数据库:五范式(1NF,2NF,3NF,BCNF,4NF)
在这篇博客中,我们将深入探讨数据库设计中的五大范式:第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、Boyce-Codd范式(BCNF)和第四范式(4NF)。通过详尽的解释和实用的例子,我们将揭示这些范式在数据库规范化过程中的关键作用,帮助您理解如何优化数据库结构,提高数据一致性和查询效率。不论您是数据库新手还是经验丰富的开发者,这篇博客将为您提供宝贵的见解和实用的技巧,让您的数据库设
1,问题的提出
1.1,问题
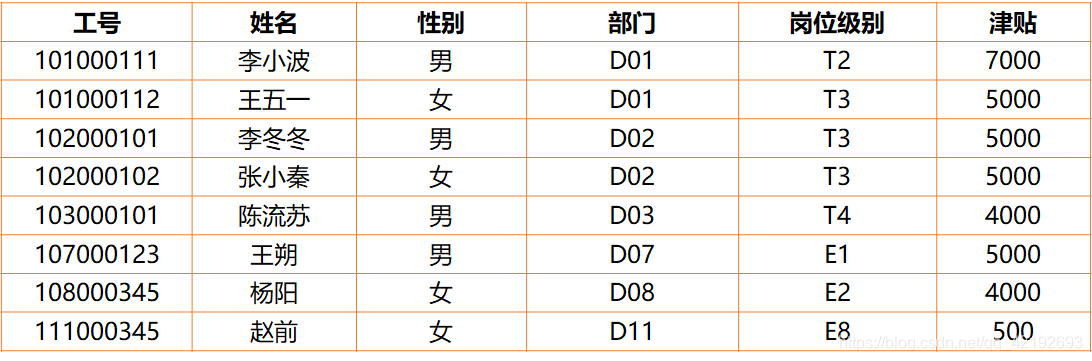
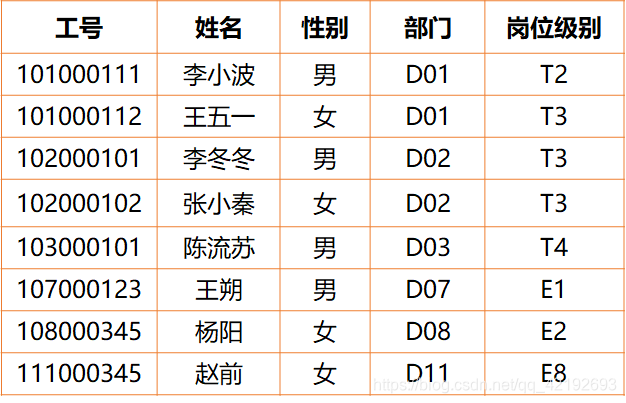
【例】:考虑为管理教职工聘岗信息及岗位津贴信息而设计关系模式。
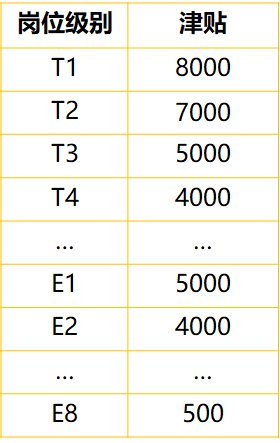
业务规则:每个教职工聘一个岗位,每个岗位对应唯一的津贴。(岗位T1-T8,E1-E8)
【问题】 :
- 插入异常:T1岗津贴8000,假如没有人应聘,则该岗位信息不能插入关系。
- 数据冗余:T3岗工津贴5000,岗位信息重复多次。
- 更新异常:将T3岗津贴由5000调整为5500,需要修改多次。
- 删除异常:如果只有赵前一个人应聘E8,赵前辞职,删除赵前个人信息的同时也删除了E8岗的信息。
【解决】:分解成两个表
1.2,概念回顾
关系:描述实体、属性、实体间的联系。从形式上看,它是一张二维表,是所涉及属性的笛卡尔积的一个子集。
关系模式:用来定义关系。
关系数据库:基于关系模型的数据库,利用关系来描述现实世界。从形式上看,它由一组关系组成。
关系数据库的模式:定义这组关系的关系模式的全体,关系模式的集合。
关系模式由五部分组成,即它是一个五元组: R(U, D, DOM, F)
★R:关系名
★U:组成该关系的属性名集合
★D:属性组U中属性所来自的域
★DOM:属性向域的映象集合
★F:属性间数据的依赖关系集合
1.3,数据依赖
数据依赖:一个关系中的属性相互之间存在联系(主要体现于值的相等与否)。
- 数据依赖是现实世界属性间相互联系的抽象
- 数据依赖是数据内在的性质
- 数据依赖是语义的体现
- 数据依赖的主要类型:函数依赖和多值依赖
1.4,数据依赖对关系模式的影响
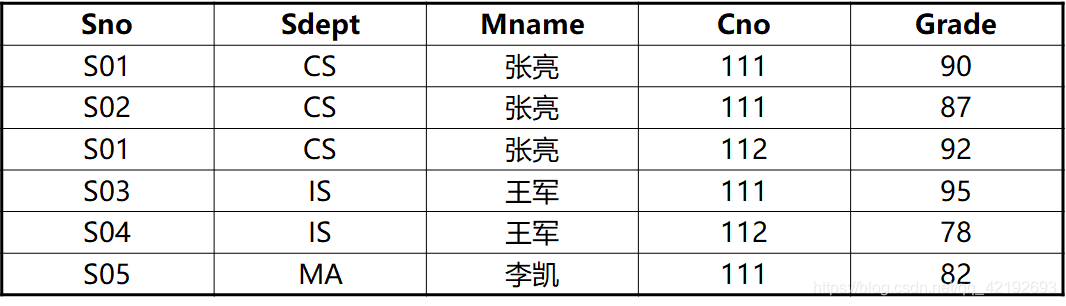
【例】建立一个描述学校教务的数据库。
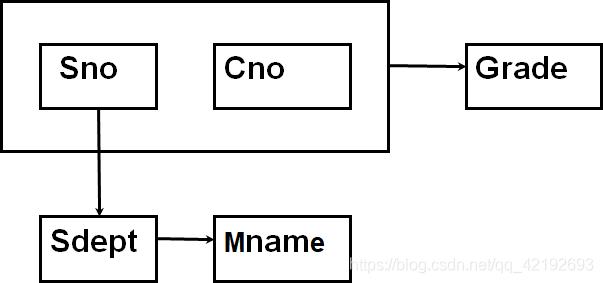
对象:学生的学号(Sno)、所在系(Sdept)、系主任姓名(Mname)、课程号(Cno)、成绩(Grade)语义:一个系有若干学生, 一个学生只属于一个系;一个系只有一名主任(正职);一个学生可以选修多门课程, 每门课程有若干学生选修;每个学生所学的每门课程都有一个成绩。
依赖: F={Sno→Sdept, Sdept→ Mname, (Sno, Cno)→ Grade}
问题:
- 数据冗余:浪费大量的存储空间。【例】每一个系主任的姓名重复出现,重复次数与该系所有学生的所有课程成绩出现次数相同。
- 更新异常:数据冗余 ,更新数据时,维护数据完整性代价大。【例】某系更换系主任后,系统必须修改与该系学生有关的每一个元组
- 插入异常:该插入的数据插不进去。【例】如果一个系刚成立,尚无学生,则无法把这个系及其系主任的信息存入数据库。
- 删除异常:不该删除的数据不得不删。【例】如果某个系的学生全部毕业了, 则在删除该系学生信息的同时,把这个系及其系主任的信息也丢掉了。
结论:Student关系模式不是一个好的模式。一个“好”的模式应当不会发生插入异常、删除异常和更新异常,数据冗余应尽可能少。
原因:由存在于模式中的某些数据依赖引起的。
解决办法:用规范化理论改造关系模式来消除其中不合适的数据依赖把这个单一的模式分成三个关系模式:
S(Sno,Sdept,Sno → Sdept); SC(Sno,Cno,Grade,(Sno,Cno) → Grade); DEPT(Sdept,Mname,Sdept → Mname);
2,规范化
2.1,函数依赖
设R(U)是一个属性集U上的关系模式,X和Y是U的子集。若对于R(U)的任意一个可能的关系r,r中不可能存在两个元组在X上的属性值相等, 而在Y上的属性值不等, 则称“X函数确定Y” 或 “Y函数依赖于X”,记作X→Y。 X称为这个函数依赖的决定属性集。
张三,李四不满足函数依赖。
说明:①函数依赖不是指关系模式R的某个或某些关系实例满足的约束条件,而是指R的所有关系实例均要满足的约束条件。②函数依赖是语义范畴的概念。只能根据数据的语义来确定函数依赖。
2.2,平凡函数依赖和非平凡函数依赖
在关系模式R(U)中,对于U的子集X和Y:
- 如果X→Y,但Y⊈X则称X→Y是非平凡的函数依赖
- 若X→Y,但Y ⊆ X, 则称X→Y是平凡的函数依赖
【例】:在关系SC(Sno, Cno, Grade)中, 非平凡函数依赖: (Sno, Cno) → Grade 平凡函数依赖: (Sno, Cno) → Sno 、 (Sno, Cno) → Cno对于任一关系模式,平凡函数依赖都是必然成立的,它不反映新的语义。若不特别声明, 我们总是讨论非平凡函数依赖。
2.3,函数依赖的确定
只能根据现实世界的数据语义确定,函数依赖的确定实际上是对现实世界数据的联系的论断,要根据数据的客观存在的联系和企业(组织)的管理规章制度来确定。
函数依赖一旦确定,任何时候(过去、现在、将来)的所有关系实例都应满足这个函数依赖。
- 对于实际问题,根据实际背景、数据约束的语义确定。
- 形式化问题,用定义验证,用推理系统推导。
- 具体的关系实例,分析属性值的情况确定。
2.4,完全函数依赖与部分函数依赖
X只由一个属性组成,则X→Y必定是完全函数依赖;X是多属性组成,才考虑X→Y是否是部分函数依赖。

2.5,传递函数依赖

2.6,码
| 候选码 | |
| 超码 | 如果U部分函数依赖于K,即K→U,则K称为超码。候选码是最小的超码,即K的任意一个真子集都不是候选码。 |
| 主码 | 若关系模式R有多个候选码,则选定其中的一个做为主码 |
| 主属性 | 包含在任何一个候选码中的属性,称作主属性。 |
| 非主属性 | 不包含在每一个候选码中的属性,称作非主属性。 |
| 全码 | 关系模式的码由整个属性组构成。 |
| 外码 | 关系模式R中属性或属性组X并非R的码,但X是另一个关系模式的码,则称 X是R的外部码也称外码。 |
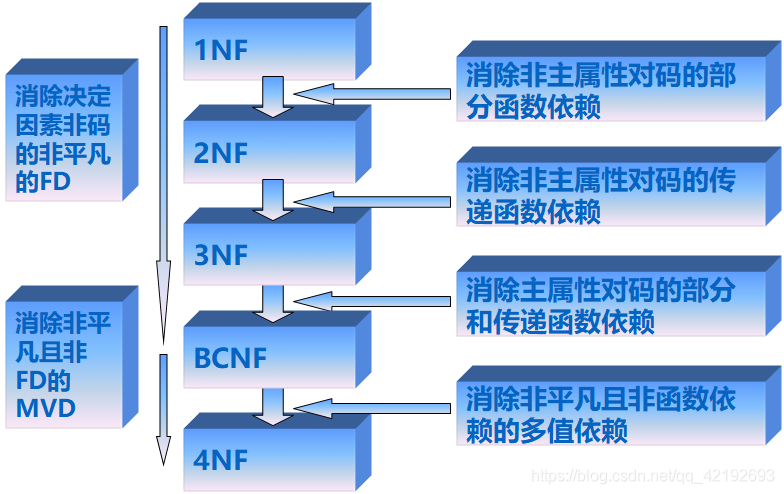
3,范式
规范化的关系简称范式,范式是对关系的不同数据依赖程度的要求。关系数据库中的关系必须满足一定的要求,满足不同程度要求的为不同范式。
当设计关系型数据库时,需要遵从不同的规范要求,设计出合理的关系型数据库,这些不同的规范要求被称为不同的范式(Normal Form),越高的范式,数据库冗余越小。应用数据库范式可以带来很多好处:消除重复数据,减少数据冗余,让数据库内的数据更好地组织,让磁盘空间得到更有效地利用。而其缺点是:范式使查询变得相当复杂,在查询时需要更多的连接,一些复合索引的列由于规范化的需要被分割到不同的表中,导致索引策略不佳。
范式的分类:第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、BC范式(BCNF)、第四范式(4NF)、第五范式(5NF)。
3.1,1NF
如果一个关系模式R的所有属性都是不可分的基本数据项,则R∈1NF。(即:即不能以集合、序列等作为属性值; 不能有大表套小表的情况)第一范式是对关系模式的最起码的要求。不满足第一范式的数据库模式不能称为关系数据库。但是满足第一范式的关系模式并不一定是一个好的关系模式。
分量是否需要再分,与具体应用有关。如果用到值的一部分,则需要进一步分割。


3.2,2NF
若关系模式R∈1NF,并且每一个非主属性都完全函数依赖于任何一个候选码,则R∈2NF。
2NF的定义要求消除非主属性对码的部分依赖
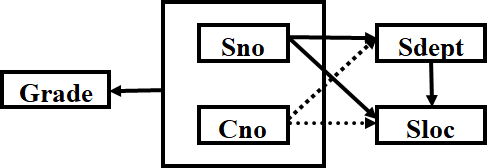
【例】: SLC(Sno,Sdept,Sloc,Cno,Grade), Sloc为学生的住处,并且每个系的学生住在同一个地方。 SLC的码为(Sno,Cno)。函数依赖有 (Sno,Cno) →(F)→ Grade Sno → Sdept, (Sno,Cno) →(P)→ Sdept Sno → Sloc, (Sno,Cno) →(P)→ Sloc Sdept → Sloc
非主属性Sdept、Sloc并不完全依赖于码,关系模式SLC不属于2NF。一个关系模式不属于2NF,会产生以下问题:
- 插入异常:如果插入一个新学生,但该生未选课,即该生无Cno,由于插入元组时,必须给定码值,因此插入失败。
- 删除异常:如果S4只选了一门课C3,现在他不再选这门课,则删除C3后,整个元组的其他信息也被删除了。
- 数据冗余度大:如果一个学生选修了10门课程,那么他的Sdept和Sloc值就要重复存储了10次。
- 修改复杂:如果一个学生选了多门课,则Sdept,Sloc被存储了多次。如果该生转系,则需要修改所有相关的Sdept和Sloc,造成修改的复杂化。
原因:非主属性有两种情况,一种完全依赖于码; 一种部分依赖于码 。
解决方法:用投影分解把关系模式S-L-C分解成两个关系模式:SC(Sno,Cno,Grade),S-L(Sno,Sdept,Sloc)。
结论:
- 不存在非主属性的关系模式属于2NF。
- 全码关系模式属于2NF。
- 码只由一个属性组成的关系模式属于2NF。
- 二目关系模式属于2NF。
- 若R属于1NF,但R不一定属于2NF。
将一个1NF关系分解为多个2NF的关系,并不能完全消除关系模式中各种异常情况和数据冗余。
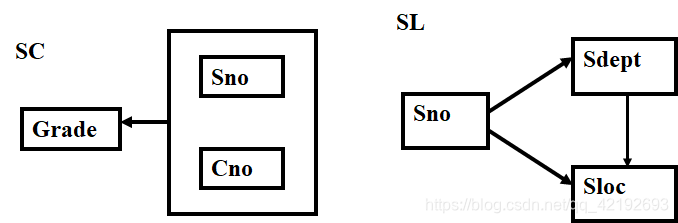
3.3,3NF
设关系模式R<U,F>∈1NF,若R中不存在这样的码X、属性组Y及非主属性Z(Z ⊇ Y), 使得X→Y,Y→Z成立,Y↛X不成立,则称R<U,F>∈3NF。
3NF的定义要求消除非主属性对码的传递依赖
【例】: 2NF关系模式SL(Sno, Sdept, Sloc)中函数依赖有 Sno→Sdept Sdept→Sloc Sno → Sloc
Sloc传递函数依赖于Sno,即SL中存在非主属性对码的传递函数依赖。SL不是一个好的关系模式,会产生以下问题:
- 插入异常:如果系中没有学生,则有关系的信息就无法插入。
- 删除异常:如果学生全部毕业了,则在删除学生信息的同时有关系的信息也随之删除了。
- 数据冗余度大:每个学生都存储了所在系的住处信息。
- 修改复杂:如果学生转系,不但要修改Sdept,还要修改Sloc,如果系的住房调整,则该系每个学生元组都要做相应修改。
解决方法:采用投影分解法,把SL分解为两个关系模式,以消除传递函数依赖,SD(Sno, Sdept)DL(Sdept, Sloc)SD的码为Sno, DL的码为Sdept。
结论:
- 不存在非主属性的关系模式属于3NF。
- 全码关系模式属于3NF。
- 二目关系模式属于3NF。
- 若R属于3NF,那么R也属于2NF。
- 若R属于2NF,但R不一定属于3NF。
将一个2NF关系分解为多个3NF的关系,并不能完全消除关系模式中各种异常情况和数据冗余。
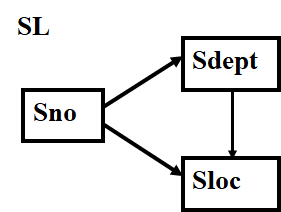
3.4,BCNF
设关系模式R<U,F>∈1NF,如果对于R的每个函数依赖X→/Y,若Y⊆X,则X必含有候选码,那么R∈BCNF
BCNF的定义排除了任何属性(不管是主属性还是非主属性)对码的传递和部分依赖。如果一个关系数据库中的所有关系模式都属于BCNF,那么在函数依赖范畴内,它已实现了模式的彻底分解,达到了最高的规范化程度,消除了插入异常和删除异常。
BCNF的定义更简单,不需要从1NF到2NF再到3NF再到BCNF一步步检查,也不涉及完全、部分和传递函数依赖等概念,可以直接判断一个1NF的关系是否属于BCNF。
BCNF的关系模式所具有的性质
- 所有非主属性对每一个码都是完全函数依赖,即, 若R ∈ BCNF, 则R ∈ 2NF。
- 所有的主属性对每一个不包含它的码也是完全函数依赖。
- 没有任何属性完全函数依赖于非码的任何一组属性。
- 若R ∈ BCNF, 则必有R ∈ 3NF; 反之不一定成立。
【例】:在关系模式STJ(S,T,J)中,S表示学生,T表示教师,J表示课程。 每一教师只教一门课。每门课由若干教师教,某一学生选定某门课,就确定了一个固定的教师。 某个学生选修某个教师的课就确定了所选课的名称 : (S,J)→T,(S,T)→J,T→J
STJ是3NF :(S,J)和(S,T)都可以作为候选码。S、T、J都是主属性。
STJ不是BCNF:T→J,T是决定属性集,T不是候选码,存在主属性对码的传递部分依赖。
问题:
- 插入异常:如果没有学生选修某位老师的任课,则该老师担任课程的信息就无法插入。
- 删除异常:删除学生选课信息,会删除掉老师的任课信息。
- 数据冗余度大:每位学生都存储了有关老师所教授的课程的信息。
- 修改复杂:如果老师所教授的课程有所改动,则所有选修该老师课程的学生元组都要做改动。
原因:主属性对码的不良依赖
解决方法:将STJ分解为二个关系模式:SJ(S,J) ∈ BCNF, TJ(T,J)∈ BCNF
没有任何属性对码的部分函数依赖和传递函数依赖
结论:
- 全码关系模式属于BCNF。
- 二目关系模式属于BCNF。
- 不存在函数依赖的关系模式属于BCNF。
- 若R属于BCNF,那么R也属于3NF。
- 若R属于3NF,但R不一定属于BCNF。
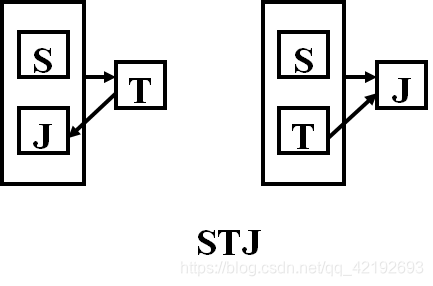
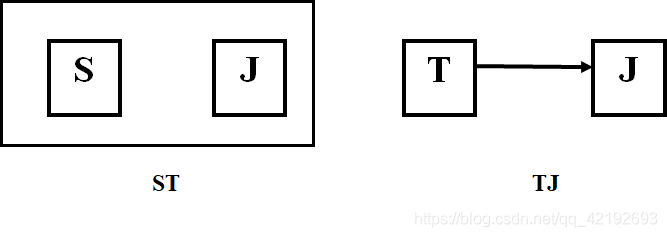
3.5,4NF
多值依赖:设R(U)是属性集U上的一个关系模式。X,Y,Z是U的子集,并且Z=U-X-Y。关系模式R(U)中多值依赖X→→Y成立,当且仅当对R(U)的任一关系r,给定的一对(x,z)值,有一组Y的值,这组值仅仅决定于x值而与z值无关。
若X→→Y,而Z=Ф,即Z为空,则称X→→Y为平凡的多值依赖。否则称X→→Y为非平凡的多值依赖。
【例】: (C,B)上的一个值(物理,光学原理)对应一组T值(李平,王强,刘明), 这组值仅仅决定于课程C上的值,也就是说对于(C,B)上的另一个值(物理,普通物理学), 它对应的一组T值仍是(李平,王强,刘明),尽管这时参考书B的值已经改变了。因此T多值依赖于C,即C→→T。
4NF:关系模式R<U,F>∈1NF,如果对于R的每个非平凡多值依赖X→→Y(Y ⊈ X),X都含有码,则R<U,F>∈4NF。
说明:
- 定义中的F是数据依赖集, 包括FD和MVD; 当F只包含FD时, 4NF的定义就是BCNF的定义。
- 4NF是BCNF的推广, 适用于具有多值依赖的关系模式。
- ★4NF的定义就是限制关系模式的属性之间不允许有非平凡且非函数依赖的多值依赖的存在。
- 如果一个关系模式是4NF, 则必为BCNF。
【例】关系模式 WSC,有W →→ S,W →→ C,码为(W, S, C), 所以 WSC不属于4NF, 但 WSC 属于BCNF。
如果仓库Wi有n个保管员,存放m件商品,则关系中分量为Wi的元组共有m×n个,每个保管员重复存储m次,每种商品重复存储n次, 数据冗余非常大。
增删也不便, 增加商品, 取消保管员都必须增删若干元组。
解决办法:将WSC分解为WS(W,S)和WC(W,C) 分解后的关系模式都属于4NF,因为只有平凡的多值依赖W →→ S和W →→ C,满足4NF的定义。
3.6,反范式
数据库设计要严格遵守范式,这样设计出来的数据库,虽然思路清晰,结构也很合理,但是有时候却要在一定程度上打破范式设计。因为范式越高,设计出来的表可能越多,关系可能越复杂,但是性能却不一定很好,因此表一多,就增加了关联性。特别是在高可用的OLTP数据库中,这一点表现得很明显,所以就引入了反范式。
不满足范式的模型就是反范式模型。反范式跟范式所要求的正好相反,在反范式的设计模式中,可以允许适当的数据冗余,用这个冗余可以缩短查询获取数据的时间。反范式其本质上就是用空间来换时间,把数据冗余在多个表中,当查询时就可减少或者避免表之间的关联。反范式技术也可以称为反规范化技术。
反范式:
- 优点:减少了数据库查询时表之间的连接次数,可以更好地利用索引进行筛选和排序,从而减少I/O数据量,提高查询效率。
- 缺点:数据存在重复行和冗余,存在部分空间浪费。另外,为了保持数据的一致性,则必须维护这部分冗余数据,增加了维护的复杂性。所以,在进行范式设计时,要在数据一致性和查询之间找到平衡点,因为符合业务场景的设计才是最好的设计。
范式:
- 优点:数据没有容易,更新容易。
- 缺点:当表的数量比较多时,查询设计需要很多关联模型(join)时,会导致查询性能低下。
在RDBMS模型设计过程中,常常使用范式来约束模型,但在NoSQL模型中则大量采用反范式,常用的数据库反范式技术包括:
- 增加冗余列:在多个表中保留相同的列,以减少表连接的次数。冗余法以空间换取时间,把数据冗余在多个表中,当查询时可以减少或者避免表之间的关联。
- 增加派生列:表中增加可以由本表或者其他表中数据计算生成列,减少查询时的连接操作并避免计算或者使用集合函数。
- 表水平分割:根据一列或者多列的值将数据放到多个独立的表中,主要用于表的规模很大、表中数据相对独立或数据需要存放到多个介质的情况。
- 表垂直分割:对表按列进行分割,将主键和一部分列放到一个表中,主键余其他列放到另一个表中,在查询时减少I/O次数。
例如:有学生表和课程表,假定课程表需要经常被查询,而且在查询中要显示学生的姓名,则查询语句为:
select code,name,subject from course c, student s where s.id = c.code and code = ?如果这个语句被大范围、高频率执行,那么可能会因为表关联造成一定程度的影响。现在,假定评估到学生改名的需求是非常少的,那么,就可以把学生姓名冗余到课程表中。
select code,name,subject from course c where code=?

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 3
3 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)