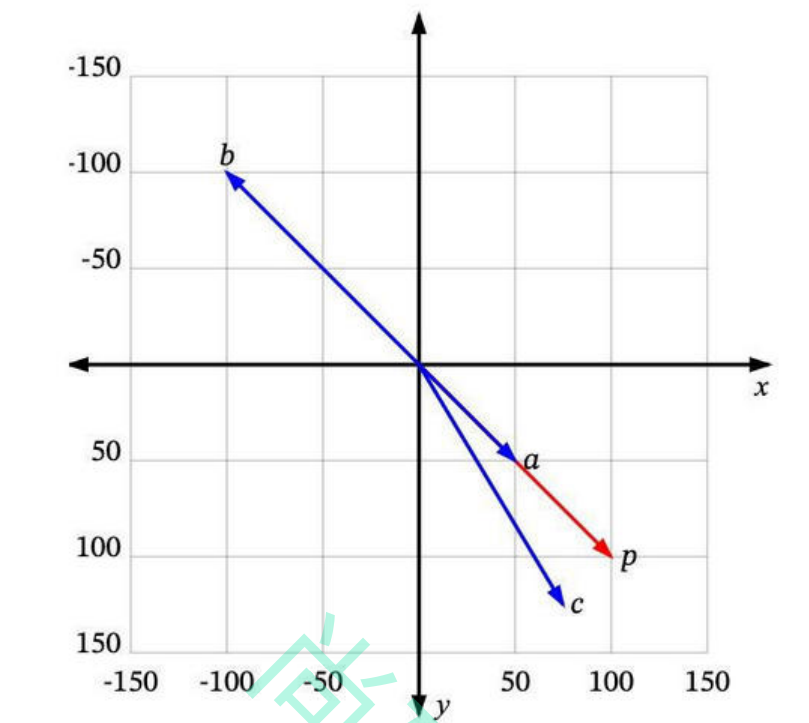
那么,哪一个最接近 p 呢?
如果“相似”仅仅意味着指向相似的方向,那么a 是最接近 p 的。接下来是 c。b 是最不相似的,因为它正好指向与p 相反的方向。如果“相似”仅仅意味着相似的长度,那么 b 是最接近 p 的(因为它有相同的长度),接下来是 c,然后是 a。
由于向量通常用于描述语义意义,仅仅看长度通常无法满足需求。大多数相似度测量要么仅依赖于方向,要么同时考虑方向和大小。
八.三种文档操作器:
1.文档加载器 —— Document Loader:

测试案例:
package cn.eleven.com.aimodel;
import dev.langchain4j.data.document.Document;
import dev.langchain4j.data.document.loader.FileSystemDocumentLoader;
import dev.langchain4j.data.document.parser.TextDocumentParser;
import dev.langchain4j.data.document.parser.apache.pdfbox.ApachePdfBoxDocumentParser;
import dev.langchain4j.data.document.splitter.DocumentByParagraphSplitter;
import dev.langchain4j.data.message.UserMessage;
import dev.langchain4j.data.segment.TextSegment;
import dev.langchain4j.model.embedding.onnx.HuggingFaceTokenizer;
import dev.langchain4j.store.embedding.EmbeddingStoreIngestor;
import dev.langchain4j.store.embedding.inmemory.InMemoryEmbeddingStore;
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;
import java.nio.file.FileSystems;
import java.nio.file.PathMatcher;
import java.util.List;
@SpringBootTest
public class RAGTest {
@Test
public void testReadDocument() {
// 示例1: 加载单个文档
// 使用FileSystemDocumentLoader读取指定目录下的知识库文档
// 并使用默认的文档解析器TextDocumentParser对文档进行解析
Document document1 = FileSystemDocumentLoader.loadDocument("src/main/resources/test-document.txt");
System.out.println(document1.text());
// 示例2: 使用特定解析器加载单个文档
Document document2 = FileSystemDocumentLoader.loadDocument("src/main/resources/test-document.txt", new TextDocumentParser());
// 示例3: 从一个目录中加载所有文档
List<Document> documents1 = FileSystemDocumentLoader.loadDocuments("src/main/resources", new TextDocumentParser());
// 示例4: 从一个目录中加载所有的.txt文档
PathMatcher pathMatcher = FileSystems.getDefault().getPathMatcher("glob:*.txt");
List<Document> documents2 = FileSystemDocumentLoader.loadDocuments("src/main/resources",
pathMatcher, new TextDocumentParser());
// 示例5: 从一个目录及其子目录中加载所有文档
List<Document> documents3 = FileSystemDocumentLoader.loadDocumentsRecursively("src/main/resources",
new TextDocumentParser());
}
}2.文档解析器 —— Document Parser:
文档可以是各种格式的文件,比如 PDF、DOC、TXT 等等。为了解析这些不同格式的文件,有一个 “文档 解析器”(DocumentParser)接口,并且我们的库中包含了该接口的几种实现方式:
① 来自 langchain4j 模块的文本文档解析器(TextDocumentParser),它能够解析纯文本格式的文件 (例如 TXT、HTML、MD 等)。
② 来自 langchain4j-document-parser-apache-pdfbox 模块的 Apache PDFBox 文档解析器 (ApachePdfBoxDocumentParser),它可以解析 PDF 文件。
③ 来自 langchain4j-document-parser-apache-poi 模块的 Apache POI 文档解析器 (ApachePoiDocumentParser),它能够解析微软办公软件的文件格式(例如 DOC、DOCX、PPT、 PPTX、XLS、XLSX 等)。
④ 来自 langchain4j-document-parser-apache-tika 模块的 Apache Tika 文档解析器 (ApacheTikaDocumentParser),它可以自动检测并解析几乎所有现有的文件格式。
添加依赖:
<!--解析pdf文档-->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-document-parser-apache-pdfbox</artifactId>
</dependency>解析PDF实例:
@SpringBootTest
public class RAGTest {
/**
* 解析PDF
*/
@Test
public void testParsePDF() {
Document document = FileSystemDocumentLoader.loadDocument(
"src/main/resources/111.pdf",
new ApachePdfBoxDocumentParser()
);
System.out.println(document);
}
}3.文档分割器 —— Document Splitter:
LangChain4j 有一个 “文档分割器”(DocumentSplitter)接口,并且提供了几种开箱即用的实现方式:
1.按段落文档分割器(DocumentByParagraphSplitter)
2.按行文档分割器(DocumentByLineSplitter)
3.按句子文档分割器(DocumentBySentenceSplitter)
4.按单词文档分割器(DocumentByWordSplitter)
5.按字符文档分割器(DocumentByCharacterSplitter)
6.按正则表达式文档分割器(DocumentByRegexSplitter)
7.递归分割:DocumentSplitters.recursive (...)
默认情况下每个文本片段最多不能超过300个token测试案例见下面。
九.向量转换与向量存储:
Embedding (Vector) Stores 常见的意思是 “嵌入(向量)存储” 。在机器学习和自然语言处理领域, Embedding 指的是将数据(如文本、图像等)转换为低维稠密向量表示的过程,这些向量能够保留数据 的关键特征。而 Stores 表示存储,即用于存储这些嵌入向量的系统或工具。它们可以高效地存储和检索 向量数据,支持向量相似性搜索,在文本检索、推荐系统、图像识别等任务中发挥着重要作用。
Langchain4j支持的向量存储: https://docs.langchain4j.dev/integrations/embedding-stores/
首先添加依赖:
<!--简单的rag实现-->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-easy-rag</artifactId>
</dependency>下面是加载文档并存入向量数据库的测试用例:
package cn.eleven.com.aimodel;
import dev.langchain4j.data.document.Document;
import dev.langchain4j.data.document.loader.FileSystemDocumentLoader;
import dev.langchain4j.data.document.parser.TextDocumentParser;
import dev.langchain4j.data.document.parser.apache.pdfbox.ApachePdfBoxDocumentParser;
import dev.langchain4j.data.document.splitter.DocumentByParagraphSplitter;
import dev.langchain4j.data.message.UserMessage;
import dev.langchain4j.data.segment.TextSegment;
import dev.langchain4j.model.embedding.onnx.HuggingFaceTokenizer;
import dev.langchain4j.store.embedding.EmbeddingStoreIngestor;
import dev.langchain4j.store.embedding.inmemory.InMemoryEmbeddingStore;
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;
import java.nio.file.FileSystems;
import java.nio.file.PathMatcher;
import java.util.List;
@SpringBootTest
public class RAGTest {
/**
* 加载文档并存入向量数据库
6.3、测试文档分割
*/
@Test
public void testReadDocumentAndStore() {
// 使用FileSystemDocumentLoader读取指定目录下的知识库文档
// 并使用默认的文档解析器对文档进行解析(TextDocumentParser)
Document document = FileSystemDocumentLoader.loadDocument("E:/knowledge/人工智能.md");
// 为了简单起见,我们暂时使用基于内存的向量存储
InMemoryEmbeddingStore<TextSegment> embeddingStore = new InMemoryEmbeddingStore<>();
// ingest
// 1、分割文档:默认使用递归分割器,将文档分割为多个文本片段,每个片段包含不超过300个token,并且有30个token的重叠部分保证连贯性
// DocumentByParagraphSplitter(DocumentByLineSplitter(DocumentBySentenceSplitter(DocumentByWordSplitter)))
// 2、文本向量化:使用一个LangChain4j内置的轻量化向量模型对每个文本片段进行向量化
// 3、将原始文本和向量存储到向量数据库中(InMemoryEmbeddingStore)
EmbeddingStoreIngestor.ingest(document, embeddingStore);
//查看向量数据库内容
System.out.println(embeddingStore);
}
}随后测试文档分割:
package cn.eleven.com.aimodel;
import dev.langchain4j.data.document.Document;
import dev.langchain4j.data.document.loader.FileSystemDocumentLoader;
import dev.langchain4j.data.document.parser.TextDocumentParser;
import dev.langchain4j.data.document.parser.apache.pdfbox.ApachePdfBoxDocumentParser;
import dev.langchain4j.data.document.splitter.DocumentByParagraphSplitter;
import dev.langchain4j.data.message.UserMessage;
import dev.langchain4j.data.segment.TextSegment;
import dev.langchain4j.model.embedding.onnx.HuggingFaceTokenizer;
import dev.langchain4j.store.embedding.EmbeddingStoreIngestor;
import dev.langchain4j.store.embedding.inmemory.InMemoryEmbeddingStore;
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;
import java.nio.file.FileSystems;
import java.nio.file.PathMatcher;
import java.util.List;
@SpringBootTest
public class RAGTest {
/**
* 文档分割
*/
@Test
public void testDocumentSplitter() {
// 使用FileSystemDocumentLoader读取指定目录下的知识库文档
// 并使用默认的文档解析器对文档进行解析(TextDocumentParser)
Document document = FileSystemDocumentLoader.loadDocument("E:/knowledge/人工智能.md");
// 为了简单起见,我们暂时使用基于内存的向量存储
InMemoryEmbeddingStore<TextSegment> embeddingStore = new InMemoryEmbeddingStore<>();
// 自定义文档分割器
// 按段落分割文档:每个片段包含不超过 300个token,并且有 30个token的重叠部分保证连贯性
// 注意:当段落长度总和小于设定的最大长度时,就不会有重叠的必要。
DocumentByParagraphSplitter documentSplitter = new DocumentByParagraphSplitter(
300,
30,
//token分词器:按token计算
new HuggingFaceTokenizer());
// 按字符计算
// DocumentByParagraphSplitter documentSplitter = new DocumentByParagraphSplitter(300, 30);
EmbeddingStoreIngestor
.builder()
.embeddingStore(embeddingStore)
.documentSplitter(documentSplitter)
.build()
.ingest(document);
}
}
十. 向量模型和向量存储:
1.向量模型:
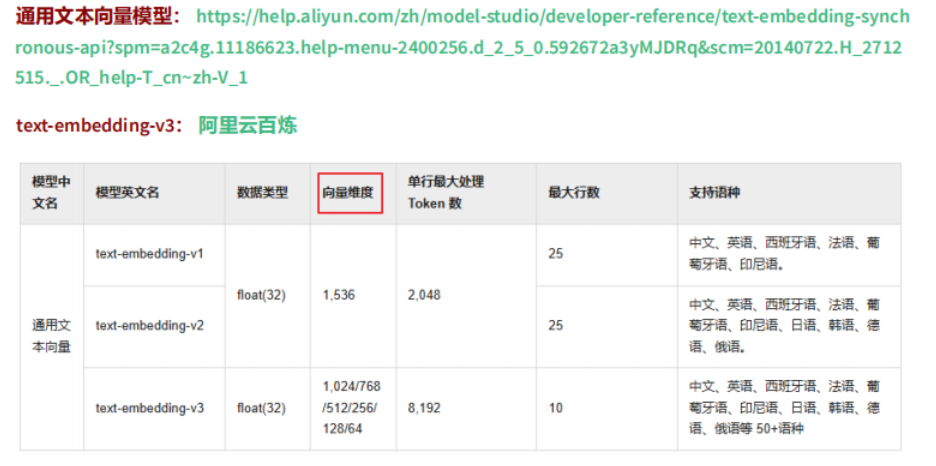
使用 text-embedding-v3 依然需要添加 langchain4j-community-dashscope 依赖,我们之前已经添 加过了:
langchain4j:
# 集成阿里通义千问-通用文本向量-v3
community:
dashscope:
embedding-model:
model-name: text-embedding-v3
api-key: ${DASH_SCOPE_API_KEY}下面是文本向量化的使用案例:
package cn.eleven.com.aimodel;
import dev.langchain4j.data.document.Document;
import dev.langchain4j.data.document.loader.FileSystemDocumentLoader;
import dev.langchain4j.data.embedding.Embedding;
import dev.langchain4j.data.segment.TextSegment;
import dev.langchain4j.model.embedding.EmbeddingModel;
import dev.langchain4j.model.output.Response;
import dev.langchain4j.store.embedding.*;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.util.Arrays;
import java.util.List;
@SpringBootTest
public class EmbeddingTest {
@Autowired
private EmbeddingModel embeddingModel;
@Test
public void testEmbeddingModel(){
Response<Embedding> embed = embeddingModel.embed("你好");
System.out.println("向量维度:" + embed.content().vector().length);
System.out.println("向量输出:" + embed.toString());
}
}2.向量存储:
之前我们使用的是InMemoryEmbeddingStore作为向量存储,但是不建议在生产中使用基于内存的向量存储。因此这里我们使用Pinecone作为向量数据库。
官方网站:The vector database to build knowledgeable AI | Pinecone
访问官方网站、注册、登录、获取apiKey且配置在环境变量中。默认有2GB的免费存储空间。

首先添加依赖:
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-pinecone</artifactId>
</dependency>随后配置EmbeddingStoreConfig:(这里的API_KEY也是需要获取并保存在环境变量中)
package cn.eleven.com.aimodel.config;
import dev.langchain4j.data.segment.TextSegment;
import dev.langchain4j.model.embedding.EmbeddingModel;
import dev.langchain4j.store.embedding.EmbeddingStore;
import dev.langchain4j.store.embedding.pinecone.PineconeEmbeddingStore;
import dev.langchain4j.store.embedding.pinecone.PineconeServerlessIndexConfig;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class EmbeddingStoreConfig {
@Autowired
private EmbeddingModel embeddingModel;
@Bean
public EmbeddingStore<TextSegment> embeddingStore() {
//创建向量存储
EmbeddingStore<TextSegment> embeddingStore = PineconeEmbeddingStore.builder()
.apiKey(System.getenv("PINECONE_API_KEY"))
.index("xiaozhi-index")//如果指定的索引不存在,将创建一个新的索引
.nameSpace("xiaozhi-namespace") //如果指定的名称空间不存在,将创建一个新的名称空间
.createIndex(PineconeServerlessIndexConfig.builder()
.cloud("AWS") //指定索引部署在 AWS 云服务上。
.region("us-east-1") //指定索引所在的 AWS 区域为 us-east-1。
.dimension(embeddingModel.dimension()) //指定索引的向量维度,该维度与 embeddedModel 生成的向量维度相同。
.build())
.build();
return embeddingStore;
}
}随后测试向量存储:
package cn.eleven.com.aimodel;
import dev.langchain4j.data.document.Document;
import dev.langchain4j.data.document.loader.FileSystemDocumentLoader;
import dev.langchain4j.data.embedding.Embedding;
import dev.langchain4j.data.segment.TextSegment;
import dev.langchain4j.model.embedding.EmbeddingModel;
import dev.langchain4j.model.output.Response;
import dev.langchain4j.store.embedding.*;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.util.Arrays;
import java.util.List;
@SpringBootTest
public class EmbeddingTest {
@Autowired
private EmbeddingModel embeddingModel;
@Autowired
private EmbeddingStore embeddingStore;
/**
* 将文本转换成向量,然后存储到pinecone中
*
* 参考:
* https://docs.langchain4j.dev/tutorials/embedding-stores
*/
@Test
public void testPineconeEmbeded() {
// 将文本转换成向量
TextSegment segment1 = TextSegment.from("我喜欢羽毛球");
Embedding embedding1 = embeddingModel.embed(segment1).content();
// 存入向量数据库
embeddingStore.add(embedding1, segment1);
TextSegment segment2 = TextSegment.from("今天天气很好");
Embedding embedding2 = embeddingModel.embed(segment2).content();
embeddingStore.add(embedding2, segment2);
}
}相似度匹配:
接收请求获取问题,将问题转换为向量,在 Pinecone 向量数据库中进行相似度搜索,找到最相似的文本 片段,并将其文本内容返回给客户端。
package cn.eleven.com.aimodel;
import dev.langchain4j.data.document.Document;
import dev.langchain4j.data.document.loader.FileSystemDocumentLoader;
import dev.langchain4j.data.embedding.Embedding;
import dev.langchain4j.data.segment.TextSegment;
import dev.langchain4j.model.embedding.EmbeddingModel;
import dev.langchain4j.model.output.Response;
import dev.langchain4j.store.embedding.*;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.util.Arrays;
import java.util.List;
@SpringBootTest
public class EmbeddingTest {
@Autowired
private EmbeddingModel embeddingModel;
@Autowired
private EmbeddingStore embeddingStore;
/**
* Pinecone-相似度匹配
*/
@Test
public void embeddingSearch() {
// 提问,并将问题转成向量数据
Embedding queryEmbedding = embeddingModel.embed("你最喜欢的运动是什么?").content();
// 创建搜索请求对象
EmbeddingSearchRequest searchRequest = EmbeddingSearchRequest.builder()
.queryEmbedding(queryEmbedding)
.maxResults(1) // 匹配最相似的一条记录
// .minScore(0.8) // 查找得分在0.8以上
.build();
// 根据搜索请求 searchRequest 在向量存储中进行相似度搜索
EmbeddingSearchResult<TextSegment> searchResult =
embeddingStore.search(searchRequest);
// searchResult.matches():获取搜索结果中的匹配项列表。
// .get(0):从匹配项列表中获取第一个匹配项
EmbeddingMatch<TextSegment> embeddingMatch = searchResult.matches().get(0);
// 获取匹配项的相似度得分
System.out.println(embeddingMatch.score()); // 0.8144288515898701
// 返回文本结果
System.out.println(embeddingMatch.embedded().text());
}
}
DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 23
23 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)