pandas 里常用的两个数据合并方法:concat 和 merge
一、concat。
一、concat 方法
作用:主要用于在 行或列方向 把多个 DataFrame 或 Series 简单地 拼接 在一起。类似于 堆叠(stack) 或者 追加(append)。
典型场景:多个结构一致的表(比如每个月的销售数据...)合并成一个大表。
常用参数
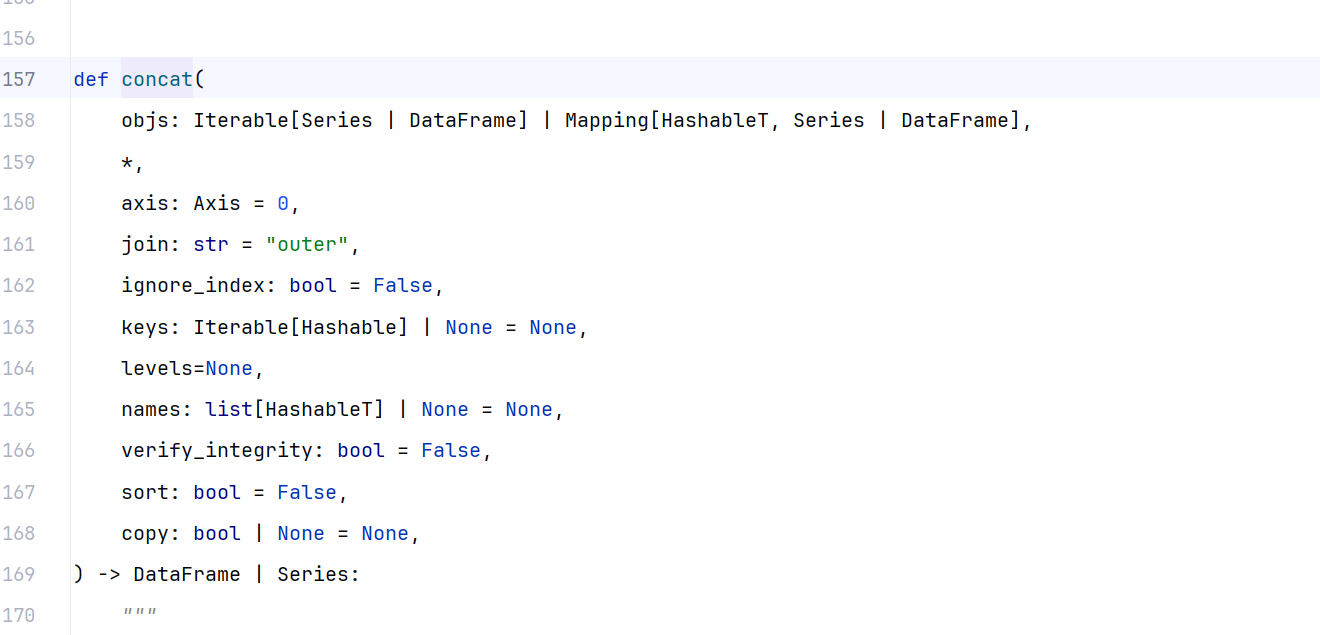
axis:拼接方向。
axis=0(默认):按行拼接(上下叠加)。
axis=1:按列拼接(左右拼接)。
ignore_index:是否重新生成索引。
keys:生成多层索引。
join:决定按什么方式对齐列(inner 或 outer,默认为 outer)
简单示例:
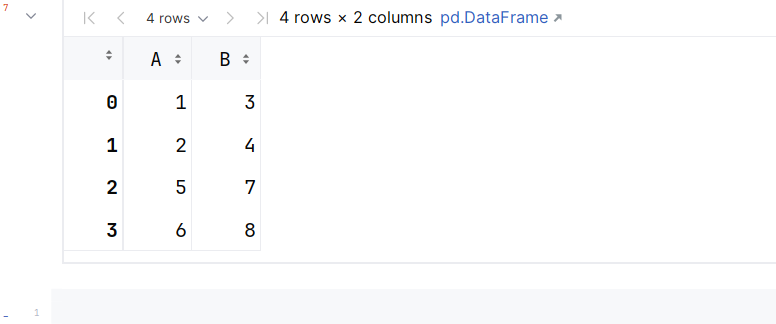
import pandas as pd
df1 = pd.DataFrame({'A': [1, 2], 'B': [3, 4]})
df2 = pd.DataFrame({'A': [5, 6], 'B': [7, 8]})
result = pd.concat([df1, df2], axis=0, ignore_index=True)
result
借助jupyter notebook 测试代码结果如下:
二、 merge 方法
作用:类似于SQL中的join,用于根据某些列的值把两个DataFrame按键对齐合并。
可以通过设置how参数来执行内连接(默认是inner),左连接(how=left),右连接(how=right)、外连接(how=outer).
经典场景:
需要根据一个或者多个关键列,将两个表按行对齐合并如(订单表和用户表)。
常用参数:
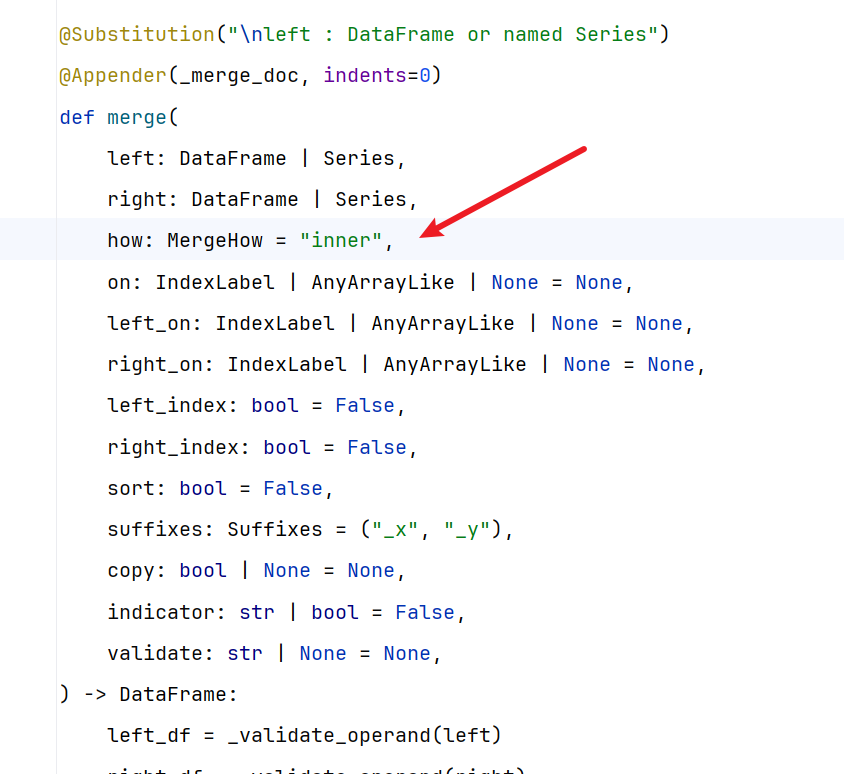
on:指定用于连接的列名。
left_on 和 right_on:分别指定左右表用于连接的列。
how:连接方式(inner、outer、left、right)。
suffixes:处理列名冲突时添加的后缀。
简单示例:
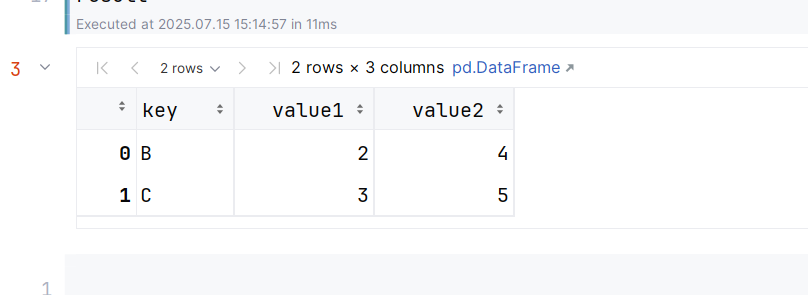
import pandas as pd
df1 = pd.DataFrame(
{
'key':['A','B','C'],
'value1':[1,2,3]
}
)
df2 = pd.DataFrame(
{
'key': ['B','C','D'],
'value2':[4,5,6]
}
)
result = pd.merge(
df1,df2,on='key',how='inner'
)
result借助jupyter notebook测试代码结果如下:
注意:
-
concat:像“拼积木”,简单堆叠,不检查匹配逻辑,索引对不上就补NaN。 -
merge:像“数据库 JOIN”,必须有键,一定要搞清楚要怎么匹配,怎么保留行。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)