深入剖析 Apache Flume:从日志收集到数据流转的全链路指南
Apache Flume 是一个分布式、高可靠、高可用的用来收集、聚合、转移不同来源的大量日志数据到中央数据仓库的工具。在大数据领域,日志数据就像城市地下的自来水,源源不断地产生却需要有序管理。Apache Flume 作为 Apache 顶级项目,正是这样一套专业的 "数据管道系统",它能将分散在各处的日志数据高效收集、聚合并传输到中央数据仓库。
目录
4.1 基础案例:Avro+Memory+Logger(测试验证,没有实战意义)
4.2 生产级案例:Taildir+File+HDFS(实时日志采集)
一、Flume:大数据世界的 "数据管道系统"
在大数据领域,日志数据就像城市地下的自来水,源源不断地产生却需要有序管理。Apache Flume 作为 Apache 顶级项目,正是这样一套专业的 "数据管道系统",它能将分散在各处的日志数据高效收集、聚合并传输到中央数据仓库。
参考网址:Flume 1.9用户手册中文版 — 可能是目前翻译最完整的版本了
1.1 Flume 的核心定位与应用场景
- 专业定位:分布式、高可靠、高可用的日志收集框架
- 数据类型覆盖:
- 文本日志(服务器访问日志、应用运行日志)
- 业务系统数据(数据库变更记录)
- 第三方数据(API 接口数据、爬虫数据)
- 典型场景:
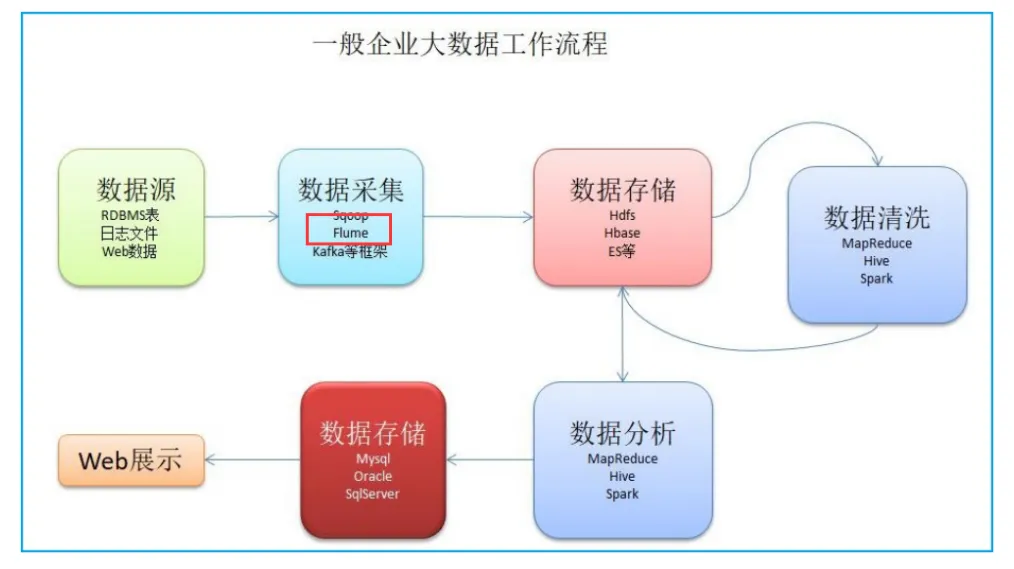
1.2 核心架构:三组件驱动的数据流转
Flume 的架构设计遵循 "生产者 - 消费者" 模式,由三个核心组件构成:Source、Channel、Sink。
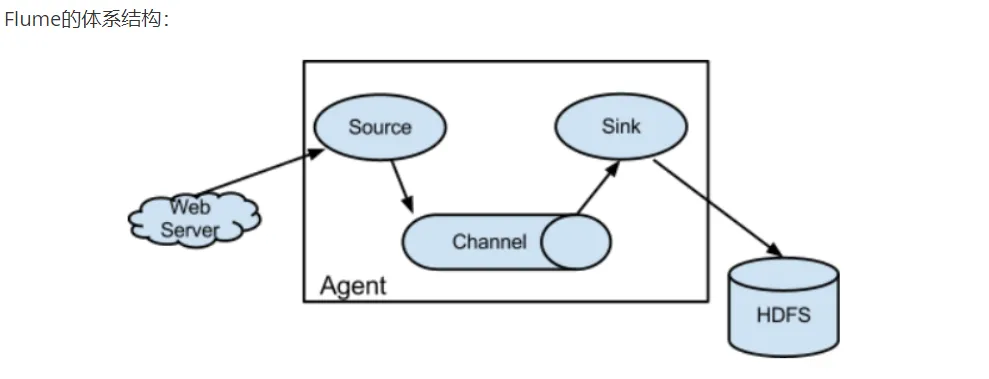
Agent : 是Flume中的基本单位,一个Flume配置文件,可以有多个Agent.
每一个Agent中有三个组件组成,缺一不可:
1、Source 来源,数据过来的地方
2、channel 通道 传递数据用的通道,一般比较的长,一个Channel中可以存储多个数据
3、Sink 数据下沉的地方
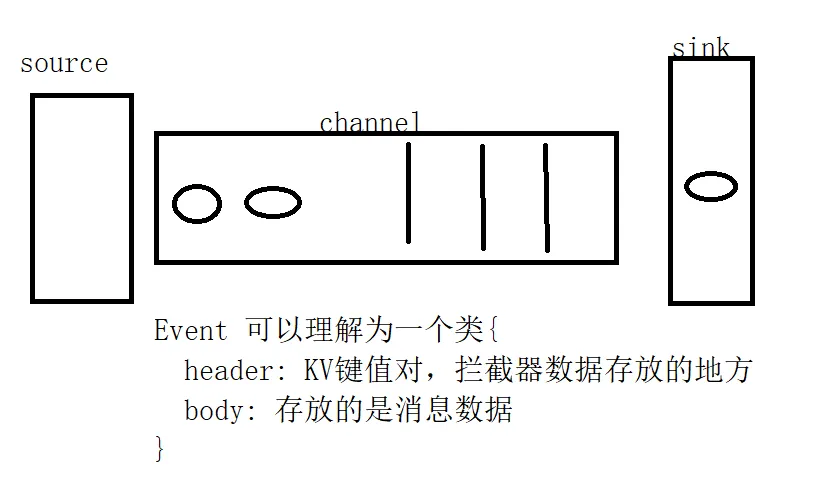
4、event 一个event就是一个数据单元(一条数据)
关键概念:Event(数据单元),每个 Event 包含 headers(元数据)和 body(数据内容),就像快递包裹上的面单信息和包裹内容。
二、Flume 安装与环境配置:从 0 到 1 的实战部署
2.1 环境准备与安装步骤
生产环境推荐配置
- JDK 1.8+(必须先安装并配置 JAVA_HOME)
- 安装路径规范:
/opt/installs/(企业级惯例)
执行安装命令
# 解压安装包
tar -zxvf apache-flume-1.9.0-bin.tar.gz -C /opt/installs/
# 重命名目录
mv /opt/installs/apache-flume-1.9.0-bin /opt/installs/flume
# 配置环境变量
echo "export FLUME_HOME=/opt/installs/flume" >> /etc/profile
echo "export PATH=$PATH:$FLUME_HOME/bin" >> /etc/profile
# 使配置生效
source /etc/profile验证安装
flume-ng version正常输出应包含:
Flume 1.9.0
Source code repository: https://git-wip-us.apache.org/repos/asf/flume.git
...2.2 关键配置文件修改
核心配置文件:flume-env.sh
cd $FLUME_HOME/conf
# 复制模板文件
cp flume-env.sh.template flume-env.sh
# 编辑配置文件
vi flume-env.sh修改内容:
# 指向实际JDK路径
export JAVA_HOME=/opt/installs/jdk
# 分配合理内存(生产环境建议2GB+)
export JAVA_OPTS="-Xms2048m -Xmx2048m -Dcom.sun.management.jmxremote"三、Flume 数据模型与核心组件解析
3.1 基础数据流转模型
单 Agent 模型(适合测试场景)
Source → Channel → Sink多 Agent 级联模型(生产环境常用)
Agent1(Source→Channel) → Agent2(Source→Channel) → Sink3.2 核心组件详解
常用 Source 类型
| 类型 | 适用场景 | 核心配置参数 |
|---|---|---|
| Avro Source | 分布式数据采集 | bind (绑定 IP)、port (端口) |
| Exec Source | 执行命令获取数据 | command (执行命令) |
| Spooling Directory | 监控文件夹新文件 | directory (监控目录) |
| Taildir Source | 监控文件追加内容 | filegroups (文件组) |
常用 Channel 类型
| 类型 | 特点 | 适用场景 |
|---|---|---|
| Memory Channel | 速度快但不持久 | 测试环境或短暂缓冲 |
| File Channel | 持久化存储 | 生产环境可靠性要求高 |
| Kafka Channel | 与 Kafka 集成 | 数据需要多系统消费 |
常用 Sink 类型
| 类型 | 适用场景 | 核心配置参数 |
|---|---|---|
| Logger Sink | 日志输出(测试用) | 无特殊参数 |
| HDFS Sink | 数据存入 Hadoop 分布式文件系统 | hdfs.path (存储路径) |
| Kafka Sink | 数据发送到 Kafka | bootstrap.servers (集群地址) |
四、实战案例:从入门到企业级应用
在自己flume安装路径下创建自己的配置文件文件夹myconf
mkdir /opt/installs/flume/myconf4.1 基础案例:Avro+Memory+Logger(测试验证,没有实战意义)
配置文件(avro_test.conf)
# 定义Agent名称
a1.sources = r1
a1.channels = c1
a1.sinks = k1
# 配置Avro Source
a1.sources.r1.type = avro
a1.sources.r1.bind = 192.138.139.128#自己的IP
a1.sources.r1.port = 44444
# 配置Memory Channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 配置Logger Sink
a1.sinks.k1.type = logger
# 绑定组件关系
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1启动命令
flume-ng agent -n a1 -c $FLUME_HOME/conf -f $FLUME_HOME/myconf/avro_test.conf -Dflume.root.logger=INFO,console
# -c 后面跟上 配置文件的路径
# -f 跟上自己编写的conf文件
# -n agent的名字
# -Dflume.root.logger=INFO,console INFO 日志输出级别 Debug,INFO,warn,error 等测试
# 使用telnet发送测试数据
telnet localhost 44444
> {"message":"hello flume"}4.2 生产级案例:Taildir+File+HDFS(实时日志采集)
tailDir 是用来监控多个文件夹下的多个文件的,只要文件内容发生变化,就会再次的进行数据的抽取
配置文件(taildir_hdfs.conf)
a1.sources = r1
a1.channels = c1
a1.sources.r1.type = TAILDIR
a1.sources.r1.channels = c1
a1.sources.r1.filegroups = f1
# . 代表的意思是一个任意字符 * 代表前面的字符出现0到多次
a1.sources.r1.filegroups.f1 = /home/scripts/datas/.*txt.*
a1.channels.c1.type = memory
a1.channels.c1.capacity = 10000
a1.channels.c1.transactionCapacity = 10000
a1.sinks = k1
a1.sinks.k1.type = hdfs
a1.sinks.k1.channel = c1
a1.sinks.k1.hdfs.path = /flume3/logstailDir 可以采集一个不断变化的文件,只要采集的文件内容不断变化,我们就可以将其不断的上传至hdfs。
flume-ng agent -c ./ -f taildir_memory_hdfs.conf -n a1 -Dflume.root.logger=INFO,console由于我们刚才的一些数据非常的大,根据如下参数可以疯狂创建文件:
hdfs.rollInterval 30
#当前文件写入达到该值时间后触发滚动创建新文件(0表示不按照时间来分割文件),单位:秒
hdfs.rollSize 1024
#当前文件写入达到该大小后触发滚动创建新文件(0表示不根据文件大小来分割文件),单位:字节
hdfs.rollCount 10
#当前文件写入Event达到该数量后触发滚动创建新文件(0表示不根据 Event 数量来分割文件)五、Flume 拦截器:数据清洗的瑞士军刀
Flume支持在运行时对Event进行修改或丢弃,可以通过拦截器来实现。
Event 就是数据,拦截住数据之后,可以修改它,也可以删除它。
5.1 内置拦截器应用
时间戳拦截器(Timestamp Interceptor)
这个拦截器会向每个Event的header中添加一个时间戳属性进去,key默认是“timestamp ”(也可以通过headerName参数来自定义修改),value就是当前的毫秒值(其实就是用System.currentTimeMillis()方法得到的)。 如果Event已经存在同名的属性,可以选择是否保留原始的值。
a1.sources = r1
a1.channels = c1
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /opt/data/c.txt
a1.sources.r1.channels = c1
a1.channels.c1.type = memory
a1.channels.c1.capacity = 10000
a1.channels.c1.transactionCapacity = 10000
a1.sinks = k1
a1.sinks.k1.type = hdfs
a1.sinks.k1.channel = c1
a1.sinks.k1.hdfs.path = /flume/events/%y-%m-%d/%H%M/
# round 用于控制含有时间转义符的文件夹的生成规则
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue = 10
a1.sinks.k1.hdfs.roundUnit = minute
# i1 是拦截器的名字,自己定义的
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = timestamp5.2 自定义拦截器开发(企业级必备技能)
需求:
处理数据样例:
log='{
"host":"www.baidu.com",
"user_id":"13755569427",
"items":[
{
"item_type":"eat",
"active_time":156234
},
{
"item_type":"car",
"active_time":156233
}
]
}'
结果样例:
[{"active_time":156234,"user_id":"13755569427","item_type":"eat","host":"www.baidu.com"},
{"active_time":156233,"user_id":"13755569427","item_type":"car","host":"www.baidu.com"}]开发步骤
- 创建 Maven 项目,添加依赖:
<dependencies>
<dependency>
<groupId>org.apache.flume</groupId>
<artifactId>flume-ng-core</artifactId>
<version>1.9.0</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.78</version>
</dependency>
</dependencies>2.实现拦截器接口
public class JsonParserInterceptor implements Interceptor {
private static final Logger LOG = LoggerFactory.getLogger(JsonParserInterceptor.class);
@Override
public void initialize() {
// 初始化操作
}
@Override
public Event intercept(Event event) {
try {
// 获取数据内容
byte[] body = event.getBody();
String json = new String(body, StandardCharsets.UTF_8);
// 解析JSON(示例:提取user_id)
JSONObject jsonObject = JSONObject.parseObject(json);
String userId = jsonObject.getString("user_id");
// 添加到headers
Map<String, String> headers = event.getHeaders();
headers.put("user_id", userId);
return event;
} catch (Exception e) {
LOG.error("JSON解析失败", e);
return null; // 解析失败则丢弃该Event
}
}
@Override
public List<Event> intercept(List<Event> events) {
List<Event> result = new ArrayList<>();
for (Event event : events) {
Event intercepted = intercept(event);
if (intercepted != null) {
result.add(intercepted);
}
}
return result;
}
@Override
public void close() {
// 资源释放
}
public static class Builder implements Interceptor.Builder {
@Override
public Interceptor build() {
return new JsonParserInterceptor();
}
@Override
public void configure(Context context) {
// 配置参数获取
}
}
}package com.bigdata;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONArray;
import com.alibaba.fastjson.JSONObject;
import java.util.ArrayList;
public class Main {
public static void main(String[] args) {
// 学习fastjson的用法
String log = "{\n" +
"\"host\":\"www.baidu.com\",\n" +
"\"user_id\":\"13755569427\",\n" +
"\"items\":[\n" +
" {\n" +
" \"item_type\":\"eat\",\n" +
" \"active_time\":156234\n" +
" },\n" +
" {\n" +
" \"item_type\":\"car\",\n" +
" \"active_time\":156233\n" +
" }\n" +
" ]\n" +
"}";
// json {} [{},{}]
// 将该json 字符串变为 一个个json 对象
// 将一个json字符串转换为json 对象
JSONObject jsonObject = JSON.parseObject(log);
// 从json 对象中获取值
String host = jsonObject.getString("host");
String userId = jsonObject.getString("user_id");
System.out.println(host);
System.out.println(userId);
// 从json 对象中获取json数组
JSONArray items = jsonObject.getJSONArray("items");
// 定义一个集合,将来把封装好的json 对象,放入进去
ArrayList<JSONObject> list = new ArrayList<>();
// 循环这个Array数组,得到更加详细的数据
for (Object item : items) {
JSONObject obj2 = JSON.parseObject(item.toString());
String active_time = obj2.getString("active_time");
String item_type = obj2.getString("item_type");
// 将解析出来的4个属性,全部放入一个json 对象中
JSONObject newObj = new JSONObject();
newObj.put("host", host);
newObj.put("user_id", userId);
newObj.put("active_time", active_time);
newObj.put("item_type", item_type);
list.add(newObj);
}
// 如何将一个集合,变为json 字符串
String jsonString = JSON.toJSONString(list);
System.out.println(jsonString);
}
}打包,上传至 flume 下的lib 下。
cp target/flume-interceptor-1.0-SNAPSHOT.jar $FLUME_HOME/lib/编写一个flume脚本文件 testInter.conf
a1.sources = s1
a1.channels = c1
a1.sinks = r1
a1.sources.s1.type = TAILDIR
#以空格分隔的文件组列表。每个文件组表示要跟踪的一组文件
a1.sources.s1.filegroups = f1
#文件组的绝对路径
a1.sources.s1.filegroups.f1=/home/b.log
#使用自定义拦截器
a1.sources.s1.interceptors = i1
a1.sources.s1.interceptors.i1.type = com.bigdata.DemoInterceptor$BuilderEvent
a1.channels.c1.type = file
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.sinks.r1.type = hdfs
a1.sinks.r1.hdfs.path = /flume/202409
a1.sinks.r1.hdfs.fileSuffix= .log
# 将上传的数据格式使用text类型,便于查看
a1.sinks.r1.hdfs.fileType=DataStream
a1.sinks.r1.hdfs.writeFormat=Text
a1.sources.s1.channels = c1
a1.sinks.r1.channel = c1
如何自定义时间戳拦截器
只需要在方法中添加如下代码
HashMap<String, String> hashMap = new HashMap<>();
hashMap.put("timestamp",System.currentTimeMillis()+"");
event.setHeaders(hashMap);六、总结与进阶方向
Flume 作为大数据生态中的 "数据搬运工",其核心价值在于:
- 提供标准化的数据采集接口
- 实现数据的可靠传输与缓冲
- 无缝对接多种数据源与数据目标
对于进阶学习者,建议从以下方向深入:
- 源码级理解 Flume 的事务机制
- 自定义组件开发(Source/Channel/Sink)
- 与 Kafka、Spark 等组件的深度集成
- 大规模集群下的性能调优与故障排查
通过本文的系统讲解,相信无论是零基础的萌新还是有一定经验的开发者,都能对 Flume 有全面的认识。在实际工作中,建议结合具体业务场景进行灵活配置与优化,让这一强大的日志收集工具发挥最大价值。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 21
21 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)