机器学习基础(二) 线性回归与梯度下降算法
本文将从线性回归入手引出梯度下降算法。
目录
本文将从线性回归入手引出梯度下降算法。
线性回归概念
概念
线性回归(Linear Regression)是一种用于建模和分析变量之间线性关系的统计方法, 通过拟合一条直线(或超平面)来描述自变量(X)与因变量(Y)之间的线性关系,从而预测或解释数据。
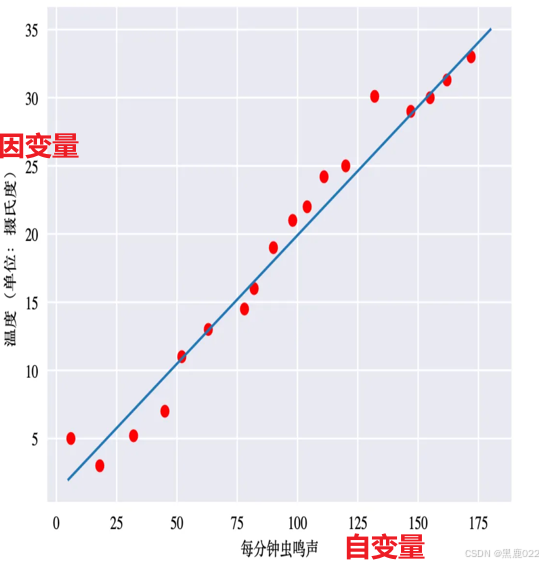
分类
一元线性回归:
y = w x + b y = wx +b y=wx+b
目标值只与一个因变量有关系
多元线性回归: y = 𝑤 1 𝑥 1 + 𝑤 2 𝑥 2 + 𝑤 3 𝑥 3 + … + 𝑏 y= 𝑤_1 𝑥_1+ 𝑤_2 𝑥_2 + 𝑤_3 𝑥_3 + … + 𝑏 y=w1x1+w2x2+w3x3+…+b
目标值只与多个因变量有关系
线性回归的求解方法
线性回归是如何找到数据分布的规律和最优解?
我们是通过让损失函数值最小,来求得线性回归中的系数。
损失函数 loss function(cost function,target function)
衡量预测值和真实值效果的函数,也叫代价函数,目标函数,成本函数
我们用线性回归建模,就是在找各个自变量和因变量的关系,这些关系就是自变量前面的系数 ω i \omega_i ωi,我们最小化损失函数的过程,就是求解这些系数。
线性回归常用的损失函数有:最小二乘、均方误差、平均绝对误差
数学表达
最小二乘法 (LS Least square)
所有样本(真实值-预测值)的平方和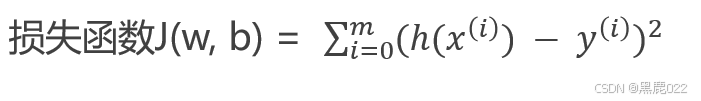
其中 h ( x ( i ) ) h(x^{(i)}) h(x(i)) 是预测值, y ( i ) y^{(i)} y(i)是真实值
平方损失函数(均方误差)(MSE Mean Square Error)
最小二乘/样本个数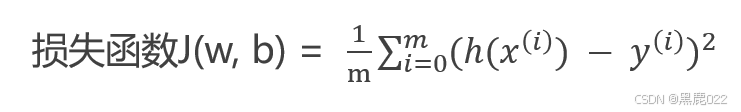
平均绝对损失函数(平均绝对误差)(MAE Mean absolute Error)
所有样本|真实值-预测值|平均值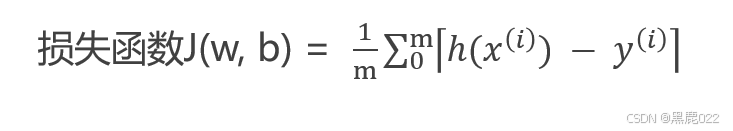
补充: 范数 Norm
范数(norm)是数学中的一种基本概念,用于度量向量或者矩阵的大小或者长度
1范数(L1范数)-向量中各个元素绝对值之和。 表示为: ∣ ∣ x ∣ ∣ 1 ||x||_1 ∣∣x∣∣1
𝑥 𝑇 = ( 1 , 2 , − 3 ) ‖ x ‖ 1 = ∣ 1 ∣ + ∣ 2 ∣ + ∣ − 3 ∣ = 6 𝑥^𝑇 = (1, 2, −3) \quad ‖x‖_1 = |1| + |2| + |−3| = 6 xT=(1,2,−3)‖x‖1=∣1∣+∣2∣+∣−3∣=6
2范数(L2范数)-向量的模长,每个元素平方求和,再开平方根。 表示为: ∣ ∣ x ∣ ∣ 2 ||x||_2 ∣∣x∣∣2
𝑥 𝑇 = ( 1 , 2 , − 3 ) ‖ x ‖ 2 = ( 1 2 + 2 2 + ( − 3 ) 2 ) = √ 14 𝑥^𝑇 = (1, 2, −3) \quad ‖x‖_2 = \sqrt{(1^2+2^2+(−3)^2 )}= √14 xT=(1,2,−3)‖x‖2=(12+22+(−3)2)=√14
p-范数:向量中每一个元素p幂求和,在开p次根。表示为: ∣ ∣ x ∣ ∣ p ||x||_p ∣∣x∣∣p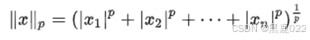
我们拿到了损失函数,接下来就是让损失函数最小。在线性回归中,我们有两种方式来求解,分别是正规方程和梯度下降法。
线性回归中的正规方程
一元解析解
拿一元线性回归举例,假设我们使用MSE均方误差作为线性回归的损失函数,那么:
J ( k , b ) = ∑ 𝑖 = 1 𝑚 ( h ( 𝑥 ( 𝑖 ) ) − 𝑦 ( 𝑖 ) ) 2 = ∑ 𝑖 = 1 𝑚 ( 𝑘 𝑥 ( 𝑖 ) + 𝑏 − 𝑦 ( 𝑖 ) ) 2 J(k, b) = ∑_{𝑖=1}^𝑚(ℎ(𝑥^{(𝑖) }) − 𝑦^{(𝑖) })^2 = ∑_{𝑖=1}^𝑚(𝑘𝑥^{(𝑖) }+𝑏− 𝑦^{(𝑖) })^2 J(k,b)=∑i=1m(h(x(i))−y(i))2=∑i=1m(kx(i)+b−y(i))2
其中k,b是两个待求解的变量,我们分别对它们求偏导:
𝜕 𝐽 ( 𝑘 , 𝑏 ) 𝜕 𝑘 = ∑ 𝑖 = 1 𝑚 2 ( k 𝑥 ( 𝑖 ) + 𝑏 − 𝑦 ( 𝑖 ) ) ( 2 − 1 ) ( k 𝑥 ( 𝑖 ) + 𝑏 − 𝑦 ( 𝑖 ) ) ′ = ∑ 𝑖 = 1 𝑚 ( 2 𝑘 𝑥 ( 𝑖 ) 2 + 2 𝑏 𝑥 ( 𝑖 ) − 2 𝑥 ( 𝑖 ) 𝑦 ( 𝑖 ) ) = 0 \frac{𝜕𝐽(𝑘, 𝑏)}{𝜕𝑘} = ∑_{𝑖=1}^𝑚 2(k𝑥^{(𝑖) }+𝑏− 𝑦^{(𝑖) })^{(2-1)} (k𝑥^{(𝑖) }+𝑏− 𝑦^{(𝑖) })^′ = ∑_{𝑖=1}^𝑚(2𝑘𝑥^{(𝑖) ^2}+2𝑏𝑥^{(𝑖) }−2𝑥^{(𝑖) } 𝑦^{(𝑖) }) = 0 𝜕k𝜕J(k,b)=∑i=1m2(kx(i)+b−y(i))(2−1)(kx(i)+b−y(i))′=∑i=1m(2kx(i)2+2bx(i)−2x(i)y(i))=0 ------1式
𝜕 𝐽 ( 𝑘 , 𝑏 ) 𝜕 𝑘 = ∑ 𝑖 = 1 𝑚 2 ( k 𝑥 ( 𝑖 ) + 𝑏 − 𝑦 ( 𝑖 ) ) ( 2 − 1 ) ( k 𝑥 ( 𝑖 ) + 𝑏 − 𝑦 ( 𝑖 ) ) ′ = ∑ 𝑖 = 1 𝑚 ( 2 k 𝑥 ( 𝑖 ) + 2 𝑏 − 2 𝑦 ( 𝑖 ) ) \frac{𝜕𝐽(𝑘, 𝑏)}{𝜕𝑘} = ∑_{𝑖=1}^𝑚 2(k𝑥^{(𝑖) }+𝑏− 𝑦^{(𝑖) })^{(2-1)} (k𝑥^{(𝑖) }+𝑏− 𝑦^{(𝑖) })^′= ∑_{𝑖=1}^𝑚 (2k𝑥^{(𝑖) }+2𝑏− 2𝑦^{(𝑖) }) 𝜕k𝜕J(k,b)=∑i=1m2(kx(i)+b−y(i))(2−1)(kx(i)+b−y(i))′=∑i=1m(2kx(i)+2b−2y(i)) ------- 2式
对1式、2式化简, 𝑦 ( i ) 𝑦^{(i)} y(i)代表第i个样本的预测值
k ∑ 𝑖 = 1 𝑚 𝑥 ( 𝑖 ) 2 + 𝑏 ∑ 𝑖 = 1 m 𝑥 ( 𝑖 ) − ∑ 𝑖 = 1 𝑚 𝑥 ( 𝑖 ) 𝑦 ( 𝑖 ) = 0 k ∑_{𝑖=1}^𝑚 𝑥^{(𝑖)^2 }+𝑏∑_{𝑖=1}^m𝑥^{(𝑖) } −∑_{𝑖=1}^𝑚𝑥^{(𝑖) } 𝑦^{(𝑖) } = 0 k∑i=1mx(i)2+b∑i=1mx(i)−∑i=1mx(i)y(i)=0 ------- 3式
k ∑ 𝑖 = 1 𝑚 𝑥 ( 𝑖 ) + 𝑏 𝑚 − ∑ 𝑖 = 1 𝑚 𝑦 ( i ) = 0 k∑_{𝑖=1}^𝑚𝑥^{(𝑖) }+𝑏𝑚−∑_{𝑖=1}^𝑚𝑦^{(i)} = 0 k∑i=1mx(i)+bm−∑i=1my(i)=0 ------- 4式
最后将数据带入3、4式 即可求解到k,b结果。
推广到多元,正规方程
多元线性回归的损失函数求解可以使用向量和矩阵相乘: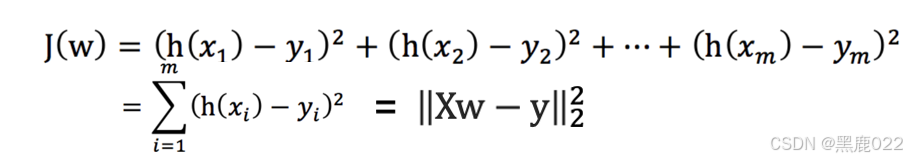
这里的 ∣ ∣ X ω − y ∣ ∣ 2 2 ||X\omega-y||_2^2 ∣∣Xω−y∣∣22是所有样本真实值和估计值差值的 L2 范数的平方
进而可以直接求出系数向量( ω \omega ω)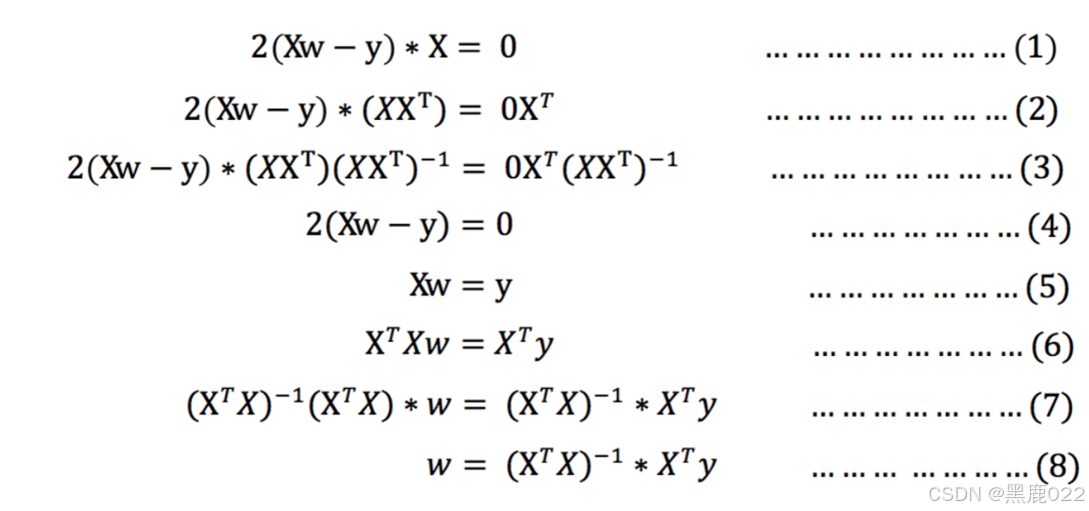
其中 ω = ( X T X ) − 1 ∗ X T y \omega=(X^TX)^{-1}*X^Ty ω=(XTX)−1∗XTy就是正规方程。
正规方程的特性和问题:
不需要学习率
一次运算得出,一蹴而就
应用场景:小数据量场景、精准的数据场景
缺点:计算量大、容易收到噪声、特征强相关性的影响
注意: X T X X^T X XTX的逆矩阵不存在时,无法求解
注意:计算 X T X X^T X XTX的逆矩阵非常耗时
如果数据规律不是线性的,无法使用或效果不好
梯度下降法
概念
梯度下降是机器学习和深度学习中优化模型参数的核心算法,通过迭代调整参数,最小化损失函数
核心思想: 沿损失函数的负梯度方向逐步调整参数,使损失函数值最小化。
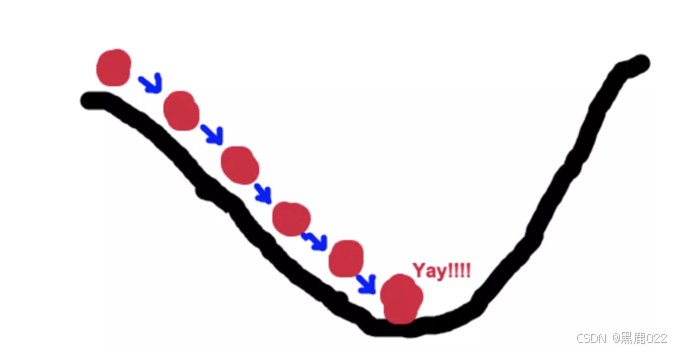
梯度下降过程就和下山场景类似
可微分的损失函数,代表着一座山
寻找的函数的最小值,也就是山底
相比于正规方程的“一步到位”,梯度下降是一步步逐渐收敛到最低点: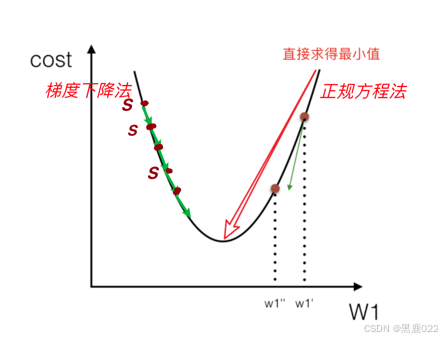
梯度 gradient
单变量函数中,梯度就是某一点切线斜率(某一点的导数);有方向为函数增长最快的方向
多变量函数中,梯度就是某一个点的偏导数;有方向:偏导数分量的向量方向
梯度下降公式:
循环迭代求当前点的梯度,更新当前的权重参数
θ i + 1 = θ i − α ∂ ∂ θ J ( θ ) \theta_{i+1}=\theta_i-\alpha\frac{\partial}{\partial\theta}J(\theta) θi+1=θi−α∂θ∂J(θ)
α: 学习率(步长) 不能太大, 也不能太小. 机器学习中:0.001 ~ 0.01
梯度是上升最快的方向, 我们需要是下降最快的方向, 所以需要加负号
梯度下降的优化过程
1.给定初始位置、步长(学习率)
2.计算该点当前的梯度的负方向
3.向该负方向移动步长
4.重复 2-3 步 直至收敛
两次差距小于指定的阈值
达到指定的迭代次数
梯度下降公式中,为什么梯度要乘以一个负号
梯度的方向实际就是函数在此点上升最快的方向!
需要朝着下降最快的方向走,负梯度方向, 所以加上负号
有关学习率(步长)
步长决定了在梯度下降迭代的过程中,每一步沿梯度负方向前进的长度
学习率太小,下降的速度会慢
学习率太大:容易造成错过最低点、产生下降过程中的震荡、甚至梯度爆炸
梯度下降特点:
需要选择学习率
需要迭代求解
特征数量较大可以使用
应用场景:更加普适,迭代的计算方式,适合于嘈杂、大数据应用场景
注意:梯度下降在各种损失函数(目标函数)求解中大量使用。深度学习中更是如此,深度学习模型参数很轻松就上亿,只能通过迭代的方式求最优解。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 23
23 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)