9大Github神仙开源大模型教程汇总,轻松一网打尽!
01Happy-LLM 带你快乐学习大模型(LLM)。现在已经在 GitHub 上斩获 4.8K 的 Star。一个系统性的大模型学习教程,从 NLP 基础概念出发,逐步剖析 Transformer 架构、预训练模型原理及 LLM 训练全流程。项目通过动手实现 LLaMA2 模型、训练 Tokenizer 和应用前沿技术(如RAG、Agent),帮助开发者深入理解 LLM 核心原理并掌握实战技能。
01
Happy-LLM
国内 Datawhale 开源组织出品,本盘点有好多开源教程都是 Datawhale 制作的,感谢 Datawhale 在 AI 知识开源领域做的贡献。
Happy-LLM 带你快乐学习大模型(LLM)。现在已经在 GitHub 上斩获 4.8K 的 Star。
一个系统性的大模型学习教程,从 NLP 基础概念出发,逐步剖析 Transformer 架构、预训练模型原理及 LLM 训练全流程。

项目通过动手实现 LLaMA2 模型、训练 Tokenizer 和应用前沿技术(如RAG、Agent),帮助开发者深入理解 LLM 核心原理并掌握实战技能。
开源地址:https://github.com/datawhalechina/happy-llm02
LLM-Universe
LLM-Universe 是面向小白的 LLM 应用开发课程,现在获得了 8.8k 的 Star,基于阿里云服务器实现个人知识库助手项目。
内容涵盖API调用(GPT、文心、讯飞)、Prompt 工程、向量数据库搭建及 Streamlit 部署,通过实战项目串联大模型开发全流程。
开源地址:https://github.com/datawhalechina/llm-universe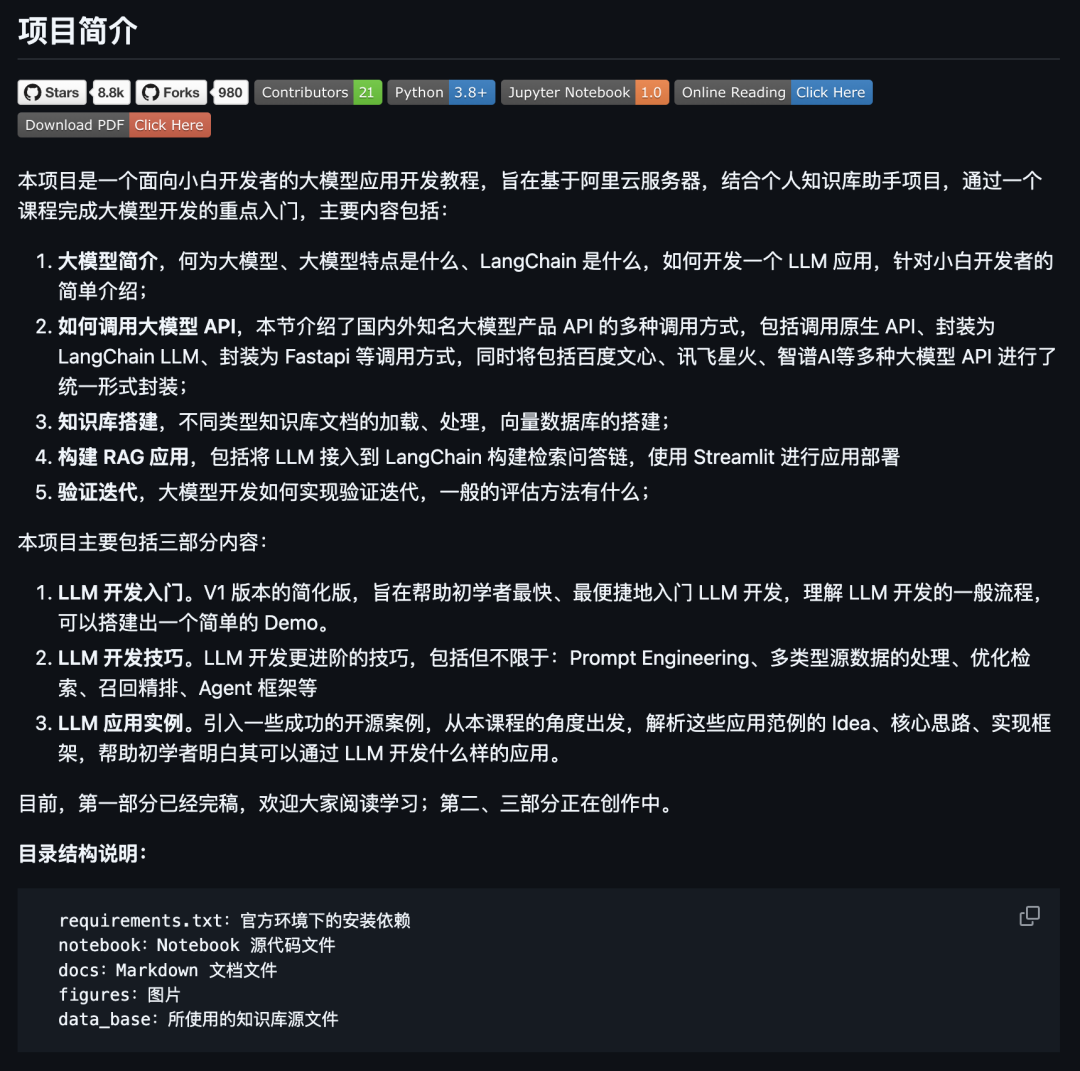
03
LLM-Action
聚焦大模型工程化与应用落地的开源项目,涵盖训练(全量/LoRA微调)、推理优化(vLLM/TensorRT-LLM)、压缩(量化/剪枝)及安全攻防。
提供 Alpaca、ChatGLM 等模型的复现教程和性能评测方案,现在已经获得了 18.9K 的 Star。
开源地址:https://github.com/liguodongiot/llm-action
04
AI Engineering Hub
这个叫做 ai-engineering-hub 的开源项目已经在 GitHub 上获得 13.1K 的 Star。
包含大模型、RAG 和 AI 智能体应用搭建等一系列教程。这个项目不是什么高深莫测的研究论文,而是一个深度教程与实践案例的集合库。
开源地址:https://github.com/patchy631/ai-engineering-hub牛的是,他们直接把核心教程整理成了一本 500 多页的 PDF。
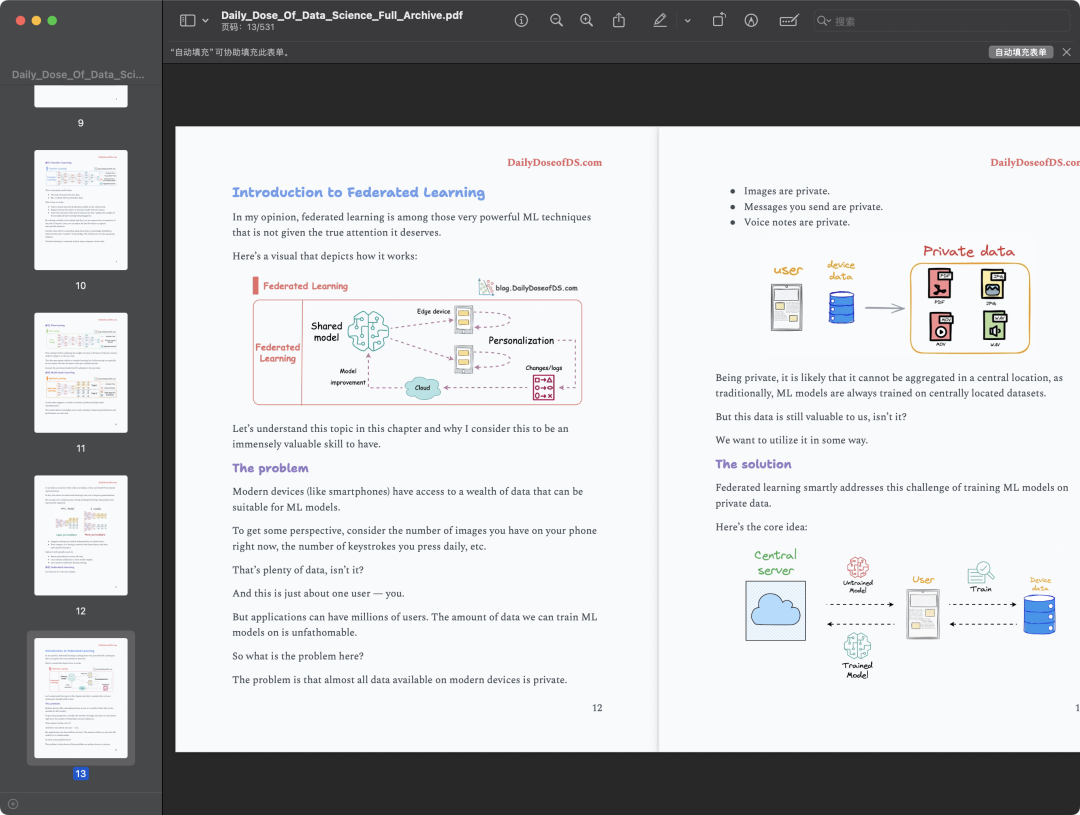
这本精心整理的“工具箱+说明书”,专注于提供深入、可操作的指南,教你如何将前沿的 AI 技术(特别是围绕像 DeepSeek、Llama、Gemma 这样的开源大模型)应用到真实世界的场景中。
05
Self-LLM
又是国内 Datawhale 团队出品,这是专为中国开发者设计的开源大模型实战指南,目前获得了 19.8K 的 Star。
提供 Linux 环境下全参数/LoRA微调、多模态模型部署教程。
项目简化开源模型(如LLaMA、ChatGLM)的本地部署流程,包含环境配置、高效微调方法和私域模型定制化实践。
开源地址:https://github.com/datawhalechina/self-llm
06
LLM Cookbook
LLM Cookbook 斩获 20.1K 的 Star。
基于吴恩达大模型课程的中文实践教程,覆盖 Prompt Engineering、RAG 开发和模型微调全流程。
项目提供双语代码示例和分级课程(必修/选修),适合国内开发者快速入门 LLM 应用开发,强调中文 Prompt 设计与 API 调用优化。
开源地址:https://github.com/datawhalechina/llm-cookbook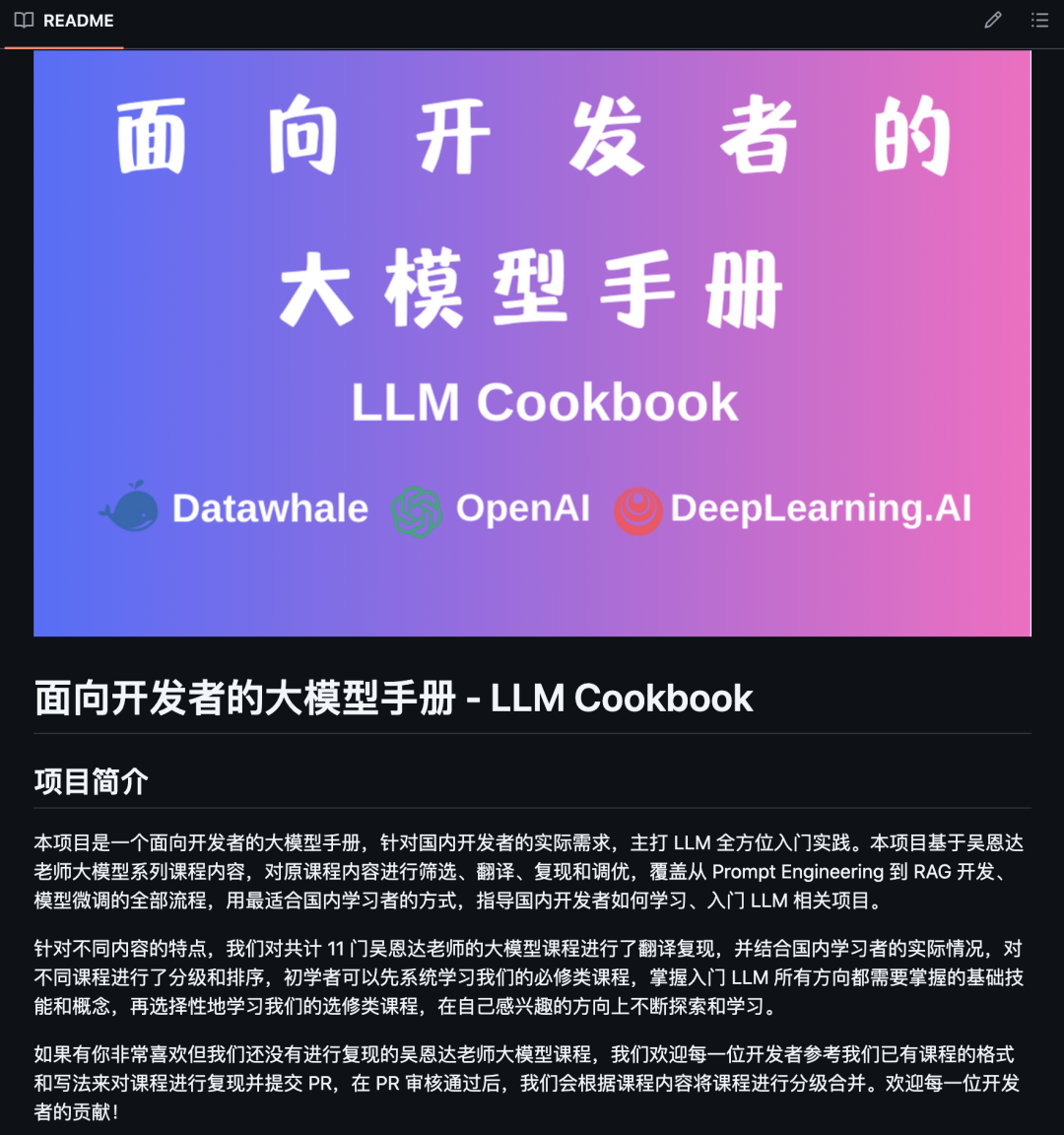
07
复现小 GPT
零门槛训练专属 AI 大模型,23K Star 爆火开源项目项目 MiniMind来了!🌟
这个开源神器让普通开发者用家用电脑,3 小时就能从零训出 26MB 超轻量 GPT!最小体积仅为 GPT-3 的 1/7000,3090 显卡轻松拿捏~
开源地址:https://github.com/jingyaogong/minimind
它从预训练、指令微调到 LoRA 适配、DPO 对齐,完整复现大模型工业化流程。集成Transformer 解码器+旋转位置编码,甚至支持 MoE 混合专家模型提升性能。
所有核心算法代码均从 0 使用 PyTorch 原生重构!不依赖第三方库提供的抽象接口。这不仅是大语言模型的全阶段开源复现,也是一个入门LLM的教程。
08
LLM Course
分为LLM基础、模型构建和应用部署三部分,提供 Transformer 原理、微调技巧(QLoRA/DPO)和 RAG 优化等实战内容。已经获得了 56k+ 的 Star。
包含大量 Colab 代码和工具(如AutoQuant、LazyMergekit),适合进阶学习模型训练与部署。
开源地址:https://github.com/mlabonne/llm-course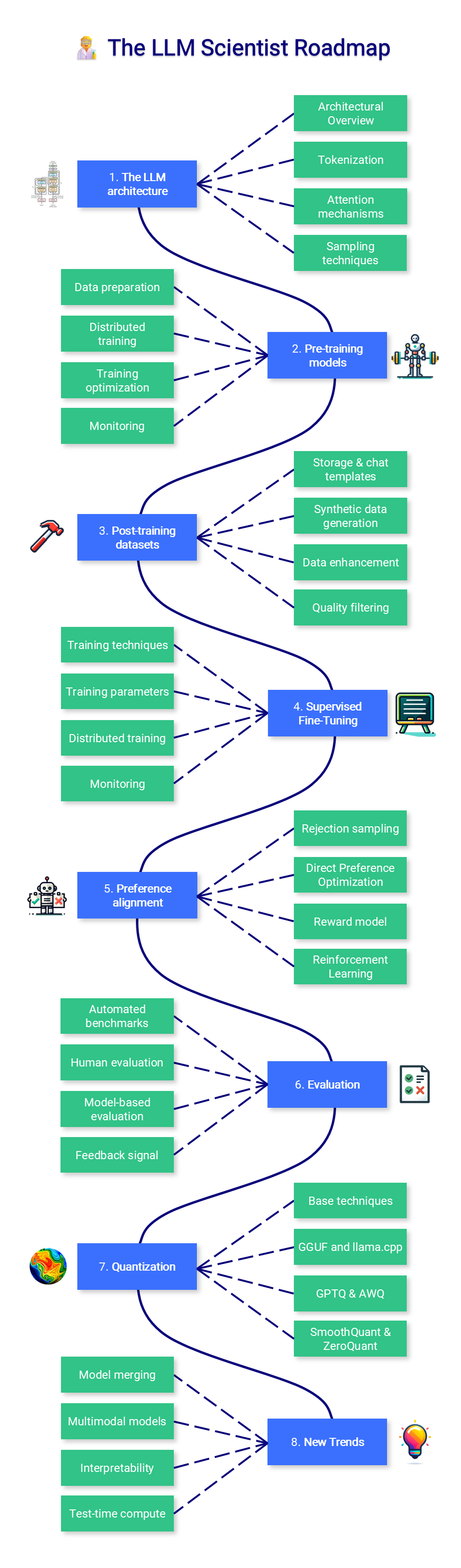
09
Generative AI for Beginners
微软开源,现在已经获得 87K 的 Star!
微软推出的 21 课生成式 AI 入门课程,涵盖 Prompt 工程、文本/图像应用开发、RAG和 Agent 集成。
结合 Python 代码示例,强调负责任AI使用和低代码工具(如Gradio),适合零基础开发者。
开源地址:https://github.com/microsoft/generative-ai-for-beginners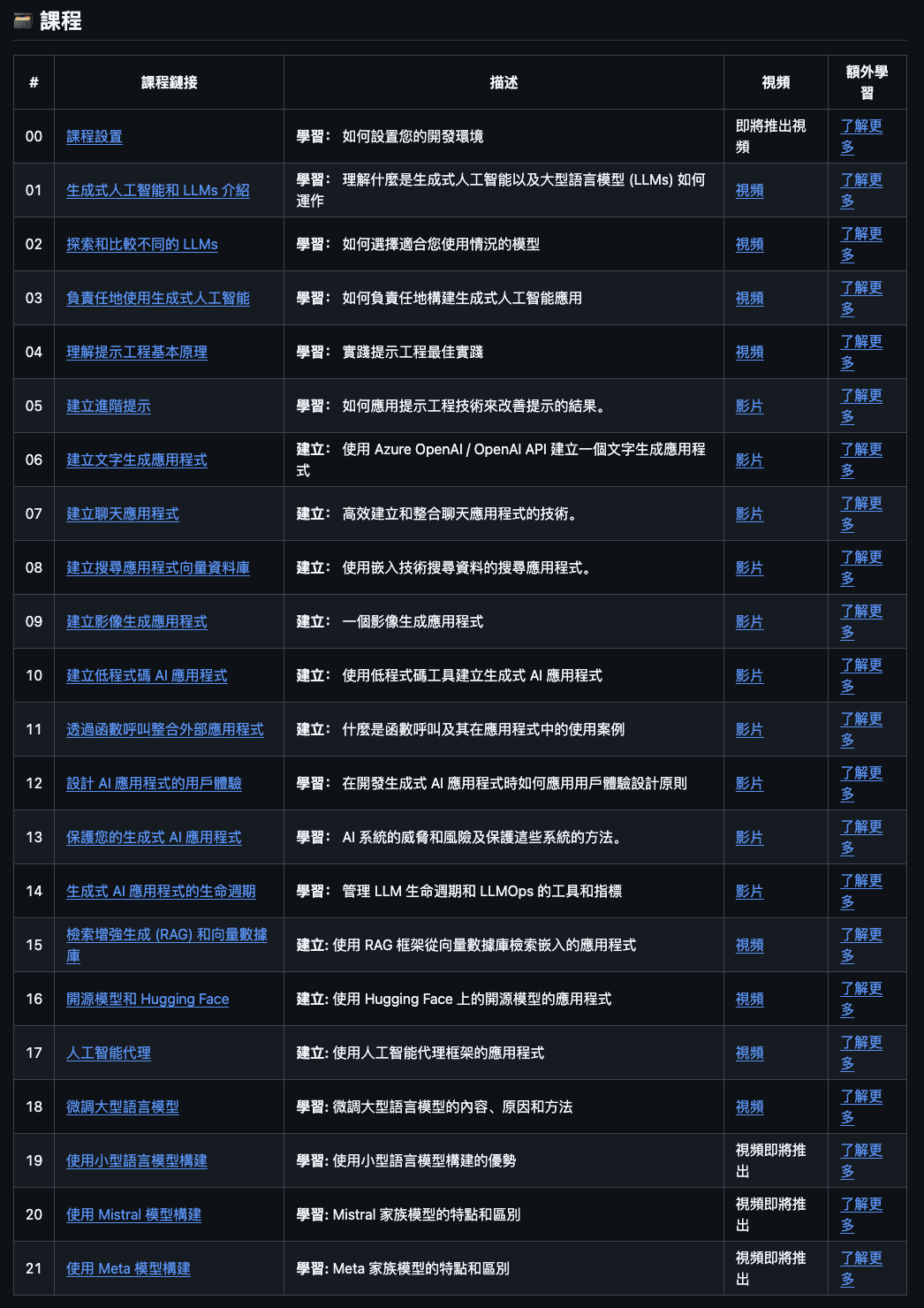
我们该怎样系统的去转行学习大模型 ?
很多想入行大模型的人苦于现在网上的大模型老课程老教材,学也不是不学也不是,基于此,我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近100余次后,终于把整个AI大模型的学习门槛,降到了最低!
第一您不需要具备任何算法和数学的基础
第二不要求准备高配置的电脑
第三不必懂Python等任何编程语言
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型教程已经给大家整理并打包,现在将这份 LLM大模型资料 分享出来: 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、大模型经典书籍(免费分享)
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套大模型报告(免费分享)
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)
三、大模型系列视频教程(免费分享)

四、2025最新大模型学习路线(免费分享)
我们把学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:我们会去了解大模型的基础知识,以及大模型在各个行业的应用和分析;学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段是我们的AI大模型RAG应用开发工程,我们会去学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,我们会去学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造我们自己的Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,我们会更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调。

L5阶段:专题集丨特训篇 【录播课】

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以微信扫描下方二维码,免费领取

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 9
9 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)