使用Istio+Prometheus+Grafana+Loki+Alertmanager构建数据库统一治理平台
数据库统一治理平台通过整合Istio、Prometheus、Grafana、Loki和Alertmanager等开源工具,为qfusion平台上的20多款数据库提供了全面的监控、日志管理、告警和可视化能力。这一平台的实施将显著提升数据库运维的效率和质量,降低运维成本,提高服务的可用性和性能,为业务系统的稳定运行提供强有力的支持。统一管理:通过单一的平台管理所有数据库,降低了管理复杂度全面监控:提供
目录标题
使用Istio+Prometheus+Grafana+Loki+Alertmanager构建数据库统一治理平台
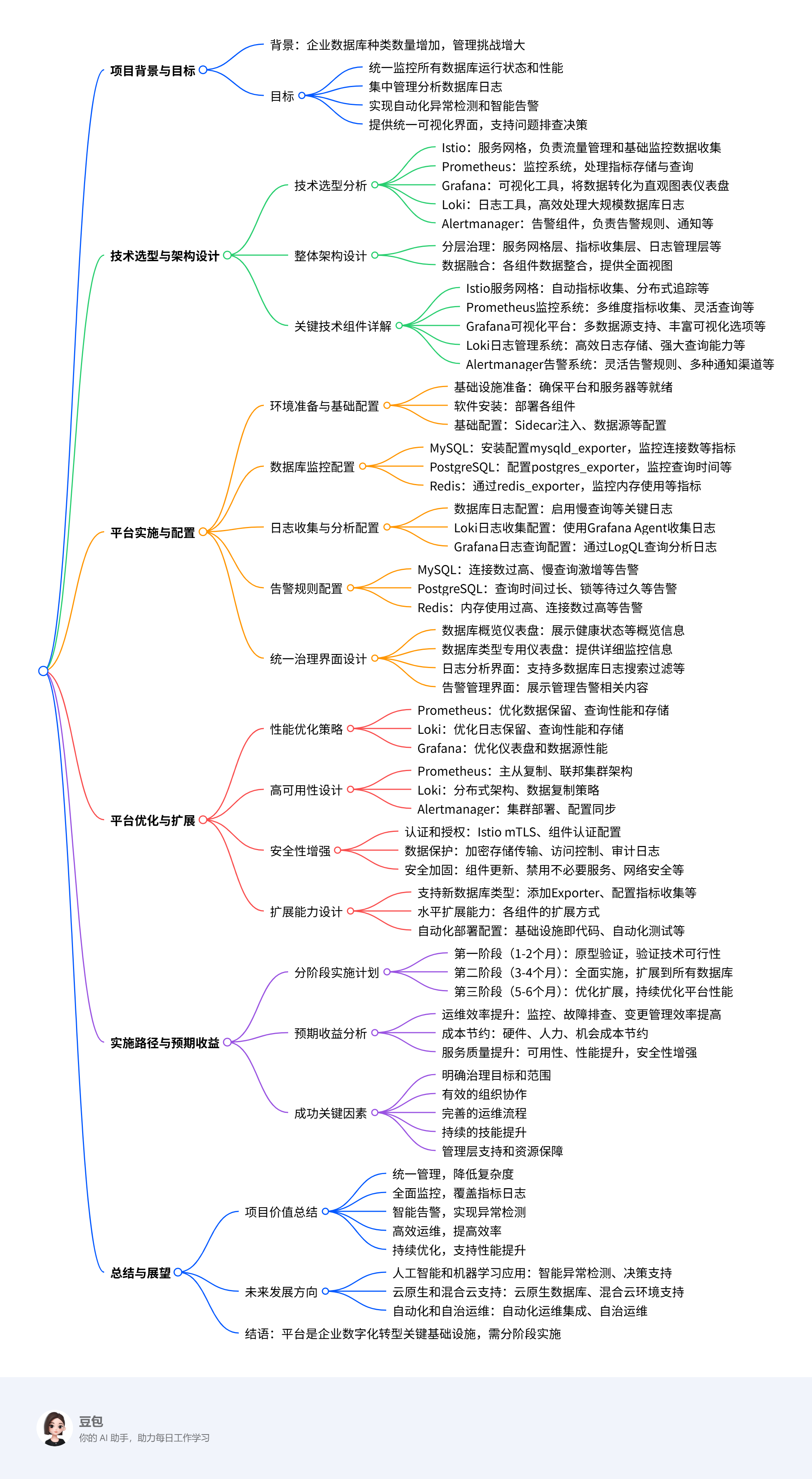
一、项目背景与目标
在当今数字化转型的关键时期,企业级应用对数据库的依赖日益增强,数据库的稳定性、性能和安全性直接影响业务的连续性和用户体验。随着云计算和微服务架构的普及,数据库的种类和数量不断增加,给运维团队带来了前所未有的管理挑战。
QFusion平台作为企业核心数据基础设施,目前运行着20多款不同类型的数据库和服务组件。这些数据库包括关系型数据库(如MySQL、PostgreSQL、SQL Server)、NoSQL数据库(如MongoDB、Redis)、时序数据库(如InfluxDB)以及其他特殊用途的数据库。面对如此多样化的数据库环境,传统的分散管理模式已经无法满足高效运维的需求,亟需建立一套统一的数据库治理平台。
本项目旨在构建一个基于Istio、Prometheus、Grafana、Loki和Alertmanager的数据库统一治理平台,实现对QFusion上所有数据库的全面监控、性能分析、日志管理和异常告警。通过这一平台,运维团队能够:
- 统一监控所有数据库的运行状态和性能指标
- 集中管理和分析数据库日志
- 实现自动化的异常检测和智能告警
- 提供统一的可视化界面,方便运维人员进行问题排查和决策支持
这一平台将显著提升数据库运维的效率和质量,降低运维成本,为业务系统的稳定运行提供强有力的支持。
二、技术选型与架构设计
2.1 技术选型分析
在构建数据库统一治理平台时,我们需要选择合适的技术工具来满足监控、日志管理、告警和可视化的需求。以下是对关键技术组件的选型分析:
Istio:作为服务网格解决方案,Istio提供了强大的流量管理、安全和可观察性功能。它可以自动收集服务间通信的详细指标,并与Prometheus集成,为数据库服务提供了天然的监控基础。Istio的主要优势在于其对服务网格的全面支持,可以轻松地将数据库服务纳入统一的治理体系。
Prometheus:作为领先的开源监控系统,Prometheus具有强大的指标收集和查询能力。它提供了丰富的客户端库和Exporter生态系统,几乎支持所有主流数据库的监控。Prometheus的时间序列数据库和PromQL查询语言为数据库性能分析提供了坚实的技术基础。
Grafana:作为专业的可视化工具,Grafana与Prometheus无缝集成,能够将枯燥的指标数据转化为直观的图表和仪表盘。Grafana的模板功能和丰富的插件生态系统使其非常适合构建统一的数据库监控界面。
Loki:作为专门为日志设计的工具,Loki具有高效的日志存储和查询能力。与传统的ELK Stack相比,Loki更加轻量级且易于扩展,特别适合处理大规模的数据库日志。
Alertmanager:作为Prometheus的告警组件,Alertmanager提供了灵活的告警规则定义、分组、抑制和通知功能。它可以根据数据库的指标变化自动触发告警,并通过多种渠道通知运维人员。
2.2 整体架构设计
基于上述技术选型,我们设计了以下数据库统一治理平台架构:
+-------------------+
| 数据库服务集群 |
| (MySQL, PostgreSQL, Redis等) |
+--------+----------+
|
+--------v----------+
| Istio Service Mesh |
| (数据面+控制面) |
+--------+----------+
|
+--------v----------+
| Prometheus Server |
| (指标存储与查询) |
+--------+----------+
|
+--------v----------+
| Grafana Dashboard |
| (可视化界面) |
+--------+----------+
|
+--------v----------+
| Loki Logging System |
| (日志存储与查询) |
+--------+----------+
|
+--------v----------+
| Alertmanager |
| (告警管理) |
+--------+----------+
|
+--------v----------+
| 通知渠道 |
| (邮件、短信、IM等) |
+-------------------+
这一架构的核心设计理念是分层治理和数据融合:
-
服务网格层:Istio作为底层基础设施,负责数据库服务的流量管理和基础监控数据收集。通过Istio的Sidecar注入机制,所有数据库服务自动获得监控能力,无需修改应用代码。
-
指标收集层:Prometheus作为核心监控系统,负责收集、存储和查询所有数据库的性能指标。通过使用Prometheus的Service Discovery机制,可以动态发现和监控新增的数据库实例。
-
日志管理层:Loki专门负责数据库日志的收集、存储和查询。通过统一的日志格式和标签体系,实现了不同类型数据库日志的集中管理。
-
可视化层:Grafana作为统一的展示平台,将Prometheus的指标数据和Loki的日志数据进行整合,提供直观的仪表盘和分析工具。
-
告警管理层:Alertmanager负责定义告警规则、触发告警通知,并通过多种渠道及时通知运维人员。通过合理设置告警规则,可以实现对数据库异常的快速响应。
2.3 关键技术组件详解
2.3.1 Istio服务网格
Istio在数据库统一治理平台中扮演着基础架构的角色,它提供了以下关键功能:
-
自动指标收集:Istio会自动收集服务间通信的详细指标,包括请求成功率、延迟、流量等,这些指标对于监控数据库服务的健康状态非常有价值。
-
分布式追踪:Istio可以为数据库请求生成分布式追踪ID,这对于排查跨服务的性能问题非常有帮助。通过与Prometheus和Loki的集成,可以实现指标与日志的关联分析。
-
安全通信:Istio提供了强大的安全功能,包括mTLS认证和细粒度的访问控制,可以确保数据库服务之间的通信安全。
-
流量管理:通过Istio的流量管理功能,可以实现数据库服务的负载均衡、故障转移和金丝雀发布,提高数据库服务的可用性和稳定性。
在数据库治理平台中,Istio主要用于监控数据库服务之间的通信,以及数据库服务与应用服务之间的交互。通过Istio的监控数据,可以快速发现数据库连接问题、性能瓶颈和安全隐患。
2.3.2 Prometheus监控系统
Prometheus是数据库统一治理平台的核心组件,负责指标的收集、存储和查询。在这一架构中,Prometheus的主要功能包括:
-
多维度指标收集:通过使用Prometheus的Exporter机制,可以收集各种数据库的详细指标。对于不同类型的数据库,我们可以使用对应的Exporter,如mysqld_exporter、postgres_exporter、redis_exporter等。
-
灵活的查询语言:PromQL是Prometheus的查询语言,它允许用户对时间序列数据进行复杂的查询和分析。通过PromQL,可以轻松地计算数据库的性能指标,如QPS、TPS、慢查询率等。
-
强大的数据聚合能力:Prometheus可以对收集到的指标进行聚合和计算,生成更高级别的指标,如平均响应时间、95%延迟等,这些指标对于评估数据库性能非常有帮助。
-
与Alertmanager集成:Prometheus可以与Alertmanager无缝集成,根据指标变化自动触发告警,实现对数据库异常的实时监控。
在数据库治理平台中,Prometheus将收集以下关键指标:
- 数据库连接数和连接使用率
- 查询执行时间和慢查询数量
- 事务处理性能指标
- 锁竞争和死锁情况
- 缓存命中率和内存使用情况
- 磁盘I/O和存储使用情况
2.3.3 Grafana可视化平台
Grafana是数据库统一治理平台的展示层,负责将Prometheus和Loki的数据转化为直观的图表和仪表盘。Grafana的主要功能包括:
-
多数据源支持:Grafana可以同时连接多个数据源,包括Prometheus和Loki,这使得它可以在同一个仪表盘上展示指标和日志数据。
-
丰富的可视化选项:Grafana提供了多种图表类型,如折线图、柱状图、饼图、热图等,可以根据不同的数据类型选择最合适的展示方式。
-
灵活的仪表盘设计:Grafana允许用户创建自定义仪表盘,并支持模板变量和条件显示,这使得我们可以为不同类型的数据库创建统一但又有针对性的监控界面。
-
与Alertmanager集成:Grafana可以直接使用Alertmanager的告警规则,并在仪表盘上显示告警状态,提供了一站式的监控和告警体验。
在数据库治理平台中,Grafana将提供以下关键功能:
- 数据库健康状态概览
- 性能指标实时监控
- 历史数据趋势分析
- 异常指标突出显示
- 自定义查询和临时分析工具
2.3.4 Loki日志管理系统
Loki是数据库统一治理平台的日志管理组件,负责日志的收集、存储和查询。在这一架构中,Loki的主要功能包括:
-
高效的日志存储:Loki采用了与传统日志系统不同的存储方式,它只索引日志的元数据(如标签),而不是日志内容本身,这使得它可以处理海量日志数据而不会占用过多资源。
-
强大的查询能力:Loki提供了LogQL查询语言,允许用户根据标签和内容快速过滤和查询日志。通过LogQL,可以轻松地查找特定数据库的错误日志或慢查询日志。
-
与Prometheus兼容的标签系统:Loki使用与Prometheus相同的标签系统,这使得指标和日志可以使用相同的标签进行关联,方便进行联合分析。
-
分布式架构:Loki支持分布式部署,可以处理大规模的日志数据,满足企业级应用的需求。
在数据库治理平台中,Loki将管理以下类型的日志:
- 数据库错误日志和警告日志
- 查询执行日志和慢查询日志
- 事务日志和变更日志
- 连接和认证日志
- 备份和恢复日志
2.3.5 Alertmanager告警系统
Alertmanager是数据库统一治理平台的告警组件,负责告警的触发、管理和通知。在这一架构中,Alertmanager的主要功能包括:
-
灵活的告警规则定义:Alertmanager可以根据Prometheus的指标定义复杂的告警规则,支持多种条件判断和时间窗口设置。
-
告警分组和抑制:Alertmanager可以将相关的告警分组,并在某些告警触发时抑制其他告警,避免告警风暴。
-
多种通知渠道:Alertmanager支持多种通知渠道,如邮件、Slack、PagerDuty等,可以根据不同的告警级别选择合适的通知方式。
-
告警历史和状态管理:Alertmanager可以记录告警的历史状态,包括触发时间、恢复时间和通知记录,方便进行问题追踪和分析。
在数据库治理平台中,Alertmanager将监控以下关键异常情况:
- 数据库连接数达到上限
- 查询执行时间超过阈值
- 慢查询数量突然增加
- 锁竞争或死锁情况
- 存储空间不足
- 错误日志数量激增
- 数据库服务不可用
三、平台实施与配置
3.1 环境准备与基础配置
在开始实施数据库统一治理平台之前,需要完成以下环境准备工作:
-
基础设施准备:
- 确保QFusion平台已经部署并运行着需要治理的数据库服务
- 准备好用于部署治理平台组件的服务器或Kubernetes集群
- 确保各组件之间的网络连通性
-
软件安装:
- 安装和配置Istio服务网格
- 安装和配置Prometheus及其相关Exporter
- 安装和配置Grafana
- 安装和配置Loki
- 安装和配置Alertmanager
-
基础配置:
- 配置Istio的Sidecar自动注入
- 配置Prometheus的数据源和收集间隔
- 配置Grafana的数据源和初始仪表盘
- 配置Loki的日志收集规则
- 配置Alertmanager的通知渠道
下面是关键组件的基础配置示例:
Prometheus配置示例:
global:
scrape_interval: 15s
evaluation_interval: 15s
scrape_configs:
- job_name: 'istio'
kubernetes_sd_configs:
- role: service
relabel_configs:
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme]
action: replace
target_label: __scheme__
regex: (https?)
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port]
action: replace
target_label: __address__
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
- job_name: 'databases'
static_configs:
- targets: ['mysql-exporter:9104', 'postgres-exporter:9187', 'redis-exporter:9121']
Grafana数据源配置示例:
{
"name": "Prometheus",
"type": "prometheus",
"url": "http://prometheus:9090",
"access": "proxy",
"isDefault": true
}
Loki数据源配置示例:
{
"name": "Loki",
"type": "loki",
"url": "http://loki:3100",
"access": "proxy",
"basicAuth": false
}
Alertmanager配置示例:
global:
resolve_timeout: 5m
route:
receiver: 'default-receiver'
group_by: ['alertname']
group_wait: 30s
group_interval: 5m
repeat_interval: 12h
receivers:
- name: 'default-receiver'
email_configs:
- to: 'ops-team@example.com'
send_resolved: true
3.2 数据库监控配置
针对不同类型的数据库,需要进行相应的监控配置。以下是几种常见数据库的监控配置示例:
3.2.1 MySQL监控配置
安装和配置mysqld_exporter:
# 下载并安装mysqld_exporter
wget https://github.com/prometheus/mysqld_exporter/releases/latest/download/mysqld_exporter-*.linux-amd64.tar.gz
tar xvf mysqld_exporter-*.linux-amd64.tar.gz
cd mysqld_exporter-*.linux-amd64
# 创建配置文件
cat > .my.cnf <<EOF
[client]
user=exporter
password=exporter_password
EOF
# 启动mysqld_exporter
./mysqld_exporter --config.my-cnf=.my.cnf
关键监控指标:
mysql_global_status_Threads_connected:当前连接数mysql_global_status_Threads_running:当前正在运行的线程数mysql_global_status_Slow_queries:慢查询数量mysql_global_status_Innodb_row_lock_waits:行锁等待次数mysql_global_status_Innodb_buffer_pool_reads:InnoDB缓冲池读次数mysql_global_status_Innodb_buffer_pool_read_requests:InnoDB缓冲池读请求次数
Grafana仪表盘配置:
使用Grafana官方提供的MySQL监控仪表盘(仪表盘ID: 7362),该仪表盘提供了以下关键指标的可视化:
- 连接状态概览
- 查询执行统计
- InnoDB缓冲池使用情况
- 复制延迟监控
- 慢查询分析
3.2.2 PostgreSQL监控配置
安装和配置postgres_exporter:
# 下载并安装postgres_exporter
wget https://github.com/prometheus-community/postgres_exporter/releases/latest/download/postgres_exporter-*.linux-amd64.tar.gz
tar xvf postgres_exporter-*.linux-amd64.tar.gz
cd postgres_exporter-*.linux-amd64
# 启动postgres_exporter
./postgres_exporter --web.listen-address=:9187 --db.user=exporter --db.password=exporter_password --db.host=localhost --db.port=5432 --db.dbname=postgres
关键监控指标:
pg_stat_activity_query_count:活动查询数量pg_stat_database_xact_commit:事务提交次数pg_stat_database_xact_rollback:事务回滚次数pg_stat_database_blks_read:数据块读取次数pg_stat_database_blks_hit:数据块命中次数pg_locks:锁信息
Grafana仪表盘配置:
使用Grafana官方提供的PostgreSQL监控仪表盘(仪表盘ID: 13979),该仪表盘提供了以下关键指标的可视化:
- 数据库连接状态
- 事务处理统计
- 缓存使用情况
- 查询执行时间分布
- 锁等待分析
3.2.3 Redis监控配置
安装和配置redis_exporter:
# 下载并安装redis_exporter
wget https://github.com/oliver006/redis_exporter/releases/latest/download/redis_exporter-*.linux-amd64.tar.gz
tar xvf redis_exporter-*.linux-amd64.tar.gz
cd redis_exporter-*.linux-amd64
# 启动redis_exporter
./redis_exporter --redis.addr=redis://:exporter_password@localhost:6379
关键监控指标:
redis_info_connected_clients:当前连接数redis_info_blocked_clients:阻塞客户端数量redis_info_mem_used:内存使用量redis_info_expired_keys:过期键数量redis_info_evicted_keys:驱逐键数量redis_info_total_commands_processed:处理的命令总数
Grafana仪表盘配置:
使用Grafana官方提供的Redis监控仪表盘(仪表盘ID: 11574),该仪表盘提供了以下关键指标的可视化:
- 连接和客户端状态
- 内存使用情况
- 键空间统计
- 命令执行统计
- 持久化状态
- 复制状态
3.3 日志收集与分析配置
在数据库统一治理平台中,Loki负责日志的收集和管理。以下是日志收集和分析的配置步骤:
3.3.1 数据库日志配置
不同类型的数据库需要进行相应的日志配置,以确保关键日志能够被收集到Loki中。以下是几种常见数据库的日志配置示例:
MySQL日志配置:
-- 启用慢查询日志
SET GLOBAL slow_query_log = 1;
SET GLOBAL slow_query_log_file = '/var/log/mysql/slow.log';
SET GLOBAL long_query_time = 2; -- 设置慢查询阈值为2秒
-- 启用一般查询日志(仅用于调试)
SET GLOBAL general_log = 1;
SET GLOBAL general_log_file = '/var/log/mysql/query.log';
PostgreSQL日志配置:
-- 启用日志记录
log_min_messages = warning
log_min_error_statement = error
log_line_prefix = '%t [%p]: [%c] user=%u,db=%d '
-- 启用慢查询日志
log_min_duration_statement = 1000ms -- 设置慢查询阈值为1秒
log_statement = 'all'
Redis日志配置:
# 配置Redis日志级别和文件
loglevel notice
logfile /var/log/redis/redis-server.log
3.3.2 Loki日志收集配置
使用Grafana Agent(现称为Grafana Alloy)来收集数据库日志并发送到Loki。以下是Grafana Agent的配置示例:
server:
http_listen_port: 8080
grpc_listen_port: 0
positions:
filename: /tmp/positions.yaml
clients:
- url: http://loki:3100/loki/api/v1/push
scrape_configs:
- job_name: 'mysql-logs'
static_configs:
- targets:
- localhost
labels:
job: mysql-logs
__path__: /var/log/mysql/*.log
- job_name: 'postgresql-logs'
static_configs:
- targets:
- localhost
labels:
job: postgresql-logs
__path__: /var/log/postgresql/*.log
- job_name: 'redis-logs'
static_configs:
- targets:
- localhost
labels:
job: redis-logs
__path__: /var/log/redis/*.log
3.3.3 Grafana日志查询配置
在Grafana中配置Loki数据源后,可以使用LogQL查询语言进行日志分析。以下是一些常见的日志查询示例:
查询MySQL慢查询日志:
{job="mysql-logs"} |= "Slow query"
查询PostgreSQL错误日志:
{job="postgresql-logs"} level=error
查询Redis警告日志:
{job="redis-logs"} level=warning
Grafana还提供了日志钻取(Logs Drilldown)功能,可以通过可视化界面进行交互式日志分析,无需编写复杂的查询语句。
3.4 告警规则配置
在数据库统一治理平台中,Alertmanager负责管理告警规则和通知。以下是几种常见数据库告警规则的配置示例:
3.4.1 MySQL告警规则
连接数过高告警:
- alert: HighMySQLConnections
expr: rate(mysql_global_status_Threads_connected[5m]) > 1000
for: 10m
labels:
severity: critical
annotations:
summary: "MySQL连接数过高 (instance {{ $labels.instance }})"
description: "MySQL连接数超过阈值 (当前值: {{ $value }})"
慢查询数量激增告警:
- alert: HighMySQLSlowQueries
expr: increase(mysql_global_status_Slow_queries[1h]) > 100
for: 30m
labels:
severity: warning
annotations:
summary: "MySQL慢查询数量激增 (instance {{ $labels.instance }})"
description: "过去1小时慢查询数量超过100 (当前值: {{ $value }})"
InnoDB缓冲池命中率低告警:
- alert: LowInnoDBBufferPoolHitRate
expr: (mysql_global_status_Innodb_buffer_pool_read_requests - mysql_global_status_Innodb_buffer_pool_reads) / mysql_global_status_Innodb_buffer_pool_read_requests < 0.95
for: 20m
labels:
severity: warning
annotations:
summary: "InnoDB缓冲池命中率低 (instance {{ $labels.instance }})"
description: "InnoDB缓冲池命中率低于95% (当前值: {{ $value | printf \"%.2f\" }}%)"
3.4.2 PostgreSQL告警规则
查询执行时间过长告警:
- alert: LongPostgreSQLQueryTime
expr: avg by (queryid) (pg_stat_statements_mean_time) > 500
for: 15m
labels:
severity: warning
annotations:
summary: "PostgreSQL查询执行时间过长 (instance {{ $labels.instance }})"
description: "平均查询执行时间超过500ms (当前值: {{ $value | printf \"%.2f\" }}ms)"
锁等待时间过长告警:
- alert: HighPostgreSQLLockWaits
expr: rate(pg_stat_activity_query_count[5m]) > 10
for: 10m
labels:
severity: critical
annotations:
summary: "PostgreSQL锁等待时间过长 (instance {{ $labels.instance }})"
description: "锁等待时间超过阈值 (当前值: {{ $value }})"
复制延迟过高告警:
- alert: HighPostgreSQLReplicationLag
expr: pg_last_xact_replay_timestamp - pg_current_xact_start_time > 60
for: 5m
labels:
severity: critical
annotations:
summary: "PostgreSQL复制延迟过高 (instance {{ $labels.instance }})"
description: "复制延迟超过60秒 (当前值: {{ $value | printf \"%.2f\" }}秒)"
3.4.3 Redis告警规则
内存使用量过高告警:
- alert: HighRedisMemoryUsage
expr: redis_info_mem_used / redis_info_total_system_memory > 0.9
for: 20m
labels:
severity: critical
annotations:
summary: "Redis内存使用量过高 (instance {{ $labels.instance }})"
description: "内存使用率超过90% (当前值: {{ $value | printf \"%.2f\" }}%)"
连接数过高告警:
- alert: HighRedisConnections
expr: redis_info_connected_clients > 1000
for: 10m
labels:
severity: warning
annotations:
summary: "Redis连接数过高 (instance {{ $labels.instance }})"
description: "连接数超过1000 (当前值: {{ $value }})"
键驱逐率过高告警:
- alert: HighRedisKeyEvictions
expr: rate(redis_info_evicted_keys[1h]) > 1000
for: 30m
labels:
severity: warning
annotations:
summary: "Redis键驱逐率过高 (instance {{ $labels.instance }})"
description: "过去1小时键驱逐数量超过1000 (当前值: {{ $value }})"
3.5 统一治理界面设计
在Grafana中设计统一的数据库治理界面,为运维人员提供一站式的监控和管理体验。以下是界面设计的关键要素:
3.5.1 数据库概览仪表盘
创建数据库概览仪表盘,提供所有数据库的健康状态和关键指标的概览:
- 数据库类型和数量统计
- 健康状态分布(健康/警告/严重)
- 关键指标热力图(连接数、CPU使用率、内存使用率)
- 最近告警列表
- 性能趋势对比
3.5.2 数据库类型专用仪表盘
为不同类型的数据库创建专用仪表盘,提供更详细的监控信息:
关系型数据库仪表盘:
- 连接状态和使用率
- 查询性能分析
- 事务处理统计
- 锁竞争情况
- 缓存使用情况
- 存储和I/O状态
NoSQL数据库仪表盘:
- 连接和客户端状态
- 内存使用情况
- 键空间统计
- 命令执行统计
- 持久化状态
- 复制状态
3.5.3 日志分析界面
设计统一的日志分析界面,提供以下功能:
- 多数据库日志统一搜索
- 基于时间的日志过滤
- 日志级别分类
- 关键字搜索和高亮显示
- 日志上下文查看
- 日志导出和下载
3.5.4 告警管理界面
设计告警管理界面,提供以下功能:
- 当前活跃告警列表
- 告警历史记录
- 告警分组和过滤
- 告警抑制规则管理
- 告警通知配置
- 告警统计和趋势分析
四、平台优化与扩展
4.1 性能优化策略
随着监控数据量的增加,数据库统一治理平台的性能优化变得尤为重要。以下是一些关键的性能优化策略:
4.1.1 Prometheus性能优化
数据保留策略优化:
# prometheus.yml配置
storage:
retention: 15d # 根据需求调整保留时间
retention_size: 10GB # 设置最大存储容量
查询性能优化:
- 使用记录规则预先计算常用指标
- 避免在查询中使用大量的label匹配
- 合理设置采样间隔,避免不必要的高频采集
存储优化:
- 使用专用的存储设备
- 考虑使用远程存储解决方案
- 定期清理旧数据
4.1.2 Loki性能优化
日志保留策略优化:
# loki-config.yaml配置
schema_config:
configs:
- from: 2020-10-24
store: boltdb-shipper
object_store: filesystem
schema: v11
index:
prefix: index_
period: 24h
查询性能优化:
- 使用更精确的标签进行过滤
- 避免全量日志扫描
- 合理设置日志保留时间
存储优化:
- 使用分布式存储方案
- 对日志进行压缩
- 实施冷热数据分离
4.1.3 Grafana性能优化
仪表盘性能优化:
- 避免在单个仪表盘上放置过多的面板
- 使用缓存机制
- 合理设置数据查询的时间范围
数据源优化:
- 配置适当的超时时间
- 使用连接池
- 限制返回的数据量
4.2 高可用性设计
为确保数据库统一治理平台的高可用性,需要实施以下措施:
4.2.1 Prometheus高可用部署
主从复制架构:
+---------+ +---------+
| Prometheus | | Prometheus |
| Server | | Server |
+----+------+ +----+------+
| |
+----v------+ +----v------+
| Consul | | Consul |
| Server | | Server |
+---------+ +---------+
联邦集群架构:
+-----------------+
| Prometheus |
| Federation |
+--------+--------+
|
+--------v--------+
| Prometheus |
| Server A |
+--------+--------+
|
+--------v--------+
| Prometheus |
| Server B |
+-----------------+
4.2.2 Loki高可用部署
分布式架构:
+-----------------+
| Loki |
| Query |
+--------+--------+
|
+--------v--------+
| Loki |
| Distributor |
+--------+--------+
|
+--------v--------+
| Loki |
| Ingester |
+--------+--------+
|
+--------v--------+
| Storage |
| Backend |
+-----------------+
数据复制策略:
- 设置适当的复制因子
- 实施数据分片
- 配置自动故障转移
4.2.3 Alertmanager高可用部署
集群部署:
+-----------------+
| Alertmanager |
| Cluster |
+--------+--------+
|
+--------+--------+
| Alertmanager |
| Server A |
+--------+--------+
|
+--------+--------+
| Alertmanager |
| Server B |
+-----------------+
配置同步:
- 使用共享存储
- 配置自动同步机制
- 定期备份配置文件
4.3 安全性增强
数据库统一治理平台处理大量敏感数据,安全性至关重要。以下是关键的安全增强措施:
4.3.1 认证和授权
Istio mTLS配置:
# peerAuthentication配置
apiVersion: security.istio.io/v1beta1
kind: PeerAuthentication
metadata:
name: default
spec:
mtls:
mode: STRICT
Prometheus认证配置:
# prometheus.yml配置
basic_auth:
username: admin
password: secret
Grafana认证和授权:
# grafana.ini配置
[auth]
disable_login_form = false
[security]
admin_user = admin
admin_password = secret
4.3.2 数据保护
数据加密:
- 对敏感数据进行加密存储
- 使用TLS加密数据传输
- 实施数据分类和分级保护
访问控制:
- 实施最小权限原则
- 基于角色的访问控制
- 定期审核访问日志
审计日志:
- 记录所有管理操作
- 保留足够长时间的审计日志
- 定期进行安全审计
4.3.3 安全加固
组件安全加固:
- 保持所有组件更新到最新版本
- 禁用不必要的服务和端口
- 限制外部访问
网络安全:
- 实施网络分段
- 使用防火墙保护关键组件
- 监控异常网络流量
安全事件响应:
- 建立安全事件响应机制
- 定期进行安全演练
- 持续监控安全态势
4.4 扩展能力设计
数据库统一治理平台需要具备良好的扩展能力,以适应不断变化的业务需求。以下是关键的扩展能力设计:
4.4.1 支持新数据库类型
平台应具备灵活的架构,能够轻松添加对新数据库类型的支持:
添加新数据库类型的步骤:
- 选择或开发对应的Exporter
- 配置Prometheus收集指标
- 创建Grafana仪表盘
- 配置日志收集规则
- 定义告警规则
4.4.2 水平扩展能力
Prometheus水平扩展:
- 使用联邦集群架构
- 实施分片策略
- 使用远程存储
Loki水平扩展:
- 增加Distributor节点
- 扩展Ingester集群
- 增加存储容量
Grafana水平扩展:
- 使用负载均衡器
- 配置数据库连接池
- 实施缓存策略
4.4.3 自动化部署和配置
基础设施即代码:
- 使用Terraform进行基础设施部署
- 使用Ansible进行配置管理
- 使用Helm进行应用部署
自动化测试:
- 实施单元测试
- 进行集成测试
- 执行端到端测试
持续集成和持续部署:
- 建立CI/CD管道
- 实施自动化发布流程
- 进行蓝绿部署
五、实施路径与预期收益
5.1 分阶段实施计划
为确保数据库统一治理平台的成功实施,建议采用分阶段的实施方法:
5.1.1 第一阶段:原型验证(1-2个月)
目标:验证技术可行性,建立概念验证系统
关键任务:
- 选择3-5种代表性数据库进行监控原型开发
- 实施Istio服务网格基础架构
- 部署Prometheus、Grafana、Loki和Alertmanager
- 实现基本的指标收集和可视化
- 建立初步的告警规则
预期成果:
- 概念验证系统
- 技术可行性报告
- 初步的监控仪表盘
5.1.2 第二阶段:全面实施(3-4个月)
目标:扩展到所有数据库,实现全面监控和管理
关键任务:
- 扩展支持所有数据库类型
- 完善指标收集和日志管理
- 开发统一的治理界面
- 建立完整的告警规则体系
- 实施高可用性和安全措施
预期成果:
- 完整的数据库统一治理平台
- 全面的监控和告警能力
- 统一的可视化界面
- 完善的安全保障体系
5.1.3 第三阶段:优化与扩展(5-6个月)
目标:持续优化平台性能,扩展功能和能力
关键任务:
- 进行性能优化和调优
- 实施自动化运维集成
- 开发自定义分析工具
- 实现与其他系统的集成
- 建立运维流程和规范
预期成果:
- 高效稳定的治理平台
- 自动化运维能力
- 定制化分析工具
- 完善的运维体系
5.2 预期收益分析
实施数据库统一治理平台将带来以下显著收益:
5.2.1 运维效率提升
监控效率提升:
- 统一的监控界面减少了运维人员的上下文切换
- 自动化的指标收集和分析减少了人工检查工作
- 智能告警减少了虚假警报和告警疲劳
故障排查效率提升:
- 指标和日志的关联分析加速了问题定位
- 历史数据和趋势分析提供了决策支持
- 统一的工具链减少了工具切换的时间
变更管理效率提升:
- 全面的监控数据提供了变更影响评估依据
- 自动化的部署和配置减少了人为错误
- 标准化的治理流程提高了变更效率
5.2.2 成本节约
硬件成本节约:
- 优化的资源使用减少了不必要的硬件投资
- 集中管理降低了基础设施的复杂度
- 高效的资源利用率提高了投资回报率
人力成本节约:
- 自动化运维减少了人工干预需求
- 统一的工具链降低了培训成本
- 快速的故障定位和恢复减少了停机时间
机会成本节约:
- 提高了开发和运维团队的生产力
- 减少了服务中断对业务的影响
- 加快了新功能的部署速度
5.2.3 服务质量提升
可用性提升:
- 实时监控和主动告警减少了服务中断
- 快速的故障响应和恢复机制提高了可用性
- 高可用性架构设计降低了单点故障风险
性能优化:
- 详细的性能指标分析支持了优化决策
- 历史趋势分析帮助识别潜在瓶颈
- 资源使用优化提高了系统性能
安全性增强:
- 统一的安全管理降低了安全风险
- 详细的审计日志支持了合规性要求
- 强大的访问控制机制保护了敏感数据
5.3 成功关键因素
数据库统一治理平台的成功实施取决于以下关键因素:
5.3.1 明确的治理目标和范围
- 定义清晰的治理目标和KPI
- 明确平台的覆盖范围和边界
- 确定与现有系统的集成策略
5.3.2 有效的组织协作
- 建立跨部门的项目团队
- 明确各角色的职责和权限
- 促进开发、运维和安全团队的协作
5.3.3 完善的运维流程
- 建立标准化的监控和告警流程
- 定义清晰的故障响应和恢复流程
- 实施变更管理和发布流程
5.3.4 持续的技能提升
- 提供系统的培训和知识转移
- 建立内部专家团队
- 鼓励持续学习和创新
5.3.5 管理层支持和资源保障
- 获得高层领导的支持和承诺
- 确保充足的人力和物力资源
- 建立有效的沟通和汇报机制
六、总结与展望
6.1 项目价值总结
数据库统一治理平台通过整合Istio、Prometheus、Grafana、Loki和Alertmanager等开源工具,为QFusion平台上的20多款数据库提供了全面的监控、日志管理、告警和可视化能力。这一平台的实施将显著提升数据库运维的效率和质量,降低运维成本,提高服务的可用性和性能,为业务系统的稳定运行提供强有力的支持。
这一平台的核心价值在于:
- 统一管理:通过单一的平台管理所有数据库,降低了管理复杂度
- 全面监控:提供了从指标到日志的全方位监控能力
- 智能告警:基于丰富的指标数据实现智能的异常检测和告警
- 高效运维:通过统一的工具链和自动化机制提高运维效率
- 持续优化:基于历史数据和趋势分析支持持续的性能优化
6.2 未来发展方向
随着技术的不断发展和业务需求的变化,数据库统一治理平台还有许多值得探索的发展方向:
6.2.1 人工智能和机器学习应用
智能异常检测:
- 使用机器学习算法识别异常模式
- 预测潜在的性能问题和故障
- 自动优化监控指标和告警阈值
智能决策支持:
- 基于历史数据提供优化建议
- 自动生成性能分析报告
- 提供故障排除的智能指引
6.2.2 云原生和混合云支持
云原生数据库支持:
- 扩展对云原生数据库的监控能力
- 支持Serverless数据库架构
- 整合云服务商的监控服务
混合云环境支持:
- 跨多云环境的统一监控
- 支持本地和云端数据库的统一治理
- 实现混合云环境下的一致性管理
6.2.3 自动化和自治运维
自动化运维集成:
- 与自动化运维工具链集成
- 实现故障自动恢复
- 实施基于策略的自动化管理
自治运维:
- 实现自我监控和自我优化
- 自动调整资源配置
- 实施预测性维护
6.3 结语
数据库统一治理平台是企业数字化转型过程中的关键基础设施,它不仅提供了对数据库资源的有效管理,还为业务创新和发展提供了有力支持。通过这一平台的实施,企业能够更加高效地管理复杂的数据库环境,提高服务质量和用户体验,降低运维成本和风险。
在未来的发展中,随着人工智能、云原生和自动化技术的不断进步,数据库统一治理平台将不断演进和完善,为企业提供更加智能、高效和安全的数据库管理能力。我们相信,这一平台将成为企业数字化转型道路上的重要基石,推动企业业务的持续创新和发展。
最后,我们建议企业在实施数据库统一治理平台时,应根据自身需求和现状,采用分阶段的实施策略,注重与现有系统的集成,关注人才培养和技能提升,确保平台的成功实施和持续价值创造。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 14
14 0
0- 0



 已为社区贡献25条内容
已为社区贡献25条内容

所有评论(0)