BigData | 大数据处理基本功(下)
? 学习笔记
还是对蔡老师的课程知识点进行巩固~
? Index
-
Workflow设计模式
-
发布/订阅模式
-
CAP定理
-
Lambda架构
-
Kappa架构
? Workflow设计模式
工作流系统(Workflow System)
指的是将多个不同的处理模块连接在一起,最后得出一个自己需要的结果的有向无环图(Directed Acyclic Graph/DAG)的系统。
4种 Workflow System的设计模式
-
复制模式(Copier Pattern)通常是将单个数据处理模块中的数据,完整地复制到两个或者更多的数据处理模块中,然后再由不同的数据处理模块进行处理,当我们需要对同一个数据集采取多种不同的数据处理转换时,就可以优先考虑这个模式。
-
过滤模式(Filter Pattern)其作用就是过滤掉不符合条件的数据,当我们需要针对一个数据集中的某些特定的数据采取数据处理时,就可以优先考虑这个模式。
-
分离模式(Splitter Pattern)当你想对数据集中的不同数据分别做不同的处理,需要注意,分离模式不会过滤任何数据,只是对数据做了分组,而且,同样的数据可以被划分到不同的数据处理模块。
-
合并模式(Joiner Pattern)会将多个不同的数据集转换集中在一起,成为一个总数据集,然后将这个总的数据集放在一个工作流中进行进行。
? 发布/订阅模式(Publish/Subscribe Pattern)
这个是流数据处理中很流行的设计模式,也经常被成为 Pub/Sub。
消息与消息队列
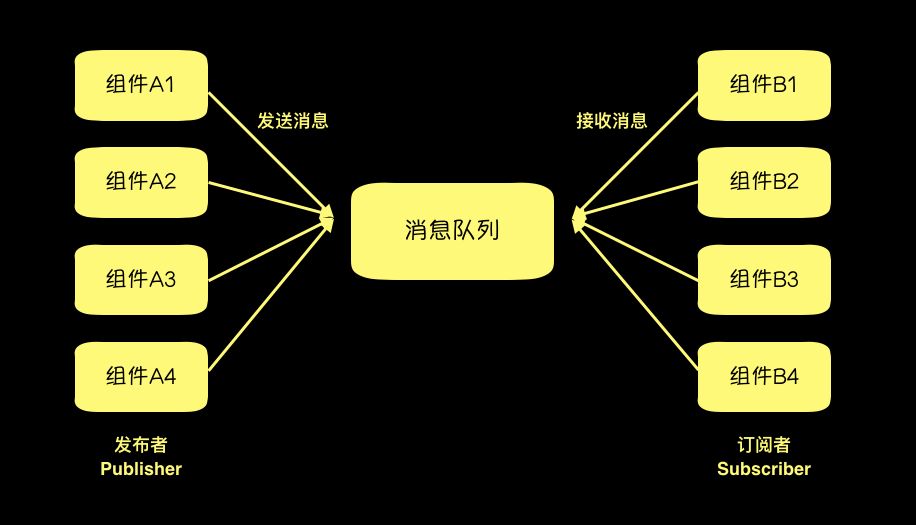
消息: 在分布式架构中,各个组件(Component)需要相互联系沟通,组件可以是后台的数据库,也可以是前端的浏览器,而各个组件之间就是依靠消息来相互通讯的,消息可以是任意格式。消息队列: 消息队列在Pub/Sub中起到的作用就是一个持久化缓冲(Durable Buffer)的作用。消息的发送方可以发送任意消息到这个消息队列中,消息队列在接受到消息之后就会将消息保存好,知道消息的接收方确认自己收到消息了,才删除。
发布/订阅模式
基础概念: 发布/订阅模式指的是消息的发送方可以将消息异步地发送给一个系统中不同的组件,而无需知道接收方是谁。发送方被称之为发布者(Publisher),接收方则称作订阅者(Subscriber)。
优点:
-
松耦合(Loose Coupling):消息的发布者与消息的订阅者在开发的时候完全不需要事先知道对方的存在,可以独立开发。
-
高伸缩性(High Scalability):发布/订阅模式中的消息队列可以独立的座位一个数据存储中心存在,在分布式环境中,消息队列更是可以扩展至上千个服务器中。
-
组件间通信更简洁:因为不需要单独对某个订阅者准备消息格式,只需要一开始定义好一个消息格式,后续订阅者只需按照这个格式去接收消息。
缺点:
-
该模式不能保证发布者发送的数据一定会送法订阅者,往往需要开发者自己实现响应机制。
适用场景:
-
系统的发送方需要向大量的接收方广播消息。
-
系统中某一个组件需要与多个独立开发的组件或者服务进行通信,而这些独立开发的组件或者服务使用着不一样的编程语言和通信协议。
-
系统的发送方在向接收方发送消息之后无需接收方进行实时响应。
-
系统中对数据一致性的要求只需数据的最终一致性(Eventual Consistency)即可。
? CAP定理
CAP这个概念是由埃里克·布鲁尔博士在2000年的ACM年度学术研讨会上提出的,发布了论文《Brewer's conjecture and the Feasibility of Consistent,Available,Partition-Tolerant Web Services》。
简单来说,论文中证明了:
在任意的分布式系统中,一致性(Consistency),可用性(Availability)和分区容错性(Partition-tolerance)这3种属性最多只能同时存在两个属性。
下面简单介绍一下这3个属性:

-
C属性(一致性): 所有分布式环境下的操作都像是在单机上完成一样。
-
A属性(可用性): 指的是在分布式系统中,任意非故障的服务器都必须对客户的请求产生响应,不管出现什么状况(除非所有的服务器都奔溃),不然都能返回消息。
-
P属性(分区容错性): 如果系统中出现了某些错误,导致部分节点之间无法连通,造成网络被分成了几块单独的区域,就是我们说的分区错误。分区容错指的是即便出现这样子的错误,系统也必须能够返回消息。
衍生的系统:
-
CP系统: Google BigTable、Hbase、MongoDB、Redis、MemCacheDB
-
AP系统: Amazon Dynamo、Apache Cassandra、Voldemort
-
CA系统: Apache Kafka
放弃了P属性的Kafka
Kafka0.8版本引入了Replication,它通过将数据复制到不同的节点上,从而增强了数据在系统中的持久性(Durability)和可用性(Availability),系统设计所有的数据日志存储在同一个数据中心,也就是说出现网络分区错误的可能性很小。
在具体的架构中,中Kafka数据副本(Data Replication)的设计中,先通过Zookeeper选举出一个领导者节点(Leader)。这个领导者节点负责维护一组被称作同步数据副本(In-sync-replica)的节点,所有的数据写入都必须在这个领导者节点中记录。
正常情况下,领导者节点在收到请求后先本地保存好,然后发消息通知副本进行存储,并回复用户写入成功,即便所有的Replication都挂了,也还有领导者节点可以用,万一连领导者节点都挂了,这个时候Zookeeper会重新区寻找健康的服务器节点当选新的领导者节点。
? Lambda架构
Lambda架构可以使得开发人员构建大规模分布式数据处理系统,它具有很好的饿灵活性和可扩展性,对硬件故障和人为失误有很好的容错性。
Lambda架构总共由三层系统组成:批处理层(Batch Layer)、速度处理层(Speed Layer)、服务层(Serving Layer)。
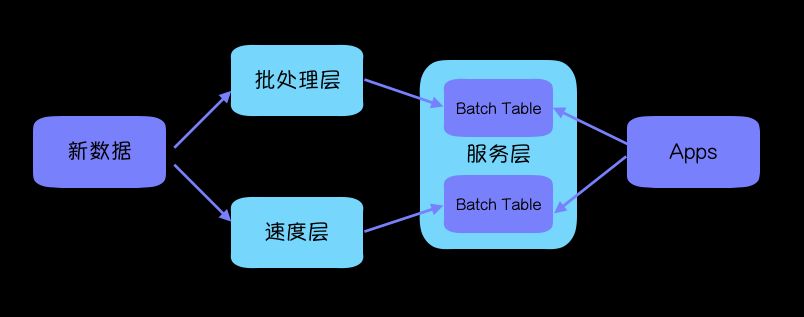
不同的系统层都有着自己的"职责":
-
批处理层: 存储管理主数据集(不可变的)和预先批处理计算好的试图,通过对已有历史数据来计算,所以它具有更高的准确性,但实效性方面就十分欠缺。
-
速度处理层: 实时处理新来的大数据,提供实时试图,虽然速度快,但是数据并不是全量数据,所以结果只能作一定的参考价值。
-
服务层: 接收所有在批处理层和速度处理层的处理结果,从而来响应用户的查询。
案例分析:
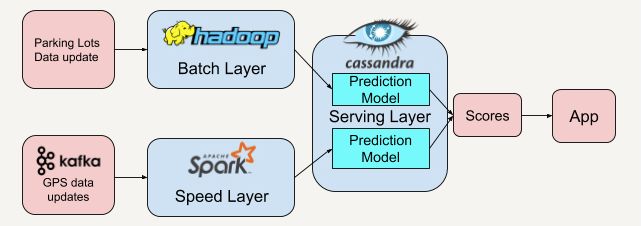
Smart Parking是一个智能的停车APP,它通过大规模数据所构建的视图推荐最近的车位给用户,如何应用Lambda架构呢?
批处理层: 把停车场的历史数据或者每隔半小时拿到的停车位数据,构建一个预测模式,预测剩余车位。
速度处理层: 聚集所有用户的GPS数据,再次建立一套预测模型来预测附近停车场位置的拥挤程度。
服务层: 将批处理层和速度处理层得到的预测分数进行结合,并将最高分数的停车场推荐给用户,从而提高推荐的准确率。
? Kappa架构
为什么会存在Kappa架构呢,是因为Lambda架构也有不足之处,简单来说就是维护复杂,因为Lambda架构中有两个完全不同的分布式系统,一个是批处理一个是流处理的,所以它们的语法不一样,但又得保证它们的逻辑上要产生相同的结果输出给服务层(比如部署Apache Hadoop到批处理层,部署Apache Flink到速度层)。
Kappa架构就是改进了其中某一层的架构,让它具有另外一层架构的特性。
下面用Apache Kafka流处理平台来讲解:
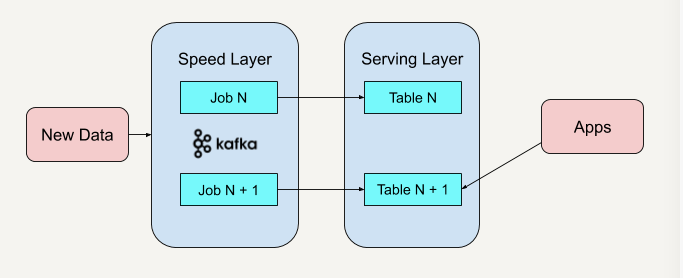
先前我们有说过,Apache Kafka平台具有永久保存数据日志的功能,所以我们可以删除批处理层,只是保留流处理层。
Step1: 部署Apache Kafka,并设置数据日志的保留期(Retention Period),一般可以设置为Forever;
Step2: 重新启动一个Apache Kafka作业实例,这个实例重头开始计算保存好的历史数据,并将结果输出到一个新的数据视图中;
Step3: 当这个心的数据视图处理过的数据进度赶上了旧的数据视图时,我们的应用便可以切换到从新的数据视图中读取;
Step4: 停止旧版本的作业实例,并删除旧的数据视图。
其架构如下图所示:
? References
-
百度百科
-
蔡元楠-《大规模数据处理实战》07-11小节 —— 极客时间

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)