无代码数据提取神器 Maxun:2 分钟搭建自动化爬虫,轻松抓取网页数据
Maxun 作为一个开源的无代码网页数据提取平台,具有显著的优势和广泛的应用前景。它的无代码操作特性降低了数据提取的技术门槛,让更多的人能够参与到数据采集工作中来。高度自动化执行和多平台集成能力,提高了工作效率和数据处理的便利性。云端服务的强大支持,确保了数据提取过程的稳定和可靠。然而,Maxun 也并非完美无缺。在处理一些复杂的网页结构和动态内容时,可能需要进一步优化提取规则,以提高数据提取的准
大家好,今天给大家分享一个名为 Maxun 的项目,它是一个开源的无代码网页数据提取平台,旨在让用户无需具备专业的编程知识,就能轻松、高效地从网页上提取所需的数据,为数据提取工作带来了全新的解决方案。
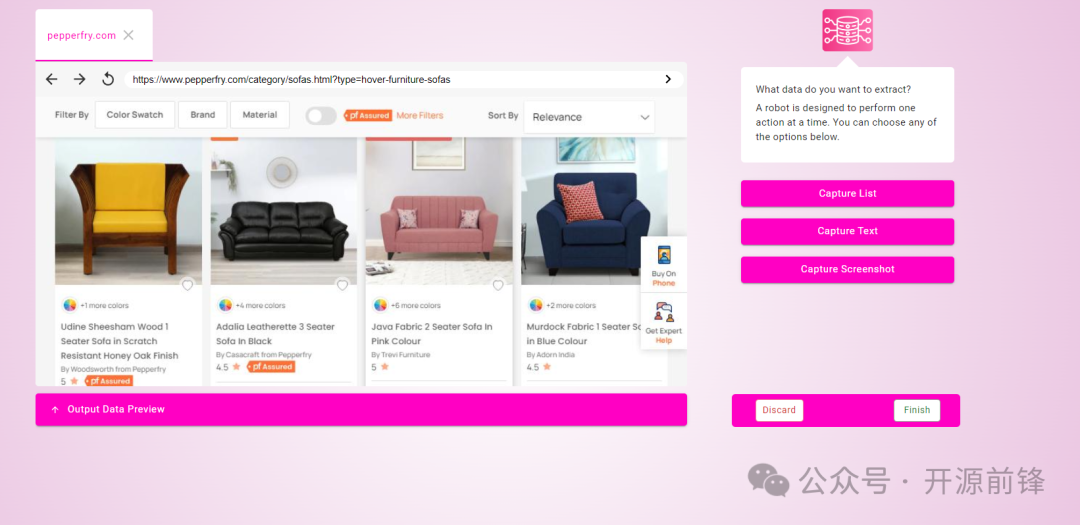
项目概述
Maxun 致力于打破传统网页数据提取依赖专业代码的限制,让普通用户也能快速上手进行数据采集。它允许用户在短短两分钟内训练一个机器人,通过模拟用户操作,实现对网页数据的自动抓取。这个机器人可以执行诸如“Capture List”(捕获列表)、“Capture Text”(捕获文本)或“Capture Screenshot”(捕获截图)等多种动作。一旦创建完成,机器人就能自动持续地为用户提取数据,无需人工时刻干预。
Maxun 不仅提供本地部署版本,还有云端版本可供选择。云端版本具备强大的功能,能够有效处理反爬虫检测,拥有庞大的代理网络并支持自动代理轮换,还能解决 CAPTCHA 验证等难题,确保数据提取过程的顺利进行。
项目特点
无代码操作的便捷性
传统的数据提取工作往往需要编写复杂的代码,使用像 Python 的 Scrapy 框架或 BeautifulSoup 库等,这对于非技术人员来说是一道难以跨越的门槛。而 Maxun 完全摒弃了代码编写的过程,用户只需通过简单的配置和操作,就能轻松创建数据提取机器人。这使得业务人员、市场调研人员等非专业技术人员也能独立完成数据提取任务,大大提高了工作效率。
高度自动化执行
创建好的机器人可以按照用户预设的规则自动运行,持续不断地从网页上提取数据。对于需要定期获取数据的场景,如每日获取股票价格、实时新闻资讯等,Maxun 的自动化特性能够节省大量的人力和时间成本。用户只需设置好机器人的运行规则和提取目标,就可以让机器人在后台自动工作,无需人工频繁干预。
多平台集成能力
Maxun 支持与 Google Sheets 和 Airtable 等常见的数据处理平台进行集成。从项目的代码实现来看,在 maxun/src/components/integration/IntegrationSettings.tsx 文件中,详细实现了与 Google Sheets 和 Airtable 的认证、数据获取和更新等功能。用户可以将提取的数据直接存储到这些平台中,方便后续的分析和处理。
云端服务的强大支持
Maxun 的云端版本为数据提取工作提供了强大的保障。它具备先进的反爬虫检测能力,能够应对各种复杂的反爬虫机制,确保数据提取的成功率。同时,庞大的代理网络和自动代理轮换功能,避免了因 IP 被封禁而导致数据提取失败的问题。此外,云端版本还能有效解决 CAPTCHA 验证问题,为数据提取的顺利进行提供了有力支持。
应用场景
市场调研领域
在市场竞争日益激烈的今天,企业需要及时、准确地了解市场动态和竞争对手的情况。Maxun 可以帮助企业快速从各大电商平台、社交媒体等网站上提取所需的数据,如竞争对手的产品价格、用户评价、市场趋势等。这些数据能够为企业的市场决策提供有力支持,帮助企业制定更加合理的营销策略。
舆情监测工作
政府部门、企业公关等机构需要及时掌握公众对特定事件、产品或品牌的看法。Maxun 可以从新闻网站、论坛、社交媒体等平台上提取相关的舆情信息,帮助机构及时了解舆情动态,做出相应的应对措施。例如,当企业推出新产品时,可以通过 Maxun 监测用户在社交媒体上的反馈,及时发现问题并进行改进。
数据采集与分析
科研机构、数据分析公司等需要大量的数据进行研究和分析。Maxun 可以帮助他们从各种网页上采集所需的数据,然后将数据存储到合适的平台中进行进一步的分析和处理。例如,在进行学术研究时,科研人员可以使用 Maxun 从学术数据库、行业报告网站等获取相关的数据,为研究提供丰富的素材。
安装使用
安装说明
准备工作
在安装 Maxun 之前,需要确保系统已经安装了 Node.js、PostgreSQL、MinIO 和 Redis。这些软件是 Maxun 运行所依赖的基础环境,安装过程中需要确保它们的版本与 Maxun 兼容。
安装步骤
1.克隆项目代码
git clone https://github.com/getmaxun/maxun2.进入项目根目录
cd maxun3.安装项目依赖
npm install4.安装 maxun-core 依赖
cd maxun-core
npm install
cd ..5.安装 Chromium 及其依赖
npx playwright install --with-deps chromium6.启动前端和后端
npm run start安装完成后,用户可以通过访问 http://localhost:5173/ 来访问前端界面,通过 http://localhost:8080/ 来访问后端服务。
环境配置
在项目的根目录下需要创建一个 .env 文件,并将示例环境文件(https://github.com/getmaxun/maxun/blob/master/ENVEXAMPLE)中的内容复制到 .env 文件中,根据实际情况进行配置。例如,需要设置数据库的连接信息、MinIO 的存储信息等。
使用示例
创建机器人
打开 Maxun 的前端界面,按照提示创建一个新的机器人。在创建过程中,用户可以根据自己的需求选择机器人要执行的动作,如“Capture List”、“Capture Text”或“Capture Screenshot”,并设置相应的目标网页和提取规则。例如,如果用户需要提取某个电商网站上的商品列表信息,可以选择“Capture List”动作,并设置网页的 URL 和商品列表的定位规则。
配置集成平台
如果需要将提取的数据存储到 Google Sheets 或 Airtable 中,可以在集成设置中进行配置。在 IntegrationSettingsModal 组件中,用户可以选择集成类型,进行认证操作,选择相应的文件或表格,并提交设置。例如,选择集成 Google Sheets 后,需要进行 Google 账号的授权,然后选择要存储数据的表格。
运行机器人
创建和配置完成后,启动机器人。机器人将按照设置的规则自动访问目标网页,提取所需的数据,并将数据存储到指定的位置。用户可以在前端界面上查看机器人的运行状态和提取结果。
总结
Maxun 作为一个开源的无代码网页数据提取平台,具有显著的优势和广泛的应用前景。它的无代码操作特性降低了数据提取的技术门槛,让更多的人能够参与到数据采集工作中来。高度自动化执行和多平台集成能力,提高了工作效率和数据处理的便利性。云端服务的强大支持,确保了数据提取过程的稳定和可靠。
然而,Maxun 也并非完美无缺。在处理一些复杂的网页结构和动态内容时,可能需要进一步优化提取规则,以提高数据提取的准确性。此外,随着反爬虫技术的不断发展,Maxun 的反爬虫检测能力也需要持续提升。
总体而言,Maxun 为网页数据提取提供了一个便捷、高效的解决方案,无论是对于个人开发者还是企业用户,都具有很大的吸引力和实用价值。未来,随着技术的不断进步和社区的不断发展,Maxun 有望在网页数据提取领域发挥更加重要的作用,为更多的用户带来便利和价值。
项目地址
https://github.com/getmaxun/maxun
DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 26
26 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)